
Dear friends,
The rise of AI over the last decade has been powered by the increasing speed and decreasing cost of GPUs and other accelerator chips. How long will this continue? The past month saw several events that might affect how GPU prices evolve.
In September, Ethereum, a major blockchain that supports the cryptocurrency known as ether, completed a shift that significantly reduced the computation it requires. This shift — dubbed the Merge — should benefit the natural environment by consuming less energy. It will also decrease demand for GPUs to carry out cryptocurrency mining. (The Bitcoin blockchain remains computationally expensive.) I expect that lower demand will help lower GPU prices.
On the other hand, Nvidia CEO Jensen Huang declared recently that the era in which chip prices could be expected to fall is over. Moore’s Law, the longstanding trend that has doubled the number of transistors that could fit in a given area of silicon roughly every two years, is dead, he said. It remains to be seen how accurate his prediction is. After all, many earlier reports of the death of Moore’s Law have turned out to be wrong. Intel continues to bet that it will hold up.
That said, improvements in GPU performance have exceeded the pace of Moore’s Law as Nvidia has optimized its chips to process neural networks, while the pace of improvements in CPUs, which are designed to process a wider range of programming, has fallen behind. So even if chip manufacturers can’t pack silicon more densely with transistors, chip designers may be able to continue optimizing to improve the price/performance ratio for AI.

International news also had implications for chip supply and demand. Last week, the United States government restricted U.S. companies from selling advanced semiconductors and chip-making equipment to China. It also prohibited all sales in China of AI chips made using U.S. technology or products and barred U.S. citizens and permanent residents from working for Chinese chip firms.
No doubt the move will create significant headwinds for many businesses in China. It will also hurt U.S. semiconductor companies by limiting their market and further incentivizing Chinese competitors to replace them. The AI community has always been global, and if this move further decouples the U.S. and China portions, it will have effects that are hard to foresee.
Still, I’m optimistic that AI practitioners will get the processing power they need. While much AI progress has been — and a meaningful fraction still is — driven by using cheaper computation to train bigger neural networks on bigger datasets, other engines of innovation now drive AI as well. Data-centric AI, small data, more efficient algorithms, and ongoing work to adapt AI to thousands (millions?) of new applications will keep things moving forward.
Semiconductor startups have had a hard time in recent years because, by the time they caught up with any particular offering by market leader Nvidia, Nvidia had already moved on to a faster, cheaper product. If chip prices stop falling, they’ll have a bigger market opportunity — albeit with significant technical hurdles — to build competitive chips. The industry for AI accelerators remains dynamic. Intel and AMD are making significant investments and a growing number of companies are duking it out on the MLPerf benchmark that measures chip performance. I believe the options for training and inference in the cloud and at the edge will continue to expand.
Keep learning!
Andrew
DeepLearning.AI Exclusive

Breaking Into AI: Learning from Failure
Sahar Nasiri’s early job interviews went well until she was asked to interpret the algorithms she had listed on her resume. These experiences pushed her to deepen her understanding of the math behind data science. Now she works for a major U.S. airline. Read her story
News

Long-Form Videos from Text Stories
Only a week ago, researchers unveiled a system that generates a few seconds of video based on a text prompt. New work enables a text-to-video system to produce an entire visual narrative from several sentences of text.
What’s new: Ruben Villegas and colleagues at Google developed Phenaki, a system that produces videos of arbitrary length from a story-like description. You can see examples here.
Key insight: The machine learning community lacks a large dataset of long-form videos and time-aligned captions, so it’s not obvious how to train a model to synthesize long videos from a narrative. But text-image pairs are plentiful. A system can be trained to generate short videos by treating images as single-frame videos and combining them with a relatively smaller dataset of short videos with captions. Then the video can be extended by feeding the system new text plus the last few generated frames. Repeating this process can generate long, complex videos even though the model was trained on short, simple ones.
How it works: Phenaki uses an encoder to produce video embeddings, a language model to produce text embeddings, a bidirectional transformer to take the text and video embeddings and synthesize new video embeddings, and a decoder to translate synthesized video embeddings into pixels.
- Using a dataset of videos less than three seconds long, the authors pretrained a C-ViViT encoder/decoder (a variant of ViViT adapted for video) to compress frames into embeddings and decompress them into the original frames. The encoder divided frames into non-overlapping patches and learned to represent the patches as vectors. Transformer layers honed each patch’s embedding according to all patches within the same frame and all previous frames. The decoder learned to translate the embeddings into pixels.
- Given a piece of text, t5x language model pretrained on web text produced a text embedding.
- The authors pretrained a MaskGIT bidirectional transformer on embeddings produced by C-ViViT for 15 million proprietary text-video pairs (each video lasted 1.4 seconds at 8 frames per second), 50 million proprietary text-image pairs, and 400 million text-image pairs scraped from the web. They masked a fraction of the video embeddings and trained MaskGIT to reconstruct them.
- At inference, MaskGIT took the text embeddings and a series of masked video embeddings (since no video had been generated yet), generated the masked embeddings, then re-masked a fraction of them to be generated in the next iterations. In 48 steps, MaskGIT generated all the masked embeddings.
- The C-ViViT decoder took the predicted embeddings and rendered them as pixels.
- The authors applied MaskGIT and C-ViViT iteratively to produce minutes-long videos. First they generated a short video from one sentence, then encoded the last k generated frames. They used the video embeddings and the next piece of text to generate further video frames.
Results: The full-size Phenaki comprised 1.8 billion parameters. In the only quantitative evaluation of the system’s text-to-video capability, the authors compared a 900 million-parameter version of Phenaki trained on half of their data to a 900 million-parameter NUWA pretrained on text-image pairs, text-video pairs, and three-second videos and fine-tuned on 10-second videos. (Phenaki was not fine-tuned.) The downsized Phenaki achieved 3.48 FID-Video compared to NUWA’s 7.05 FID-Video (a measure of similarity between generated and original videos, lower is better).
Why it matters: Last week’s Make-A-Video used a series of diffusion models that generate a short video from a text description and upscale its temporal and image resolution. Phenaki bootstrapped its own generated frames to extend the output’s length and narrative complexity. Together, they may point to a revolution in filmmaking.
We’re thinking: One challenge of the recent approaches is maintaining consistency across spans of frames. In the clip shown above, for example, the lion’s appearance at the beginning differs from its appearance at the end. We don’t regard this as a fundamental problem, though. It seems like only a matter of time before an enterprising developer devises an attention-based/transformer architecture that resolves the issue.
Wreckage Recognition
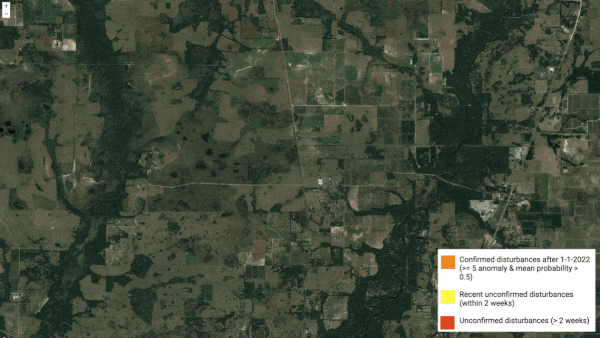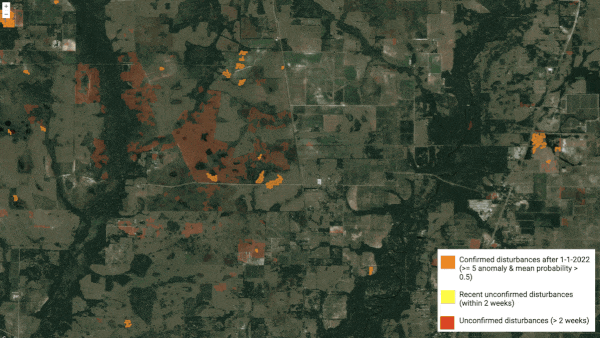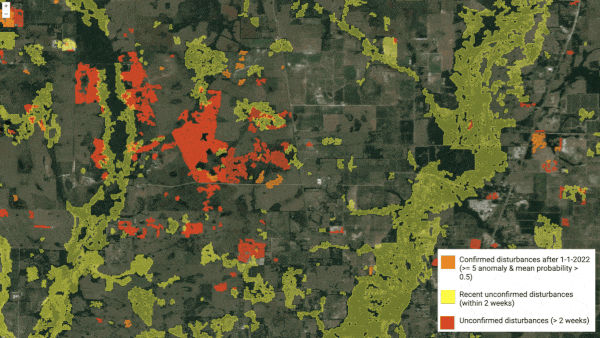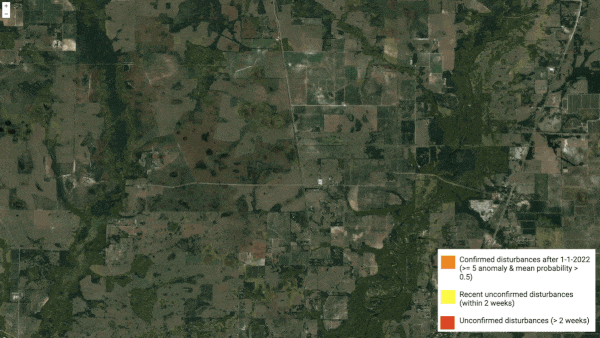
A machine learning model identified areas likely to have been damaged by Hurricane Leo as it swept through the southern United States.
What's new: University of Connecticut researchers Zhe Zhu and Su Ye used a learning algorithm to examine satellite images of the storm’s path and spot changes that might indicate wreckage.
How it works: The system was originally designed to identify damage to forests caused by fires, disease, drought, and the like. Given a satellite image, it evaluated changes in real time.
- The authors started with images taken by satellites operated by the United States National Aeronautics and Space Administration and the European Space Agency. They used non-learning algorithms to filter out clouds, snow, and shadows.
- They computed the initial features of each pixel (a vector based on its light spectrum, each representing 30 square meters) based on a time series of 18 prior observations.
- They used a Kalman filter to update a linear model that estimated the changes in each pixel’s vector over time. Given a new observation, if the difference between the estimated and observed vector was great enough, they classified it as a disturbance. If not, they updated the model using the Kalman filter and the current observation.
- They also calculated a disturbance probability, which increased if the changes persisted over repeated observations.
Results: The authors displayed the system’s output as an overlay of yellow squares on a satellite image. Those areas track Ian’s course up the peninsula. They didn’t confirm the damage, however.
Behind the news: Similar approaches to detecting changes in satellite images have been used to assist relief efforts following a number of recent disasters. Researchers have used AI to map surviving roads that relief groups could use to reach victims, direct firefighters towards the most active areas of a woodland blaze, and scan satellite images for signs of impending volcanic eruption.
Why it matters: Satellite imagery can be a boon to responders after a disaster, but the data is often too immense for manual evaluation. AI can enable relief workers to arrive faster and work more effectively. And it’s likely that humanity will need the extra help: Natural disasters such as hurricanes, wildfires, and floods are growing more destructive as global temperatures rise.
We're thinking: We enthusiastically support the use of AI to guide relief efforts after disasters. We urge agencies that are charged with responding to integrate the technology with their plans.
A MESSAGE FROM DEEPLEARNING.AI

Want to launch an AI company? Looking for guidance on your existing startup? Join us for “Founding an AI Startup,” a panel discussion, on October 18, 2022. Speakers will share practical tips on how to get started, how to avoid common pitfalls, and more! RSVP
Food Forecaster
The ability to predict customer demand could make fast food even faster.
What's new: The Mexican-themed Chipotle restaurant chain is testing AI tools that forecast demand, monitor ingredients, and ensure that workers fill orders correctly, according to QSR Magazine, a restaurant trade publication.
How it works: Eight Chipotle locations in California will employ tools from New York-based startup PreciTaste, which offers systems designed to boost efficiency in restaurants, bakeries, and food manufacturers. On the AI menu:
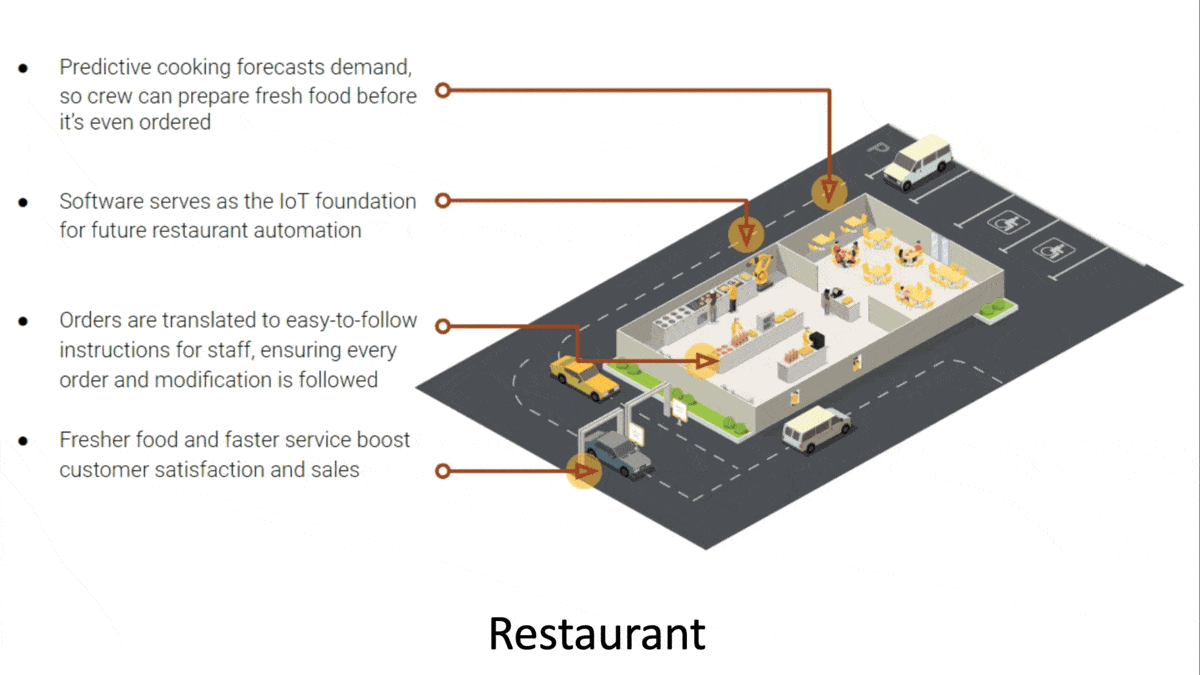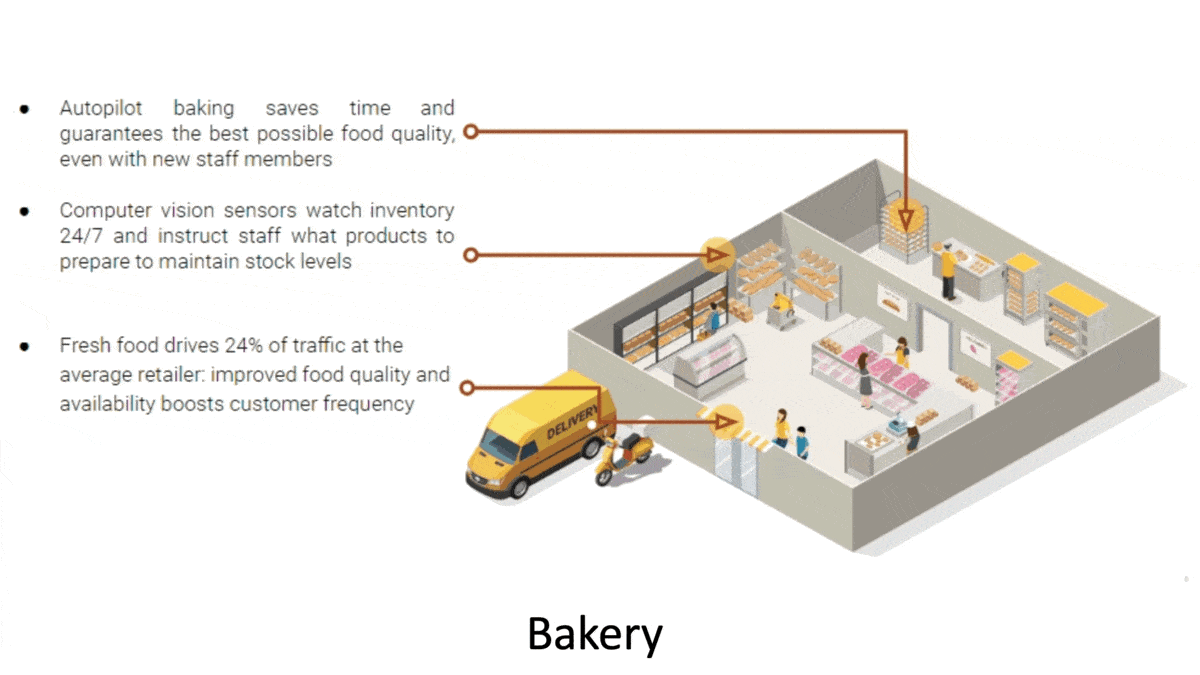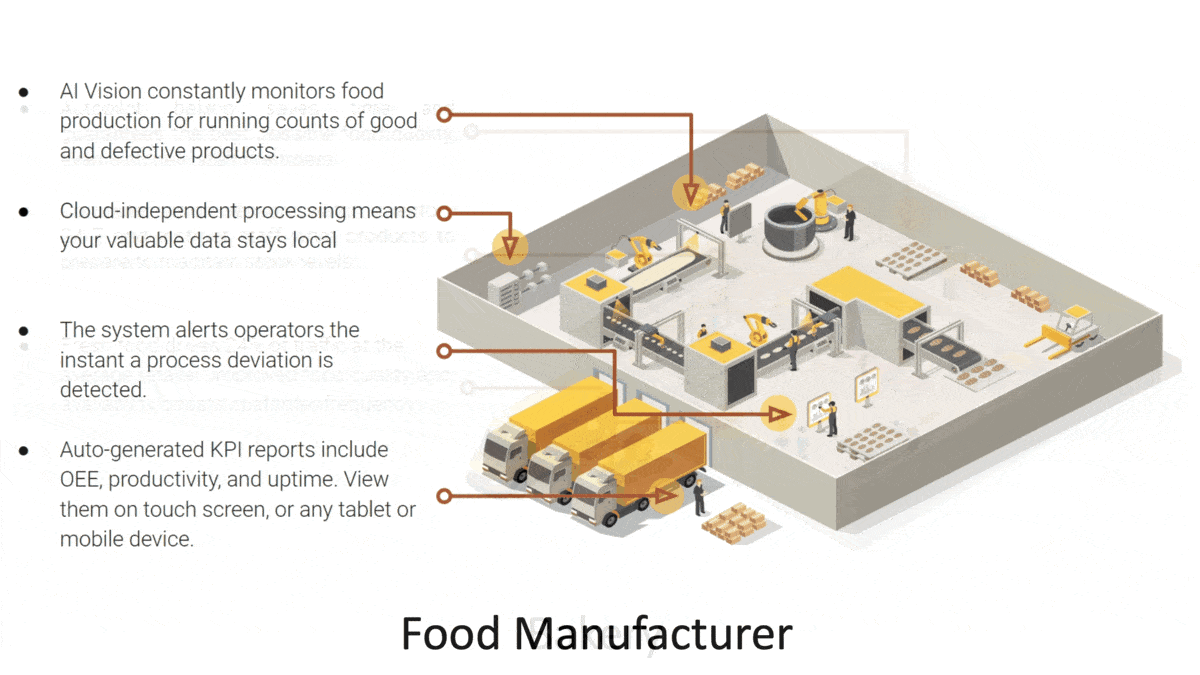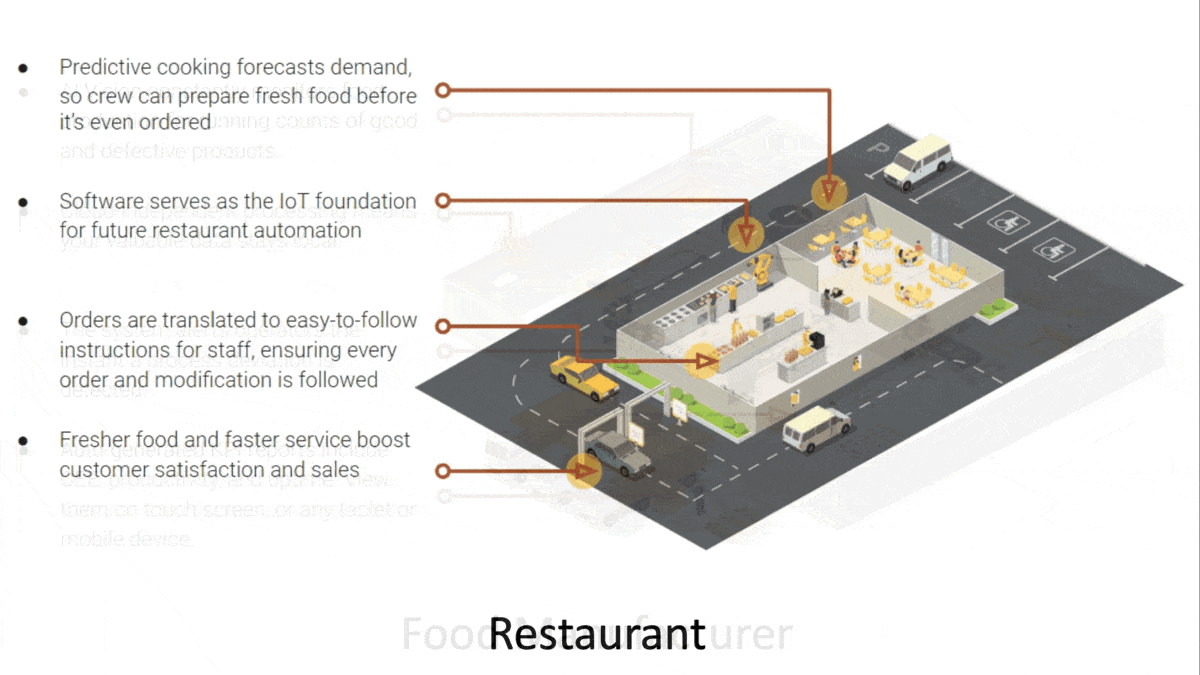
- A demand-prediction system uses computer vision to estimate foot and vehicle traffic. Combined with historical sales data, the system predicts which menu items, and how many of each, the restaurant will need to prepare. A screen display keeps kitchen staff informed.
- Other cameras track ingredient supplies and determine when menu items have sat long enough to lose their freshness. Cameras check items that go into a customer’s bag against the order. Workers receive visual and audio alerts if things go awry.
- Still other cameras monitor the drive-thru lane for traffic spikes. It alerts employees when they can prevent congestion by directing vehicles to park.
- Managers can monitor a facility’s performance via an online dashboard.
Behind the news: The fast-food industry’s focus on efficiency has made it a proving ground for a variety of AI applications.
- Checkers, a chain in the southern United States, plans to deploy a speech recognition system that will take orders at 250 of its locations by the end of 2022.
- In 2021, Israel-based Hyper-Robotics launched a pizza restaurant, approximately the size and shape of a shipping container, that automatically takes orders, cooks, assembles, and packages food.
- Restaurants including White Castle, Jack in the Box, and Panera use robots from Miso Robotics to flip hamburgers, fry chicken wings, and the like.
Why it matters: Fast-food outlets in the U.S. are facing historic shortages of labor — a ripe market for startups that aim to automate food prep. The captains of fast-food have taken notice: PreciTaste counts the CEOs of McDonald’s, Burger King, and Shake Shack among its investors.
We're thinking: It’s good to see industrial AI used to help employees do their work better rather than to do it for them. Perhaps increasingly automated eateries will spur competition to emphasize the human touch.
New Clarity on Rules for Medical AI
The United States paved the way to regulate AI systems in healthcare.
What's new: The U.S. Food and Drug Administration (FDA) interpreted existing rules that govern health-related software to include some machine learning algorithms.
What they said: The FDA requires that automated decision-making software meet the same standards as medical devices. The new guidance clarifies which AI systems fall under this designation. Manufacturers of medical devices must submit technical and performance data that demonstrate safety and effectiveness. Makers of medical devices that critically support or pose a potential risk to human life must submit laboratory and clinical trial results and gain explicit approval.
- Systems to be regulated as medical devices include those used for time-sensitive decision-making, intended to replace a healthcare provider’s judgment, or designed to provide a specific directive for prevention, diagnosis, or treatment.
- The guidance lists 34 examples of systems the FDA intends to regulate including those that analyze medical images or signals from diagnostic devices, diagnose respiratory illness, forecast risk of an opioid addiction, estimate the severity of a heart attack, and estimate the best time for a Cesarean section.
- The rules don’t cover systems that supply information without recommending care decisions. This includes systems that produce lists of diagnostic, follow-up, or treatment options; those that evaluate interactions among drugs and allergies; or those that generate patient discharge papers.
- Developers who aim to dodge the medical-device requirements must provide to regulators and users plain-language descriptions of their algorithm’s logic and methods (including machine learning techniques), data (including collection sites, demographics, and practices), and results of clinical studies.
Behind the news: The guidance seeks to comply with a 2016 law that aimed to accelerate innovation in medical devices. The American Medical Informatics Association had petitioned regulators to clarify the law on several fronts.
- The new guidance met some of their requests — for example, by explaining what should be included in plain-language descriptions and providing examples of systems that would and wouldn’t fall under the law.
- However, it apparently bypassed other requests. For instance, it failed to define the difference between software that “informs” clinical management and software that “drives” it.
Why it matters: Regulators have struggled to interpret existing frameworks for oversight with respect to machine learning algorithms, whose functioning can change with ongoing training and whose output often can’t be clearly explained. The government’s new interpretation is a substantial step toward rules that protect patients without inhibiting innovation.
We're thinking: We welcome regulation of AI systems, particularly when they're involved in life-and-death decisions. However, clarity is paramount. To the extent that the difference between words like “informing” and “driving” clinical management remains vague, the new guidance highlights the need for caution. On the plus side, it will give many AI developers a clearer target to aim for.