
Dear friends,
Last week, I wrote about key steps for building a career in AI: learning technical skills, doing project work, and searching for a job, all of which is supported by being part of a community. In this letter, I’d like to dive more deeply into the first step.
More papers have been published on AI than any person can read in a lifetime. So, in your efforts to learn, it’s critical to prioritize topic selection. I believe the most important topics for a technical career in machine learning are:
- Foundational machine learning skills. For example, it’s important to understand models such as linear regression, logistic regression, neural networks, decision trees, clustering, and anomaly detection. Beyond specific models, it’s even more important to understand the core concepts behind how and why machine learning works, such as bias/variance, cost functions, regularization, optimization algorithms, and error analysis.
- Deep learning. This has become such a large fraction of machine learning that it’s hard to excel in the field without some understanding of it! It’s valuable to know the basics of neural networks, practical skills for making them work (such as hyperparameter tuning), convolutional networks, sequence models, and transformers.
- Math relevant to machine learning. Key areas include linear algebra (vectors, matrices, and various manipulations of them) as well as probability and statistics (including discrete and continuous probability, standard probability distributions, basic rules such as independence and Bayes rule, and hypothesis testing). In addition, exploratory data analysis (EDA) — using visualizations and other methods to systematically explore a dataset — is an underrated skill. I’ve found EDA particularly useful in data-centric AI development, where analyzing errors and gaining insights can really help drive progress! Finally, a basic intuitive understanding of calculus will also help. In a previous letter, I described how the math needed to do machine learning well has been changing. For instance, although some tasks require calculus, improved automatic differentiation software makes it possible to invent and implement new neural network architectures without doing any calculus. This was almost impossible a decade ago.

- Software development. While you can get a job and make huge contributions with only machine learning modeling skills, your job opportunities will increase if you can also write good software to implement complex AI systems. These skills include programming fundamentals, data structures (especially those that relate to machine learning, such as data frames), algorithms (including those related to databases and data manipulation), software design, familiarity with Python, and familiarity with key libraries such as TensorFlow or PyTorch, and scikit-learn.
This is a lot to learn! Even after you master everything in this list, I hope you’ll keep learning and continue to deepen your technical knowledge. I’ve known many machine learning engineers who benefitted from deeper skills in an application area such as natural language processing or computer vision, or in a technology area such as probabilistic graphical models or building scalable software systems.
How do you gain these skills? There’s a lot of good content on the internet, and in theory reading dozens of web pages could work. But when the goal is deep understanding, reading disjointed web pages is inefficient because they tend to repeat each other, use inconsistent terminology (which slows you down), vary in quality, and leave gaps. That’s why a good course — in which a body of material has been organized into a coherent and logical form — is often the most time-efficient way to master a meaningful body of knowledge. When you’ve absorbed the knowledge available in courses, you can switch over to research papers and other resources.
Finally, keep in mind that no one can cram everything they need to know over a weekend or even a month. Everyone I know who’s great at machine learning is a lifelong learner. In fact, given how quickly our field is changing, there’s little choice but to keep learning if you want to keep up. How can you maintain a steady pace of learning for years? I’ve written about the value of habits. If you cultivate the habit of learning a little bit every week, you can make significant progress with what feels like less effort.
Keep learning!
Andrew
DeepLearning.AI Exclusive

Breaking Into AI: Back to Basics
Why did Lorenzo Ostano leave a job as a machine learning engineer to work in traditional software development? In this edition of our Breaking Into AI series, Ostano explains how the pivot will help him achieve his long-term goal: building enterprise machine learning systems. Learn more
News

Tracking Changes on Earth’s Surface
Computer vision systems are scanning satellite photos to track construction on the Earth’s surface — an exercise in behavior recognition on a global scale.
What’s new: Space-based Machine Automated Recognition Technique (Smart) is a multi-phase competition organized by the United States government. So far, it has spurred teams to develop systems that track large-scale construction in sequential satellite images, Wired reported.
The challenge: Barren earth, dump trucks, and large cranes are common markers of construction sites. But they aren’t always present at the same time, and they may be found in other contexts — for instance, dump trucks travel on highways and large cranes sit idle between jobs. Moreover, different satellites have different imaging systems, orbits, schedules, and so on — a stumbling block for automated classification. In the first phase of the contest, from January 2021 through April 2022, competitors built models that correlate features that were present in the same location but not at the same time, regardless of the image source.
How it works: The Intelligence Advanced Research Projects Activity (IARPA), a U.S. intelligence agency, organized the challenge.
- The agency provided 100,000 satellite images of 27 regions that range from fast-growing Dubai, where the population increased by nearly one million during that time period, to untouched parts of the Amazon rainforest. Roughly 13,000 images were labeled to indicate over 1,000 construction sites shot by multiple satellites at multiple points in time, as well as 500 non-construction activities that are similar to construction. Rather than dividing the dataset, which was made up of publicly available archives, into training and test sets, the agency split the annotations, withholding roughly labeled 300 construction sites for testing.
- The models were required to find areas of heavy construction, classify the current stage of construction, and alert analysts to specific changes. They were also required to identify features in areas of interest including thermal anomalies, soil permeability, and types of equipment present.
- The team at Kitware approached the problem by segmenting pixels according to the materials they depicted, then using a transformer model to track changes from one image to the next. In contrast, Accenture Federal Services trained its model on unlabeled data to recognize similar clusters of pixels.
Results: Judges evaluated contestants based on how they approached the problem and how well their models performed. The jury came from institutions including NASA’s Goddard Space Flight Center, U.S. Geological Survey, and academic labs.
- The judges advanced six teams to the second phase: Accenture Federal Services, Applied Research Associates, BlackSky, Intelligent Automation (now part of Blue Halo), Kitware, and Systems & Technology Research.
- In the second phase, teams will adapt their construction-recognition models to different change-over-time tasks such as detecting crop growth. It will continue through 2023
- The third phase, beginning in 2024, will challenge participants to build systems that generalize to different types of land use.
- Teams are allowed to use the systems they develop for commercial purposes, and all datasets are publicly available.
Behind the news: Satellite imagery is a major target of development in computer vision. Various teams are tracking the impact of climate change, predicting volcanic eruptions, and watching China’s post-Covid economy rebound.
Why it matters: Photos taken from orbit are a key resource for intelligence agencies. Yet the ability to see changes on Earth’s surface is a potential game changer in fields as diverse as agriculture, logistics, and disaster relief. It’s impractical for human analysts to comb the flood of images from more than 150 satellites that observe Earth from orbit. By automating the process, machine learning opens huge opportunities beyond Smart’s focus on national security.
We’re thinking: Large-scale events on Earth are of interest to all of the planet’s inhabitants. We’re glad to see that the contestants will be able to use the models they build, and we call on them to use their work to help people worldwide.

AI AI, Captain!
An autonomous research ship crossed the Atlantic Ocean — with a few pit stops to address challenges along the way.
What’s new: Built by IBM and marine research nonprofit ProMare, the Mayflower Autonomous Ship 400 (MAS400) last week completed a voyage from Plymouth, England, to Plymouth, Massachusetts.
How it works: The vessel navigates autonomously using a system based on IBM’s Operational Decision Manager, a rules-based system that integrates data from machine learning and other sources to adhere to conventions for maritime navigation. It carries no human crew, but ProMare can control it remotely if necessary.
- Six cameras equipped with computer vision detect hazards. The team trained the algorithm to recognize other ships, buoys, debris, and land using over one million nautical images.
- A separate rules-based system detects and responds to nearby ships. It considers input from cameras, radar, sonar, and transceivers that detail other vessels and charts a course in accordance with established maritime rules for avoiding collisions. A safety backstop checks this decision before the ship adjusts its course.
- The ship also gathers data for scientific purposes. Sensors measure indicators of environmental conditions such as pollution and climate change: the ocean’s temperature, salinity, acidity, fluorescence, and microplastic content. Acoustic sensors record the sounds of whales and dolphins. Accelerometers record wave energy.
Choppy waters: The passage from Plymouth to Plymouth, which originally was scheduled to commemorate the 400-year anniversary of Pilgrims who traveled from England to America to escape religious persecution, ran a year late. It was supposed to take place over three weeks in June 2021, but less than a week into the first attempt, a power issue forced ProMare to guide the vessel back to England for repairs. The second attempt lasted over two months, with two unplanned port calls in the Azores and Nova Scotia to address generator issues and battery defects.
Behind the news: Autonomous vessels are increasingly plying the seven seas.
- An autonomous cargo ship piloted by technology from Orca AI recently completed a 790-kilometer test off the coast of Japan. An autonomous cargo ship sponsored by Norwegian fertilizer giant Yara International ASA — this one all-electric — began traveling short distances along the coast of Norway in February.
- Last summer a sail-powered autonomous research ship from Saildrone mapped the sea floor as it traveled from California to Hawaii.
Why it matters: Removing the crews from ships can save space, fuel, and money. The industry has taken notice, and the International Maritime Organization is drafting rules to adapt maritime regulation for autonomous craft.
We’re thinking: Let this ship’s voyage be a lesson: You may encounter setbacks, but persist and you will arrive at your destination — schooner or later.
A MESSAGE FROM DEEPLEARNING.AI

“The Machine Learning course explained mathematical concepts, and I found the programming approach intuitive for a non computer-science major. It helped me get into a master’s degree program in data science.” — Jose Eduardo Santo. Enroll in the Machine Learning Specialization
Order in the Court
Machine learning is helping lawyers sift through mountains of documents to find evidence.
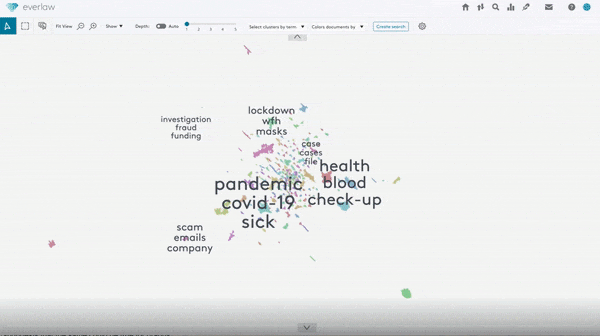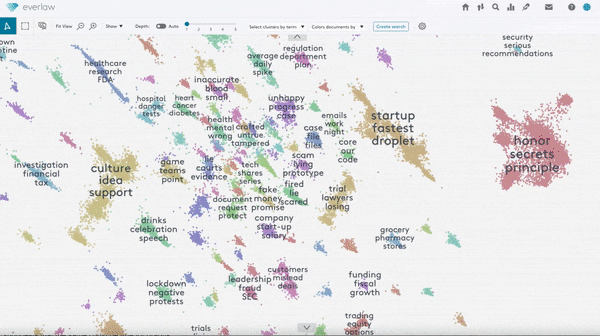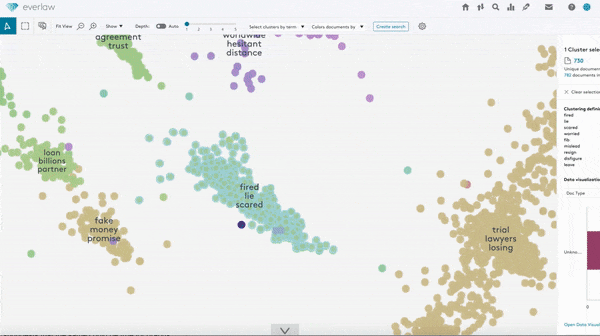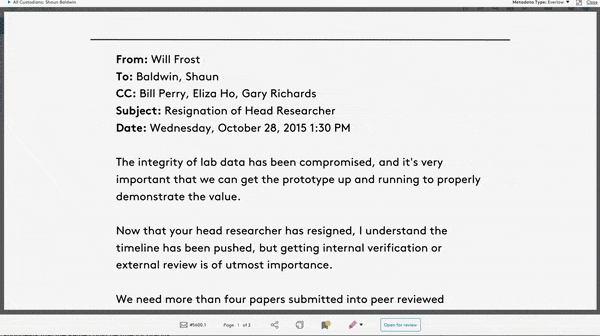
What’s new: The legal technology company Everlaw launched a clustering feature that automatically organizes up to 25 million documents for lawyers gathering evidence to be used during a trial.
How it works: The new feature analyzes text documents via unsupervised density-based clustering to build a visual map of word clouds.
- The algorithm forms clusters of at least 35 documents by analyzing the text as well as email metadata like author, subject, title, sender, recipient, cc, and bcc fields. Users can create smaller clusters or regroup documents into new clusters manually.
- Users can scroll across word clouds and zoom in and out to browse documents.
- A feature called predictive coding learns to recognize documents relevant to a given case based on user behavior.
- The software also translates documents among 109 languages.
Making headlines: Prosecutors used Everlaw’s software during the high-profile trial of Theranos co-founder Elizabeth Holmes. Among 1 million documents, they found 40 that implicated her criminal intent to defraud investors.
Behind the news: AI increasingly contributes to legal proceedings.
- Lex Machina, a legal analytics platform, forecasts how a given judge will rule on a certain case, estimates trial length, and evaluates the opposing legal team’s record.
- AI assists in intellectual property cases nearly end-to-end: CorsearchNow finds registered properties and SmartShell aids in drafting lawsuits.
- Many U.S. states perform functions such as setting bail and determining sentence lengths based on predictions made by risk-assessment tools that estimate the likelihood that a defendant will re-offend or fail to appear in court. However, these tools have been shown to exhibit bias. For instance, a 2016 investigation into Florida’s recidivism risk system found evidence of racial bias.
Why it matters: Tools that streamline the mundane, high-stakes chore of sifting through documents could help lawyers and their aides discover evidence they might otherwise overlook. This may be a boon especially for less-privileged plaintiffs and defendants, as some legal scholars have long held that the resource-intensive discovery process favors the wealthy.
We’re thinking: There’s a strong case for AI in legal practice.

Who Was That Masked Input?
Researchers have shown that it’s possible to train a computer vision model effectively on around 66 percent of the pixels in each training image. New work used 25 percent, saving computation and boosting performance to boot.
What's new: Kaiming He, Xinlei Chen, and colleagues at Facebook developed a pretraining method they call Masked Auto-Encoder (MAE). Given a fixed processing budget, MAE pretrained a larger model three times faster, resulting in higher performance in less computation than earlier methods.
Key insight: In a masked training scenario (in which portions of each training example are masked and the model learns to fill in the blanks), the larger the mask, the less computation is required. At the same time, it’s axiomatic that bigger neural networks make for better learning. Combining a very large mask with a very high parameter count should result in better performance with less computation.
How it works: A typical autoencoder uses an encoder and decoder to generate representations for use by a different model. During training, the encoder learns to create a representation of the input, and the decoder learns to use the representation to reproduce the input. The authors used transformers for the encoder and decoder, and the encoder’s parameter count was roughly an order of magnitude greater than the decoder’s. They pretrained it on ImageNet examples that had been heavily masked. Then they fine-tuned the encoder’s representations on ImageNet as well.
- Following Vision Transformer, the authors divided each training example into patches. They masked 75 percent of patches at random and passed the unmasked patches to the encoder, which produced a representation of each one.
- Given the representations, the decoder reconstructed the entire image.
- The loss function encouraged the decoder to minimize the difference between a reconstructed image and the original.
- To fine-tune the representations for ImageNet classification, the authors appended a fully connected layer to the encoder and discarded the decoder.
Results: MAE’s fine-tuned representations achieved 85.9 percent accuracy on ImageNet classification, outperforming representations learned from scratch using the same architecture (82.6 percent) and BEiT, an earlier masked training method that used less masking, a smaller encoder, and a different random masking strategy (85.2 percent). MAE trained 3.7 times faster than the same architecture without masking and up to 3.5 times faster than BEiT.
Why it matters: Given a larger model, providing less information at input is not necessarily a disadvantage. Rather, it can improve both computational efficiency and performance.
We're thinking: Would a similar design that pairs heavy masking and a plus-sized encoder boost training efficiency in large language models?