
Dear friends,
Last week, I wrote about how rising interest rates are likely to lead investors and other finance professionals to focus on short-term returns rather than longer-term investments. Nonetheless, I believe this is still a good time to invest in long-term bets on AI. Why? In a nutshell, (i) the real interest rate (adjusted for inflation) remains very low, and (ii) the transformative value of AI is more financially powerful than interest rates.
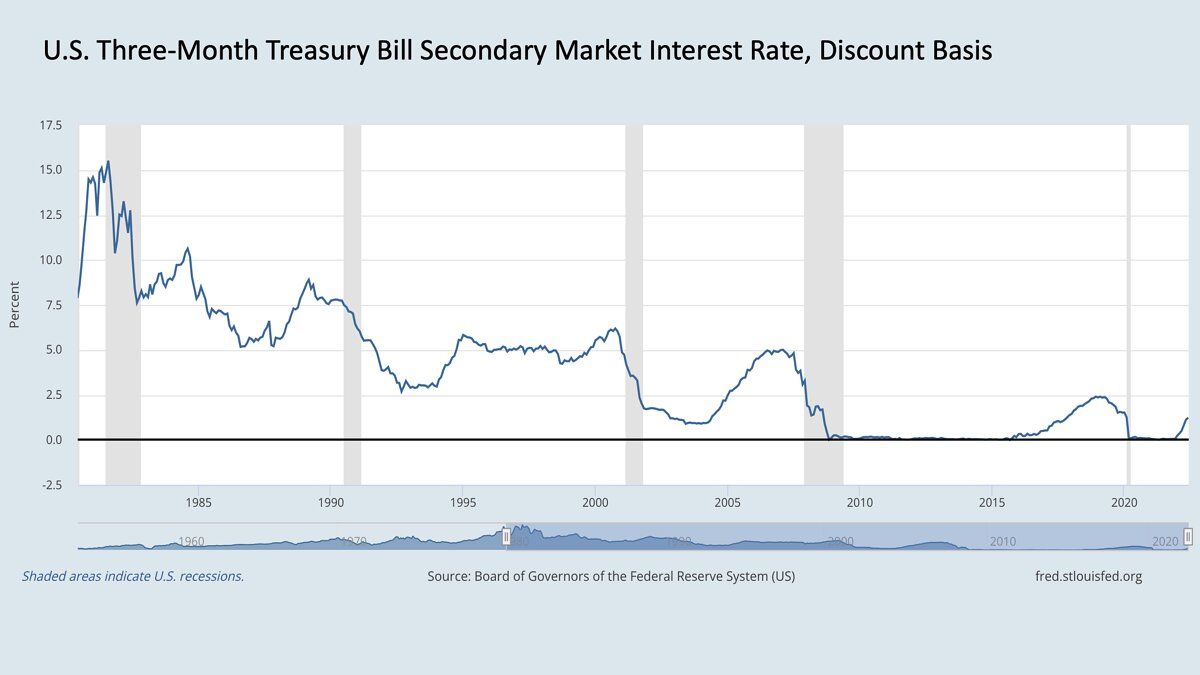
Although the news is full of rising interest rates, today’s rates are still quite low from a historical point of view. Interest rates (technically, the three-month U.S. treasury bill rate) peaked at over 15% in the 1980s. In contrast, they varied between nearly 0% and about 2.5% over the past decade.
A few percentage points of interest aren’t very significant in the face of historic gains in the value of innovative technology. Given the transformative impact of AI — which is making it possible to automate more tasks than ever — I believe that many projects will deliver returns (as measured by, say, share prices) much higher than the interest rate.
For instance, if you have an idea for a project that can create a 150% return, it matters little if interest rises by 5% and reduces the present value of your project slightly. The returns from high-risk, high-reward AI projects vary so widely — and have so much upside potential — that a modest change in interest rates should have little impact on the decision whether to go for it.
Rising interest rates aren’t the only factor that influences how we should view AI investments. Inflation is going up as well. This makes it relatively attractive to invest in building AI projects now, rather than wait and pay a higher price in the future.
Let’s say you’re debating whether to invest in a $100 GPU to speed up your work. A high interest rate — say, 10% — is a disincentive to spend the money: If you can postpone the investment, you save your $100 for a year, end up with $110 after that period, buy the GPU, and pocket the extra $10. But what if you know that inflation will cause the GPU to cost $110 in a year (10% inflation), or even $120 in a year (20% inflation)? Then it’s more attractive to spend the money now.
In fact, many people are underestimating how much inflation reduces the real cost of interest. The real interest rate, which takes inflation into account, is roughly the nominal (not adjusted for inflation) interest rate minus the rate of inflation. Because inflation is high, short-term real interest rates (technically, the risk-free rate) going out to 5 years are actually negative right now. Thus, in my view, it remains a good time to continue to make significant investments in technology that you believe will pay off.
The great investor Warren Buffet once said he tries to be “fearful when others are greedy, and greedy when others are fearful.” Current market conditions are making many investors fearful. I don’t advocate greed, but I do think for many teams this is a good time to charge ahead bravely and pursue ideas that you believe in. Just as many great companies were founded around the time of the Great Recession of 2007 to 2009, today’s economic headwinds, by sweeping away weaker projects, will clear the way for the strongest teams and ideas to leap ahead.
In case you’re wondering, I plan to put my money where my mouth is. AI Fund, the venture studio I lead, will continue to build companies with energy and enthusiasm. Even though some bets on AI will fail, I’m more concerned about aggregate underinvestment than overinvestment in AI.
I don’t advocate ignoring the market downturn. This is a good time to make sure you’re operating efficiently and your teams are appropriately frugal and have good fiscal discipline. Despite the gloomy market, I intend to charge ahead and keep building valuable projects — and I hope you will, too.
Keep learning!
Andrew
News

DALL·E 2’s Emergent Vocabulary
OpenAI’s text-to-image generator DALL·E 2 produces pictures with uncanny creativity on demand. Has it invented its own language as well?
What’s new: Ask DALL·E 2 to generate an image that includes text, and often its output will include seemingly random characters. Giannis Daras and Alexandros G. Dimakis at University of Texas discovered that if you feed the gibberish back into the model, sometimes it will generate images that accord with the text you requested earlier.
How it works: The authors devised a simple process to determine whether DALL·E 2’s gibberish has meaning to the model.
- They prompted the model to generate images that include text.
- Many of the characters produced were distorted, requiring some degree of human interpretation to read, so the authors parsed them manually.
- They fed text strings produced by DALL·E 2 back into the model, prompting it to produce a new image.
Results: The authors provide only a handful of quantitative results, but they are intriguing. They report that “a lot of experimentation” was required to find gibberish that produced consistent images.
- Asking DALL·E 2 to generate an image of “two whales talking about food, with subtitles” produced an image with the text the authors rendered as, “Wa ch zod rea.” Prompting the model with “Wa ch zod rea” produced images of seafood.
- Prompting DALL·E 2 with “Apoploe vesrreaitais” yielded images of birds and other flying creatures in most of an unspecified number of attempts.
- The prompt “Contarra ccetnxniams luryca tanniounons” resulted in images of insects around half the time and an apparently random assortment of other creatures the other half.
- “Apoploe vesrreaitais eating Contarra ccetnxniams luryca tanniounons” brought forth images of — you guessed it — birds with bugs in their beaks.
Inside the mind of DALL·E 2: Inputs to DALL·E 2 are tokenized as subwords (for instance, apoploe may divide into apo, plo, e). Subwords can make up any possible input text including gibberish. Since DALL·E 2 was trained to generate coherent images in response to any input text, it’s no surprise that gibberish produces good images. But why does the author’s method for deriving this gibberish produce consistent images in some cases, random images in others, and a 50/50 combination of consistent and random images in still others? The authors and denizens of social media came up with a few hypotheses:
- The authors suggest that the model formed its own internal language with rules that may not make sense to people. In this case, similar and dissimilar images produced in response to the same prompt would have something in common that the model discovered but people may not recognize.
- One Twitter user theorized that DALL·E 2’s gibberish is based on subword patterns in its training dataset. For instance, if “apo” and “plo” are common components of Latin bird species names, then using both syllables would yield images of birds. On the other hand, subwords of “Contarra ccetnxniams luryca tanniounons” might be related to bugs in 50 percent of occurrences in the training set and to random other animals in the rest.
- Other Twitter users chalked up the authors’ findings to chance. They assert that the phenomenon is random and unrelated to patterns in the training dataset.
Why it matters: The discovery that DALL·E 2’s vocabulary may extend beyond its training data highlights the black-box nature of deep learning and the value of interpretable models. Can users benefit from understanding the model’s idiosyncratic style of communication? Does its apparent ability to respond to gibberish open a back door that would allow hackers to get results the model is designed to block? Do builders of natural language models need to start accounting for gibberish inputs? These questions may seem fanciful, but they may be critical to making such models dependable and secure.
We’re thinking: AI puzzles always spur an appetite, and right now a plate of fresh wa ch zod rea would hit the spot!

Standout Startups
AI startups are creating high value across a wide variety of industries.
What’s new: CB Insights, which tracks tech startups, published the latest edition of the AI 100, its annual list of 100 notable AI startups. The list includes companies in healthcare, retail, transportation, finance, construction, media, and manufacturing. (Disclosure: The list includes Landing AI, where Andrew Ng is CEO, and Bearing.ai, a portfolio company of AI Fund, the venture studio that he leads.)
Early-stage stars: The authors considered 7,000 private companies headquartered around the world. They selected outstanding entries based on the factors that include number and types of investors, research and development activities, market potential, sentiment analysis of news reports, plus a proprietary score related to the startup’s target market, level of funding, and momentum.
- The authors divided the list into companies that serve a particular industry, multiple industries, and other AI developers. The largest number of companies, 10, serve healthcare. Seven companies are in the finance and insurance, and six are in retail.
- The companies have raised a total of $12 billion since 2017. Several have raised over $1 billion alone including autonomous vehicle firm Nuro and pre-trained model provider SambaNova Systems. Thirty-nine are in an early, pre-Series B stage.
- The list contains startups headquartered in 10 countries, including 73 in the U.S. The UK and Canada come in a distant second and third, with 8 and 5 entries, respectively.
Blasts from the past: Many of last year’s AI 100 continue to gain momentum. They’ve raised $6 billion in aggregate since April 2021. Six are valued at over $1 billion, and nine were acquired or offered shares to the public. (See The Batch’s coverage of the AI 100 in 2021 and 2020.)
Behind the news: CB Insights’ recent State of AI report highlighted trends among AI startups during the first quarter of 2022.
- AI firms raised around $15 billion between January and April — less than in any quarter in 2021 but still more than in any prior quarter. U.S. companies more than $9 billion, companies headquartered on the Asian continent nearly $4 billion, and European companies raised most of the rest.
- Most of the total funding went to Series A rounds or earlier. Later-stage startups, however, proceeded through Series C and D rounds more quickly than at any time since 2018.
- This year’s first quarter saw 52 exits, significantly fewer than in any of the previous three quarters.
Why it matters: The AI 100 confirms that AI is finding valuable applications beyond the technology’s stronghold among consumer-internet companies. It also highlights hot sectors for both entrepreneurs and funders. Healthcare and finance are perennial favorites among investors, while automation for warehouses and logistics receive steadily growing attention.
We’re thinking: Investors, take note: U.S. companies received the lion’s share of AI startup funding, but the rest of the world is a rich source of talent for both existing startups and those yet to be formed.
A MESSAGE FROM DEEPLEARNING.AI

Congratulations to Brigita Bizjak of Amsterdam! She’s making a positive impact on her local community as one of DeepLearning.AI’s global Pie & AI Ambassadors. Sign up to be a Pie & AI Ambassador and learn how you, too, could be featured!
Child-Welfare Agency Drops AI
Officials in charge of protecting children stopped using a machine learning model designed to help them make decisions in difficult cases.
What’s new: The U.S. state of Oregon halted its use of an algorithm intended to identify children who may benefit from intervention, The Associated Press reported. The state did not disclose the reason for the move. It came roughly one month after a similar algorithm used by the state of Pennsylvania, which inspired Oregon’s effort, came under criticism for bias.
How it works: Oregon’s Department of Human Services developed the Safety at Screening Tool to help social workers screen reports of at-risk children. Social workers were empowered to decide whether to take action with respect to any given report.
- The developers trained the algorithm on hundreds of thousands of existing child-welfare reports. The dataset included over 180 features including reports of abuse or neglect, numbers of children per report, and whether those children had been involved in previous reports.
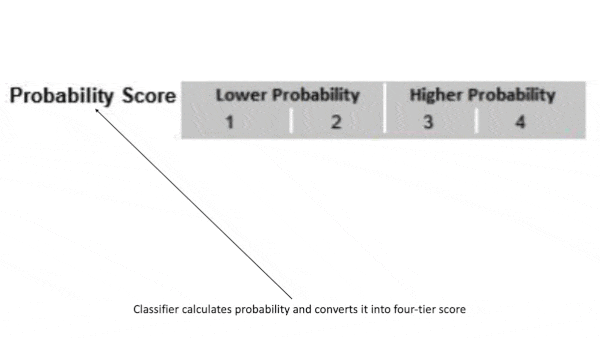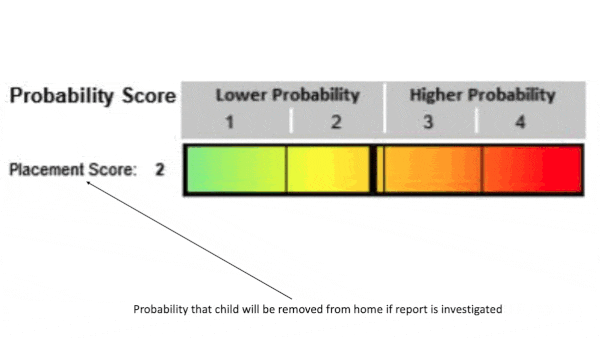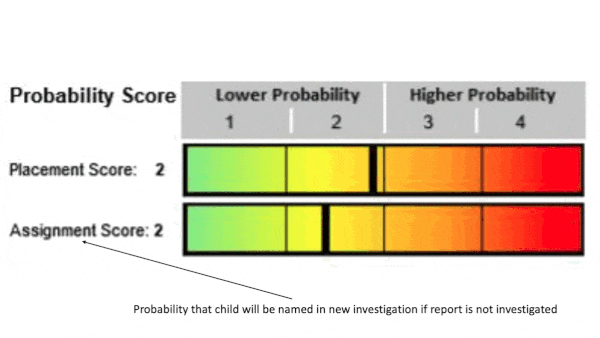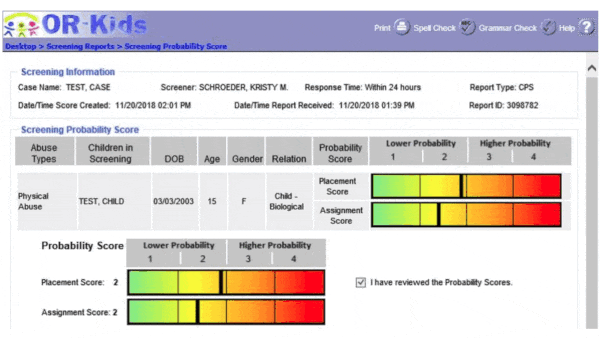
- They trained two models. One, trained on reports that had prompted an investigation, determined the probability that a child would be removed from their home within two years. The other, trained on reports that hadn’t prompted an investigation, found the probability that a child would be involved in a future investigation. At inference, the models examined a report and produced separate scores.
- The developers acknowledged that bias was inevitable but sought to mitigate it by separately modeling the probabilities of removal from a home and involvement in a future investigation, and by scoring on a scale of 0 to 100 rather than 0 to 20, the scale used in previous work.
- The department told its employees that it would stop using the tool at the end of June. An official told The Associated Press that a change in the screening process had made the tool unnecessary.
Pennsylvania’s problem: Researchers at Carnegie Mellon University found signs of bias in a similar tool used in Pennsylvania. That algorithm, which assesses the probability that a child will enter foster care within two years, is still in use.
- The researchers found that the algorithm disproportionately flagged cases involving Black children relative to their White counterparts. They also found that social workers — who were authorized to make decisions — displayed significantly less racial disparity than the algorithm.
- Officials countered that the analysis used old data and a different method for pre-processing data.
- The researchers undertook a second analysis using newer data and the officials’ recommended pre-processing steps. They reached the same conclusion.
Why it matters: Oregon’s decision to drop its learning algorithm sounds a note of caution for public agencies that hope to take advantage of machine learning. Many states have applied machine learning to ease the burden on social workers as both the number of child welfare cases has risen steadily over the past decade. However, the effort to automate risk assessments may come at the expense of minority communities whose members may bear the brunt of biases in the trained models.
We’re thinking: We’re heartened to learn that independent researchers identified the flaws in such systems and public officials may have acted on those findings. Our sympathy goes out to children and families who face social and economic hardships, and to officials who are trying to do their best under difficult circumstances. We continue to believe that AI, with robust auditing for bias, can help.

Tech Imitates Life, Life Imitates Art
The computational systems known as cellular automata reproduce patterns of pixels by iteratively applying simple rules based loosely on the behavior of biological cells. New work extends their utility from reproducing images to generating new ones.
What’s new: Rasmus Berg Palm and colleagues at IT University of Copenhagen developed an image generator called Variational Neural Cellular Automata (VNCA). It combines a variational autoencoder with a neural cellular automaton, which updates pixels based on the output of a neural network and the states of neighboring pixels.
Key insight: A variational autoencoder (VAE) learns to generate data by using an encoder to map input examples to a distribution and a decoder to map samples of that distribution to input examples. Any architecture can serve as the decoder, as long as it can reconstruct data similar to the inputs. Given a distribution, a neural cellular automaton can use samples from it to generate new, rather than predetermined, data.
How it works: VNCA generates pixels by updating a grid of vectors, where each vector is considered a cell and each cell corresponds to a pixel. The encoder is a convolutional neural network, and the decoder is a neural cellular automaton (in practical terms, a convolutional neural network that updates vectors depending on the states of neighboring vectors). The authors trained the system to reconstruct images in the MNIST dataset of handwritten digits.
- The encoder learned to map an input image to the parameters of a Gaussian distribution. The system used this distribution to produce a two-by-two matrix of cells.
- The decoder updated each cell’s state based on that of its neighbors. After the update, the system duplicated each cell into a new two-by-two matrix while pushing other cells out of the way (see diagram above). This process was repeated to fill the output pixel resolution with cells.
- VNCA applied a sigmoid to the first value of each cell’s vector to determine the probability that the associated pixel should be white or black.
- The loss function encouraged the output image to be as similar as possible to the input while also encouraging the encoder to map images to the parameters of the standard Gaussian distribution, which has a mean of 0 and variance of 1.
- At inference, the decoder received a two-by-two matrix sampled from the standard Gaussian distribution and generated a new image accordingly.
Results: The authors showed that a cellular automaton can generate images, though not very well at this point. They evaluated VNCA using log likelihoods in natural units of information (nats), which gauge similarity between the system’s output and the training data (higher is better). VNCA achieved -84.23 nats, worse than the -77 nats achieved on MNIST by state-of-the-art models such as NVAE and BIVA.
Why it matters: This work demonstrates that a neural cellular automaton can generate new images. While it shows no clear advantage of using a neural cellular automaton in a VAE, the combination might lend itself to useful applications. For instance, neural cellular automata have an inherent regenerative ability: Deface an image, and they can regrow the damaged pixels. Thus a VNCA-type approach might be useful for image inpainting. Given an image, the encoder could map it to a Gaussian distribution. Then you could damage the image where you wanted to change it, sample from the distribution, and use the decoder to generate novel pixels in that area.
Yes, but: This approach may be challenging to scale. VNCA’s decoder used only 1.2 million parameters rather than the hundreds of millions used in other high-performing decoders. Adding parameters would increase its computational cost significantly, since it updates cells repeatedly based on the states of neighboring cells.
We’re thinking: Deep learning offers a widening array of neural image generators: GANs, VAEs, diffusion models, normalizing flows, and more. While each has its advantages and disadvantages, together they amount to an enticing playground for synthesizing data and producing visual art.