
Dear friends,
Last week, Elon Musk launched a surprise attempt to acquire Twitter. The $43-billion bid was motivated, he said, by his desire to protect free speech endangered by the company’s practice of promoting some tweets while burying others. To that end, he proposes publishing the company’s ranking algorithm, the program that decides which tweets appear in a given user’s feed.
Social media companies generally keep their ranking algorithms secret. Let’s take a look at some pros and cons of letting people see what these companies are doing behind the scenes.
Why keep ranking algorithms secret?
- Keeping the algorithm secret arguably makes it harder for scammers and spammers to manipulate its output. Security through obscurity can’t be the only defense, but it is one barrier. It’s true, open source software can be highly secure because public scrutiny reveals holes to be patched. But I think there’s a difference between defending traditional software from hackers and defending a ranking algorithm from statistical manipulation. Rather than probing a live website, which may alert the security team, attackers can repeatedly probe an offline copy of the algorithm to find message formats that it’s likely to promote.
- Crucially, if the point is to enable people to understand how a learning algorithm works, then publishing it also requires publishing the data that drives it — the system’s behavior depends on both. But releasing Twitter’s data isn’t practical. One reason is the massive size of the dataset. Another is the company’s obligation to protect users’ privacy when the dataset presumably includes intimate details like user locations, interests, and times of use.
- Even if both the code and the data were available, the algorithm’s behavior would still be very difficult to analyze due to the black-box nature of machine learning.
- Proprietary algorithms confer a competitive advantage. Twitter developed its ranking algorithm at great time and expense, and it’s an important part of what differentiates the company from competitors. Publishing it would give rivals a leg up.

On the other hand, there are clear benefits to making ranking algorithms public.
- Researchers and the broader public could gain more insight into how the algorithms work, spot problems, and evaluate the provider’s neutrality. Such scrutiny would put pressure on companies to improve flawed products and, if they were to do so, raise public confidence in their services.
- Given the huge impact of these algorithms on millions of people — including, perhaps, influencing the outcomes of democratic elections — there’s a case to be made that citizens and governments alike deserve to know more about how they work.
Of course, overseeing ranking algorithms is only a small part of protecting free speech online. Some commentators panned Musk’s views on social media moderation as naive. Other social networks have been overrun by toxic communication, scams, and spam when they allowed people to post without restriction. Former Reddit CEO Yishan Wong offered insights into the difficulty of moderating social network posts in a widely read tweet storm.
Twitter has been a valuable place for the AI community to share knowledge and perspectives, and I have deep respect for Parag Agrawal and Jack Dorsey, the current and former CEOs of Twitter, who have kept their product successful through difficult changes in social media. I also applaud its ML Ethics, Transparency and Accountability team for its insightful studies. Nonetheless, Twitter has been criticized for its business performance, which has created an opening for corporate raiders like Musk and private equity firms.
Whether or not Musk’s bid is successful, the question remains: Would society be better off if internet companies were to publish their ranking algorithms? This is a complicated question that deserves more than simplistic statements about freedom of speech. My gut says “yes,” and I believe the benefit of even the partial transparency afforded by publishing the code (but not the data) would outweigh the harm. Having said that, how to secure such open-source learning algorithms, and whether demanding disclosure is fair considering the huge investment it takes to develop this intellectual property, requires careful thought.
Keep learning!
Andrew
News

How AI Ventures Spend Their Capital
AI startups are putting their cash into . . . AI startups.
What’s new: Young AI companies flush with venture capital are purchasing startups to expand the range of services they can offer, The Wall Street Journal reported.
Feeding frenzy: Venture-funded companies spent $8 billion on AI startups in 2021, up from $942 million in 2020 and $82 million in 2019, according to market analyst 451 Research. The number of acquisitions jumped from 48 to 72 in that period. The Journal focused on two chatbot deals: Gupshup’s purchase of Active.ai and Observe.AI’s acquisition of Scope.AI.
- Snapping up other companies may be a way for the acquirers to attract further investment at a time when venture funding is becoming scarce. Total investment in startups dropped by 19 percent between January 2022 and March 2022, according to CB Insights. Initial public offerings and fundraising by special-purpose acquisition companies tumbled 45 percent in the same period.
- AI startups make a ready source of engineering talent for companies looking to beef up their technical capabilities, said Jonathan Lehr, co-founder and general partner of Work-Bench, a venture investor. Startups are facing a worldwide shortage of AI engineers.
- The wave of acquisitions is also affecting startup finance departments. Early-stage companies are hiring investment bankers and corporate development specialists, according to Andrew Gazdecki, chief executive of MicroAcquire, which specializes in helping startups buy other startups.
Behind the news: All told, investors are spending more than ever on AI. Private investments in AI more than doubled to $93 billion in 2021 from $42 billion in 2019, according to the Stanford AI Index. However, they’re also becoming choosier about where they put their money. The number of newly funded AI companies worldwide fell from 1,200 to 746 between 2018 and 2021.
Why it matters: AI continues to be hot in the startup world — so hot that startups themselves want more of it. The current wave of purchases suggests that startups not only want to expand their AI holdings, they consider purchasing AI companies a strategic way to broaden their markets.
We’re thinking: Ultimately, young companies have to make money by creating long-term value, but the route may not be direct. For instance, we’ve seen self-driving car startups that have little in the way of products or revenue thrive by serving other self-driving car startups. This is part of the value of venture capital: It gives companies the time and resources they need to (hopefully) create massive value.
Neural Nets + Rules = Truer Text
A new approach aims to cure text generators of their tendency to produce nonsense.
What’s new: AI21 Labs launched Jurassic-X, a natural language processing system that combines neural networks and rule-based programs. Jurassic-X weds a large language model with modules that supply up-to-date facts, solve math problems, and process special kinds of input.
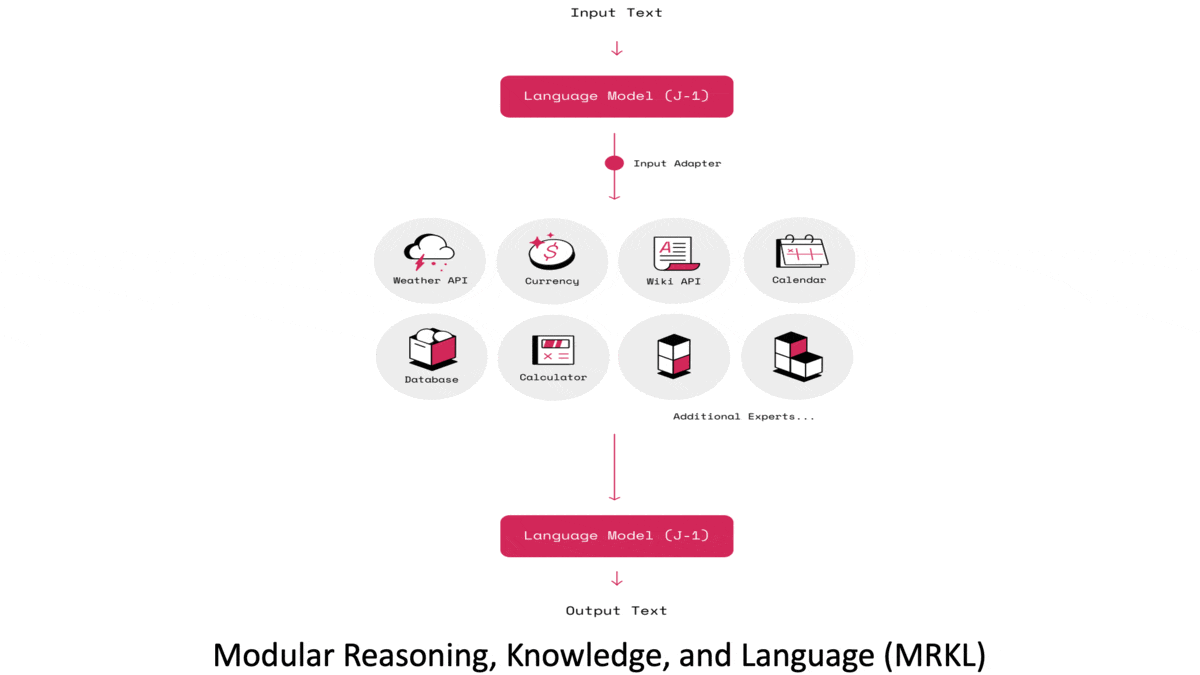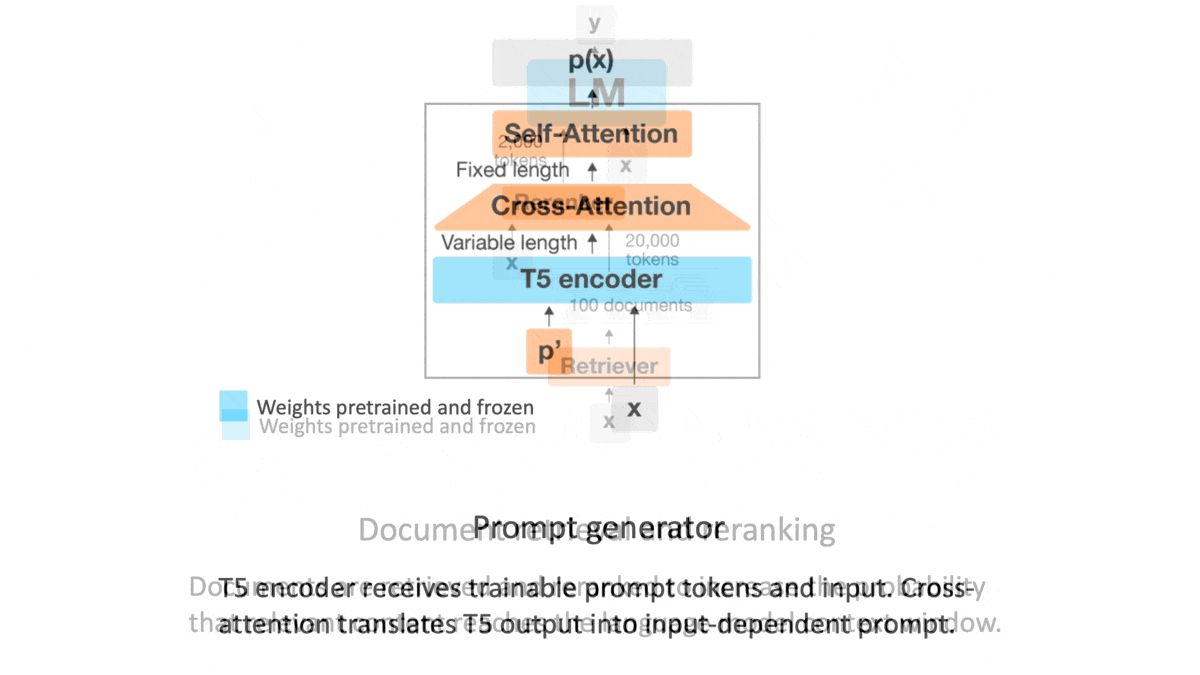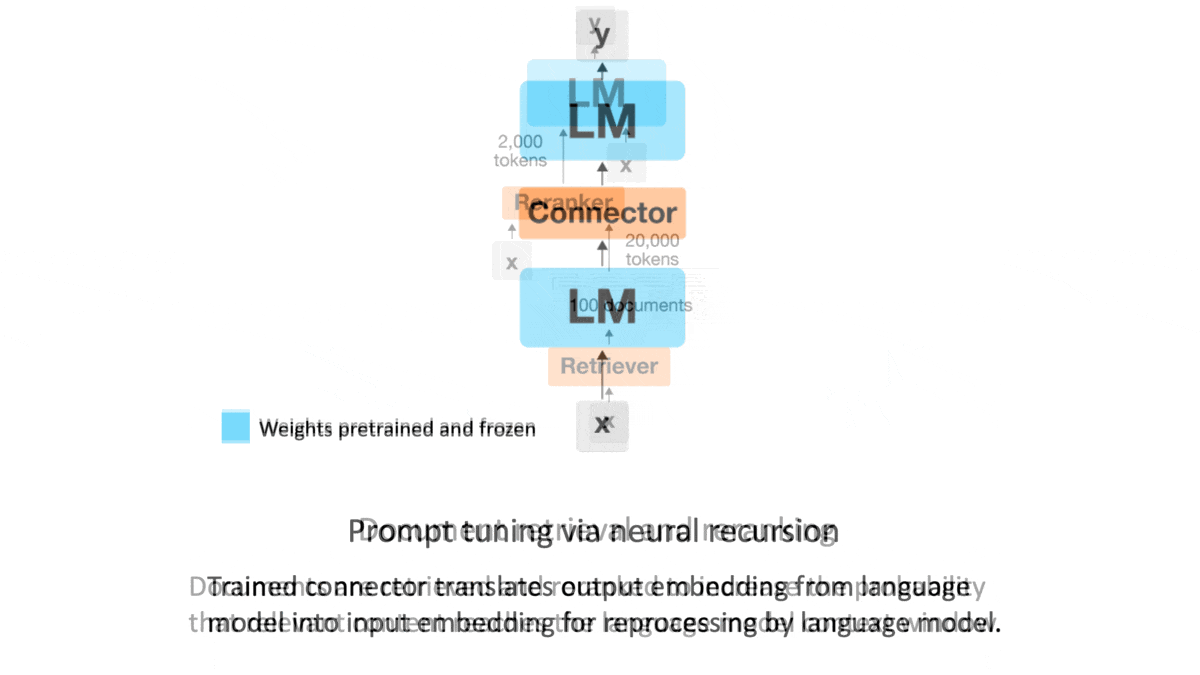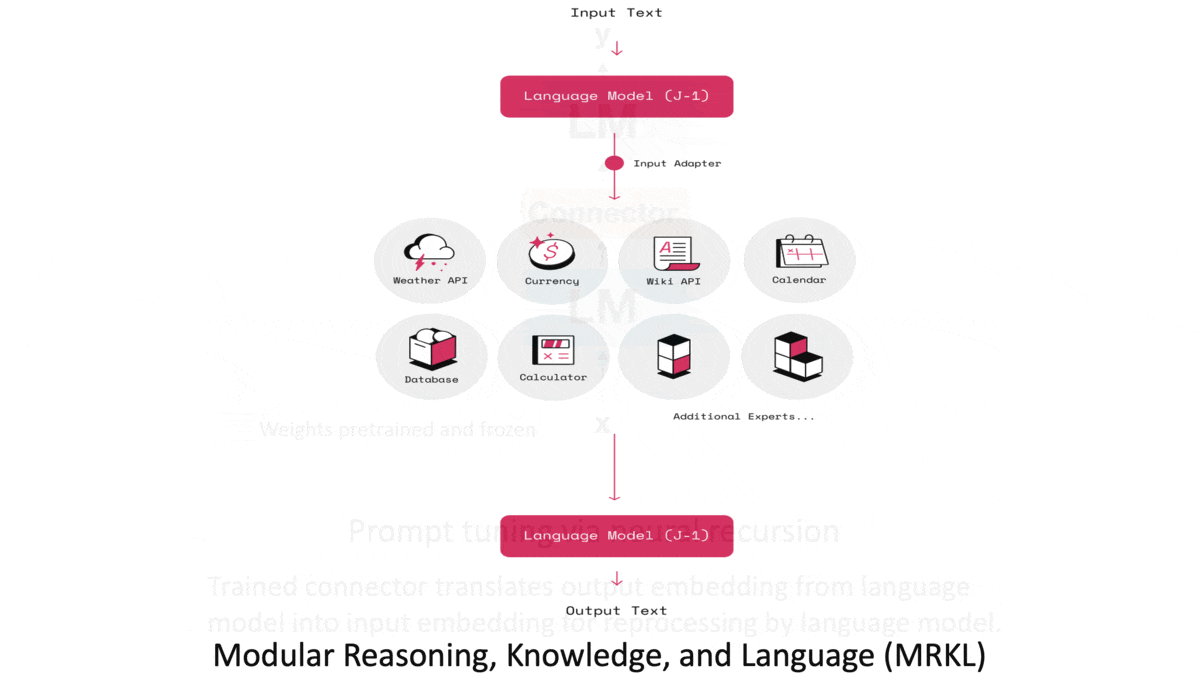
How it works: Jurassic-X is built on a software infrastructure called Modular Reasoning, Knowledge and Language (MRKL) that incorporates a variety of programs. AI21’s Jurassic-1, a large pretrained transformer model, performs general language tasks. Specialized modules include a calculator and programs that query networked databases such as Wikipedia, as well as a router that mediates among them.
- The router is a trained transformer that parses input text and selects modules to process it. It includes a so-called prompt generator, also a transformer, that adjusts the input to suit a particular module. For instance, it may rephrase input text to match a language template that Jurassic-1 performs especially well on, such as, “If {Premise} is true, is it also true that {Hypothesis}?”
- To use the calculator, the router learned to extract numbers and operators from randomly generated math expressions rendered in English, such as “what is fifty seven plus three?” or “how much is 5 times the ratio between 17 and 7?”
- Given an open-domain question, a modified passage retriever determines the most relevant Wikipedia articles and a reranker scours them for pertinent passages. It sends the passages along with the input to Jurassic-1, which answers the question.
- To fine-tune Jurassic-1’s performance in some tasks (including Natural Questions), the system feeds input to Jurassic-1, modifies the language model’s representation through a specially trained two-layer transformer, and routes the modified representation back to Jurassic-1 to generate output.
Why it matters: Current neural networks perform at nearly human levels in a variety of narrow tasks, but they have little ability to reason (especially over words or numbers), are prone to inventing facts, and can’t absorb new information without further training. On the other hand, rules-based models can manipulate meanings and facts, but they fall down when they encounter situations that aren’t covered by the rules. Combining a general language model with specialized routines to handle particular tasks could yield output that’s better aligned with the real world.
We’re thinking: Humans frequently resort to a calculator or Wikipedia. It makes sense to make these things available to AI as well.
A MESSAGE FROM DEEPLEARNING.AI
 |
Our updated and expanded Machine Learning Specialization is set to launch in June! The new specialization will cover the latest techniques and foundational AI concepts that made the original the world’s most popular machine learning course. Sign up to be notified when it’s available

More Realistic Pictures From Text
OpenAI’s DALL·E got an upgrade that takes in text descriptions and produces images in styles from hand-drawn to photorealistic. The new version is a rewrite from the ground up. It uses the earlier CLIP zero-shot image classifier to represent text descriptions. To generate images, it uses a method first described in a recent paper.
Imagination engine: Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, and colleagues at OpenAI published GLIDE, a diffusion model that produces and edits images in response to text input.
Diffusion model basics: During training, this generative approach takes noisy images and learns to remove the noise. At inference, it starts with pure noise and generates an image.
Key insight: Previous work showed that, given a class label in addition to an image, a diffusion model can generate new images of that class. Likewise, given a representation of text as an additional input, it should produce output that reflects the representation.
How it works: GLIDE used a transformer and ADM, a convolutional neural network outfitted with attention. Like DALL·E, the system was trained on 250 million image-text pairs collected from the internet. Unlike DALL·E, the authors added noise to each image incrementally to produce 150 increasingly noisy examples per original.
- During training, the transformer learned to create representations of input text.
- Given the representations and a noisy example, ADM learned to determine the noise that, when added to the previous image in the series, resulted in the current example. In this way, the system learned to remove the noise that had been added at each step.
- At inference, given a text description and noise, GLIDE determined and removed noise 150 times, producing an image.
- The authors boosted the influence of the text using classifier-free guidance. The model first determined the noise while ignoring the text representation and did it again while using the text representation. It scaled up the difference between the two noises and used the result to generate the noise to be removed.
- To edit images according to text descriptions, the authors replaced image regions with noise. The system then modified the noise iteratively while leaving the rest of the image intact.
Results: Human evaluators rated GLIDE’s output more photorealistic than DALL·E’s in 91 percent of 1,000 comparisons. They ranked GLIDE’s images more similar to the input text than DALL·E’s 83 percent of the time. The authors reported only qualitative results for the model’s ability to edit existing images, finding that it introduced objects in an appropriate style with good approximations of illumination, shadows, and reflections.
Yes, but: GLIDE’s photorealistic output comes at a cost of inference time. It took 15 seconds — far longer than GAN-based text-to-image generators, which generally take a fraction of a second.
Why it matters: Generative models typically are hard to control in an intuitive way. Enabling users to direct photorealistic image generation via natural language opens the door to broader and more widespread uses.
We’re thinking: Diffusion models are emerging as an exciting alternative among generative architectures. GLIDE’s 3.5 billion-parameter implementation (which, while very large, is roughly a quarter the size of DALL·E) is further evidence.
Algorithm as Real Estate Agent
House sales priced by algorithms account for a small but growing portion of the real estate market.
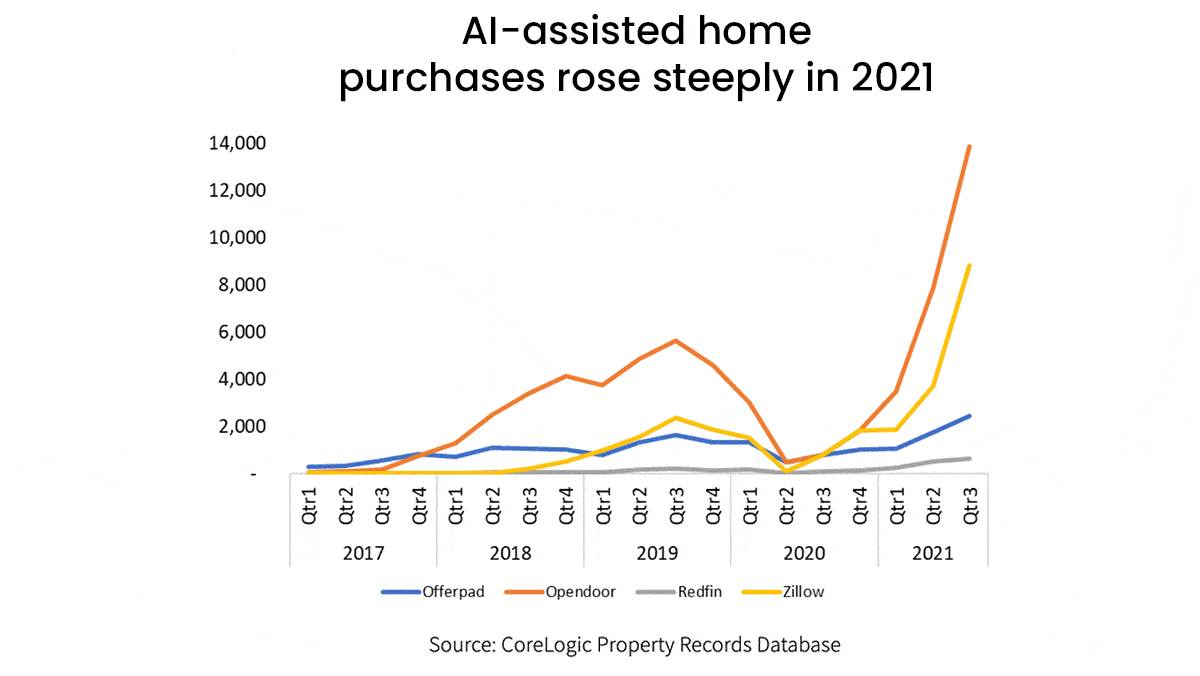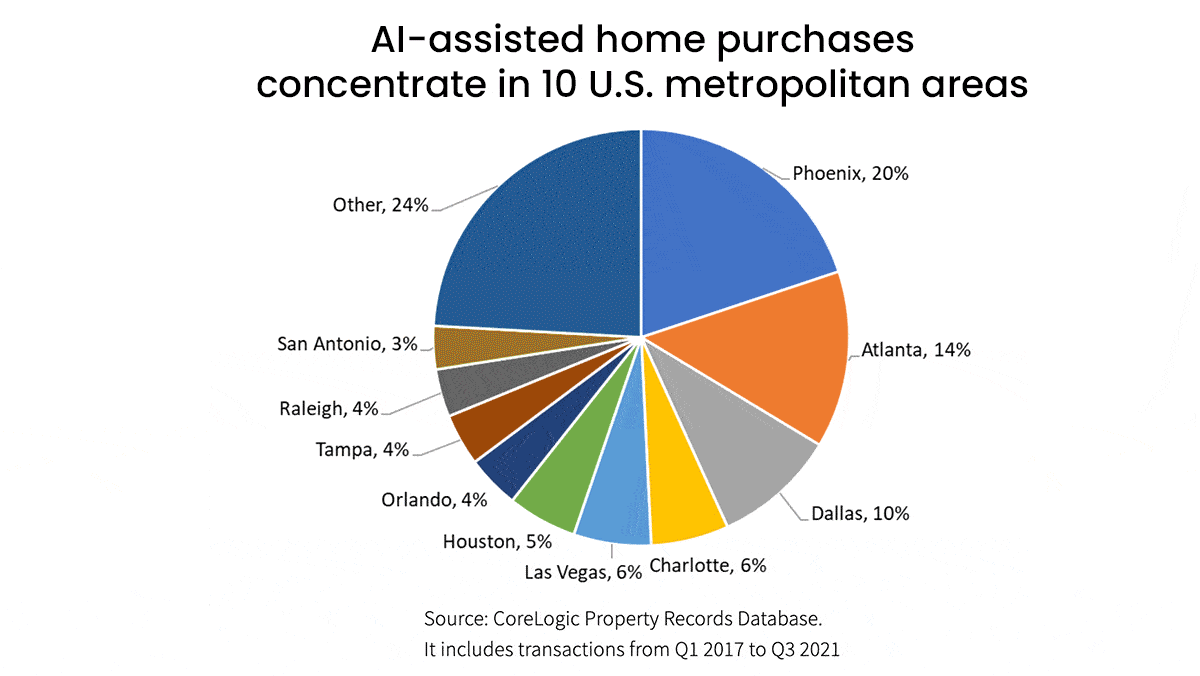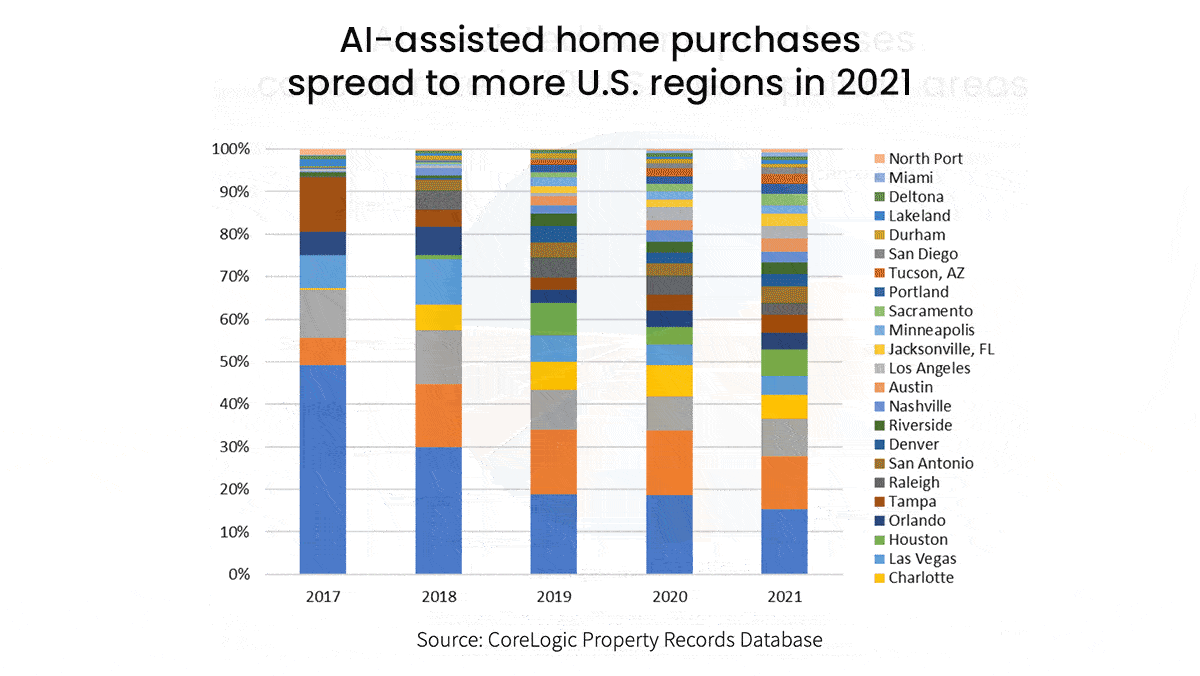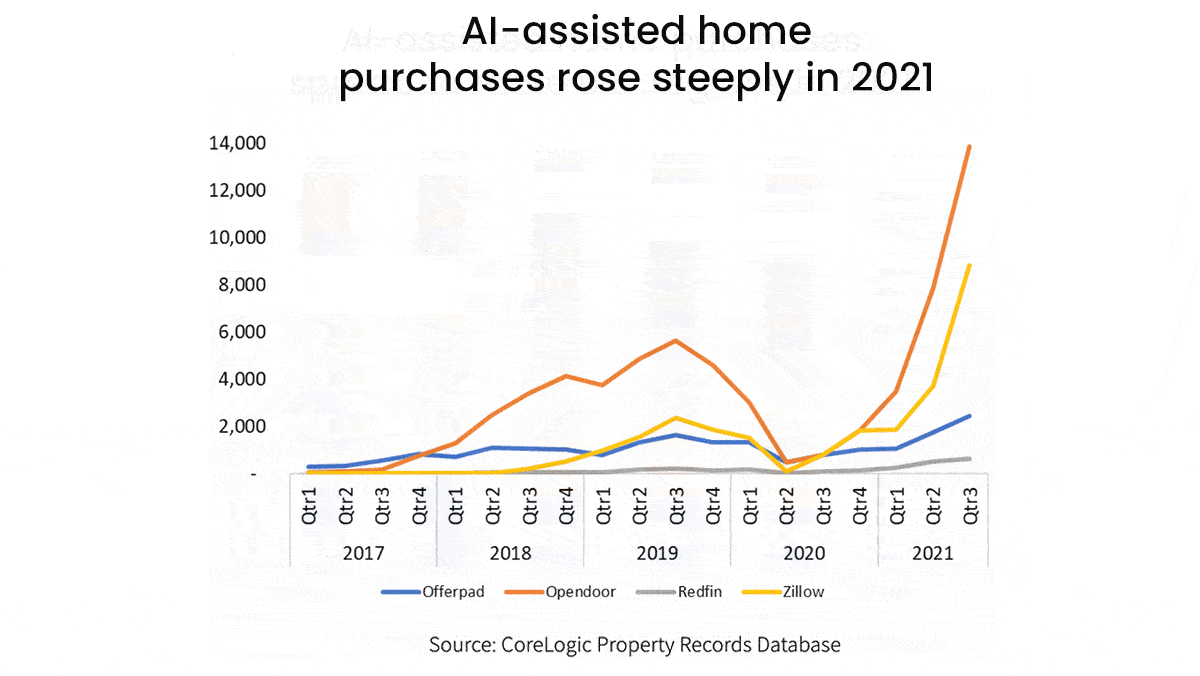
What’s new: Companies that use algorithmic pricing models to buy and sell houses, known as iBuyers, purchased around 1 percent of homes sold in the United States in 2021, roughly double the volume of such transactions in 2019, according to Core Logic, a real-estate data company. However, these deals may not benefit typical home buyers.
How it works: Unlike traditional real estate agents who determine a property’s value by considering the selling prices of similar properties nearby, iBuyers use models that estimate prices based on a variety of factors including national real-estate listings, mortgages, reviews of local businesses, and human assessments.
- The top four iBuyers accounted for 95 percent of all iBuyer purchases between 2017 and early 2021, the most recent time frame for which data is available. Opendoor bought 56 percent of those homes, Zillow 24 percent, Offerpad 18 percent, and Redfin 2 percent. (Zillow shuttered its iBuying division after incurring a huge loss amid the pandemic, which disrupted housing prices and confounded its algorithm.)
- In that time, 75 percent of iBuyer purchases took place in five states: Arizona, Texas, Florida, Georgia, and North Carolina. Their models can have difficulty estimating the value of properties that are older or atypical, so they tend to operate in cities with large numbers of newer, homogenous homes, according to CoreLogic.
- In February, Opendoor told MIT Technology Review that its model could assess homes in locales that are harder to price, such as gated or age-restricted communities, and in cities that offer more varied property types including older buildings, multiplexes, and condos, such as San Francisco.
Yes, but: iBuyers sell 20 percent of their stock to institutional investors like banks and private equity funds rather than individuals or families, according to a January analysis by Bloomberg News. These investors, in turn, often sell the houses to landlords as rental properties.
Why it matters: Automated pricing can make markets more efficient. It can also bring unintended consequences. While iBuyers pitch their services as a way to streamline the Byzantine process of selling and buying houses, they often end up funneling homes into the rental market. That can make it harder than ever for individuals and families to find an affordable home.
We’re thinking: While automated commerce may increase the market’s efficiency in aggregate, we should work to make sure that systems we design don’t inadvertently shut out some buyers.