
Dear friends,
My last two letters explored robustness and small data as common reasons why AI projects fail. In the final letter of this three-part series, I’d like to discuss change management.
Change management isn’t an issue specific to AI, but given the technology’s disruptive nature, we must pay attention to it if we want our projects to succeed. An AI system that, say, helps doctors triage patients in an emergency room affects many stakeholders, from doctors to the intake nurses to the insurance underwriters. To keep projects on track, people must be brought onboard and systems must be adjusted.
I recently saw a union block even small-scale experiments because of fear that AI would automate jobs away. This was unfortunate, because the AI system being contemplated would have made employees more valuable without reducing employment. A change management process could have made the stakeholders comfortable with experimenting and helped them understand why it was worthwhile rather than threatening.

Many engineers underestimate the human side of change management. Some tips:
- Budget enough time. Change management requires asking lots of questions, assessing how various roles will change, and explaining to many people what the AI will do.
- Identify all stakeholders. Either communicate with them directly or find ways to have colleagues talk to them. Many organizations make decisions by consensus, and it is important to minimize the odds of any stakeholder blocking or slowing down implementation. We also need to build trust among stakeholders that the AI will work.
- Provide reassurance. Where possible, explain to people how their work may change and how the new system will benefit them.
- Explain what’s happening and why. There is still significant fear, uncertainty and doubt (FUD) about AI. I have seen that providing a basic education — along the lines of the AI for Everyone curriculum — eases these conversations. Other tactics including explainability, visualization, rigorous testing, and auditing also help build trust in an AI system and convince our customers (and ourselves!) that it really works.
- Right-size the first project. If it is not possible to start with a complex deployment that affects a lot of people, consider starting with a smaller pilot (The AI Transformation Playbook includes helpful perspective on this) that affects a smaller number of stakeholders, and is thus easier to get buy in.
As we have seen with self-driving cars, building an AI system often involves solving a systems problem. That requires reorienting not only stakeholder roles and organizational structures, but also many things around the AI, like setting expectations with other drivers, pedestrians, and first responders and updating procedures around road maintenance and construction. Addressing the systems problem will increase the odds of your project succeeding.
If you understand the problems of robustness, small data, and change management, and if you can spot these problems in advance and pre-empt them, you’ll be well ahead of the curve in building a successful AI project.
Building AI projects is hard. Let’s keep pushing and share what we learn with each other, so we can keep moving the field forward!
Keep learning!
Andrew
DeepLearning.ai Exclusive

Breaking Into AI: The Smart Pitch
Nitin knew he needed to learn more to build the products he had in mind. So he took the Deep Learning Specialization and applied to jobs that would allow him to transition from web performance to machine learning. He sold LinkedIn on combining the two. Read more
News

What the Watchbot Sees
Knightscope’s security robots look cute. But these cone-headed automatons, which serve U.S. police departments and businesses, are serious surveillance machines.
What happened: Newly released documents including contracts, emails, and a company slideshow highlight Knightscope’s ability to gather information and track people. Medium’s OneZero tech website obtained the documents through a public records request and reported on their contents.
How it works: The Southern California community of Huntington Park in November 2018 agreed to pay $240,000 to lease a Knightscope unit for three years. The 300-pound K5 patrol robot, which trundles on three wheels, senses its surroundings using optical cameras, lidar, and thermal imaging:
- The robot scans passersby using face recognition software and cars using a license plate reader. It compares captured images with police databases detailing persons of interest, flags matches, and sends alerts to law enforcement personnel.
- Remote users can monitor the robot’s cameras in real time and direct it to take actions such as issuing parking violations.
- The robot passively collects signals from nearby wireless devices. The slideshow describes how such records can be used to track individuals using a device’s MAC address.
- The robot saves data it collects for two weeks, during which time police can access it through an app or download it for their own use.
Behind the news: Huntington Park’s police department is one of three in the U.S. currently using Knightscope’s robots. An unknown but rising number of private companies, including operators of shopping malls or large parking plazas, have leased the robots as well.
Why it matters: Knightscope’s data-collection and -analysis features could violate privacy restrictions and laws in some cities and states. Privacy groups like the Electronic Frontier Foundation argue that face recognition and license plate readers violate individuals’ civil rights, and wireless sniffing could raise similar questions. Face recognition technology is illegal in San Francisco, Oakland, and Somerville, MA. A number of other cities have cancelled programs to procure automated license plate readers.
We’re thinking: Automated security can save municipalities and businesses a lot of money. But we all could pay a price in civil liberties if we’re not careful about how the technology is deployed. Citizens should demand transparency from local governments about where surveillance equipment is situated and how captured data can be used and stored.
Nose Job
Predicting a molecule’s aroma is hard because slight changes in structure lead to huge shifts in perception. Good thing deep learning is developing a sense of smell.
What’s new: Benjamin Sanchez-Lengeling and a team from Google Brain, Arizona State University, and the University of Toronto developed a model that predicts a chemical’s smell from an embedding of its molecular structure.
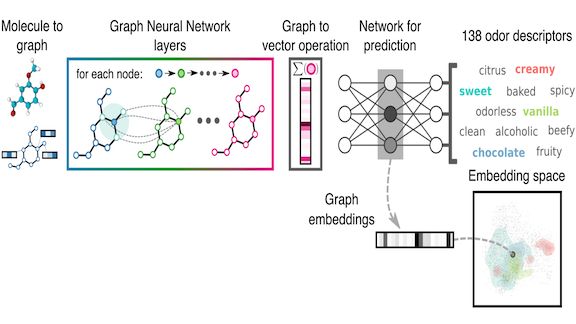
Key insight: A molecule is composed of atoms with bonds between them. Representing atoms as nodes and bonds as edges yields a graph ripe for processing by a graph neural network, or GNN.
How it works: The researchers gathered about 5,030 molecules and 138 odor descriptions, such as “fruity” or “medicinal,” from the GoodScents and Leffingwell PMP 2001 fragrance databases. They treated each description as a class in a classification task. Their model included a GNN, a component that converts graphs into vectors, and a fully connected layer that performs classification.
- The GNN takes a graph representation of a molecule as its input and learns a more information-rich graph representation. The network learns a vector that describes each node. The network’s layers update these vectors based on the values of neighboring nodes. The model converts the enriched output graph to a vector by summing the values of each node’s neighbors.
- A sequence of feed-forward layers then classifies the molecule’s odor.
- The network’s penultimate layer encodes the molecule-scent embedding, which can be used for other tasks as well. For instance, the authors applied it to the DREAM Olfaction Prediction Challenge to predict an odor’s strength (“how fruity is this smell?”) on a scale of 1 to 100.
Results: The GNN achieved a 5 percent higher F1 score than random-forest or nearest-neighbor methods trained on hand-crafted features. On the DREAM Olfaction Prediction Challenge, the authors matched the original winner’s 2015 score, even though their embedding wasn’t designed for this particular task.
Why it matters: Chemists often struggle to predict properties of molecules based on their structure. This work suggests that deep learning can aid in the effort. Beyond predicting smells, the molecule-scent embedding is suited to transfer learning for other scent-related tasks and possibly generative methods that might, say, predict molecules having a particular scent.
We’re thinking: One of the biggest challenges to building an artificial nose is not in the software, but in the hardware: How to build a sensor that can detect minute numbers of scent molecules in the air. This research could help design new fragrances, but further work in chemical sensing technology is also needed. Whoever cracks this problem will come up smelling like roses.

Researchers Blocked at the Border
Foreign researchers hoping to attend one of AI’s largest conferences were denied entry into Canada, where the event will be held. Most of those blocked were from developing nations.
What happened: This year’s Conference on Neural Processing Information Systems (NeurIPS) is being held in Vancouver, Canada, in December. The country’s Ministry of Immigration rejected visas for a number of researchers, mostly from Africa.
Gatekeeping gaffe: It’s unclear exactly how many researchers were blocked, but organizers for the conference’s Black in AI workshop said they were aware of around 30 people affected.
- Canada’s immigration ministry screens visitors for signs that indicate they might overstay their visa. The agency, for example, flags individuals from countries that are poor or at war, especially if they also have relatives living in Canada.
- NeurIPS had anticipated that attendees might experience difficulties getting through Canada’s border, and had been working with immigration officials since May to help smooth the process.
- After NeurIPs organizers complained, officials allowed 15 researchers whose visas initially were denied to enter the country. The rest are still under review.
- “While we cannot comment on the admissibility of any particular individual, we can say that, in general, all visitors to Canada must meet the requirements for temporary residence in Canada, as set out in Canada’s Immigration and Refugee Protection Act,” the ministry told the BBC by email.
Behind the news: This isn’t the first time Canada has blocked researchers seeking to attend NeurIPS. Over 100 researchers bound for last year’s event in Montreal were held back. At the 2018 meeting of the G7, Wired confronted Prime Minister Justin Trudeau over whether Canada’s immigration policy undermined its goal to become an AI powerhouse. In September, the Partnership on AI suggested a new visa category for AI researchers.
Why it matters: Conferences aren’t just opportunities tor share ideas. They’re opportunities for researchers to form important professional relationships. Policies like Canada’s keep developers from developing economies on the margins. The International Conference on Learning Representations (ICLR) is holding its 2020 conference in Addis Ababa, Ethiopia, because of the difficulty African researchers have entering places like the U.S., UK, and Canada.
We’re thinking: We encourage conferences to schedule meetings in developing nations. A global research community benefits all nations. We need to make sure the rewards of AI — and, more broadly, science — are shared fairly. Pushing hard to make knowledge accessible to all is the ethical thing to do.
A MESSAGE FROM DEEPLEARNING.AI

Want to apply sequence models to natural language problems? Learn how in Course 5 of the Deep Learning Specialization.

When Private Data is Not Private
Google spent the past year training an AI-powered health care program using personal information from one of the largest hospital systems in the U.S. Patients had no idea — until last week.
What happened: The tech giant gave the Ascension hospital network access to a system for managing healthcare information called Project Nightingale. In exchange, Ascension gave Google access to the medical records of up to 50 million patients, according to an exposé in the Wall Street Journal. The effort triggered an investigation by U.S. privacy regulators.
How it works: Google designed Project Nightingale as a machine learning tool for matching patient information with healthcare decisions. Once trained, it would suggest treatment options or additional tests and highlight suggestions for special care based on a patient’s history.
- The system would perform administrative tasks, such as reassigning doctors based on changes in the patient’s condition or special needs. It would also enforce policies to prevent unlawful prescriptions and suggest ways to generate more income from patients.
- Ascension gave Google personal information (including patient names and addresses along with the names of patients’ family members) as well as medical records such as lab results, diagnoses, prescriptions, and hospitalizations.
- Ascension didn’t inform patients or doctors that it was sharing data with Google.
- At least 150 Google employees had access to the data.
The controversy: The U.S. Health Insurance Portability and Accountability Act of 1996 (HIPAA) protects patient data from being used or shared for purposes unrelated to healthcare. The law allows providers to share data with business partners without telling patients as long as the goal is better care. Google and Ascension said Project Nightingale is intended for that purpose. However, regulators at the Department of Health and Human Services are concerned that the companies aren’t properly protecting data. They launched an investigation, which is in progress.
We’re thinking: We need Google, Ascension, and other organizations to keep innovating in healthcare. But we also need rules that are crystal clear about allowable uses of sensitive health data. When HIPAA was passed, public information about how AI works was far less available and data sharing among companies was much less common. An update is long overdue.
Beyond the Bounding Box
Computer vision models typically draw bounding boxes around objects they spot, but those rectangles are a crude approximation of an object’s outline. A new method finds keypoints on an object’s perimeter to produce state-of-the-art object classification.
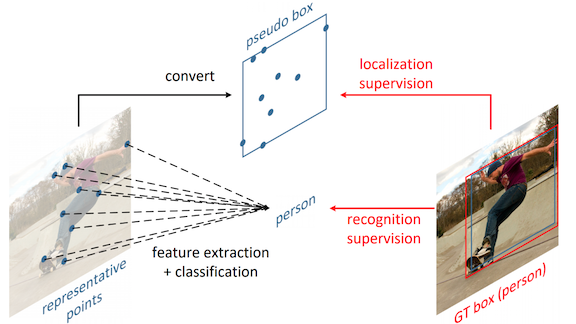
What’s new: Ze Yang and researchers from Peking University, Tsinghua University, and Microsoft Research developed a network, RPDet, that extracts what the authors call representation points, or RepPoints.
Key insights: Bounding boxes can be constructed from RepPoints, which enables RPDet to learn to derive RepPoints from bounding-box labels in standard object-recognition datasets. A good RepPoint is one that helps to answer two questions: What is the bounding box, and what object does it enclose?
How it works: RPDet uses feature pyramidal networks that extract a hierarchy of image features of varying levels of detail. From these features, it extracts a user-defined number of points as follows:
- The model starts by identifying the center point.
- It infers the remaining points from that one using deformable convolutions. Typical convolutions learn only weights, and they’re appropriate for bounding boxes because of their rectangular structure. Deformable convolutions learn offsets as well. The offsets define a custom shape, as opposed to the usual grid.
- The model constructs a bounding box around the RepPoints by finding the smallest box that contains all points. RPDet is trained via backpropagation to match bounding box corners in the training data.
- Having located objects by finding their RepPoints, RPDet classifies the objects. This additional task encourages RPDet to identify important locations on an object and avoid fixating on bounding-box corners.
Results: Processing image features supplied by a ResNet, RPDet achieved a 2 percent boost in classification accuracy over bounding-box representations. Further, RPDet achieves a new state of the art for precision on COCO, an object detection and classification dataset, with 4 percent improvement in average precision over the alternatives considered.
Why it matters: This technique encodes relatively detailed information about object shapes that could be useful in a variety of tasks. For instance, RepPoints’ implicit estimation of poses could help predict the trajectory of a moving object.
We’re thinking: Plenty of applications, including face recognition, find explicit predefined keypoints. But they tend to be specialized for specific types of objects, such as finding the eyes, nose, and mouth on faces. RepPoints encode arbitrary geometry and pose information for a wide range of shapes, giving them a potential role in applications that otherwise wouldn’t be feasible.