
Dear friends,
I’ve always thought that how you treat those who are powerless shows your true character. People rarely mistreat others who have power over them -- for example, their boss — because they might suffer adverse consequences. But when you encounter someone whom you can either push down or lift up, with no risk of harm or possibility of gain, your choice reveals your character.
Similarly, the way a nation treats those with less power — specifically refugees — shows its character. As Russia continues to attack Ukraine, millions of refugees are streaming across Europe. They join refugees from Afghanistan, Syria, Congo, Myanmar, Iraq and other nations in seeking safety. I’ve been heartened by news that Poland, Romania, Moldova, Hungary, Germany, France, Ireland, the United Kingdom and other countries are offering them a safe haven. I hope the U.S. will open its doors wider to all refugees.
Historically, refugees have made rich contributions to their host nations. The U.S. would have been a very different country without Albert Einstein, Madeleine Albright, and Sergey Brin, all of whom were refugees. Countries that welcome refugees today may find tomorrow that they’ve adopted the next Einstein, yielding great prestige and prosperity.

Of course, integrating refugees is not a trivial matter. They must adjust to a new home, their host country must adapt to a more diverse population, and local people may worry about competition for jobs and resources. But the need to welcome people fleeing for their lives is pressing. Surely we can find it in ourselves to share with those who have lost everything.
Treating people well regardless of their power should be a key part of building in AI as well. I would love to see the AI community assist displaced Ukrainian engineers. At the same time, let’s help Russian engineers who don’t support the war and want to emigrate and build a new life in a different country.
When developers write software, there’s an economic temptation to focus on serving people who have power: How can one show users of a website who have purchasing power an advertisement that motivates them to click? To build a fairer society, let’s also make sure that our software treats all people well, including the least powerful among us.
Keep learning!
Andrew
P.S. I just spoke at Nvidia’s GPU Technology Conference about data-centric AI, where I showed the first public demo of data-centric features of LandingLens, an MLOps platform for computer vision built by my team at Landing AI. A highlight for me came during the question-and-answer session, when my friend Bryan Catanzaro, Nvidia’s vice president of applied research, mentioned that the company’s cutting-edge Deep Learning Super Sampling project, which applies deep learning to graphics, uses a data-centric approach. The neural network changes rarely but the team improves the data! You can register for conference and watch a video of the presentation here.
News

Who Needs Programming?
The next killer AI application may be developed by someone who has never heard of gradient descent.
What’s new: A rising generation of software development platforms serves users who aren’t familiar with AI — and even programming. The New York Times surveyed the scene.
Robocoders: Using no-code AI platform — an automated programming tool that either generates new code or customizes pre-existing code according to user input — generally requires access to a web browser and training data. From there, a user-friendly interface lets users train a prebuilt architecture.
- Teachable Machine from Google (pictured above) and Lobe from Microsoft make building vision models a point-and-click process. Users supply training images.
- Power Platform and AI Builder, both from Microsoft, are aimed at business users who want to process text in documents and images.
- Juji enables users to build chatbots by choosing from a list of topics and question-and-answer pairs.
- Akkio helps users build models that predict business outcomes from spreadsheets. For instance, Ellipsis, a marketing company, uploaded a spreadsheet of keywords, blog titles, and click rates to train a model that predicts which words and phrases rank highly in Google search results.
- Amazon Sagemaker offers Canvas, which is designed to help business analysts derive insights from data.
- eBay deployed proprietary low-code and no-code AI tools internally, enabling nontechnical employees in areas like marketing to roll their own models.
Behind the news: Similar tools for building non-AI applications like websites (Wordpress), ecommerce stores (Shopify), and video games (RPG Maker) undergird a significant portion of the online economy. OpenAI and DeepMind offer natural language tools that write code using plain-English prompts. Source AI, available in a beta-test version, extends such auto-coding functionality to French, German, and Spanish to generate programs in at least 40 languages.
Why it matters: Platforms that automate coding, data collection, and training are an important part of AI’s future. Although no-code AI tools are still maturing — for example, they’re limited to particular tasks and some aren’t yet suitable for commercial-grade applications — they’re on track to open the field to a far broader range of users, enabling them to apply tried-and-true approaches to certain classes of problems. And they may be useful to experienced AI developers, too. For instance, trained engineers may also use them to build wireframe versions of more intensive projects.
We’re thinking: No-code tools have a long way to go, and even when they get there, education in AI technology will be necessary to handle difficult problems, high-stakes situations, and cutting-edge developments. Skilled engineers will exceed the capabilities available at the press of a button for the foreseeable future.
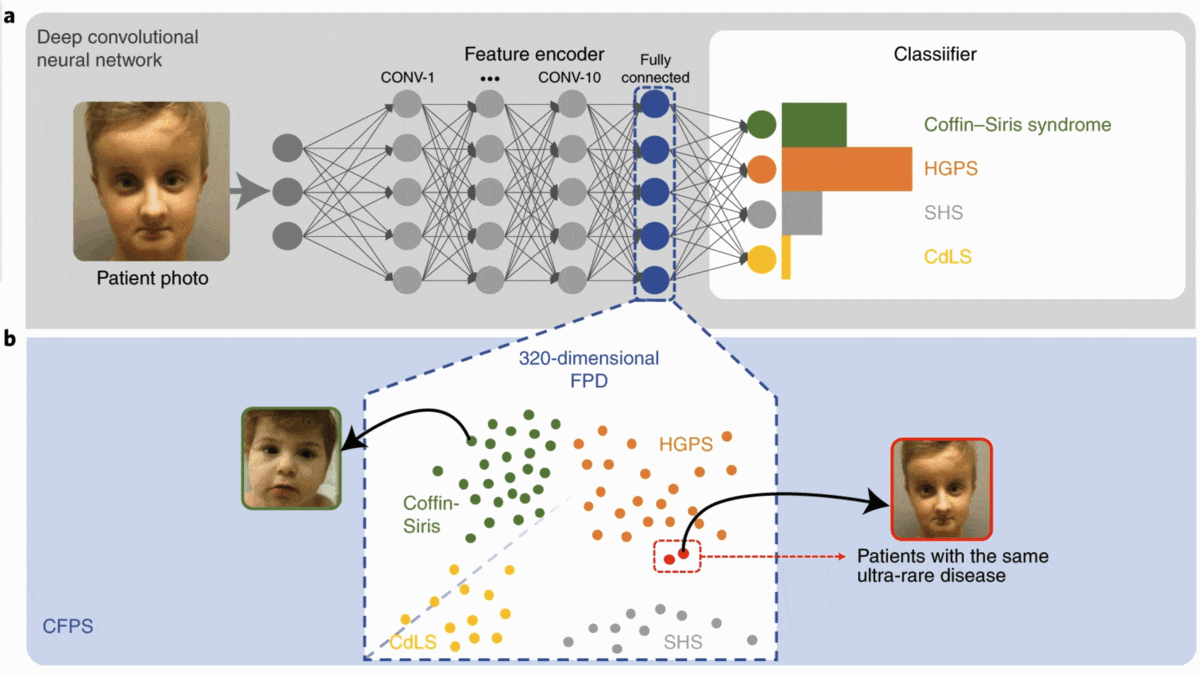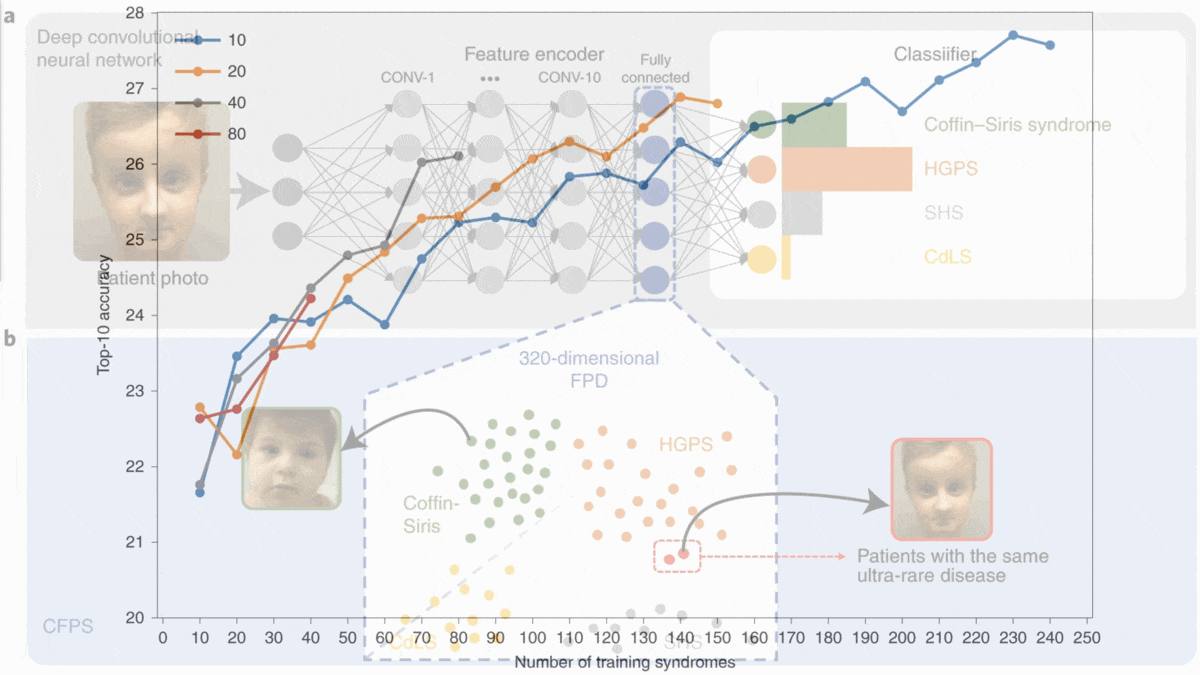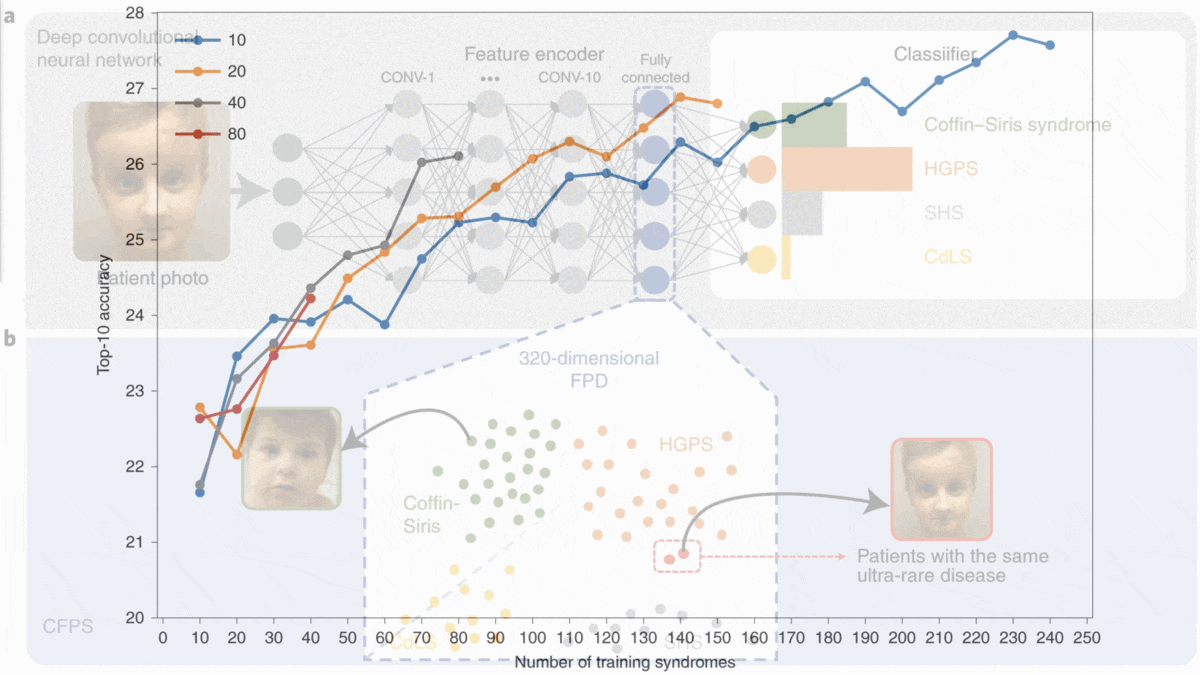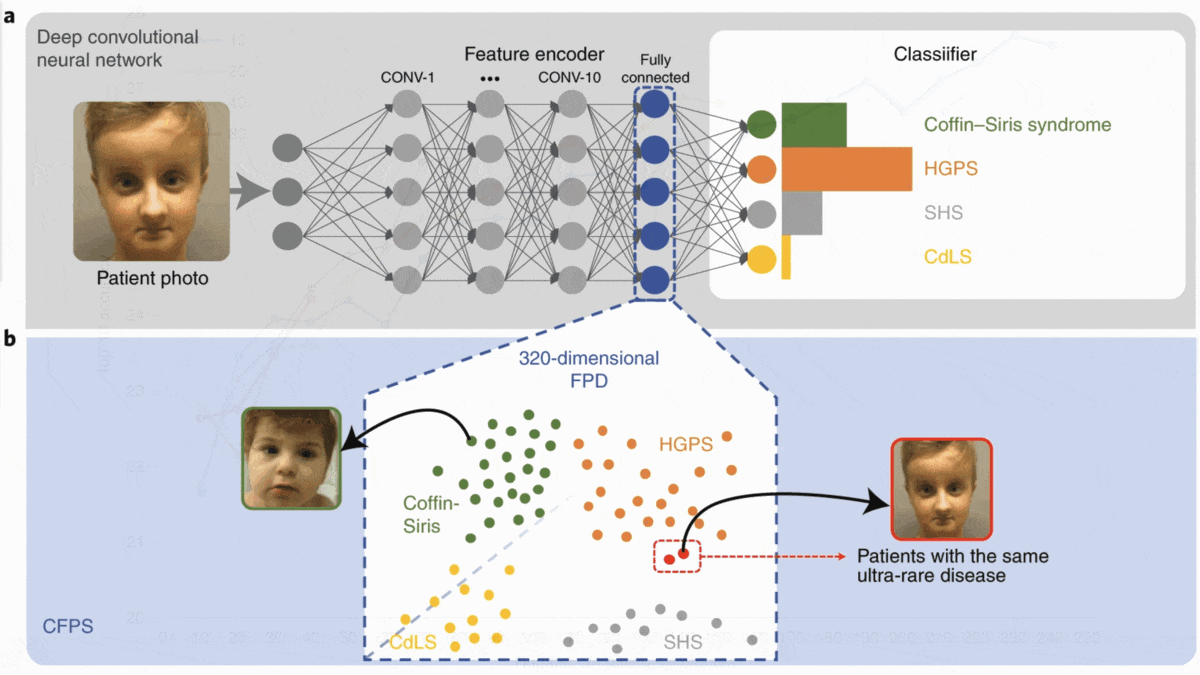
The Many Faces of Genetic Illness
People with certain genetic disorders share common facial features. Doctors are using computer vision to identify such syndromes in children so they can get early treatment.
What’s new: Face2Gene is an app from Boston-based FDNA that recognizes genetic disorders from images of patients’ faces. Introduced in 2014, it was upgraded recently to identify over 1,000 syndromes (more than three times as many as the previous version) based on fewer examples. In addition, the upgrade can recognize additional conditions as photos of them are added to the company’s database — no retraining required.
How it works: New work by Aviram Bar-Haim at FDNA, Tzung-Chien Hsieh at Rheinische Friedrich-Wilhelms-Universität Bonn, and colleagues describes the revised model.
- Face2Gene’s underpinning is a convolutional neural network that was pretrained on 500,000 images of 10,000 faces and fine-tuned on proprietary data to classify 299 conditions such as Down syndrome and Noonan syndrome.
- The developers removed the trained model’s classification layer to output a representation of each input face. They fed the model around 20,000 images labeled with 1,115 syndromes and stored their representations.
- Presented with an unfamiliar face, the model calculates the cosine similarity between the new representation and those in the database.
- It ranks the top 30 most similar representations. Their labels yield a ranked list of possible diagnoses.
Results: In tests, the new version proved somewhat less accurate than its predecessor at recognizing the 91 syndromes pictured in the London Medical Database. It ranked the correct syndrome in the top 30 possibilities 86.59 percent of the time versus the earlier version’s 88.34 percent. However, it was able to identify 816 conditions that its predecessor couldn’t, ranking the correct one in the top 30 possibilities 24.41 percent of the time and in the top position 7.07 percent of the time. (The chance of choosing the correct syndrome randomly was 0.09 percent.)
Why it matters: Some 350 million people worldwide live with a rare genetic disorder. Such conditions are especially difficult to diagnose because they’re so numerous, and many doctors never encounter a case. Face2Gene, which reportedly is used by thousands of geneticists, has been credited with making the job much easier.
We’re thinking: Humanity has a sad history of judging people based on appearance. While this model is designed for healthcare professionals to evaluate children who may need medical treatment, we caution against trying to use AI to classify an individual’s traits such as intelligence, character, or sexual preference based on their looks.
A MESSAGE FROM DEEPLEARNING.AI
.png?upscale=true&width=1200&upscale=true&name=The%20Batch%20Image%201%20(2).png) |
Looking to build or customize powerful real-world models to solve difficult problems? Check out the TensorFlow: Advanced Techniques Specialization! Enroll today

Stock-Trading Test Bed
If you buy or sell stocks, it’s handy to test your strategy before you put real money at risk. Researchers devised a fresh approach to simulating market behavior.
What's new: Andrea Coletta and colleagues at Sapienza University of Rome used a Conditional Generative Adversarial Network (cGAN) to model a market’s responses to an automated trader’s actions.
Key insight: Previous approaches tested a simulated trader in a virtual market populated by other simulated traders. However, real-world markets tend to be too complex to be modeled by interactions among individual agents. Instead of simulating market participants, a cGAN can model aggregated sales and purchases in each slice of time.
Conditional GAN basics: Given a random input, a typical GAN learns to produce realistic output through competition between a discriminator that judges whether output is synthetic or real and a generator that aims to fool the discriminator. A cGAN works the same way but adds an input — in this case, details about individual buy and sell orders and the overall market — that conditions both the generator’s output and the discriminator’s judgment.
How it works: The authors built a simulated stock exchange based on the Agent-Based Interactive Discrete Event Simulation (ABIDES) framework to match buy and sell orders. They trained a cGAN to generate such orders based on two days of market data for Apple and Tesla stocks. Then they added orders by an independent trader.
- The authors simulated the stock market as a whole by connecting these components in a feedback loop. The first time through the loop, the exchange received historical buy and sell orders; subsequent times, it received orders from the agent and/or the cGAN.
- The exchange paired offers with purchases. Then it sent details for each order (price, volume, buy or sell, and time since the previous trade) and the market as a whole (best price, highest volume, average price, and time when the details were calculated) to the cGAN.
- Given the details provided by the exchange, the cGAN generated a new order along with a wait time. After waiting, it passed the order to the exchange, which triggered the cGAN to generate another order.
- For a half-hour within a period of several hours, an independent agent sent its own purchases to the exchange. In each of 30 minutes, it observed the trading volume and issued a buy order based on its observation. The authors set the volume: 1, 10, or 25 percent of the observed volume.
Results: The authors checked statistical similarity between historical and cGAN orders in terms of price, volume, direction (buy or sell), and frequency distributions. In particular, they looked at Tesla shares on May 2 and May 3, 2019, and plotted the distributions. The real and synthetic distributions matched fairly closely. When they ran the simulation using historical orders plus cGAN orders, the price rose slightly during the 30 minutes when the agent would have been active. Given the orders generated by the cGAN and the agent, the price rose by an order of magnitude more and returned to normal shortly after the agent stopped trading, demonstrating the simulation’s response to the agent’s activity.
Why it matters: GANs are usually associated with image generation. This paper adds to a growing body of research showing that they can successfully generate data outside of perceptual domains.
We're thinking: Supervised learning tends to apply when a specific output y can be predicted from a given input x. In applications where y is a complex data type that’s also inherently stochastic — such as a sequence of market trades or a future weather map — we might try to model y using a stochastic process rather than attempt to learn one correct answer. cGANs appear to be emerging as a promising approach.

AI: A Progress Report
A new study showcases AI’s growing importance worldwide.
What’s new: The fifth annual AI Index from Stanford University’s Institute for Human-Centered AI documents rises in funding, regulation, and performance.
What it says: The authors based their report on academic and conference publications as well as public datasets.
- Private investment in AI more than doubled from $42.2 billion in 2020 to $93.5 billion in 2021. The bulk of the money — $76.5 billion — came from China, the European Union, and the United States. It reached fewer recipients than in previous years: The number of new AI companies dropped from over 4,000 in 2017 to less than 750 in 2021.
- Regulation is on the rise. Fifty-five AI-related laws have been enacted by 25 key countries since 2015. Eighteen were passed in 2021.
- Despite simmering geopolitical tensions between the U.S. and China, in 2021, more than 9,000 publications came from teams that included members in both countries, a fivefold increase since 2010.
- Training times and costs are falling for a wide range of tasks including image classification, object detection, and language processing. Image classification models were 63.3 percent less costly and 94.4 percent faster to train in 2021 than 2018.
- Conferences focused on AI ethics received five times as many paper submissions in 2021 as they did in 2014. The percentage of ethics papers submitted by private-sector researchers during that period rose by 71 percent, reflecting mainstream adoption of ethical concerns.
Behind the news: Previous editions of the AI Index highlighted important inflection points in the industry’s growth.
- In 2021, the report highlighted the growing share of newly-minted doctoral degrees in AI. Foreign students made up a growing majority of U.S. PhDs, and China surpassed the U.S. in journal citations. It also highlighted the rapid adoption of AI-driven surveillance.
- The 2020 report recognized the U.S. and China as unquestioned global leaders in AI research and projected that China would eclipse other nations.
Why it matters: The boom in private investment and spike in laws that regulate automation signal the same fundamental trend: AI is increasingly central to the forces that drive society.
We’re thinking: We can confirm a further trend: the rising volume of reports on AI trends!