
Dear friends,
If you want to build a career in AI, it’s no longer necessary to be located in one of a few tech hubs such as Silicon Valley or Beijing. Tech hubs are emerging in many parts of the world, and cities large and small offer opportunities both for local talent and companies worldwide.
Colombia is an inspiring example. In 2019, several of my teams (including Landing AI and other AI Fund portfolio companies) made a bet on Latin America. I set up an engineering hub in Medellín, Colombia, because I was impressed by the tech scene, educational institutions, enthusiastic engineers, and supportive partners we found there. (You can see in the photo below what a good time we had there! Non-Spanish speakers: Can you read the phrase on the t-shirts?)
Judging by record venture investments and successful IPOs in Latin America, the secret is out about the caliber of the region’s technical talent, entrepreneurial spirit, and ability to build high-quality systems. For U.S. teams, in particular, its proximity in terms of time zones and geography makes it one of the most interesting emerging ecosystems in tech. Several AI Fund portfolio companies now have a significant presence there.
Our fastest-growing Latin American team is Factored, which helps companies build world-class AI and data engineering teams. Factored’s Latin American operation grew from 24 engineers to well over 100 in the past year. Its projects have ranged from developing MLOps pipelines for one of the largest financial-tech companies in Silicon Valley to presenting papers at NeurIPS.
 |
The rise of opportunities in Latin America is part of the broader trend toward working from home. I can collaborate as easily with someone in Palo Alto, California, as with someone in Buenos Aires, Argentina. In fact, I’ve been spending more time in Washington State (where I enjoy the benefit of free babysitting by my wonderful in-laws) instead of my Palo Alto headquarters.
Remote work highlights a fact that should have been obvious: Talent is everywhere, even if access to opportunity has not been. Whatever city you live in, today you’ll find more opportunities than ever to learn, find an exciting job, and do meaningful work.
It has been over two years since I visited Colombia. While I appreciate the excellence of Colombian engineers, I also love the local culture. I enjoy the sculptures of Fernando Botero, and bandeja paisa is a favorite dish that I haven’t managed to find in the U.S. I hope the pandemic will allow me to return before long.
No matter where you’re located, I will continue to think about how DeepLearning.AI can do more to support you in developing your talent and building the career you want.
Keep learning!
Andrew
News
 |
Machine Learning Jobs on the Rise
Jobs for machine learning engineers are growing fast, according to an analysis by LinkedIn.
What’s new: Machine learning engineer ranks fourth among the 25 fastest-growing job titles in the United States, according to the professional social network’s annual Jobs on the Rise report. (The top three were vaccine specialist, diversity and inclusion manager, and customer marketing manager.)
What the data says: LinkedIn analyzed job openings listed on its site between January 2017 and July 2021 and ranked those that showed consistent growth over the entire period. The analysis counted open positions at different levels of seniority as a single position. It didn’t count positions occupied by interns, volunteers, or students.
- Salaries for machine learning engineers generally ranged from $72,600 to $170,000.
- Applicants were expected to have a median of four years of prior experience. Skills requested most often included deep learning, natural language processing, and TensorFlow.
- Most jobs were located in San Francisco, Seattle, and Los Angeles, and nearly 20 percent of them allowed remote work.
- Of machine learning engineers who previously held a different title, most had been software engineers, data scientists, or AI specialists.
- Of machine learning engineers whose gender was known, 22.3 percent were women.
Behind the news: While LinkedIn’s analysis was confined to the U.S., evidence suggests that machine learning jobs are growing worldwide.
- In the Philippines, where automation is replacing call center jobs, the outsourcing industry has launched a massive effort to train professionals in machine learning and data analytics.
- A survey by MIT Technology Review found that 96 percent of Asian executives and 82 percent of executives in Africa and the Middle East said their companies had deployed at least one machine learning algorithm as of 2019.
Why it matters: North America is the world’s largest AI market, accounting for around 40 percent of AI revenue globally. The fact that remote work is an option for one in five U.S. machine learning jobs suggests a huge opportunity for applicants located in other parts of the world.
We’re thinking: The world needs more AI practitioners! If you’re wondering whether to pursue a career in the field, this is a good time to jump in.
.gif?upscale=true&width=1200&upscale=true&name=AMAZON%20(1).gif) |
Let the Model Choose Your Outfit
Amazon’s first brick-and-mortar clothing store is getting ready to deliver automated outfit recommendations.
What’s new: The ecommerce giant announced plans to open a flagship Amazon Style location at a Los Angeles-area mall this year.
How it works: The 30,000 square-foot store will feature aisles and racks like a traditional clothing store, but customers will be able to scan QR codes using their phones to see variations in color and size as well as items recommended by machine learning models. A touchscreen in each fitting room will enable customers to request such items to try on.
Proposed innovations: Research papers provide glimpses of Amazon’s ideas for AI-driven fashion retailing. The company declined to comment on whether it plans to implement them. For instance:
- CSA-Net finds items that fit an existing outfit using convolutional neural networks and attention. A customer can enter a shirt and shoes, and the model might choose a matching handbag.
- VAL uses a transformer network to interpret an image-and-text pair and searches for matching products. A customer might, say, select a picture of a shirt and request a different color.
- Outfit-Viton turns a full-body photo of a customer into a 3D model, then uses a generative adversarial network to generate images of the person wearing selected outfits.
Behind the news: Last summer, Amazon opened its first brick-and-mortar grocery store, where customers can take merchandise off a shelf and exit without interacting with a clerk for payment. Computer vision identifies them at the door and identifies the products to charge their account automatically.
Why it matters: The fashion retailing market is crowded, but Amazon’s considerable AI expertise puts it at the forefront of low-friction retailing.
We’re thinking: Fashion companies such as Stitch Fix and Wantable have used AI to recommend clothing and build valuable businesses. There are good reasons to believe that future fashion leaders will be sophisticated AI players.
 |
High Accuracy at Low Power
Equipment that relies on computer vision while unplugged — mobile phones, drones, satellites, autonomous cars — need power-efficient models. A new architecture set a record for accuracy per computation.
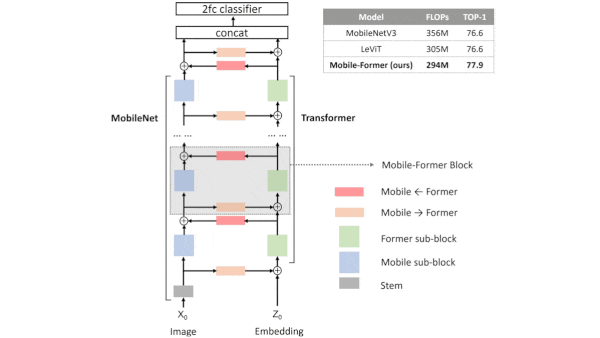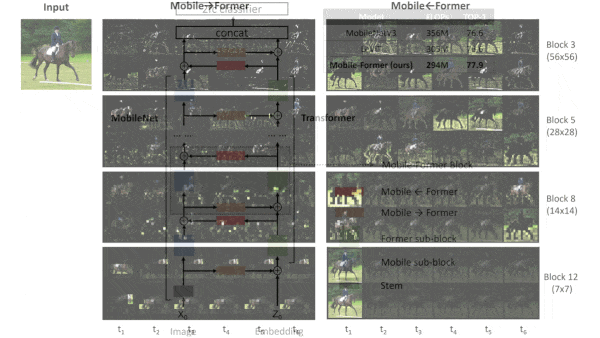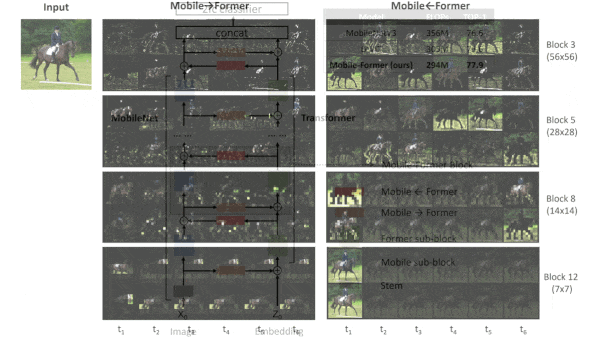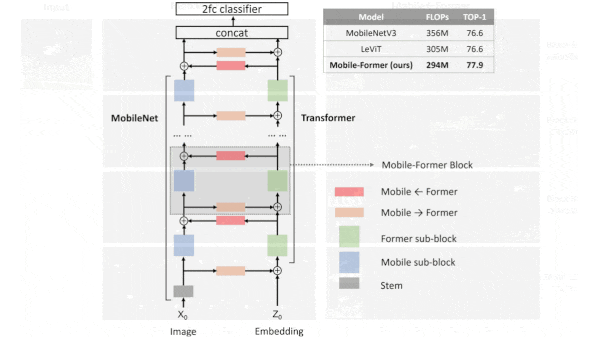
What's new: Yinpeng Chen and colleagues at Microsoft devised Mobile-Former, an image recognition system that efficiently weds a MobileNet’s convolutional eye for detail with a Vision Transformer’s attention-driven grasp of the big picture.
Key insight: Convolutional neural networks process images in patches, which makes them computationally efficient but ignores global features that span multiple patches. Transformers represent global features but they’re inefficient. A transformer’s self-attention mechanism compares each part of an input to each other part, so the amount of computation requires grows quadratically with the size of the input. Mobile-Former combines the two architectures, but instead of using self-attention, its transformers compare each part of an input to a small learned vector. This gives the system information about global features without the computational burden.
How it works: Mobile-Former is a stack of layers, each made up of three components: a MobileNet block and transformer block joined by a two-way bridge of two attention layers (one for each direction of communication). The MobileNet blocks refine an image representation, the transformer blocks refine a set of six tokens (randomly initiated vectors that are learned over training), and the bridge further refines the image representation according to the tokens and vice versa. The authors trained the system on ImageNet.
- Given an image, a convolutional layer generates a representation. Given the representation and the tokens, the bridge updates the tokens to represent the image. This starts an iterative process:
- A MobileNet block refines the image representation and passes it to the bridge.
- A transformer block refines the tokens based on the relationships between them and passes them to the bridge.
- The bridge updates the image representation according to the tokens, and the tokens according to the image representation, and passes them all to the next series of blocks.
- The process repeats until, at the end of the line, two fully connected layers render a classification.
Results: Mobile-Former beat competitors at a similar computational budget and at much larger budgets as well. In ImageNet classification, it achieved 77.9 percent accuracy using 294 megaflops (a measure of computational operations), beating transformers that required much more computation. The nearest competitor under 1.5 gigaflops, Swin, scored 77.3 percent using 1 gigaflop. At a comparable budget of 299 megaflops, a variation on the ShuffleNetV2 convolutional network scored 72.6 percent accuracy.
Yes, but: The system is not efficient in terms of the number of parameters and thus memory requirements. Mobile-Former-294M encompasses 11.4 million parameters, while Swin has 7.3 million and ShuffleNetV2 has 3.5 million. One reason: Parameters in the MobileNet blocks, transformer blocks, and bridge aren’t shared.
Why it matters: Transformers have strengths that have propelled them into an ever wider range of applications. Integrating them with other architectures makes it possible to take advantage of the strengths of both.
We're thinking: Using more than six tokens didn’t result in better performance. It appears that the need for attention in image tasks is limited — at least for images of 224x224 resolution.
A MESSAGE FROM DEEPLEARNING.AI
 |
We’re highlighting our global deep learner community. Read their stories, get inspired to take the next step in your AI journey, and #BeADeepLearner! Learn more
 |
Standards for Hiring Algorithms
Some of the world’s largest corporations will use standardized criteria to evaluate AI systems that influence hiring and other personnel decisions.
What’s new: The Data and Trust Alliance, a nonprofit group devoted to mitigating tech-induced bias in workplaces, introduced resources for evaluating fairness in algorithms for personnel management. Twenty-two companies have agreed to use them worldwide including IBM, Meta, and Walmart.
What it says: Algorithmic Bias Safeguards for Workforce includes a questionnaire for evaluating AI system vendors, a scoring system for comparing one vendor to another, and materials for educating human-resources teams about AI.
- The questionnaire addresses three themes: the business case for a given algorithm; vetting for bias during data collection, training, and deployment; and organizational biases arising from poor governance or lack of transparency. Answers can be shared between the developer and customer only, not with the rest of the group.
- Answers are converted into scores, then added to scorecards that alliance members can use to compare vendors.
- A primer is available to help human-resources staff, lawyers, and other stakeholders in interpreting the results of the survey. Other educational materials define key vocabulary and explain how algorithmic bias impacts hiring and personnel decisions.
- Alliance members are not required to use the materials.
Behind the news: Algorithms for hiring and managing employees have been at the center of several high-profile controversies.
- Earlier this year, drivers for Amazon’s Flex, the online retailer’s delivery-crowdsourcing program, criticized the company’s algorithm for scoring their performance, saying it unjustly penalized them for unavoidable delays due to bad weather and other factors outside their control. In 2018, Amazon abandoned a hiring algorithm that was found to penalize female candidates.
- An analysis by MIT Technology Review found that hiring systems from Curious Thing and MyInterview gave high scores in English proficiency to an applicant who spoke entirely in German.
- In January, hiring software developer HireVue stopped using face recognition, which purportedly analyzed facial expressions to judge traits such as dependability, in response to a lawsuit from the nonprofit Electronic Privacy Information Center that challenged the company’s use of AI for being unfair and deceptive.
Why it matters: Companies need ways to find and retain top talent amid widening global competition. However, worries over biased AI systems have spurred laws that limit algorithmic hiring in New York City and the United Kingdom. Similar regulations in China, the European Union, and the United States may follow.
We’re thinking: We welcome consistent standards for AI systems of all kinds. This looks like a good first step in products for human resources.
 |
Transformers See in 3D
Visual robots typically perceive the three-dimensional world through sequences of two-dimensional images, but they don’t always know what they’re looking at. For instance, Tesla’s self-driving system has been known to mistake a full moon for a traffic light. New research aims to clear up such confusion.
What's new: Aljaž Božic and colleagues at Technical University of Munich released TransformerFusion, which set a new state of the art in deriving 3D scenes from 2D video.
Key Insight: The authors teamed two architectures and a novel approach to estimating the positions of points in space:
- Transformers excel at learning which features are most relevant to completing a particular task. In a video, they can learn which frames, and which parts of a frame, reveal the role of a given point in space: whether it’s empty or filled by an object.
- However, while transformers do well at selecting the best views, they’re not great at identifying points in space. The authors addressed this shortfall by refining the representations using 3D convolutional neural networks.
- To position the points in space, they generated representations at both course and fine scales. The coarse representations enabled the system to place points coherently across relatively large distances, while the fine representations enabled the system to reproduce details.
How it works: Given a series of 2D frames, TransformerFusion learned to reconstruct the 3D space they depicted by classifying whether each 3D pixel, or voxel, belonged (or was very close) to an object’s surface. The authors trained the system on ScanNet, a dataset that contains RGB-D (video plus depth) clips shot in indoor settings like bedrooms, offices, and libraries; object segmentations; and 3D scene reconstructions.
- Given a 2D frame, a ResNet-18 pretrained on ImageNet produced a coarse representation and a fine representation.
- A transformer mapped the coarse representations, along with information derived from the images such as viewing direction, to a 3D grid with 30-centimeter resolution and produced a new representation for each point. A second transformer mapped fine representations and other information to a 3D grid with 10-centimeter resolution and, likewise, produced a new representation for each point.
- Given the coarse representations, a 3D convolutional neural network learned to classify whether a point was near an object’s surface and refined the representations accordingly. If the point was near a surface, the system continued; otherwise, it classified the point as not near a surface and stopped to save computation.
- A second 3D CNN used both fine and coarse representations to learn how to classify, refine, and filter the representations of points on the fine grid.
- The system interpolated the remaining coarse and fine representations onto a 3D grid of even higher resolution (2 centimeters) and generated another set of point representations. Given each new point, a vanilla neural network classified whether there was an object at that point.
- The authors trained the system using three loss terms: one that encouraged the coarse CNN’s classifications to match ground truth, a similar one for the fine CNN, and a similar one for the higher-resolution CNN.
Results: The authors measured distances between TransformerFusion’s estimated points in space and ground truth. They considered an estimation correct if it matched ground truth within 5 centimeters. The system achieved an F-1 score, a balance of precision and recall where higher is better, of 0.655. The best competing method, Atlas, achieved 0.636. Without the 3D CNNs, TransformerFusion achieved 0.361.
Yes, but: Despite setting a new state of the art, TransformerFusion’s ability to visualize 3D scenes falls far short of human-level performance. Its scene reconstructions are distorted, and it has trouble recognizing transparent objects.
Why it matters: Transformers have gone from strength to strength — in language, 2D vision, molecular biology, and other areas — and this work shows their utility in a new domain. Yet, despite their capabilities, they can’t do the whole job. The authors took advantage of transformers where they could do well and then refined their output using an architecture more appropriate to 3D modeling.
We're thinking: Training systems on both low- and high-resolution versions of an image could improve other vision tasks as well.