
Dear friends,
One rule I try to live by is to not surprise my collaborators. During a project, for example, a deadline may slip, or a customer may drop out. If I can foresee such risks, l let my collaborators know about major things that could go wrong so they’re not surprised if something does. And if something unforeseen happens, I ask myself, “Would my collaborators be surprised if they were to hear this news from someone else?” If the answer is yes, I try to reach out quickly to let them know myself.
I find this rule useful when thinking about AI systems, too. Is there a chance that what this system does will surprise my collaborators, partners, or customers? No one likes unpleasant surprises, and asking this question might help you decide when to proactively reach out to set clearer expectations about what your system might do.
Over the years, unfortunately, the AI community collectively has delivered a lot of unpleasant surprises. For example, I’ve seen users of AI systems surprised when a system that achieved 99% accuracy on a test set didn’t perform well on a business application. This may be because concept drift or data drift led to degradation, or because the test metric (such as average accuracy) did not match the business’ need (which might be accurate recall even on rare classes). I’ve also seen users surprised by:
- the large amount of maintenance a system needs
- the great size of the cloud hosting bill
- the large amount of work involved in labeling data
- the fact that an AI system can, despite being right 90% of the time, still make occasional, incomprehensible, “dumb” mistakes
- the complexity of taking a Jupyter Notebook model to deployment
 |
Some of these surprises occurred because AI is still evolving and practitioners themselves are still learning — for example, I think most folks working in self-driving were well-meaning but honestly underestimated how long it would take to make the technology work. By now, our community has seen enough AI use cases that we should be getting better at minimizing surprises by identifying potential issues and communicating in advance.
Today many people don’t trust tech. There are many reasons for this; among them, some systems aren’t well built and should not be trusted. But one of the keys to building trust in human relationships is to avoid major unpleasant surprises. If we can at least avoid surprising our collaborators, this would reduce one unnecessary source of distrust.
So ask yourself: Might anything about your current project — its cost, performance, or other characteristics — be a big surprise to your associates? If so, consider reaching out to let them know right now.
Keep learning!
Andrew
News
 |
Robots in the Workplace
Machines are doing light janitorial work in the uncontrolled environment of Google’s offices.
What’s new: Everyday Robots, a new spin-out from Google’s experimental X Development division, unleashed 100 robots to perform an array of cleanup tasks. Since learning a few years ago to sort garbage for recycling, compost, and landfill, the machines have learned to open doors, straighten chairs, and squeegee tabletops (as in the video above).
How it works: The robot rolls on four wheels guided by lidar. Its head contains five cameras and other sensors whose output helps direct an articulated arm tipped with a gripping claw. Google implies that the control system uses a single base model and changes output layers for different tasks. It’s trained via imitation learning followed by rounds of reinforcement learning in conventional and federated learning (also called collaborative learning) settings.
- A human operator manipulates the arm to complete a task. A robot learns to imitate this behavior, sometimes in a simulation, sometimes in the real world.
- The robots refine such behaviors over large numbers of attempts in a simulation using reinforcement learning, which delivers a reward depending on how successful an attempt was.
- The robots share a cloud-based neural network that estimates the value of taking a given action in a given state. Each robot independently uses the network to decide what actions to take. Actions that garner rewards improve the neural network, and a new version is shared with the fleet at regular intervals.
- These steps prepare the robot to enter a real-world environment and achieve 90 percent success in a new task, such as opening doors, after less than one day of further federated learning.
Behind the news: Mechanical helpers are beginning to grasp basic custodial chores.
- Toyota Research Institute demonstrated a robot that performs rote house-cleaning tasks. It used machine learning to pick up objects without breaking them.
- Silicon Valley restaurants can send their dirty dishes to Dishcraft Robotics, where autonomous grippers guided by computer vision scrub a variety of plates and cutlery.
- The venerable Roomba is getting an AI makeover. The latest version of the robot vacuum cleaner can map rooms and avoid furniture.
Why it matters: In many countries, older people outnumber younger ones who could take care of them. Offices aren’t as complex as homes, with their clutter, tight spaces, and multi-story floor plans, but they are a proving ground for robots that might tidy up for people who aren’t able to do it themselves.
We’re thinking: We celebrate progress in robotics. At the same time, we empathize with people whose jobs are be threatened. Even as we build these wonderful contraptions, it’s important to provide workers with retraining, re-skilling, and safety nets to make sure no one is left behind.
 |
U.S. Adults Fail AI 101
Most Americans don’t understand AI, according to a new survey.
What’s new: Only 16 percent of adults in the United States got a passing grade on a true-or-false questionnaire of AI’s capabilities and uses. The survey was created by the Allen Institute for Artificial Intelligence and administered by Echelon Insights.
Conceptions and misconceptions: The study queried 1,547 participants. Correct answers to 12 of the 20 questions earned a passing grade.
- What they knew: Substantial majorities of respondents understood that AI learns from large quantities of data, smart speakers use AI, a smartphone’s face recognition capability is based on AI, and banks use AI to detect fraud. Around half knew that an AI system can outplay top chess experts, can identify common objects in photos as well as an adult human, and can’t drive a car as well as a human driver.
- What they didn’t know: Responses divided nearly evenly between “true,” “false,” and “don’t know” over whether AI can think for itself or detect emotions in photos and conversations at the level of a human adult — capabilities well out of reach of current systems. 79 percent of respondents incorrectly believed that AI can write basic software programs by itself, and 64 percent wrongly thought that AI can transcribe conversations as well as a human adult. 43 percent believed the false statement that AI can understand cause and effect, while 32 percent didn’t know.
Behind the news: Despite the United States’ dominant role in AI research and products, the U.S. lags other nations in teaching tech literacy.
- In 2019, India’s national board of education announced that students at 883 schools across the country had added AI to their curriculum for students beginning in eighth grade.
- In 2018,China’s Ministry of Education began to provide AI lessons and textbooks to primary and secondary students.
- Australia encourages teachers to teach about AI.
Why it matters: While U.S. adults misunderstand AI, most of them apparently recognize the high stakes involved. A different study found that 57 percent of Americans believe that AI has potential to cause harm due to misuse in the next decade. It will take informed citizens to ensure that AI benefits people broadly worldwide.
We’re thinking: To be fair, even Andrew wasn’t sure of the answers to some of the questions. Can AI analyze chest X-rays with equal or better accuracy than a radiologist? Andrew contributed to research describing a system that performed comparably to humans on this task, so perhaps the correct answer is “true.” But even AI systems that beat humans in a research lab often lack the robustness to beat humans outside the lab, so maybe it’s “false.” That left him inclined toward “don’t know.”
A MESSAGE FROM DEEPLEARNING.AI
 |
This month, we’re celebrating our global deep learner community. Read their stories, get inspired to take the next step in your AI journey, and #BeADeepLearner! Read more
 |
Tax Relief the AI Way
Nothing is certain except death and taxes, the saying goes — but how to make taxes fair and beneficial remains an open question. New research aims to answer it.
What’s new: Stephan Zheng and colleagues at Salesforce built a tax planning model called AI Economist. It observes reinforcement learning agents in an economic simulation and sets tax rates that promote their general welfare.
Key insight: Economic simulations often use pre-programmed agents to keep the computation manageable, but hard-coding makes it difficult to study the impact of tax rates on agent behavior. A reinforcement learning (RL) system that accommodates different types of agents can enable worker agents to optimize their own outcomes in response to tax rates, while a policy-maker agent adjusts tax rates in response to the workers’ actions. This dual optimization setup can find a balanced optimum between the interests of individual workers and the policy maker.
How it works: Four workers inhabited a two-dimensional map, 25 squares per side. One episode spanned 10 tax periods, each lasting 100 time steps. The policy maker changed tax rates after each period. Workers sought high income and low labor individually, while the policy maker pursued social welfare, the product of the average difference in incomes and the sum of all incomes.
- The workers and policy maker were convolutional LSTMs trained using proximal policy optimization (PPO).
- Workers learned whether to move, gather building materials, sell them to each other for coins, build houses, sell houses, or do nothing. Each action consumed a certain amount of effort and accrued a certain amount of income. Their choices were influenced by their neighborhood, wealth, gathering skill (productivity in collecting materials), building skill (which determined the market value of a house), market prices (based on asking prices, bids, and past transactions), and tax rates.
- The policy maker set the tax rates for seven income brackets based on current prices, tax rates, and worker wealth. It distributed tax revenue equally among workers.
Results: The authors observed several realistic phenomena. Workers specialized: Skilled builders constructed houses while others gathered materials. There was a tradeoff between productivity and quality; that is, more-productive builders produced houses of lower quality. And workers developed strategies to game the system by, say, delaying a house sale to a later period when the tax rate might be lower. When it came to promoting general welfare — measured as the product of income equality and productivity — AI Economist achieved 1,664, outperforming three benchmarks: a widely studied tax framework called the Saez formula (1,435), the U.S. Federal Income Tax schedule (1,261), and no taxes (1,278). Its policy also outperformed those baselines when human players stood in for the RL workers.
Why it matters: Reinforcement learning with heterogeneous agents can automate the modeling of incentives in interactions between different parties such as teachers and students, employers and employees, or police and criminals.
We’re thinking: Simulations of this nature make many assumptions about incentives, rate of learning, cost of various actions, and so on. They offer a powerful way to model and make decisions, but validating their conclusions is a key step in mapping them to the real world.
 |
Ethics for an Automated Army
The U.S. Department of Defense issued new ethical guidelines for contractors who develop its AI systems.
What’s new: The Pentagon’s Defense Innovation Unit, which issues contracts for AI and other high-tech systems, issued guidelines that contractors must follow to ensure that their systems work as planned without harmful side effects.
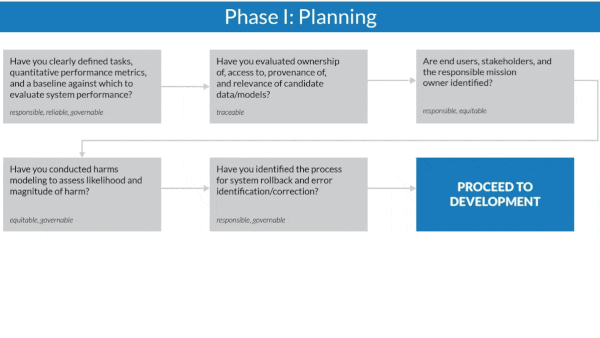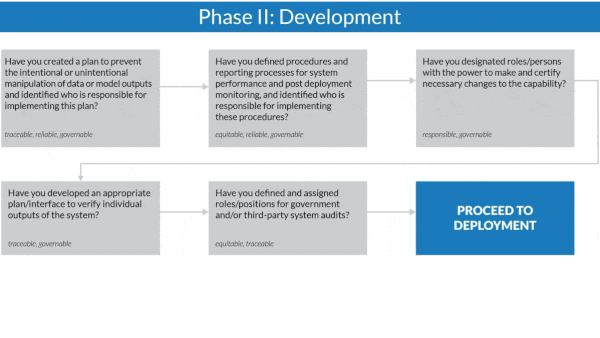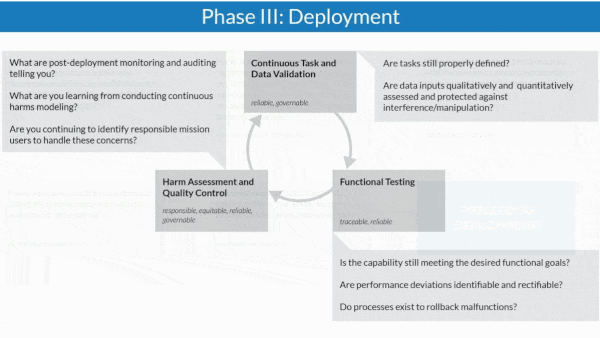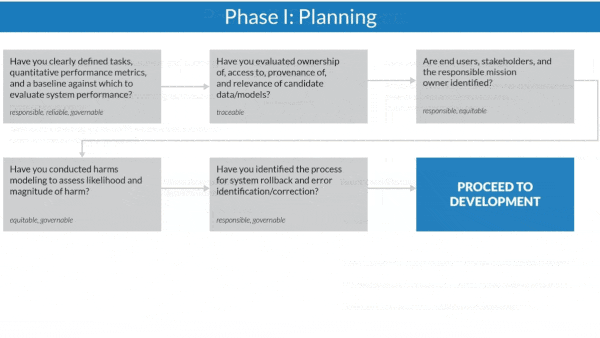
How it works: The authors organized the guidelines around AI system planning, development, and deployment. Throughout each phase, questions arranged in a flowchart prompt contractors to satisfy the Defense Department’s ethical principles for AI before moving on to the next stage.
- During planning, contractors work with officials to define a system’s capabilities, what it will take to build it, and how they expect it to be deployed.
- During development, contractors must explain how they will prevent data manipulation, assign responsibility for changes in the system’s capabilities, and outline procedures for monitoring and auditing.
- During deployment, contractors must perform continuous assessments to ensure that their data remains valid, the system operates as planned, and any harm it causes is documented.
- In a case study, the guidelines helped a team realize that its system for examining x-ray images could deny critical care to patients with certain rare conditions. To address the issue, the team tested the model on rare classes of x-ray images.
Behind the News: The Pentagon adopted its ethical principles for AI in February 2020 after 15 months of consultation with experts in industry, academia, and government. The document, which applies to service members, leaders, and contractors, broadly defines ethical AI as responsible, transparent, reliable, governable, and deployed with minimal bias.
Why It Matters: The Department of Defense (DOD) invests generously in AI. One estimate projects that military spending on machine learning contracts will reach $2.8 billion by 2023. But the department has had difficulty collaborating with big tech: In 2018, over 4,000 Google employees protested the company’s involvement in a DOD program called Project Maven, highlighting qualms among many AI professionals about military uses of their work. DOD’s new emphasis on ethics may portend a smoother relationship ahead between big tech and the military.
We’re thinking: The document doesn't mention fully autonomous weapons, but they lurk in the background of any discussion of military AI. While we acknowledge the right of nations to defend themselves, we support the United Nations’ proposal to ban such systems.
 |
Why Active Learning Fails
Where labeled training data is scarce, an algorithm can learn to request labels for key examples. While this practice, known as active learning, can supply labeled examples that improve performance in some tasks, it fails in others. A new study sheds light on why.
What's new: Siddharth Karamcheti and colleagues at Stanford University showed that examples of a certain kind hinder active learning in visual question answering (VQA), where a model answers questions about images.
Key insight: Most active learning methods aim to label examples that a model is least certain about. This approach assumes that providing labels that resolve the model’s uncertainty will improve performance faster than providing labels that confirm its certainty. However, some examples that prompt uncertainty are also difficult to learn, and the uncertainty doesn’t dissipate with additional learning. For instance, in VQA, some questions about an image may refer to information that’s absent from the image itself; consider a photo of a car and the question, “What is the symbol on the hood often associated with?” If an active learning algorithm were choose many such examples, the additional labels would contribute little to learning. For active learning to work, it needs to choose examples the model can learn from. Thus, removing hard-to-learn examples prior to active learning should improve the results.
How it works: The authors trained several VQA models on a variety of datasets. They fine-tuned the models using five diverse active-learning strategies and compared their impact to labeling examples at random.
- The authors applied each active learning strategy to each model-dataset pair. They noted the number of additional labeled examples needed to reach a certain level of accuracy, or sample efficiency.
- They computed the model’s confidence in its classification of each training example. They also computed a variability score that quantifies how much its confidence varied over the course of training. Low confidence and high variability indicated the most difficult-to-learn examples.
- They removed the 10 percent, 25 percent, or 50 percent of examples that had the lowest product of confidence and variability. Then they repeated step one, using each active learning strategy and measuring its impact on performance.
Results: Culling the most difficult-to-learn training examples (those that elicited the lowest product of confidence and variability) enabled all five active learning strategies to train VQA models using fewer examples. For instance, the authors used the active learning strategy called least-confidence, which labels additional examples in which the model is least confident in its classification, to fine-tune a Bottom-Up Top-Down Attention model on the VQA-2 dataset. It achieved 50 percent accuracy with 120,000 labeled examples — no better than labeling at random. The authors removed 10 percent of the most difficult-to-learn examples and achieved the same accuracy with 100,000 labeled examples. After removing 25 percent, it achieved the same accuracy with 70,000 labeled examples. After removing 50 percent, it took only 50,000 labeled examples (while labeling additional examples at random required 70,000 labeled examples).
Why it matters: VQA is data-hungry, while active learning is sample-efficient. They make a handy combo — when they work well together. This study identifies one problem with the pairing and how to solve it.
We're thinking: The authors focused on how difficult-to-learn examples affect active learning in VQA, but the same issue may hinder active learning in other tasks. We hope that further studies will shed more light.