
Dear friends,
Building AI systems is hard. Despite all the hype, AI engineers struggle with difficult problems every day. For the next few weeks, I’ll explore some of the major challenges. Today’s topic: The challenge of building AI systems that are robust to real-world conditions.
The accuracy of supervised learning models has grown by leaps and bounds thanks to deep learning. But there’s still a huge gap between building a model in a Jupyter notebook and shipping a valuable product.
Multiple research groups, including mine and several others, have published articles reporting DL’s ability to diagnose from X-ray or other medical images at a level of accuracy comparable or superior to radiologists. Why aren’t these systems widely deployed?
I believe robustness is a major impediment. For example, if we collect data from a top research hospital that has well trained X-ray technicians and high-quality X-ray machines, and we train and test a state-of-the-art model on data from this hospital, then we can show comparable or superior performance to a radiologist.
But if we ship this algorithm to an older hospital with less well-trained technicians or older machines that produce different-looking images, then the neural network likely will miss some medical conditions it spotted before and see others that aren’t really there. In contrast, any human radiologist could walk over to this older hospital and still diagnose well.

I have seen this sort of challenge in many applications:
- A speech recognition system was trained primarily on adult voices. After it shipped, the demographic of users started trending younger. The prevalence of youthful voices caused performance to degrade.
- A manufacturing visual inspection system was trained on images collected on-site over one month. Then the factory’s lighting changed. Performance degraded in turn.
- After engineers shipped a web page ranking system, language patterns evolved and new celebrities rose to fame. Search terms shifted, causing performance to degrade.
As a community, we are getting better at addressing robustness. Approaches include technical solutions like data augmentation and post-deployment monitoring along with setting alarms to make sure we fix issues as they arise. There are also nascent attempts to specify operating conditions under which an algorithm is safe to use, and even more nascent attempts at formal verification. Robustness to adversarial attacks is another important consideration, but most practical robustness issues that I see involve non-adversarial changes in the data distribution.
One of the challenges of robustness is that it is hard to study systematically. How do we benchmark how well an algorithm trained on one distribution performs on a different distribution? Performance on brand-new data seems to involve a huge component of luck. That’s why the amount of academic work on robustness is significantly smaller than its practical importance. Better benchmarks will help drive academic research.
Many teams are still addressing robustness via intuition and experience. We, as a community, have to develop more systematic solutions.
Keep learning!
Andrew
DeepLearning.ai Exclusive

Optimizing the Ride Sharing Market
Or Cohen’s background in physics gave him a theoretical foundation to dive into the practicalities of machine learning. Now he’s prototyping models at Lyft. Read more
News
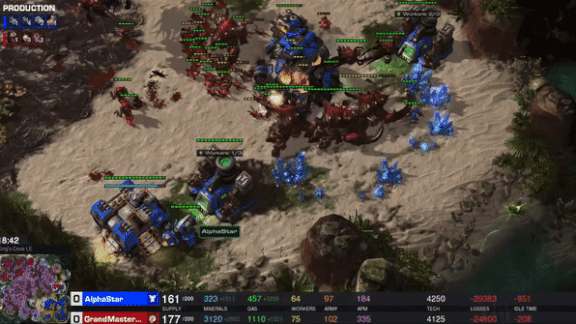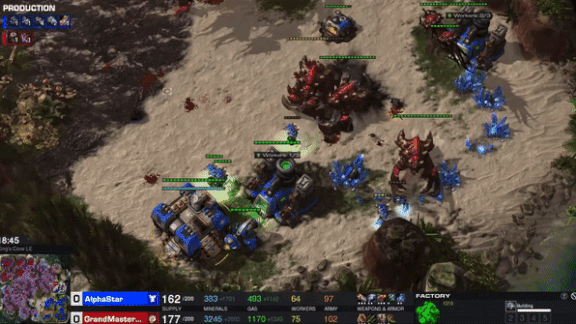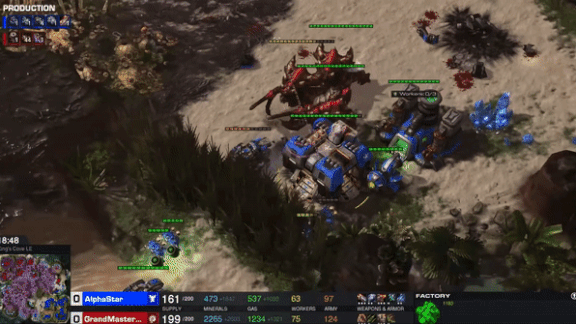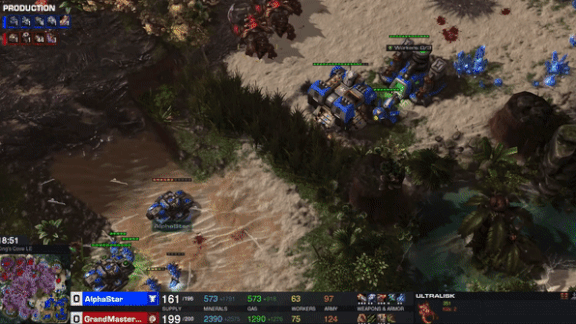
Take That, Humans!
At the BlizzCon gaming convention last weekend, players of the strategy game StarCraft II stood in line to get walloped by DeepMind’s AI. After training for the better part of a year, the bot has become one of the world’s top players.
What’s new: DeepMind, the AI research division of Alphabet, announced that its AlphaStar model had achieved StarCraft II Grandmaster status, able to beat 99.8 percent of active players, under restrictions that mimic those affecting human players.
How it works: StarCraft II boils down to simple goals — mining resources, raising armies, and annihilating opponents — but gameplay is complex, offering 1026 possible actions at each time step. AlphaStar was designed not only to defeat human rivals but to play like humans do. Indeed, the model doesn’t invent its own strategies. It adopts human strategies and hones them with experience, according to the project’s latest paper.
- Agents were initialized via supervised learning.
- The developers used imitation learning to train an initial strategic policy capable of beating roughly 84 percent of human players.
- Then they set up a simulated league where AlphaStar used reinforcement learning while playing against itself the way human StarCraft II players do — not to win at all costs but to improve its skills by exposing and learning to defend against strategic flaws. To this end, the developers added agents whose sole purpose was to exploit weaknesses discovered in previous matches.
- After sharpening its skills in the virtual league, AlphaStar faced human opponents on Battle.net, an online gaming network, where it attained Grandmaster status.
Humanizing the bot: DeepMind announced AlphaStar in January and showcased its ability to beat professional human players in a series of matches. That version had features that gave it a clear advantage over humans. For instance, it could see the entire field of play rather than a limited view and could perform any number of actions per minute. The Grandmaster version was revamped to put it on equal footing with human players.
Why it matters: DeepMind has invested heavily in game-playing AI since its early days with classic Atari titles. Its accomplishments have generated lots of excitement around the technology. Its AlphaGo system is credited with motivating many countries to invest more in AI. AlphaStar keeps the momentum going.
We’re thinking: AI has beaten humans at a succession of games: Othello, Checkers, Chess, Go, Hold’em poker, and now StarCraft II. Still, there remains a significant gap between mastering even a very complex video game and practical, real-world applications.

Unfinished Artwork? No More
Generative networks can embroider sentences into stories and melodies into full-fledged arrangements. A new model does something similar with drawings.
What’s new: Researchers at the University of Oxford, Adobe Research, and UC Berkeley introduce a model that interactively fills in virtual pencil sketches. SkinnyResNet turns crude lines drawn in a web browser into photorealistic pictures complete with colors and textures.
Key insight: Most sketch-to-image networks require users to create a complete sketch before transforming it into a finished picture. To bridge the gap between initial strokes and completed outlines, the model starts conjuring detailed images from the first pencil mark.
How it works: The system is based on two generative adversarial networks. A sketch-completion GAN predicts what the user aims to draw, and an image-generation GAN acts on the prediction to generate an image.
- The authors constructed an outline-to-image dataset comprising 200 pairs in 10 classes. They obtained the images by searching Google and extracted the outlines digitally.
- The sketch-completion GAN generates a complete outline from the current state of a user’s sketch. It was trained on partial outlines created by deleting random patches from full outlines.
- The user chooses a class of object to sketch. The image-generation GAN takes the predicted sketch and object class, and generates a photorealistic image.
- Another neural network controls the image-generation GAN to create the type of object selected. The GAN is composed of CNN layers, and the control network can toggle particular channels on or off depending on the object class. In this way, different channels specialize in generating different image classes.
Results: Arnab Ghosh and colleagues compared their model’s output with that of an encoder-decoder network inspired by MUNIT. They fine-tuned a pretrained Inception v3 network on their dataset and used it to classify images generated by both models. The classifier correctly identified 97 percent of SkinnyResNet images compared with 92.7 percent of the encoder-decoder’s output. A group of human labelers classified 23 percent of SkinnyResNet’s output as real images, while labeling only 14.1 percent of the encoder-decoder’s output as real.
Why it matters: We’ve come a long way since Photoshop 1.0, and this research may offer a glimpse of the design tools to come. Rather than passive programs modeled after real-world items like pencils and paintbrushes, such tools might evolve into proactive assistants that help designers visualize and finish their creations.
We’re thinking: Why stop at drawing? Tools for writing and music composition are already headed in this direction. Other creative pursuits like 3D modeling, mechanical design, architecture, and choreography could take advantage of similar generative techniques.
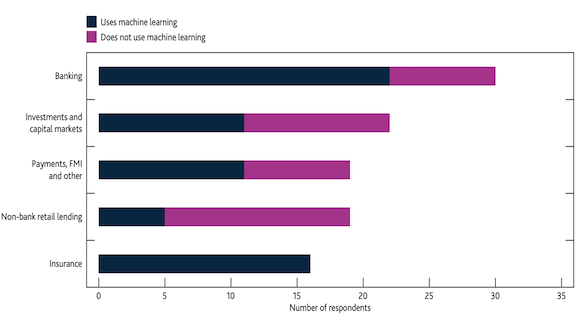
Banking on Automation
The UK’s banking industry is using AI in many facets of the business.
What’s new: A survey of financial firms in the UK found that nearly two-thirds of respondents have deployed machine learning technology. Many said they expect their use to double in the next two years.
What the report says: The Bank of England and the UK Financial Conduct Authority sent questionnaires to nearly 300 institutions and got responses from a little over 100 firms offering a variety of services.
- Two thirds of those surveyed are actively using machine learning applications. The median number was two applications per firm.
- Machine learning is used mostly for fraud detection and anti-money laundering. It also automates customer service in applications such as online chatbots and marketing in tasks like recommending loans or account types.
- The technology also contributes to risk management including credit lending, trade pricing, insurance pricing, and underwriting.
- Despite AI’s penetration throughout the industry, few of the firms polled expressed worry about recruiting skilled developers. Instead, they were concerned with overcoming the constraints of legacy IT systems.
Behind the news: AI’s penetration in banking extends well beyond the UK. JPMorgan Chase in its 2018 annual report told investors it had gone “all in on AI.” HSBC recently opened data science innovation labs in Toronto and London to help process insights from the 10 petabytes of data its clients generate each year. Citigroup is using AI to fight fraud, Bank of America has an AI-powered customer service bot, and Capital One says it uses AI from end to end.
Why it matters: Banking and finance tend to fly under the radar in press reports on AI’s role in traditional industries. This report, while specific to the UK, may well correlate with trends in banks around the world.
We’re thinking: The report lists nine classes of ML algorithms used by respondents including trees, clustering, neural networks (used in roughly 32 percent of cases), and reinforcement learning (around 15 percent). The category called Other is used around 35 percent of the time. We’re happy to call, say, linear regression an ML algorithm. Given such an expansive definition, though, we imagine that most financial institutions use machine learning in some capacity.
A MESSAGE FROM DEEPLEARNING.AI

Recurrent neural networks have transformed speech recognition and natural language processing. In Course 5 of the Deep Learning Specialization, you will learn how to build these models for yourself. Enroll today!

Who’s Minding the Store?
Amazon, watch your back. There’s a new player in the book business and, unlike Jeff Bezos, it doesn’t need eight hours of sleep a night.
What’s new: The online bookstore Booksby.ai is run entirely by AI. Neural networks write the books, create the cover art, price the merchandise, even write the reviews.
How it works: Booksby.ai is an art project created by interaction designer Andreas Refsgaard and data scientist Mikkel Loose. It’s not really meant to generate sales or turn a profit. Rather, it’s a wry commentary on the notion that AI threatens to take human jobs.
- To generate text, author names, book titles, and reader reviews, Refsgaard and Loose used a multiplayer recurrent neural network trained on data from Amazon and Project Gutenberg.
- A generative adversarial network designed the book covers based on training data from Open Library.
- A different GAN generated portraits of reviewers from a training set of Amazon reviewer photos.
- A model designed to aid in transfer learning came up with prices based on data from Amazon.
Soft demand: The store has sold only 19 books so far (taking advantage of Amazon’s shopping cart). “Being a writer is a tough job, even if you are an artificial intelligence,” Refsgaard said in an interview with New Atlas.
But is it art? The store’s wares definitely cater to avant-garde tastes. The description of the tome provocatively titled Bitches of the Points reads:
Mary Martin has decided to have a life she sees the world when her world comes out to make Sam must confront the strange past of the FBI agent Sam has no surprise for someone all the problems of the killer. And now that the story could destroy the dead children and joins forces to stay on his family.
Gertrude Stein, the literary master of scrambled syntax, would approve.
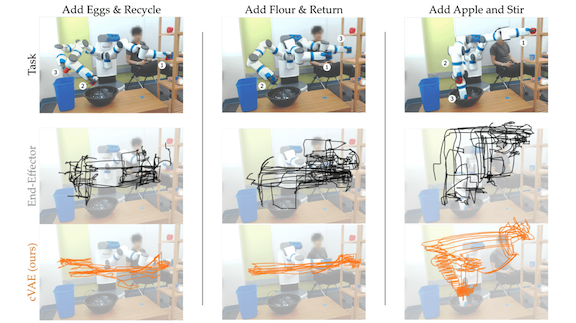
Robotic Control, Easy as Apple Pie
Robots designed to assist people with disabilities have become more capable, but they’ve also become harder to control. New research offers a way to operate such complex mechanical systems more intuitively.
What’s new: Researchers at Stanford enabled a joystick to control a seven-joined mechanical arm in a way that adapts automatically to different tasks. Their work could make it easier for people suffering from compromised mobility in a variety of common activities.
Key insight: An intuitive mapping of joystick motions to arm movements depends on context. Pushing a joystick downward to control a robot arm that holds a glass of water may be an instruction to pour, while the same motion applied to an empty hand may be a command to sweep the arm downward. Dylan P. Losey and colleagues used a conditional variational autoencoder to learn a vector, controllable by a joystick, that depends on the arm’s current position.
How it works: An autoencoder is a two-part network, consisting of an encoder and decoder, that learns a simplified representation of its input. The encoder maps an input vector to a smaller output vector. The decoder network tries to recreate the input from the encoder’s output. A variational autoencoder creates a distribution of latent vectors for a given input, and a conditional variational autoencoder changes that distribution depending on state information.
- The model learns a simplified control representation from examples of the robotic arm achieving a task; for example, reaching to grab an item.
- A joystick captures user input in the form of this simplified control representation. The decoder translates this input into motor controls that maneuver the arm. For instance, for reaching, up and down may control arm extension, while left and right open and close the hand’s grasp.
- To prevent logical inconsistencies, such as large motor changes from small joystick movements, the encoder is penalized for having large variance in its simplified representations. However, the simplified representations don’t define the exact movements of each joint, so they sacrifice some precision.
Results: Among other experiments, the researchers had users control the arm to make an apple pie by mixing ingredients and disposing of containers. Participants used either the simplified controls or common controls that define the movement of each joint. Users of the new method produced their pies in half the time, on average, and reported much greater ease.
Why it matters: Nearly a million Americans face disabilities requiring robotic assistance in everyday tasks. A simple, intuitive control method could allow such people autonomy rather than having to delegate tasks to a caregiver.
We’re thinking: In this case, a conditional variational autoencoder made it easier to use a mechanical arm, but these networks could help simplify a plethora of human interactions with machines and computers.