
Dear friends,
The physical world is full of unique details that differ from place to place, person to person, and item to item. In contrast, the world of software is built on abstractions that make for relatively uniform coding environments and user experiences. Machine learning can be a bridge between these two worlds.
Software is largely homogenous. When a search-engine company or smartphone maker upgrades its product, users all over the world are offered the same upgrade. This is economically efficient because, despite high fixed costs for design and manufacturing, it results in low marginal costs for manufacturing and distribution. These economics, in turn, support huge markets that can finance innovation on a grand scale.
In contrast, the real world is heterogeneous. One city is surrounded by mountains, another by plains, yet another by seas. One has paved roads, another dirt tracks. One has street signs in French, another in Japanese. Because of the lack of platforms and standards — or the impossibility of creating them — one size doesn’t fit all. Often it fits very few.
This is one reason why it’s difficult to design a self-driving car. Making a vehicle that could find its way around safely would be much easier if every city were built to a narrow specification. Instead, self-driving systems must be able to handle streets of any width, stop lights in any configuration, and a vast array of other variables. This is a tall order even for the most sophisticated machine learning systems.
 |
Software companies have been successful at getting users to adapt to one-size-fits-all products. Yet machine learning could help software capture and interact with the rich diversity of the physical world. Rather than forcing every city to build streets of the same composition, width, color, markings, and so on, we can build learning algorithms that enable us to navigate the world’s streets in all their variety.
We have a long way to go on this journey. Last week, I wrote about how Landing AI is using data-centric AI to make machine learning work under the wide variety of conditions found in factories. When I walk into a factory, I marvel at how two manufacturing lines that make an identical product may be quite different because they were built a few years apart, when different parts were available. Each factory needs its own trained model to recognize its own specific conditions, and much work remains to be done to make machine learning useful in such environments.
I hope that you, too, will see the heterogenous world you live in and marvel at the beautiful diversity of people, buildings, objects, and cultures that surround you. Let’s use machine learning to better adapt our software to the world, rather than limit the world to adapt to our software.
Keep learning!
Andrew
News
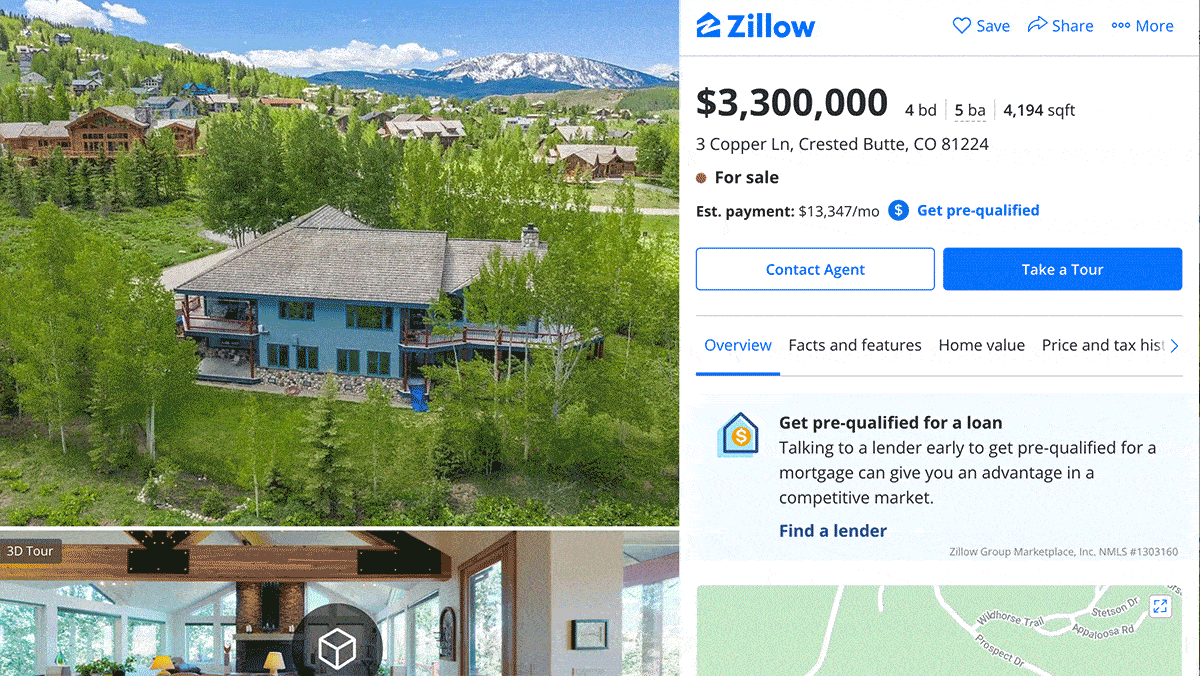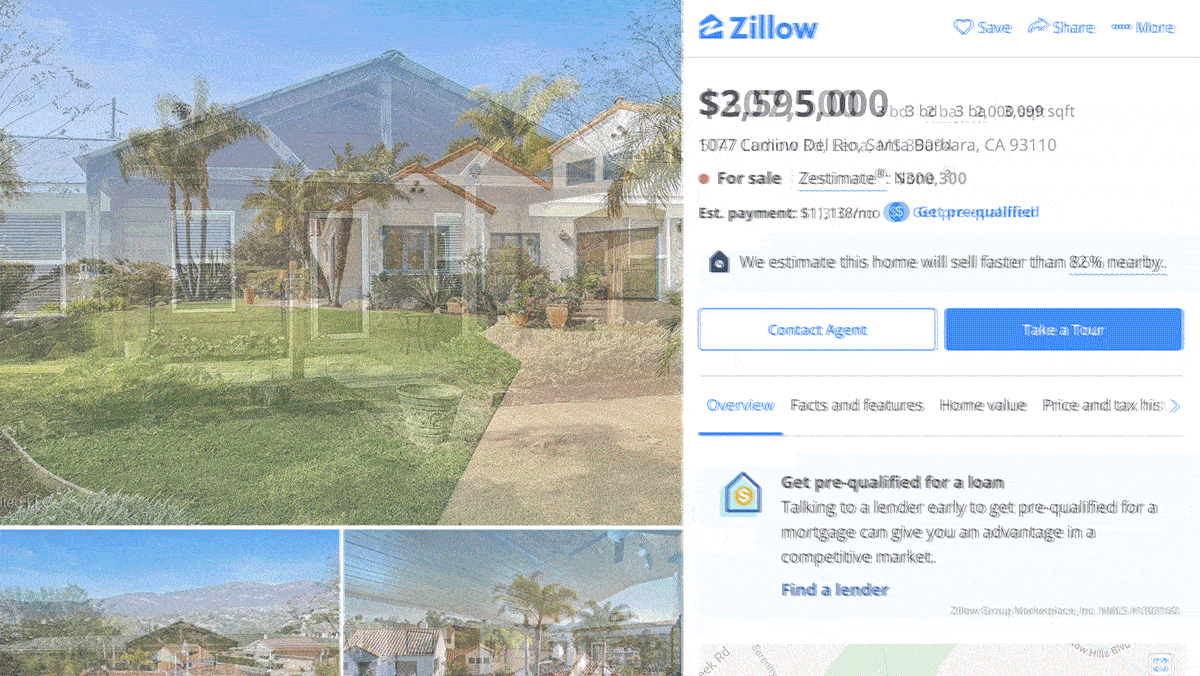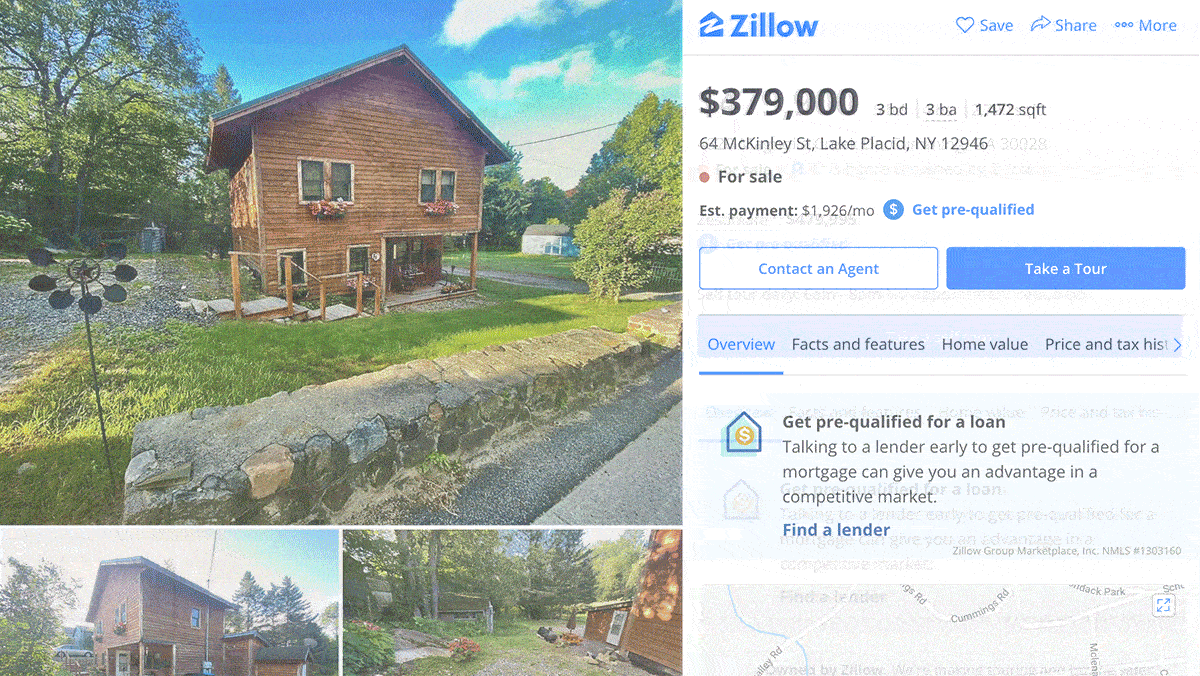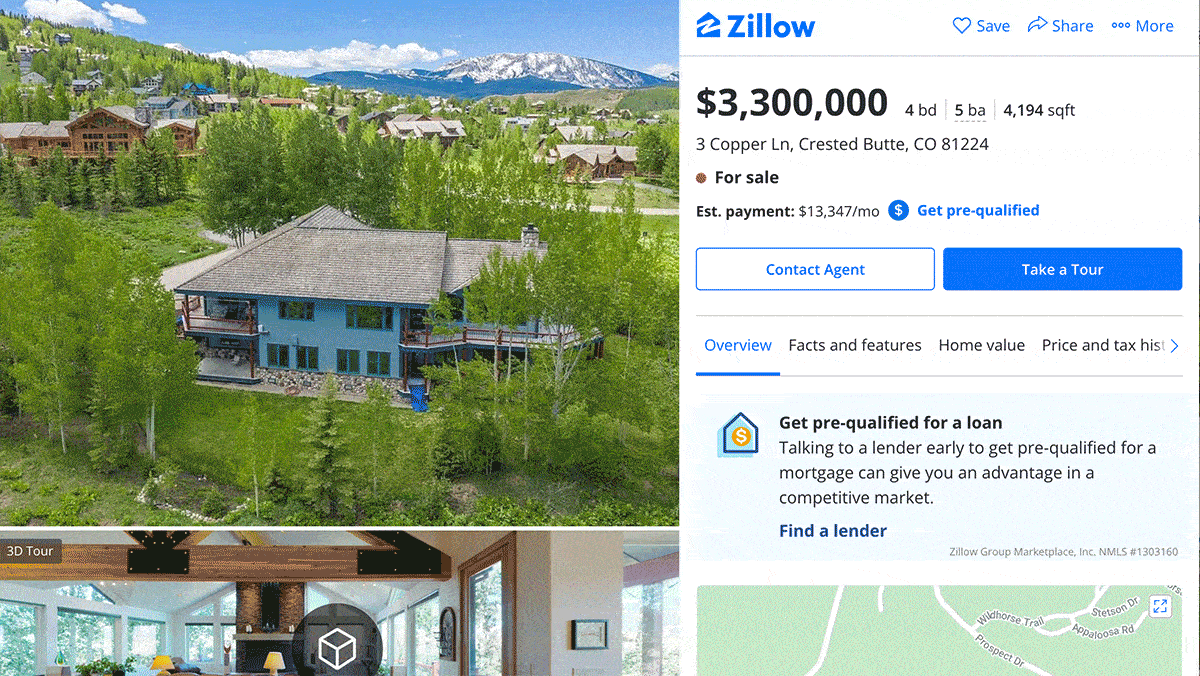 |
Price Prediction Turns Perilous
The real-estate website Zillow bought and sold homes based on prices estimated by an algorithm — until Covid-19 confounded the model’s predictive power.
What’s new: Zillow, whose core business is providing real-estate information for prospective buyers, shut down its house-flipping division after the algorithm proved unable to forecast housing prices with sufficient accuracy, Zillow CEO Rich Barton told investors on a quarterly conference call. Facing losses of over $600 million, the company will lay off around 25 percent of its workforce. (A related algorithm called Zestimate continues to supply price estimates on the website.)
What went wrong: The business hinged on purchasing, renovating, and reselling a large number of properties. To turn a profit, it needed to estimate market value after renovation to within a few thousand dollars. Since renovation and re-listing take time, the algorithm had to forecast prices three to six months into the future — a task that has become far more difficult over the past 18 months.
- The pandemic triggered a real-estate spree, driving price fluctuations that Zillow’s algorithm, which was trained on historical data, has been unable to foresee. It also disrupted the supply chain for products needed to renovate homes, extending turnaround time.
- The company bought 9,680 houses in the third quarter of 2021, but it sold only 3,032 at an average loss of $80,000 per property.
- Zillow has listed the majority of its remaining inventory in four major markets at prices lower than it paid, according to an analysis by Business Insider.
What the CEO said: “Fundamentally, we have been unable to predict future pricing of homes to a level of accuracy that makes this a safe business to be in,” Barton explained on the conference call. “We’ve got these new assumptions [based on experience buying and selling houses] that we’d be naïve not to assume will happen again in the future we pump them into the model, and the model cranks out a business that has a high likelihood, at some point, of putting the whole company at risk.”
Behind the News: Zestimate began as an ensemble of roughly 1,000 non-machine-learning models tailored to local markets. Last summer, the company revamped it as a neural network incorporating convolutional and fully connected layers that enable it to learn local patterns while scaling to a national level. The company is exploring uses of AI in natural language search, 3D tours, chatbots, and document understanding, as senior vice president of AI Jasjeet Thind explained in DeepLearning.AI’s exclusive Working AI interview.
Why it matters: Zillow’s decision to shut down a promising line of business is a stark reminder of the challenge of building robust models. Learning algorithms that perform well on test data often don’t work well in production because the distribution of input from the real world departs from that of the training set (data drift) or because the function that maps input x to prediction y changes, so a given input demands a different prediction (concept drift).
We’re thinking: Covid-19 has wreaked havoc on a wide variety of models that make predictions based on historical data. In a world that can change quickly, teams can mitigate risks by brainstorming potential problems and contingencies in advance, building an alert system to flag data drift and concept drift, using a human-in-the-loop deployment or other way to acquire new labels, and assembling a strong MLOps team.
 |
Who Has the Best Face Recognition?
Face recognition algorithms have come under scrutiny for misidentifying individuals. A U.S. government agency tested over 1,000 of them to see which are the most reliable.
What’s new: The National Institute of Standards and Technology (NIST) released the latest results of its ongoing Face Recognition Vendor Test. Several showed marked improvement over the previous round.
How it works: More than 300 developers submitted 1,014 algorithms to at least one of four tests. The test datasets included mugshots of adults, visa photos, and images of child exploitation.
- The verification test evaluated one-to-one face recognition like that used by smartphones for face-ID security, customs officials to match travelers with passports, and law enforcement agencies to identify victims in photos. Top performers included entries by China’s SenseTime, Netherlands-based VisionLabs (whose work is illustrated in the video above), and the open-source project InsightFace.
- The identification test evaluated one-to-many algorithms such as those used by closed-circuit surveillance systems that find flagged individuals in crowds of people. Top performers included those from SenseTime, Japan’s NEC, and CloudWalk, a spin-out from the Chinese Academy of Sciences.
- A test for face morphing evaluated how well an algorithm could detect processing that aims to fool security systems by blending faces. Top performers included entries by Portugal’s University of Coimbra and Germany’s Darmstadt University of Applied Sciences.
- The agency also rated algorithms that assess image quality for face recognition with respect to factors like lighting and angle. Algorithms from U.S.-based Rank One and Russia-based Tevian performed best.
Behind the news: NIST has benchmarked progress in face recognition since 2000. The first test evaluated five companies on a single government-sponsored image database. In 2018, thanks to deep learning, more than 30 developers beat a high score set in 2013.
Why it matters: Top-scoring vendors including Clearview AI, NtechLab, and SenseTime have been plagued by complaints that their products are inaccurate, prone to abuse, and threatening to individual liberty. These evaluations highlight progress toward more reliable algorithms, which may help win over critics.
We’re thinking: Companies that make face recognition systems need to undertake rigorous, periodic auditing. The NIST tests are a great start, and we need to go farther still. For instance, ClearView AI founder Hoan Ton-That called his company's high score on the NIST one-to-one task an “unmistakable validation” after widespread critiques of the company’s unproven accuracy and lack of transparency. Yet ClearView AI didn’t participate in the test that evaluated an algorithm’s ability to pick out an individual from a large collection of photos — the heart of its appeal to law enforcement.
A MESSAGE FROM DEEPLEARNING.AI
-1.png?upscale=true&width=1200&upscale=true&name=The%20Batch%20Image%20(1)-1.png) |
Have you checked out the updated Natural Language Processing Specialization? Courses 3 and 4 now cover state-of-the-art techniques with new and refreshed lectures and labs! Enroll now
 |
This Chatbot Does Its Research
Chatbots often respond to human input with incorrect or nonsensical answers. Why not enable them to search for helpful information?
What's new: Mojtaba Komeili, Kurt Shuster, and Jason Weston at Facebook devised a chatbot that taps knowledge from the internet to generate correct, timely conversational responses.
Key insight: A chatbot typically knows only what it has learned from its training set. Faced with a subject about which it lacks information, it can only make up an answer. If it can query a search engine, it can gather information it may lack.
How it works: The chatbot comprised two BART models. To train and test the system, the authors built a dataset of roughly 10,000 search-assisted dialogs. One human conversant chose a topic and started the conversation, while another, if necessary, queried a search engine and formulated replies. The authors tracked which statements led to a search, and which statements and searches led to which responses.
- The authors trained one BART to take a dialogue-in-progress as input and generate the associated search query. The search engine returned five documents per query.
- The authors trained the other BART to generate representations of each document and the dialog in progress, concatenate the representations, and generate the response.
Results: Human volunteers chatted with both the authors’ system and a BART model without internet access, and scored the two according to various metrics. They rated the authors’ chatbot more consistent (76.1 percent versus 66.5 percent), engaging (81.4 percent versus 69.9 percent), knowledgeable (46.5 percent versus 38.6 percent), and factually correct (94.7 percent versus 92.9 percent).
Why it matters: This work enables chatbots to extend and update their knowledge on the fly. It may pave the way to more conversational internet search as well as a convergence of conversational agents and intelligent assistants like Siri, Google Assistant, and Alexa, which already rely on internet search.
We're thinking: When it comes to chatbots, things are looking up!
 |
Who Can Afford to Train AI?
The cost of training top-performing machine learning models has grown beyond the reach of smaller companies. That may mean less innovation all around.
What’s new: Some companies that would like to build a business on state-of-the-art models are settling for less, Wired reported. They’re exploring paths toward higher performance at a lower price.
How it works: Models are getting larger, and with them, the amount of computation necessary to train them. The cost makes it hard to take advantage of the latest advances.
- Glean, which provides tools for searching workplace chat, sales, and other apps, doesn’t have the money to train large language models that would improve its products. Instead, it has turned to smaller, less capable models, software engineer Calvin Qi told Wired.
- Optum, a health benefits provider, spends upward of $50,000 per model for training in the cloud. It’s considering purchasing specialized hardware to speed up the process, according to Dan McCreary, a distinguished engineer at the company.
- Matroid, which offers a computer vision platform, uses its own GPUs supplemented by cloud computing to train transformers for “under $100,000 for the largest models,” founder Reza Zadeh told The Batch. At inference, it cuts compute costs via parameter pruning, quantization, low-rank factorizations, and knowledge distillation.
- Mosaic ML is a startup working on techniques to make training more efficient. Its executive team includes Michael Carbin and Jonathan Frankel. They formulated the “lottery ticket hypothesis,” which posits that only a portion of a neural network is responsible for much of its performance.
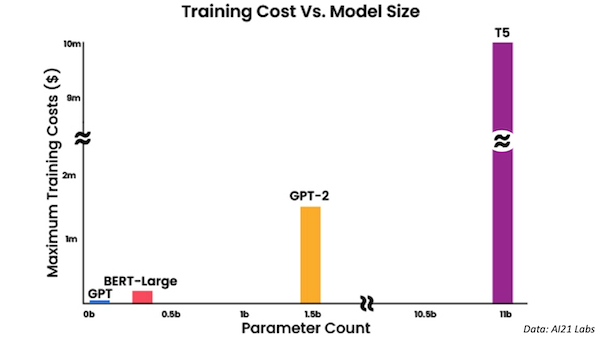
Behind the news: In 2020, researchers estimated the cost of training a model of 1.5 billion parameters (the size of OpenAI’s GPT-2) on the Wikipedia and Book corpora at $1.6 million. They gauged the cost to train Google’s Text-to-Text Transformer (T5), which encompasses 11 billion parameters, at $10 million. Since then, Google has proposed Switch Transformer, which scales the parameter count to 1 trillion — no word yet on the training cost.
Why it matters: The growing importance of AI coupled with the rising cost of training large models cuts into a powerful competitive advantage of smaller companies: Their ability to innovate without being weighed down by bureaucratic overhead. This doesn't just hurt their economic prospects, it slows down the emergence of ideas that improve people’s lives and deprives the AI community of research contributions by small players.
We’re thinking: A much bigger model often can perform much better on tasks in which the data has a long tail and the market supports only one winner. But in some applications — say, recognizing cats in photos — bigger models deliver diminishing returns, and even wealthy leaders won’t be able to stay far ahead of competitors.