
Dear friends,
Building AI products and businesses requires making tough choices about what to build and how to go about it. I’ve heard of two styles:
- Ready, Aim, Fire: Plan carefully and carry out due diligence. Commit and execute only when you have a high degree of confidence in a direction.
- Ready, Fire, Aim: Jump into development and start executing. This allows you to discover problems quickly and pivot along the way if necessary.
Say you’ve built a customer-service chatbot for retailers, and you think it could help restaurants, too. Should you take time to study the restaurant market before starting development, moving slowly but cutting the risk of wasting time and resources? Or jump in right away, moving quickly and accepting a higher risk of pivoting or failing?
Both approaches have their advocates, but I think the best choice depends on the situation.
Ready, Aim, Fire tends to be superior when the cost of execution is high and a study can shed light on how useful or valuable a project could be. For example, if your team can brainstorm a few other use cases (restaurants, airlines, telcos, and so on) and evaluate these cases to identify the most promising one, it may be worth taking the extra time before committing to a direction.

Ready, Fire, Aim tends to be better if you can execute at low cost and, in doing so, determine whether the direction is feasible and discover tweaks that will make it work. For example, if you can build a prototype quickly to figure out if users want the product, and if canceling or pivoting after a small amount of work is acceptable, then it makes sense to consider jumping in quickly. (When taking a shot is inexpensive, it also makes sense to take many shots. In this case, the process is actually Ready, Fire, Aim, Fire, Aim, Fire, Aim, Fire.)
After agreeing upon a product direction, when it comes to building a machine learning model that’s part of the product, I have a bias toward Ready, Fire, Aim. Building models is an iterative process. For many applications, the cost of training and conducting error analysis is not prohibitive. Furthermore, it is very difficult to carry out a study that will shed light on the appropriate model, data, and hyperparameters. So it makes sense to build an end-to-end system quickly and revise it until it works well.
But when committing to a direction means making a costly investment or entering a one-way door (meaning a decision that’s hard to reverse), it’s often worth spending more time in advance to make sure it really is a good idea.
Keep learning!
Andrew
News

Dances With Robots
Tesla unveiled its own AI chip and — surprise! — plans for a humanoid robot.
What’s new: At Tesla’s AI Day promotional event, the company offered a first look at an upcoming self-driving computer powered by custom AI chips. To make sure the event got headlines, CEO Elon Musk teased a forthcoming android.
Chips and bots: Company executives explained how the company trains models, labels data, and meets various AI challenges. Then they dove into what’s ahead:
- Tesla claims that Dojo will process computer vision data four times faster than existing systems, enabling the company to bring its self-driving system to full autonomy. The first Dojo cluster will be running by next year.
- The computer is based on D1, an AI training chip designed in-house. Three thousand D1s can be ganged together to deliver more processing power and network bandwidth than typical training rigs.
- The same technology that undergirds Tesla’s cars will drive the forthcoming Tesla Bot, which is intended to perform mundane tasks like grocery shopping or assembly-line work. Its design spec calls for 45-pound carrying capacity, “human-level hands,” and a top speed of 5 miles per hour (so humans can outrun it).
- Rather than showing a working prototype, Musk presented a human dancing in a bodysuit. He said a prototype would be ready next year. (Musk frequently exaggerates Tesla’s capabilities.)
Behind the news: Tesla’s Autopilot system has recently come under government scrutiny. Last week, the U.S. National Highway Traffic Safety Administration launched an investigation into 11 incidents in which Tesla vehicles using Autopilot collided with parked emergency vehicles. If the agency finds Autopilot at fault, it could require the company to change or recall its technology.
Why it matters: Tesla’s promise of full self-driving capability was premature, but Dojo’s muscled-up computing power could bring it substantially closer. As for the Tesla Bot, we’re not holding our breath.
We’re thinking: Tesla’s genuine achievements — the innovative electric car, charging infrastructure, driver-assistance capabilities — may be overshadowed by stunts like the dancer in the bodysuit. History will decide whether Elon Musk is remembered as a genius at engineering or marketing.
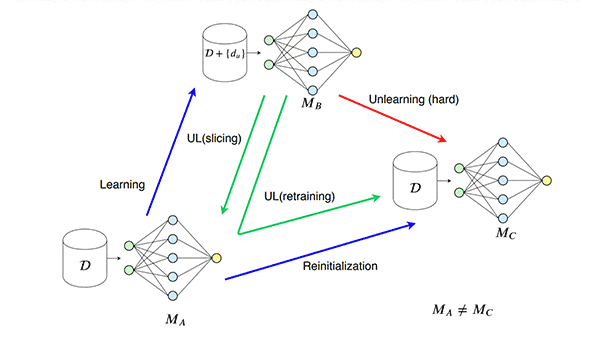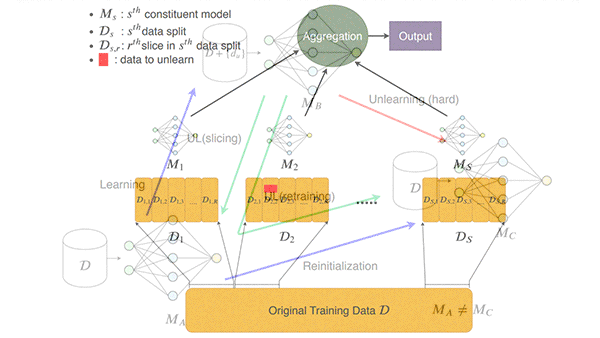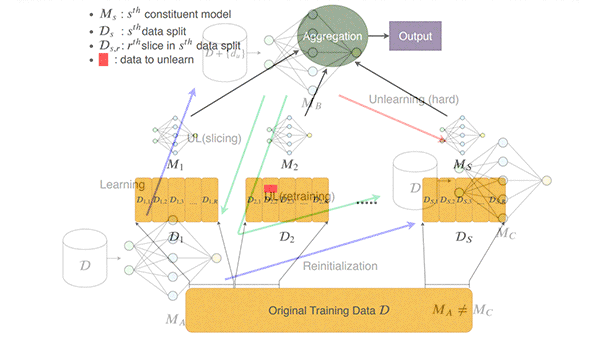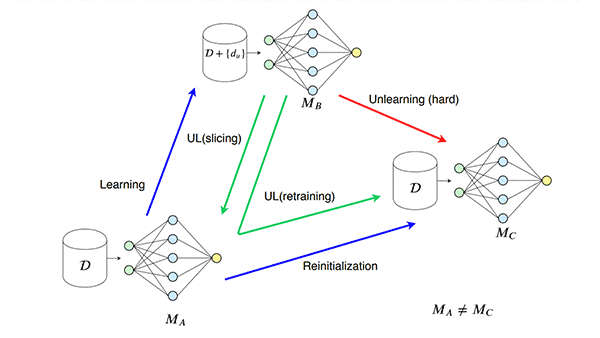
Deep Unlearning
Privacy advocates want deep learning systems to forget what they’ve learned.
What’s new: Researchers are seeking ways to remove the influence of particular training examples, such as an individual’s personal information, from a trained model without affecting its performance, Wired reported.
How it works: Some researchers have experimented with preparing data prior to training for potential removal later, while others have worked to remove the effect of selected examples retroactively.
- Researchers from the Universities of Toronto and Wisconsin-Madison developed a training method called SISA in which different versions of a model are trained on non-overlapping subsets of the same dataset. During inference, they combine the predictions from each model via majority vote. This makes it possible to remove selected training examples and retrain only the model associated with their subset.
- A team at Harvard, Stanford, and University of Pennsylvania later showed that SISA would fail to remove the influence of data if the requests to do so weren’t randomly distributed. The team mitigated this problem by introducing noise in the training algorithm based on ideas from differential privacy.
- Researchers from Google, Cornell, and University of Waterloo showed how to remove the impact of a training example on a model’s weights if its loss function meets certain mathematical conditions.
Behind the news: Evolving data privacy laws could wreak havoc on machine learning models.
- The European Union’s General Data Privacy Regulation includes a “right to be forgotten” that could force companies retroactively to remove the influence of specific data from trained models, some observers argue.
- California’s Privacy Rights Act gives citizens the right to know how their data is being used and request that it be deleted, even if it has been sold to a third party.
Why it matters: Enabling models to unlearn selectively and incrementally would be less costly than retraining repeatedly from scratch. It also could give users more control over how their data is used and who profits from it.
We’re thinking: Wait … what was this article about?
A MESSAGE FROM DEEPLEARNING.AI

Mark your calendar: We’re launching “Deploying Machine Learning Models in Production,” Course 4 of the Machine Learning Engineering for Production (MLOps) Specialization, on September 8, 2021! Pre-enroll now

Full-Bodied With Hints of Forest Fire
Wineries in areas affected by wildfires are using machine learning to produce vintages that don’t taste like smoke.
What’s new: Some California winemakers are using a service called Tastry to identify grapes tainted by smoke from the state’s surging blazes and recommend blends that will mask the flavor, The Wall Street Journal reported.
How it works: Called CompuBlend, Tastry’s system analyzes grapes’ chemical makeup, including smoke compounds absorbed through their skins. A model recommends other varieties that can mask the taste.
- The system was trained on the chemical composition of various grape varieties and consumer preferences gathered by surveying reactions to various flavors and aromas, such as the taste of coffee or the smell of cut grass.
- The model finds blends that both mask off-flavors and appeal to consumers.
Behind the news: The ancient art of winemaking is adopting AI.
- VineScout is an autonomous wheeled robot that uses lidar and ultrasonic cameras to navigate rows of grapes while analyzing soil conditions.
- Diam Bouchage, a cork manufacturer, assesses quality with a machine learning tool that analyzes x-ray images of individual corks.
- Ailytic, an Australian company, built a machine learning platform that helps winemakers monitor aspects of their manufacturing process such as temperature and bottle inventory.
Why it matters: Wildfires are a growing threat to wine regions in Australia, California, and France. They cost the industry an estimated $3.7 billion in 2020. AI could help vintners recoup some of the losses.
We’re thinking: While there's a clear need to adapt to human-induced climate change, it’s tragic that the planet has heated to the point that formerly temperate areas are burning. We applaud the work of Climate Change AI.

Ask Me in a Different Way
Pretrained language models like GPT-3 have shown notable proficiency in few-shot learning. Given a prompt that includes a few example questions and answers (the shots) plus an unanswered question (the task), such models can generate an accurate answer. But there may be more to getting good results.
What’s new: Ethan Perez, Douwe Kiela, and Kyunghyun Cho subjected GPT-style language models to a test they call true few-shot learning. They found that the heralded few-shot success may depend on a well engineered prompt. The authors are based at New York University, Facebook, and CIFAR, respectively.
Key insight: Training a machine-learning model typically requires a validation set to tune hyperparameters such as the learning rate. For GPT-style models, those hyperparameters include the prompt format. In few-shot learning with a pretrained model, the prompt typically contains a handful of examples. However, researchers often experiment extensively to find a prompt format that yields accurate responses. This amounts to stacking the deck in the model’s favor, and without it, such models can’t perform so well.
How it works: The authors evaluated four sizes of GPT-3, four sizes of GPT-2, and DistilGPT-2. They tested prompt formats from LAMA, a benchmark that comprises factual statements in a variety of formats, and LPAQA, which contains LAMA statements translated from English into a different language and back.
- LAMA provides statements in 41 categories, such as “X was born in Y,” where X is a personal name and Y is a place, and “X was created by Y,” where X is the name of a company and Y is the name of a product. It presents each statement in an average of 12 formats. For instance, “X was created by Y” is also formatted “X is developed by Y” and “X is being developed by Y.”
- The authors assembled prompts made of five such statements, all in the same category and format, in which the last word was missing, such as, “The iPhone is being developed by _.” The missing word is, of course, “Apple.” They provided versions of these prompts in all 120 possible orders of the five statements, always with the final word missing, prompting the model to fill in the blank.
- They used cross-validation to find the prompt format that, given four complete and one incomplete examples, prompted the best performance on average across all formats and categories.
- For each model, they compared performance prompted by the best format according to cross-validation, the format associated with the highest accuracy on the test set, and the mean accuracy on the test set across all formats and categories.
Results: For all models tested, the accuracy prompted by the format selected according to cross-validation was only marginally above the mean and significantly below the accuracy of the best format. For instance, for the largest model (GPT-3 with 175 billion parameters), the format chosen by cross-validation scored about 55 percent, mean accuracy was about 54 percent, and the accuracy of the best format was about 60 percent.
Why it matters: Previous claims of few-shot learning in GPT-style models left out an important variable: the size of the dataset used to pick a good format. Choosing among 12 prompt formats boosted accuracy by around 5 percent; choosing among a larger set of formats could make a bigger difference. If researchers don’t include all the information that went into the results they report, follow-up studies are unlikely to duplicate their work.
We’re thinking: We like prompt engineering that gets things done on time. We’re less enamored with prompt engineering that muddies the water around few-shot learning.