
Dear friends,
How much math do you need to know to be a machine learning engineer? It’s always nice to know more math! But there’s so much to learn that, realistically, it’s necessary to prioritize. Here are some thoughts about how you might go about strengthening your math background.
To figure out what’s important to know, I find it useful to ask what you need to know to make the decisions required for the work you want to do. At DeepLearning.AI, we frequently ask, “What does someone need to know to accomplish their goals?” The goal might be building a machine learning model, architecting a system, or passing a job interview.
Understanding the math behind algorithms you use is often helpful, since it enables you to debug them. But the depth of knowledge that’s useful changes over time. As machine learning techniques mature and become more reliable and turnkey, they require less debugging, and a shallower understanding of the math involved may be sufficient to make them work.
For instance, in an earlier era of machine learning, linear algebra libraries for solving linear systems of equations (for linear regression) were immature. I had to understand how these libraries worked so I could choose among different libraries and avoid numerical roundoff pitfalls. But this became less important as numerical linear algebra libraries matured.

Deep learning is still an emerging technology, so when you train a neural network and the optimization algorithm struggles to converge, understanding the math behind gradient descent, momentum, and the Adam optimization algorithm will help you make better decisions. Similarly, if your neural network does something funny — say, it makes bad predictions on images of a certain resolution, but not others — understanding the math behind neural network architectures puts you in a better position to figure out what to do.
Sometimes, we’re told that an idea is “foundational.” While there’s a lot to be said for understanding foundations, often this designation is arbitrary and thus not very useful for prioritizing what to study next. For example, computing happens on processors that are packed with transistors. Do you need a deep understanding of how transistors work to write software? It's hard to imagine an AI application where a detailed knowledge of the physics of transistors would affect your decisions.
Rather than accepting an authority’s decree that a topic is foundational, it’s worth asking what circumstances would require specific knowledge to help you make better decisions.
Of course, I also encourage learning driven by curiosity. If something interests you, go ahead and learn it regardless of how useful it will be in the foreseeable future. Maybe this will lead to a creative spark or technical breakthrough.
Keep learning!
Andrew
News
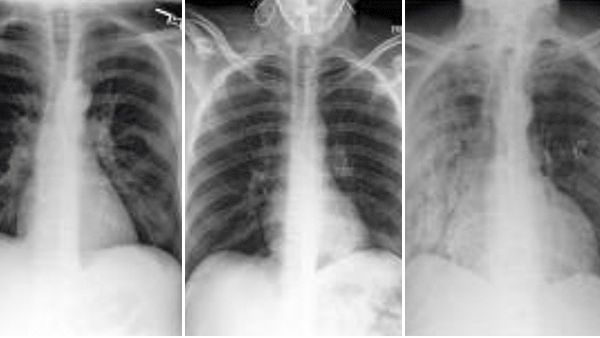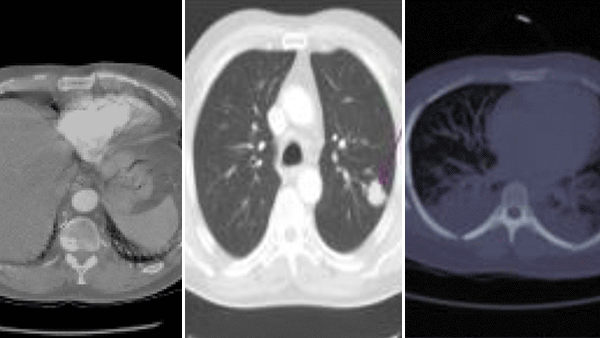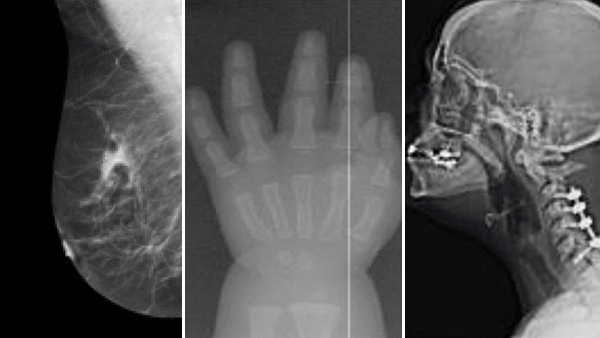
AI Sees Race in X-Rays
Algorithms trained to diagnose medical images can recognize the patient’s race — but how?
What’s new: Researchers from Emory University, MIT, Purdue University, and other institutions found that deep learning systems trained to interpret x-rays and CT scans also were able to identify their subjects as Asian, Black, or White.
What they found: Researchers trained various implementations of ResNet, DenseNet, and EfficientNet on nine medical imaging datasets in which examples were labeled Asian, Black, or White as reported by the patient. In tests, the models reliably recognized the race, although their performance varied somewhat depending on the type of scan, training dataset, and other variables.
- The models were pretrained on ImageNet and fine-tuned on commonly used datasets of chest, limb, breast, and spinal scans.
- The ResNet identified the patient’s race most accurately: 80 to 97 percent of the time.
- The authors tried to determine how the models learned to differentiate races. Factors like body mass, tissue density, age, and sex had little bearing, they found. The models were able to guess the patient’s race even when the images had been blurred.
Behind the news: Racial bias has been documented in some medical AI systems.
- In 2019, researchers found that an algorithm widely used by health care providers to guide treatment recommended extra care for Black patients half as often as it did White patients.
- Several studies have found that convolutional neural networks trained to detect skin cancer are less accurate on people with darker complexions.
- Most ophthalmology datasets are made up of data from Chinese, European, and North American patients, which could make models trained on them to recognize eye diseases less reliable with groups that aren’t well represented in those regions.
Why it matters: The fact that diagnostic models recognize race in medical scans is startling. The mystery of how they do it only adds fuel to worries that AI could magnify existing racial disparities in health care.
We’re thinking: Neural networks can learn in ways that aren’t intuitive to humans. Finding out how medical imaging algorithms learn to identify race could help develop less biased systems — and unlock other mysteries of machine learning.

Sharper Attention
Self-attention enables transformer networks to track relationships between distant tokens — such as text characters — in long sequences, but the computational resources required grow quadratically with input size. New work aims to streamline the process by rating each token’s relevance to the task at hand.
What’s new: Sainbayar Sukhbaatar and colleagues at Facebook proposed Expire-Span, which enables attention to ignore tokens that aren’t useful to the task at hand.
Key insight: Depending on the task, some tokens affect a model’s performance more than others. For instance, in predicting the sentiment of the sentence, “Then she cried,” “cried” is more important than “then.” By forgetting less relevant tokens, attention can process longer sequences with less computation.
How it works: The authors modified a transformer’s attention layers. They trained the model in typical fashion to predict the next character in a sequence using the enwik8 dataset of text from English Wikipedia. Given the first token, it predicted the next. Then, using the first two tokens, it predicted the next, and so on.
- To each attention layer, the authors added a vanilla neural network that predicted the number of times that attention should use each token. It assigned a value to each new token, subtracted 1 after each prediction, and deleted the token when the value reached 0.
- The loss function minimized the number of times the model used each token to keep it from assigning arbitrarily high values (otherwise, it could predict that every token should be used until the whole sequence had been processed). In this way, the model learned to retain only the tokens most useful to an accurate prediction.
Results: The authors evaluated Expire-Span based on total memory usage, training time per batch, and bits per byte (a measure of how well the model predicted the next token; lower is better). On enwik8, it achieved 1.03 bits per byte, while Adaptive-Span achieved 1.04 bits per byte and compressive transformer achieved 1.05 bits per byte. The authors’ model used 25 percent less GPU memory than the other two approaches (15GB versus 20GB and 21GB respectively). It also took less time to train (408ms per batch of 512 tokens compared to 483ms and 838ms).
Why it matters: Forgetting the least relevant information enables transformers to process longer sequences in less time and memory.
We’re thinking: Q: What do you do if a transformer forgets too much? A: Give it an Optimus Primer.
A MESSAGE FROM FACTORED

Factored, a sister company of DeepLearning.AI that helps ambitious Silicon Valley-based companies build data science teams, is partnering with rigorously vetted machine learning engineers, data engineers, and data analysts to work on your projects. Learn more

To Bee or Not to Bee
Insects that spread pollen to fruiting plants are in trouble. A possible alternative: Robots.
What’s new: Farmers in Australia and the U.S. are using robots from Israeli startup Arugga Farming to pollinate greenhouse tomatoes, The Wall Street Journal reported.
How it works: The system is designed for growing tomatoes, which self-pollinate when their pollen is stirred up by the beating of insect wings. Robots equipped with cameras, vision algorithms, and air compressors wheel themselves between rows of plants. When they recognize a flower that’s ready to produce fruit, they blast it with air to release its pollen.
- The company trained the computer vision system using tens of thousands of photos of tomato flowers shot in multiple greenhouses under a variety of lighting conditions.
- U.S. greenhouse grower AppHarvest tested the system. It found that the plants pollinated by robots produced a harvest comparable to those pollinated by bumblebees and much larger than those pollinated by hand.
- Costa Group Holdings, an Australian farming company that grows crops in vertical greenhouse arrays, recently tested two of the robots in a 25-acre facility. It plans to add more, aiming for a total of around 30.
Behind the news: A number of other companies are using AI-enabled robots to pollinate plants. Edete Precision Technologies has had success with almonds, and Bumblebee AI hopes to pollinate avocados, kiwis, and cocoa. Developed at West Virginia University, a robot called BrambleBee aims to pollinate blackberries, raspberries, and brambleberries.
Why it matters: Robotic pollinators may prove to be an important technology outside of greenhouses. Climate change and habitat loss are ravaging Earth’s insect populations including bees. Meanwhile, such machines could be helpful to farmers: Bees are expensive to rent, they can spread plant diseases, and importing them is restricted in places such as Australia.
We’re thinking: These robots are sure to generate a buzz.

Fresh Funds for U.S. Research
The U.S. plans to build nearly a dozen new civilian AI research labs.
What’s new: The U.S. National Science Foundation (NSF) committed $220 million to fund 11 National Artificial Intelligence Research Institutes, complementing seven other AI research institutes that were established last year.
What’s happening: The NSF grants provide each institute about $20 million annually over five years. Some will receive additional funding from public and private partners such as the U.S. Department of Homeland Security, Amazon, and Intel. Their missions include:
- Agriculture: Several institutes will focus on improving aspects of farming, including adapting to climate change, modeling plants, and developing security infrastructure for initiatives such as precision agriculture.
- Industry: Others will look at challenges like improving semiconductor design and building better robots. Two institutes will specialize in edge devices and wireless AI systems. Another is devoted to using AI models to optimize systems and automated decision-making.
- Scientific research: One institute will focus on algorithms and applications to control complex dynamic systems.
- Social good: A trio will seek to improve human life at various stages. One will focus on education for children, another on training for adults. A third institute will develop systems to care for elderly people.
Behind the news: The NSF funded an initial seven national AI institutes in September. Earlier, the U.S. had said it would spend $2 billion annually on AI over the next two years.
Why it matters: Other governments spend much more on AI than the U.S., and this outlay is small in the scheme of national AI funding. However, the allocation and the goals to which it is being put suggest that the federal government recognizes AI’s importance to the U.S. economy and its potential to benefit the world at large.
We’re thinking: U.S. government funding was critical to AI's rise. For example, the Defense Advanced Research Products Agency (DARPA) provided funds to both Andrew and Yann LeCun for deep learning research. We’re hopeful that these new programs will fund similarly valuable innovations.