
Dear friends,
I’ve been following with excitement the recent progress in space launches. Earlier this week, Richard Branson and his Virgin Galactic team flew a rocket plane 53 miles up, earning him astronaut wings. Next week, Jeff Bezos’ Blue Origin is expected to attempt a similar feat and achieve an even greater altitude. (I once also sat in a Blue Origin passenger capsule; see the picture below. I remained firmly on planet Earth.)
The first space race was between the U.S. and the Soviet Union, a competition between rival superpowers with dramatically different visions for civilization. Some pundits have panned the current space race as a contest between billionaires, but I’m glad that Bezos, Branson, and Elon Musk are pushing the boundaries of commercial flight.
I’ve found space exploration exhilarating since I was a child. My father had a passion for astronomy. We spent many hours on the rooftop of our apartment complex in Singapore — often staying up way past the bedtime designated by my mother 😅 — peering through my dad’s telescope at the planets in our solar system. I remember peering at Alpha Centauri (the closest star system to ours) and wondering if I would visit someday.

Space exploration has been criticized as a waste of resources, given the problems we have here at home. Of course, we need to work on problems such as the still-rampaging Covid-19, climate change, poverty, and injustice. I believe society will be best off if we pursue multiple meaningful projects simultaneously.
As we push further into space, AI will play an increasing role. Our robots will need to be increasingly autonomous because, even though radio waves travel at the speed of light, there won’t be sufficient time to wait for guidance from human operators on Earth. (Mars averages 13 light minutes from Earth, and the more distant Neptune about 250 light minutes.) I was excited when ROS, the open-source Robot Operating System framework launched by Morgan Quigley out of my Stanford group, started running in the International Space Station. And we still have much work ahead!
Private entities are at the center of this week’s space boom, but I would love to see public entities play a bigger role. NASA’s innovations have been widely shared. I’m excited about the Perseverance rover and Ingenuity helicopter now roaming Mars (over 1 million times farther than Branson has yet to travel). So let’s make sure to strongly support public space exploration as well. Further advances will come even faster with their help.
Keep learning! 🚀
Andrew
News

Walking the Dog
A reinforcement learning system enabled a four-legged robot to amble over unfamiliar, rapidly changing terrain.
What’s new: Researchers at UC Berkeley, Facebook, and Carnegie Mellon developed Rapid Motor Adaptation (RMA). The system enabled a Unitree Robotics A1 to negotiate changing conditions and unexpected obstacles nearly in real time. The machine traversed muddy trails, bushy backcountry, and an oil-slicked plastic sheet without falling.
How it works: The system includes two algorithms, both of which are trained in simulation. The reinforcement learning component learns to control locomotion basics, while the adaptation module learns to generate a representation of the environment.
- In deployment, the two algorithms run asynchronously on a single edge device. They analyze the previous 0.5 seconds of data from limbs and joints and adjust the gait accordingly.
- In tests, the robot maneuvered through conditions that it hadn’t encountered in simulations, such as a squishy foam mattress, over piles of rubble, and rough-hewn staircases. It repeated many of the tests carrying loads of varying weight.
- The machine achieved 70 percent or better success in each scenario. When it fell, the mishap typically was due to a sudden drop while descending stairs or debris that blocked more than one leg.
Behind the news: Video clips of robots from Boston Dynamics and others have become viral sensations in recent years. They may be mouth-watering, but the bots involved often are programmed for specific motions or scenarios and can’t adapt to novel conditions.
Why it matters: RMA is among the first robotic walking systems that don’t need to be trained for every variety of terrain they're likely to encounter.
We’re thinking: For many applications where navigating flat ground is sufficient, wheeled locomotion is much simpler and more reliable. But legs still carry the day when navigating rough terrain — not to discount their uncanny anthropomorphic appeal. They’re likely to be important for tasks like fighting fires, traversing disaster zones, and navigating the toy-strewn obstacle course that is Andrew’s daughter's playroom.
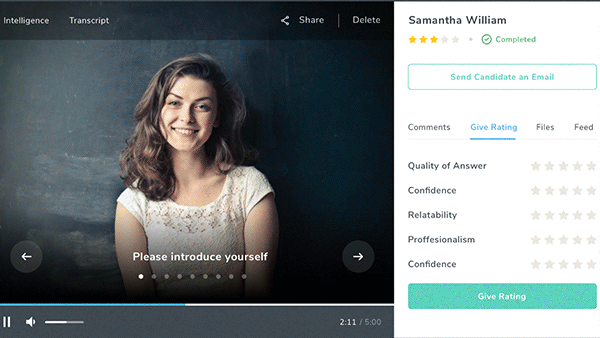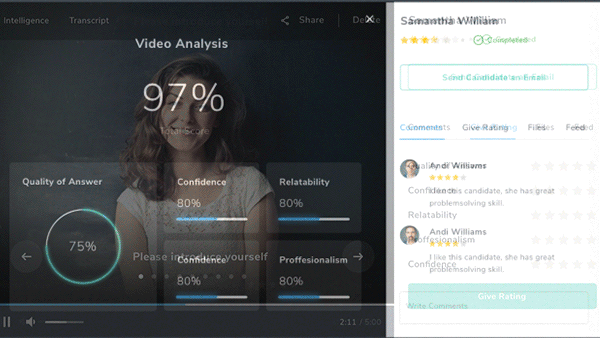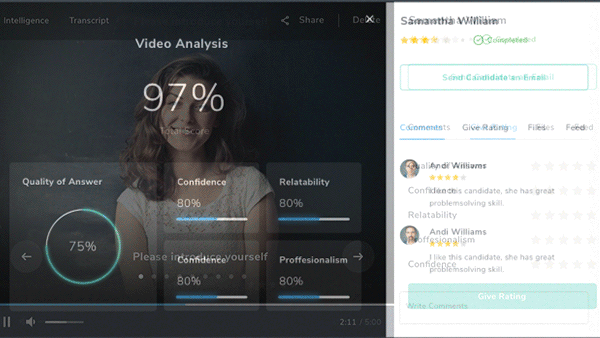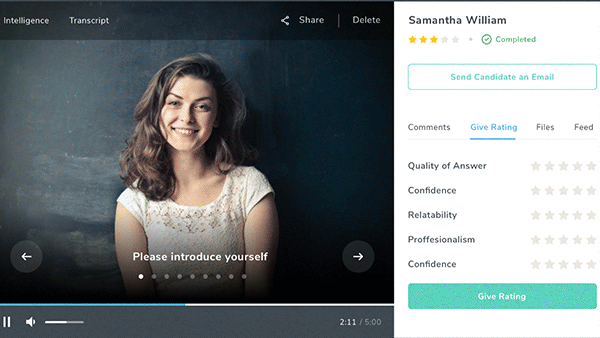
Danke for the Interview
An independent test found flaws in AI systems designed to evaluate job applicants.
What’s new: MyInterview and Curious Thing, which automate job interviews, gave a candidate who spoke only in German high marks on English proficiency, according to MIT Technology Review.
The test: Reporters created a fake job posting for an office administrator/researcher on both companies’ platforms. They used the tools provided to select questions for applicants to answer and define their ideal candidate. Then one of them applied for the position, completing interviews by reading aloud from a Wikipedia article written in German.
- MyInterview typically conducts a video interview and analyzes a candidate’s verbal and body language, then grades their suitability for a given job. MyInterview interpreted the German-speaking reporter’s responses as nonsensical English (“So humidity is desk a beat-up. Sociology, does it iron?”) but graded her as a 73 percent match for the job. A MyInterview spokesperson said the algorithm inferred personality traits from the interviewee’s voice rather the content of her answers.
- Curious Thing analyzes phone interview responses. Its algorithm gave the reporter 6 out of 9 points for English-language competency after she responded exclusively in German. The company’s cofounder said the bogus application was an “extremely valuable data point.”
Behind the news: A 2019 survey found that 40 percent of companies worldwide use AI to help screen job candidates, but outside investigators have found such systems lacking.
- In February, Bavarian Public Broadcasting showed that accessories like glasses and headscarves and backgrounds including objects like pictures and bookcases dramatically changed a German video-interview platform’s automated assessments.
- In 2018, LinkedIn discovered that a candidate recommendation algorithm preferred male applicants. The company replaced it with a new system intended to counteract that bias.
- A recent study from NYU, CUNY, and Twitter proposed a matrix for rating automated hiring systems to counteract the prevalence of algorithms that rely on dubious features like voice intonation and subtle facial expressions.
Why it matters: Matching prospective employers and employees is a nuanced process, and any attempt to automate it requires the utmost rigor. Applicants subject to a flawed algorithm could be barred from jobs they’re eminently qualified for, while prospective employers who rely on it could miss ideal candidates.
We’re thinking: An AI system that gives high marks to someone who replies to an English-language interview in German — confidently rendering incorrect predictions in response to data that’s dramatically different its training set — is not equipped to handle data drift. Such concepts are not purely academic. They have a huge impact on such systems — and on critical decisions like who gets a job.
A MESSAGE FROM DEEPLEARNING.AI

“Optimize ML Models and Deploy Human-in-the-Loop Pipelines,” Course 3 in our new Practical Data Science Specialization, is set to launch on July 21, 2021! Harness human intelligence to tune accuracy, compare performance, and generate new training data. Pre-enroll now
I Know It When I See It
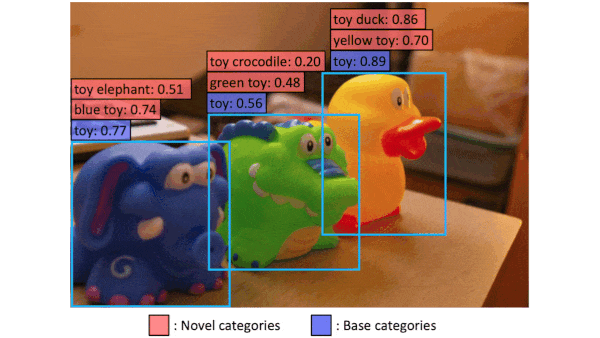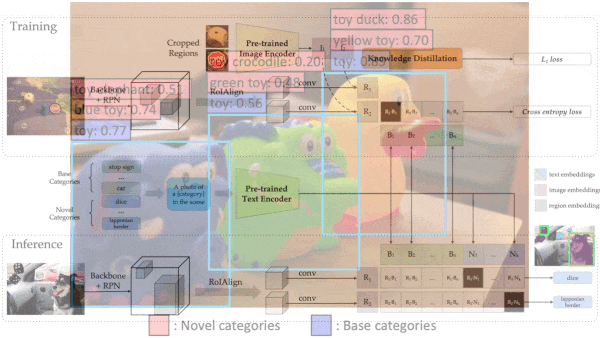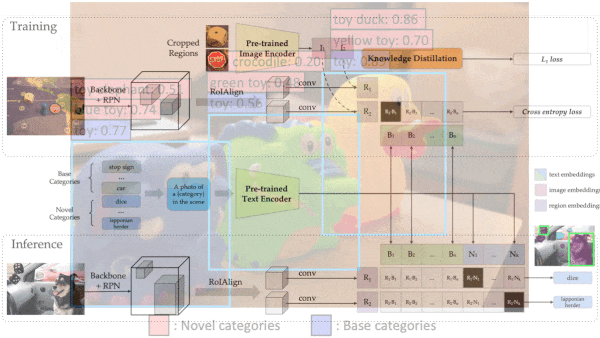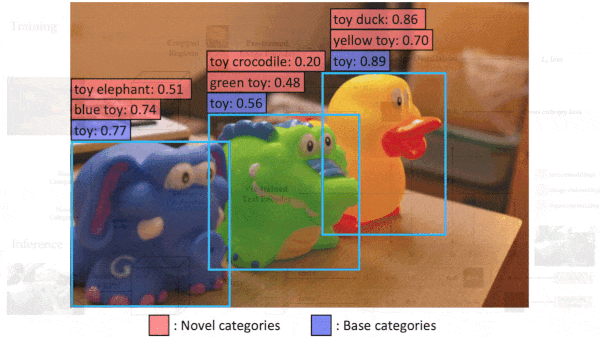
Object detectors typically detect only items that were labeled in their training data. A new method liberates them to locate and recognize a much wider variety of objects.
What’s new: Xiuye Gu and colleagues at Google Research developed Vision and Language Knowledge Distillation (ViLD) to build a zero-shot object detector — that is, one that can handle classes on which it didn’t train. ViLD takes advantage of representations generated by the pretrained zero-shot classifier CLIP.
Key Insight: In knowledge distillation, one model learns to mimic another model’s output. Similarly, one model can learn to mimic another’s representations. An object detector’s representations (which encode several regions and classifications per image) can conform to a classifier’s (which encode one classification per image) by cropping the images that contain multiple objects into separate regions for the classifier. Then the object detector can learn to reproduce the classifier’s representation of each region.
How it works: To understand ViLD, it helps to know a bit about CLIP. CLIP matches images and text using a vision transformer and a text transformer pretrained on 400 million image-text pairs. At inference, users give it a text list of the classes they want to recognize. Fed an image, it returns the most likely class in the list. To that system, the authors added a Mask R-CNN object detector trained on the most common classes in Large Vocabulary Instance Segmentation (LVIS), a dataset that contains images of objects that have been segmented and labeled. They reserved the other LVIS classes for the test set.
- Given a list of LVIS classes, CLIP’s text transformer generated a list of class representations.
- Given an image, Mask R-CNN generated object representations. In parallel, CLIP’s vision transformer generated corresponding cropped-region representations.
- For each Mask R-CNN object representation, the authors found the closest LVIS class representation. They measured similarity using cosine similarity, a measure of the angle between two vectors, and applied a softmax to predict the object’s class.
- They trained the Mask R-CNN using two loss terms. The first minimized the difference between CLIP’s and Mask R-CNN’s representations. The second encouraged the Mask R-CNN’s predicted class of a region to match the known label.
- At inference, they fed the remaining LVIS classes to CLIP and added the text transformer’s representations to the earlier list. Presented with a new object class, the Mask R-CNN generated a representation, and the authors found the closest LVIS class representation in the list.
Results: The authors pitted their system against a Mask R-CNN trained on all LVIS classes in a supervised manner. They compared average precision, a measure of how many objects were correctly identified in their correct location (higher is better). The author’s system achieved 16.1 average precision on novel categories, while the supervised model’s achieved 12.3 average precision.
Why it matters: Large, diverse training datasets for object detection are difficult and expensive to obtain. ViLD offers a way to overcome this bottleneck.
We’re thinking: Physicists who want to classify a Bose-Einstein condensate need absolute-zero-shot object detection.

CLIP Art
Creative engineers are combining deep learning systems to produce a groundswell of generated imagery.
What’s new: Researchers, hackers, and artists are producing new works by pairing CLIP, a pretrained image classifier, with a generative adversarial network (GAN). UC Berkeley researcher Charlie Snell captured the ferment in a blog post.
How it works: Users typically give CLIP a text list of the classes they want to recognize; given an image, it returns the most likely class in the list. Digital artists, on the other hand, feed CLIP a verbal description of an image they want to produce and use its ability to match text with images to guide a GAN.
- The community has developed a set of Google Collab Notebooks that link CLIP with various GANs. A user types a phrase, sets some parameters, and chooses which GAN to use for image generation.
- Once the GAN has generated an image, CLIP scores it based on how closely it matches the original phrase. The Collab code then adjusts the GAN’s hyperparameters iteratively, so its output earns a higher score from CLIP. It repeats the cycle of generation and adjustment until CLIP’s score exceeds a threshold set by the user.
- Different GANs yield images with different visual characteristics. For instance, pairing CLIP with BigGAN produces output that tends to look like an impressionist painting. Pairing CLIP with VQ-GAN produces more abstract images with a cubist look.
- Adding to the prompt a phrase like “rendered in Unreal Engine,” referring to a popular video game renderer, can drastically improve the quality of the generated output.
Behind the news: Open AI has its own image generator, DALL·E. Reportedly its output is less abstract and fanciful.
Why it matters: CLIP was built to classify, not co-create, while GANs were developed to produce variations on familiar images. The boomlet in generated art shows how the creative impulse can unlock potential that engineers may not have imagined.
We’re thinking: It’s great to see human artists collaborating with neural networks. It’s even better to see neural networks collaborating with one another!