
A new breed of audio generator produces synthetic performances of songs in a variety of popular styles.
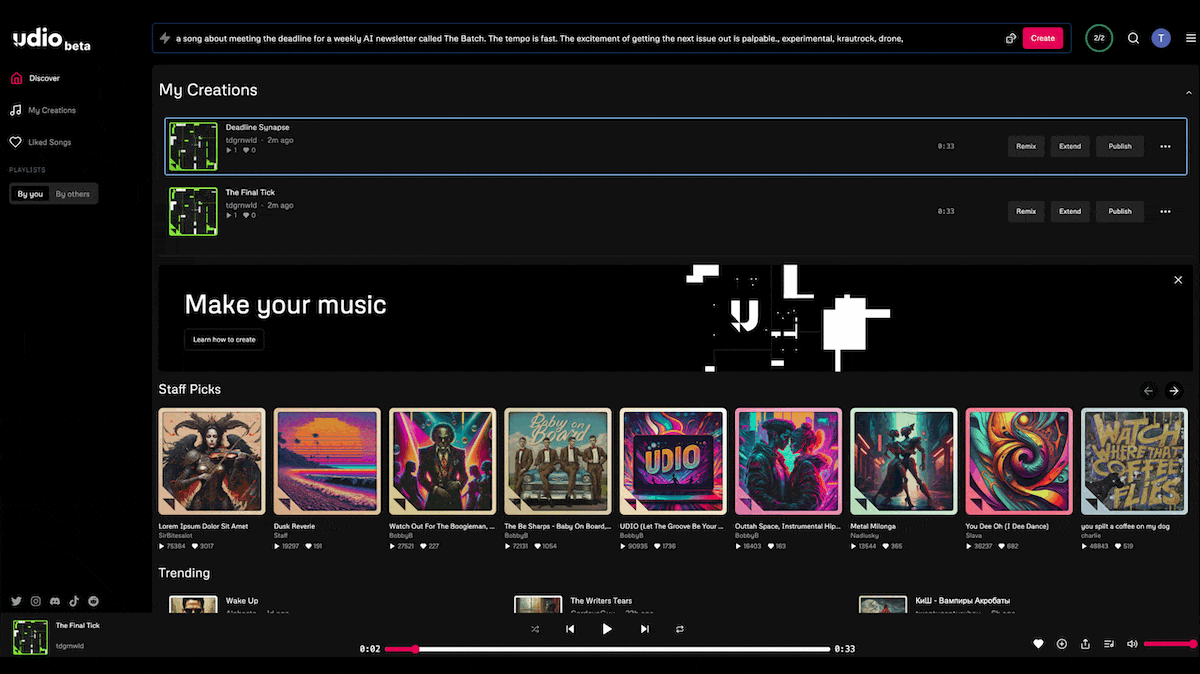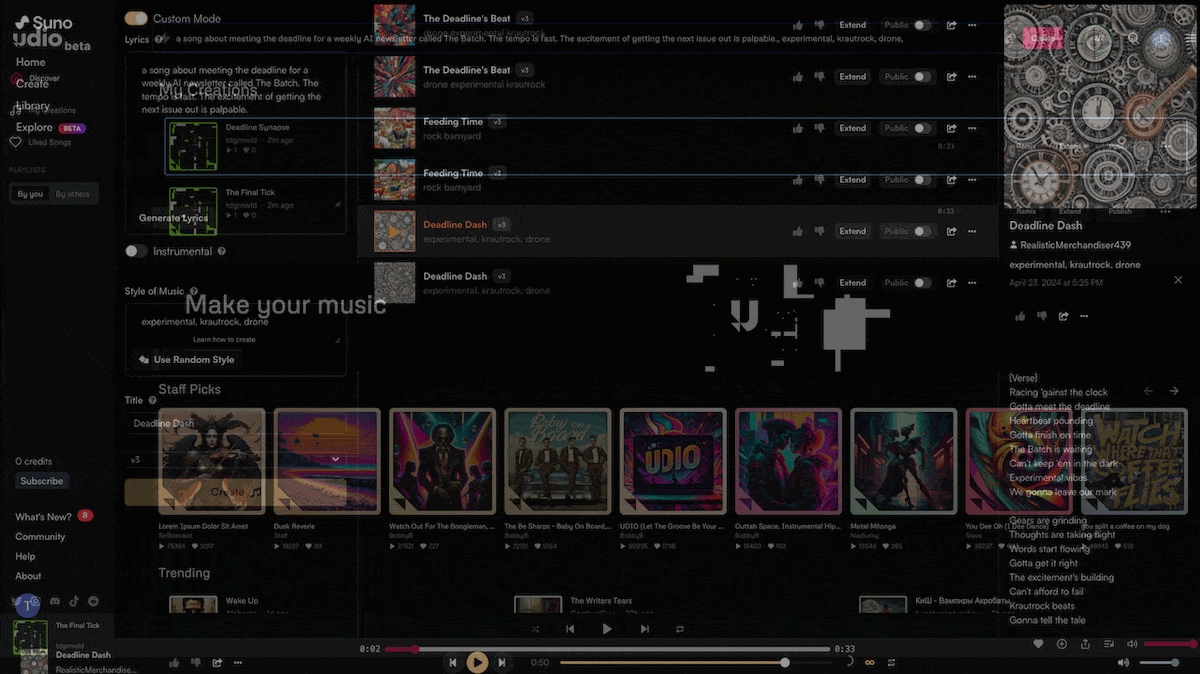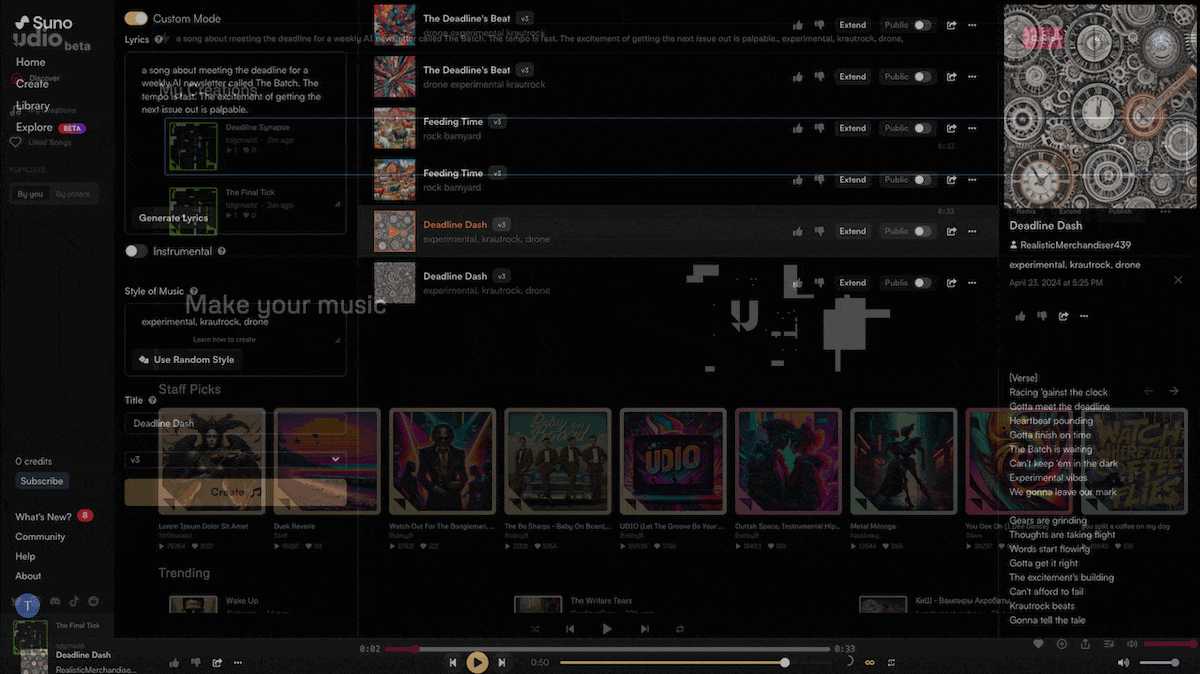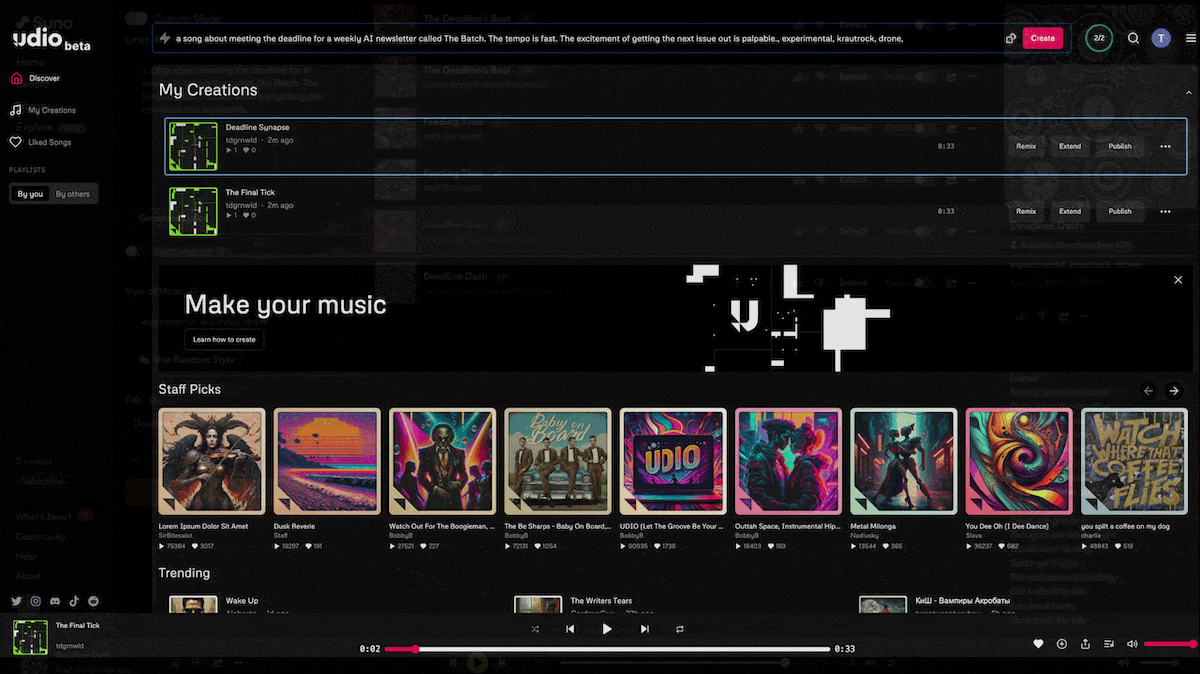
What’s new: Udio launched a web-based, text-to-song generator that creates songs in styles from barbershop to heavy metal. Suno, which debuted its service late last year with similar capabilities, upgraded to its offering.
How it works: Both services take text prompts and generate full-band productions complete with lyrics, vocals, and instrumental solos, two separate generations per prompt. Users can generate lyrics to order or upload their own words, and they can download, share, and/or post the results for others to hear. Leaderboards rank outputs according to plays and likes.
- Founded by alumni of Google’s DeepMind division, Udio lets registered users generate up to 1,200 songs monthly for free and expects to offer paid services at an unspecified future date. Users enter a text prompt and/or choose style tags. The system automatically replaces artist names with stylistic descriptions but sometimes produces results that sound uncannily like the artists requested. Users can choose to generate an instrumental track or add lyrics, allocating them to verse, chorus, or background vocals. Udio generates audio segments 33 seconds long, which users can extend, remix, and modify. The company has not released information about the underlying technology.
- Suno lets users generate 10 songs daily for free or pay to generate more. Enter a prompt, and the system generates complete songs up to 2 minutes long; alternatively, users can specify lyrics, style, and title in separate prompts. The system refuses to generate music from prompts that include the name of a real-world artist. Suno hasn’t disclosed technical information, but last year it released an open-source model called Bark that turns a text prompt into synthetic music, speech, and/or sound effects.
Behind the news: Most earlier text-to-music generators were designed to produce relatively free-form instrumental compositions rather than songs with structured verses, choruses, and vocals. Released earlier this month, Stable Audio 2 generates instrumental tracks up to three minutes long that have distinct beginnings, middles, and endings. Users can also upload audio tracks and use Stable Audio 2.0 to modify them.
Yes, but: Like text-to-image generators circa last year, current text-to-music models offer little ability to steer their output. They don’t respond consistently to basic musical terminology such as “tempo” and “harmony,” and requesting a generic style like “pop” can summon a variety of subgenres from the last 50 years of popular music.
Why it matters: With the advent of text-to-music models that produce credible songs, audio generation seems primed for a Midjourney moment, when the public realizes that it can produce customized music at the drop of a prompt. Already Udio’s and Suno’s websites are full of whimsical paeans to users’ pets and hobbies. The technology has clear implications for professional performers and producers, who, regrettably, have little choice but to adapt to increasing automation. But for now fans have fun, new toys to play with.
We’re thinking: You can dance to these algo-rhythms!