
How accurate are machine learning models that were trained on data produced by other models? Researchers studied models that learned from data generated by models that learned from data generated by still other models.
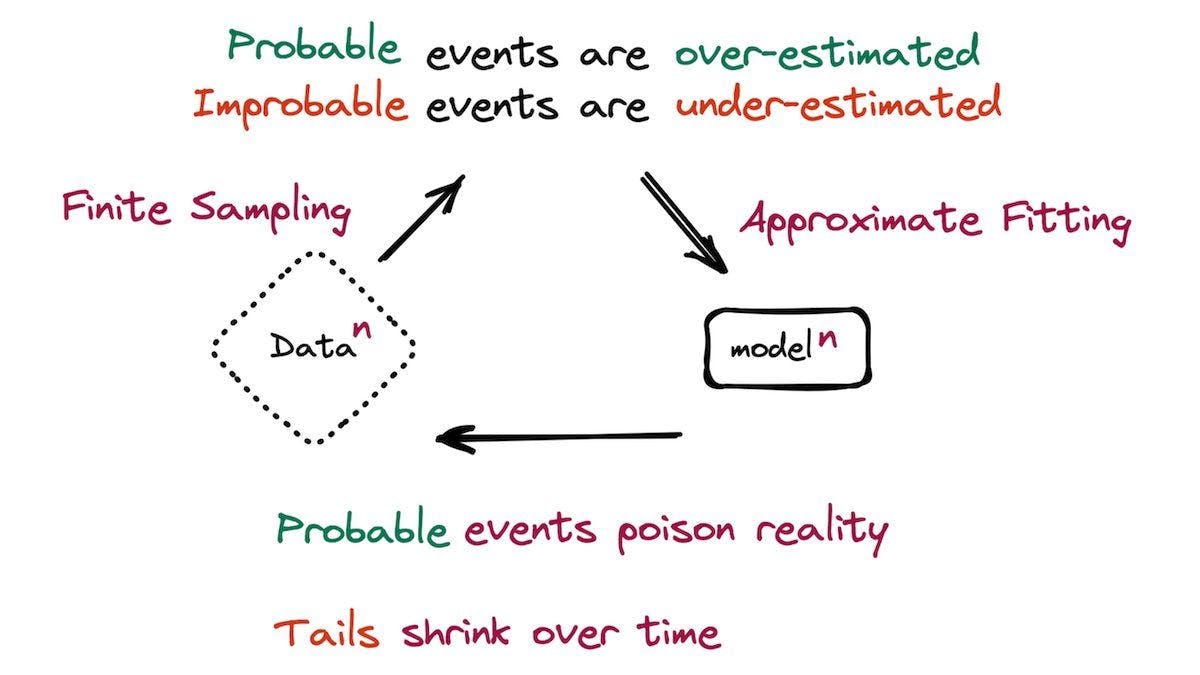
What’s new: Ilia Shumailov and Zakhar Shumaylov and colleagues at University of Oxford, University of Cambridge, Imperial College London, University of Toronto, Vector Institute, and University of Edinburgh argue — both theoretically and empirically — that models, when they’re trained almost exclusively on the output of earlier models, learn a distorted data distribution.
Key insight: Trained models are less likely to generate types of examples that appear infrequently in their training data. Moreover, they don’t model their training data perfectly, so their output doesn’t quite match the distribution of the training dataset. They may combine elements from training examples. When one model learns from another in a series, errors accumulate — a phenomenon the authors call model collapse.
How it works: The authors trained models of different types. First they trained a model on a human-collected and -curated dataset — generation 0. Then they trained generation 1 of the same architecture on the output of generation 0, generation 2 on the output of generation 1, and so on. In some cases, they replaced a fraction of the generated examples with examples from the original training set.
- The authors trained a Gaussian mixture model (GMM), which assumed that input data came from a pair of 2-dimensional Gaussian distributions and clustered the data to fit them. They trained 2,000 generations of GMMs on 1,000 examples generated by the previous-generation model, using no original data.
- They trained a variational autoencoder (VAE) to generate MNIST digits over 20 generations. As with the GMMs, they trained each successive generation only on output produced by the previous generation.
- They fine-tuned a pretrained OPT language model (125 million parameters) on WikiText-2. They fine-tuned 9 subsequent generations (i) only on examples produced by the previous generation and (ii) on a mixture of 90 percent data from the previous generation and 10 percent original training data.
Results: The first-generation GMM recognized the Gaussians as ellipses, but each successive generation degraded their shape. By generation 2,000, the shape had collapsed into a tiny region. Similarly, the late-generation VAEs reproduced MNIST digits less accurately; by generation 20, the output looked like a blend of all the digits. As for the OPT language models, generation 0 achieved 34 perplexity (which measures how unlikely the model is to reproduce text in the test set; lower is better). Trained only on generated data, successive generations showed decreasing performance; generation 9 achieved 53 perplexity. Trained on 10 percent original data, successive generations still performed worse, but not as badly; generation 9 achieved 37 perplexity.
Yes, but: The authors’ recursive training process is a worse-case scenario, and generated data does have a place in training. For instance, Alpaca surpassed a pretrained LLaMA by fine-tuning the latter on 52,000 examples produced by GPT-3.5.
Why it matters: The advent of high-quality generative models gives engineers an option to train new models on the outputs of old models, which may be faster and cheaper than collecting a real-world dataset. But this practice, taken to extremes, can lead to less-capable models. Moreover, if models are trained on data scraped from the web, and if the web is increasingly populated by generated media, then those models likewise will become less capable over time.
We’re thinking: To produce output that could be used for training without bringing on model collapse, a data generator would need access to sources of novel information. After all, humans, too, need fresh input to keep coming up with new ideas.