
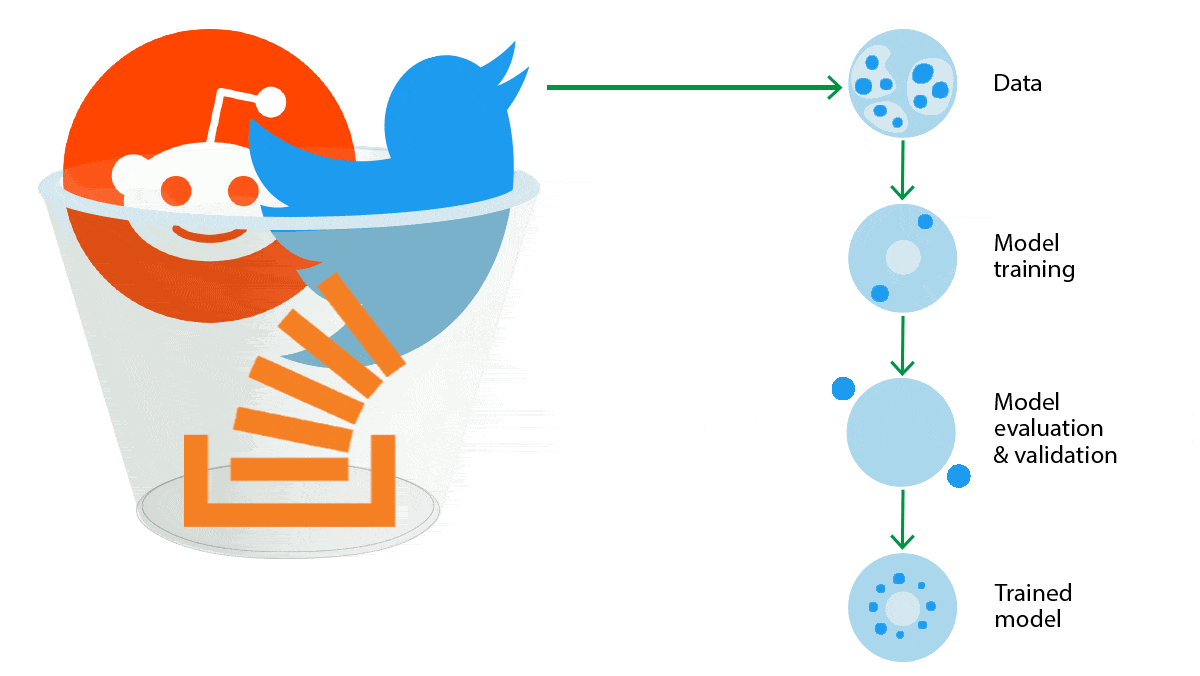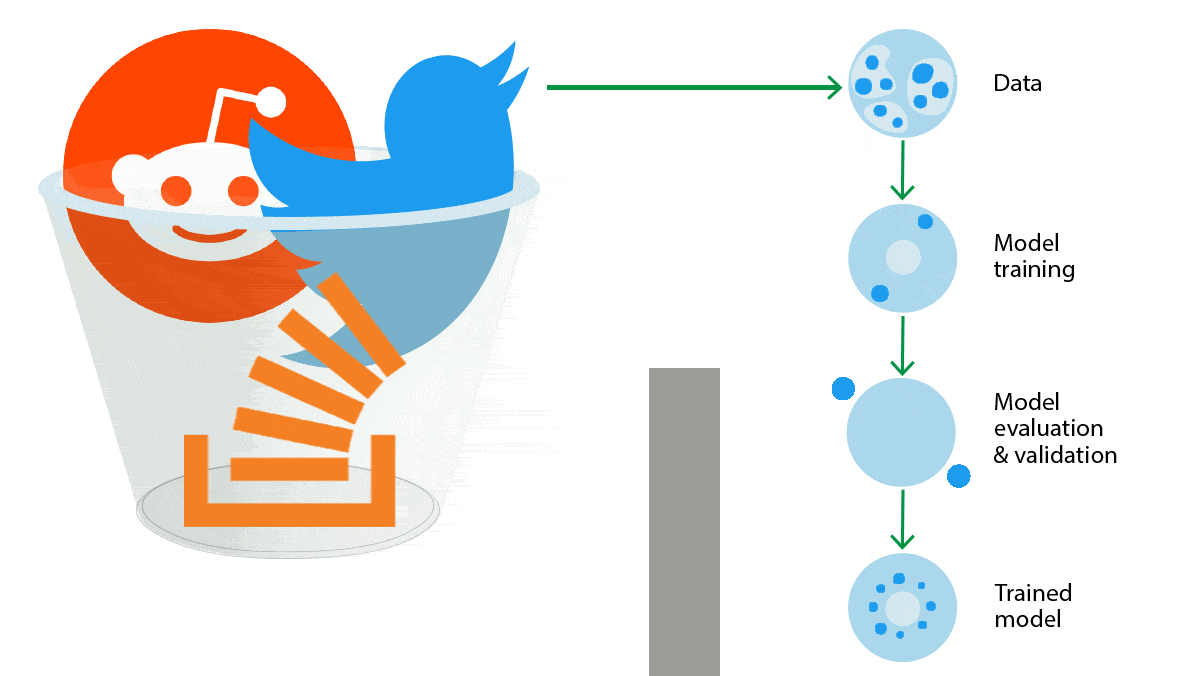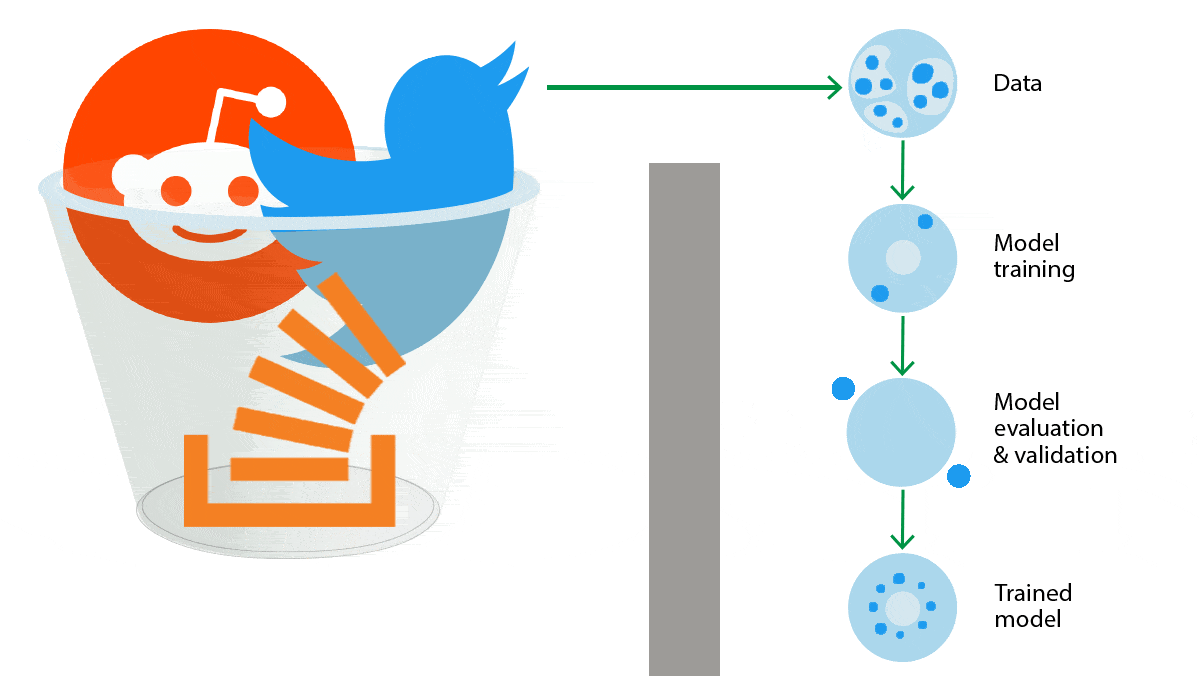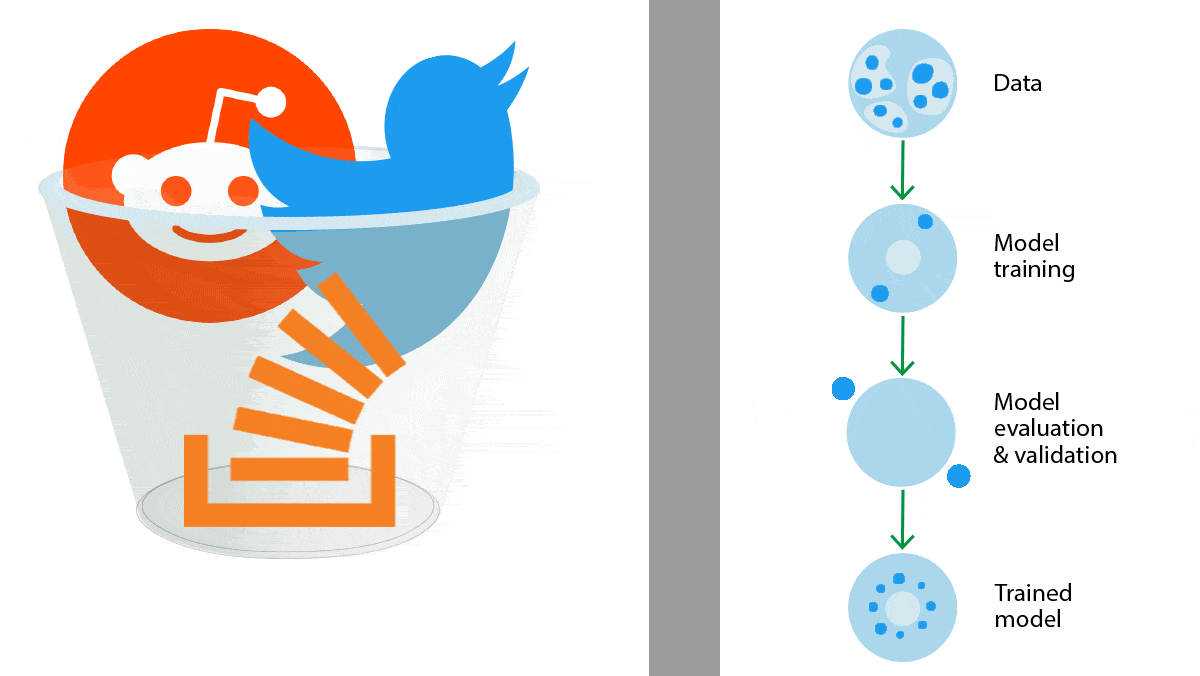
Developers of language models will have to pay for access to troves of text data that they previously got for free.
What’s new: The discussion platform Reddit and question-and-answer site Stack Overflow announced plans to protect their data from being used to train large language models.
How it works: Both sites offer APIs that enable developers to scrape data, like posts and conversations, en masse. Soon they'll charge for access.
- Reddit updated its rules to bar anyone from using its data to train AI models without the company’s permission. CEO Steve Huffman told The New York Times he planned to charge for access with an exception for developers of applications that benefit Reddit users.
- Stack Overflow’s CEO Prashanth Chandrasekar said that using the site’s data to train machine learning models violates the company’s terms of use, which state that developers must clearly credit both the site and users who created the data. The company plans to impose a paywall, pricing or other details to be determined.
What they’re saying: “Community platforms that fuel LLMs absolutely should be compensated for their contributions so that companies like us can reinvest back into our communities to continue to make them thrive,” Chandrasekar told Wired.
Behind the news: In February, Twitter started charging up to $42,000 monthly for use of its API. That and subsequent API closures are part of a gathering backlash against the AI community’s longstanding practice of training models on data scraped from the web. This use is at issue in ongoing lawsuits. Last week a collective of major news publishers stated that training AI on text licensed from them violates their intellectual property rights.
Why it matters: Although data has always come at a cost, the price of some corpora is on the rise. Discussion sites like Reddit are important repositories of conversation, and text from Stack Overflow has been instrumental in helping to train language models to write computer code. The legal status of existing datasets and models is undetermined, and future access to data depends on legal and commercial agreements that have yet to be negotiated.
We’re thinking: It’s understandable that companies watching the generative AI explosion want a slice of the pie and worry that users might leave them for a chatbot trained on data scraped from their own sites. Still, we suspect that charging for data will put smaller groups with fewer resources at a disadvantage, further concentrating power among a handful of wealthy companies.