
Dear friends,
Shortly after Pi day (3/14), I announced our Pie & AI series of meetups. We held them in Seattle in March and London in April.
We just hosted our third Pie & AI meetup at Google’s office in Sunnyvale, California, to celebrate the launch of the final course in the deeplearning.ai TensorFlow Specialization. Instructor Laurence Moroney and TensorFlow Program Manager Alina Shinkarsky joined in. You can watch the full conversation on our blog.

I was inspired by:
- The number of people who started learning AI just two or three years ago, and are now building great products.
- Laurence’s comments about making sure AI is unbiased.
- The sheer volume of pie 300 developers can eat.
If you want to know when we’re coming to your area for Pie & AI, sign up here.
Keep learning!
Andrew
News
Programmer's Helper
TabNine, a maker of programming tools, released Deep TabNine, an app that installs on your text editor of choice and fills in code as you type.
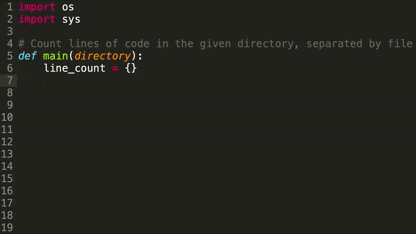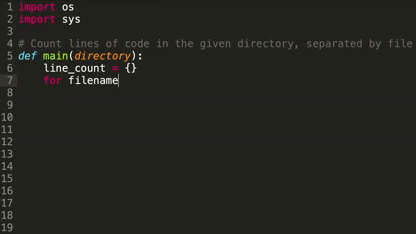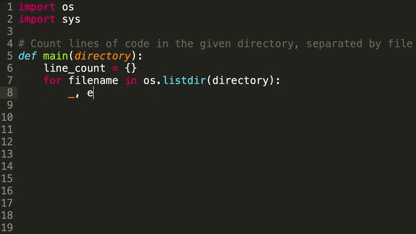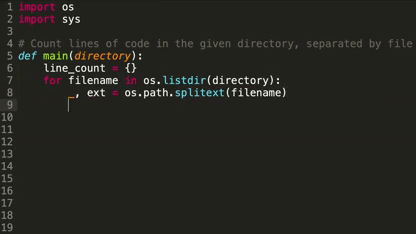
How it works: Deep TabNine is based on OpenAI's GPT-2, the text generator that penned a decent dystopian short story based on a single sentence from George Orwell’s 1984. Trained on open-source code, it predicts the next chunk of code, as illustrated in the picture above.
- Deep TabNine was trained on 2 million Github files.
- It supports 22 programming languages.
- Individuals can buy a license for $49. Business licenses cost $99.
Behind the news: Predictive tools for coding have existed for years, but they're typically geared for a single language and base their predictions largely on what has already been typed, making them less useful early in a project. Thanks to GitHub, Deep TabNine is familiar with a range of tasks, algorithms, coding styles, and languages.
Why it matters: Deep TabNine cuts coding time, especially when typing rote functions, according to evaluations on Reddit and Hacker News. Compounded across the entire software industry, it could be a meaningful productivity booster. And that doesn’t count the doctor bills saved by avoiding screen-induced migraines.
We’re thinking: Pretrained language models like GPT-2 are opening new, sometimes worrisome possibilities for text generation. Could this be the start of a new, powerful wave of AI-driven coding tools?
Da Vinci Code
Artificial intelligence is fueling artistic experimentation from painting to music. Now creatives can spend less time keeping up with the expanding AI palette and more time making digital masterpieces.
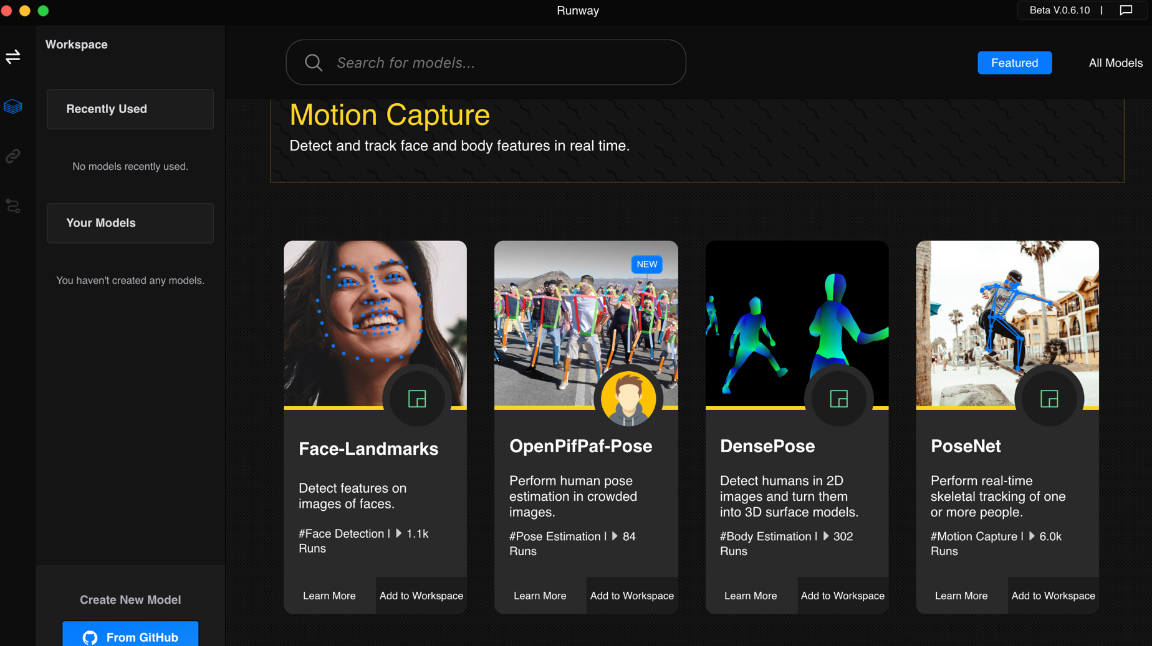
What’s new: Runway ML is a desktop clearinghouse that aims to connect visual artists with machine learning models that ignite their imagination and sharpen their productions. Browse the Image Generation category, for instance, and you’ll find a GAN that can make a selfie look like a Monet, or a semantic image synthesizer that transforms Microsoft Paint-quality doodles into photorealistic pictures.
How it works: Creators of AI models can upload their projects via Github.
- Developers retain rights to their software, but don’t expect compensation.
- A Netflix-like user interface organizes models according to their output.
- Users can run models in an easy-to-use workspace.
- The app, which is in beta, charges $0.05 per minute of compute and comes with $10.00 in free credit.
Behind the news: RunwayML began as a thesis project when artist and coder Cristóbal Valenzuela was a graduate student at NYU’s Tisch School of the Arts, according to The Verge. Now he works on it full-time.
Why it matters: AI opens a universe of creative possibilities: processing existing works, generating new ones, mashing up styles, creating new forms of order out of chaos and new forms of chaos out of order. Runway gives artists a playground for experimenting with these emerging resources.
We’re thinking: Making models accessible to artists doesn’t just broaden the market for AI. Engineers who listen to artists’ creative needs may find themselves taking on challenges they wouldn’t imagine on their own. Like, say, deciding what is and isn't art.
Text to Speech In Three Languages
Human voices retain their distinctive character no matter what language they’re speaking. New research lets computers imitate human voices across a number of languages.
What’s new: Researchers at Google built a multilingual text-to-speech engine that can mimic a person’s voice in English, Spanish, and Mandarin. You can hear examples of its output here.
Key Insights: Some languages are written as letters (like English) and others as symbols (Mandarin). The difference can have a dramatic impact on choice of architecture and training. Yu Zhang and colleagues found that processing phonemes — the basic sounds that make up language — simplifies the task by eliminating the need to learn pronunciation rules that vary among languages.
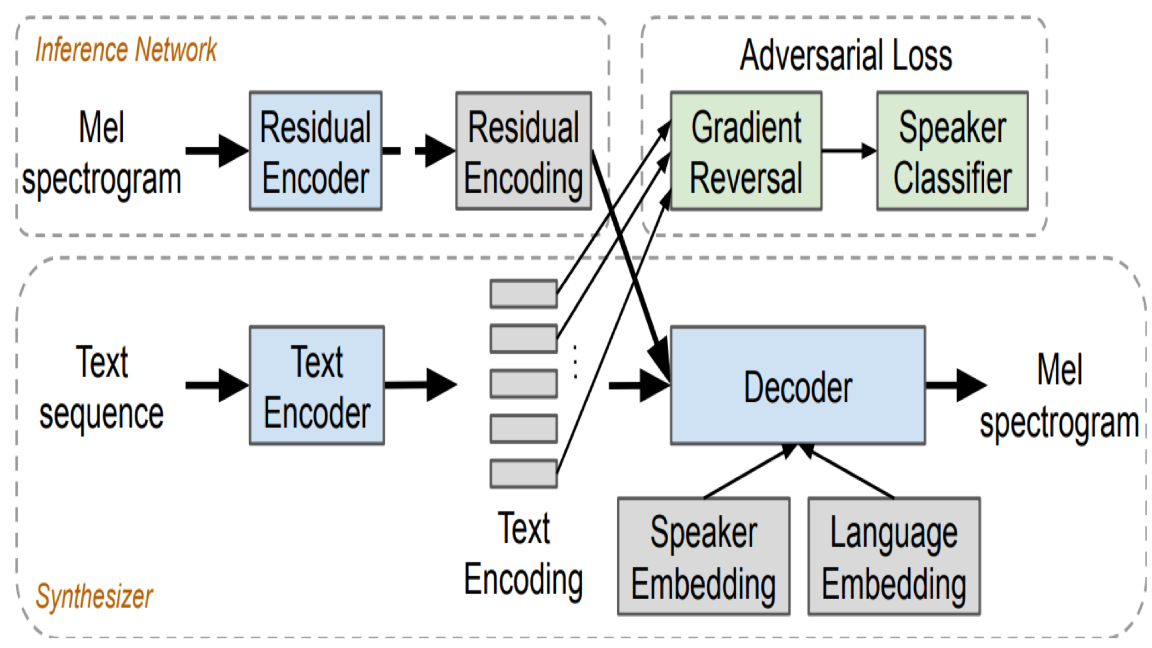
How it works: The model embeds phonemes in a vector space before decoding those vectors into spectrograms for a WaveNet speech synthesizer. Using phonemes enables the model to find similarities in speech among different languages, so the system requires less training data per language to achieve good results.
- The first step is to translate text input in various languages to phonemic spelling.
- Phonemes are embedded in vector space using the architecture of the earlier Tacotron 2, a state-of-the-art, single-language, speech-to-text model.
- In the training data, an individual speaker and the words spoken are strongly correlated. To disentangle them, a separate speaker classifier is trained adversarially against Tacotron 2 to judge whether a particular phoneme embedding came from a particular speaker. Adversarial training allows phoneme embeddings to encode spoken sounds without information about a particular speaker such as vocal pitch or accent.
- Separate models are trained to create two additional embeddings. A speaker embedding encodes an individual's vocal tone and manner. A language embedding encodes a given language's distinctive accents.
- A decoder takes speaker, language, and phoneme embeddings to produce a spectrogram for the WaveNet synthesizer, which renders the final audio output.
- By switching speaker and accent embeddings to a different set, the model can generate different voices and accents.
Results: In a subjective assessment of naturalness, the multilingual model’s performance in three languages roughly matches Tacotron 2’s performance on one.
Why it matters: Training a text-to-speech model typically requires plenty of well-pronounced and labeled training data, a rare commodity. The new approach takes advantage of plentiful data in popular languages to improve performance in less common tongues. That could extend the reach of popular services like Siri or Google Assistant (which work in 20 and 30 languages respectively out of 4,000 spoken worldwide) to a far wider swath of humanity.
We're thinking: A universal voice translator — speak into the black box, and out comes your voice in any language — is a longstanding sci-fi dream. This research suggests that it may not be so far away from reality.
A MESSAGE FROM DEEPLEARNING.AI

How do you know if your new idea for improving your algorithm is better or worse than your old one? Learn to set single-number evaluation metrics in the Deep Learning Specialization.

What's Not Written on Your Face
Many AI teams have bet big on models that can determine peoples’ emotional state by analyzing their face. But recent work shows that facial expressions actually provide scant information about a person’s feelings.
What’s new: An in-depth review of the scientific literature shows there are very few rules when it comes to how people use their faces to show emotion. For instance, the researchers found that a scowl indicates anger only 30 percent of the time.
What they found: Psychologists from universities in the US and Europe spent two years poring over 1,000 studies, including their own, examining facial expressions of emotion. They identified three categories of shortcomings:
- Researchers don’t account adequately for variability in the emotions people intend to convey, and how others read them. The person making a face might be feeling something completely different from what an observer perceives, and vice versa.
- Many studies assume there’s a consistent, species-wide map connecting certain sets of facial movements to emotional categories. If such a map exists, it contains many more side roads, dead ends, and detours than the literature describes.
- Much research ignores cultural differences. A grin can be pleasant in one society but hostile in another. Also, context matters. A person scowling at a book might be angry at its message or just trying to decipher tricky wordplay.
Behind the news: Most emotion recognition systems are based on ’60s-era research by psychologist Paul Ekman. He argued that humans share a vocabulary of facial configurations tied to emotion.
Why it matters: The emotion-detection industry is worth $20 billion, including marketing, security, and road safety, according to The Verge. But there’s more than money at stake. Systems designed for security and safety may not be doing their job because they're based on faulty research.
We’re thinking: Emotional expressions common to every human may exist. But if so, they’re more nuanced than current systems are designed to handle. Further research will help develop and validate AI's ability to recognize subtle muscle movements and contextual cues.
Seeing Into the Heart
Machine learning stumbles in diagnosing many medical conditions based on imagery if little labeled data is available. In small data settings, supervised learning is often unable to train an accurate classifier. But a twist on such methods dramatically boosts accuracy — without additional hand-labeled data.
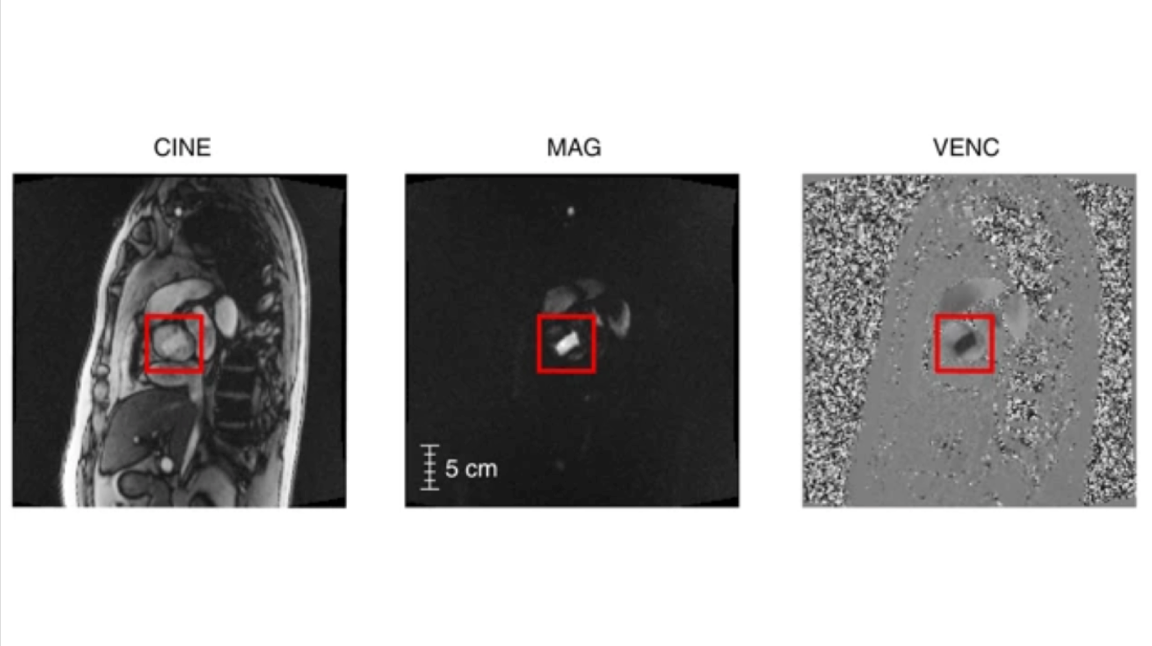
What’s new: Researchers at Stanford developed an improved diagnostic model for bicuspid aortic valve, a dangerous heart deformity, based on a database of MRI videos.
Key insight: Medical data typically is aggregated from many doctors and clinics, leading to inconsistent labels. Jason Fries and his teammates sidestepped that problem via weakly supervised learning, an emerging approach that doesn’t rely on labeled data. The trick is to use a separate model to produce a preliminary label and confidence score for every training example.
How it works: The labeler predicts initial diagnoses along with confidence levels, creating imprecise, or noisy, labels. A neural network uses the raw MRI and noisy labels to predict a final diagnosis.
- The labeler includes five algorithms that don’t learn. Rather, a data scientist sets them manually to compute the aorta’s area, perimeter length, resemblance to a circle, amount of blood flow, and ratio between area and perimeter. Using these values, each algorithm produces a prediction for every frame.
- These features are mapped using a simple probabilistic model to a noisy label and a degree of confidence.
- The noisy labels are used for training, with the loss function weighting higher-confidence labels more heavily.
Results: The weakly-supervised diagnostic model diagnosed BAV correctly in 83 percent of patients. The previous fully-supervised method achieved only 30 percent.
Why it matters: BAV is severely underdiagnosed (only one-sixth of sufferers had been labeled with the correct diagnosis in the training data set). Its day-to-day effects include fatigue, shortness of breath, and chest pain. Moreover, using long-term data on health outcomes, researchers discovered that patients whom their model diagnosed with BAV had twice the risk of a major cardiac event later in life. Having a correct diagnosis up-front clearly could be a life-saver.
Takeaway: General practitioners aren’t likely to detect rare, hidden conditions as accurately as specialists. But patients don’t schedule appointments with specialists unless they get a GP’s referral. Models like this one could help solve that chicken-or-egg problem by bringing powerful diagnostic tools to common checkups.