
Dear friends,
On Monday, I delivered a keynote via teleconference for Dubai's AI Everything conference. It was inspiring to see so many governments, businesses, and social enterprises coming together to talk about AI. The United Arab Emirates famously appointed a Minister of State for Artificial Intelligence, but I think every country should embrace the growth opportunity that AI offers.
Although Silicon Valley and Beijing are the leading AI hubs right now, we will need many centers of AI around the world applying machine learning to solve problems in all industries. I hope online courses such as our Deep Learning Specialization and AI for Everyone can help people everywhere unlock AI's practical value.
Keep learning,
Andrew
DeepLearning.ai Exclusive

Working AI: Educating the Globe
Younes Mourri is helping set the direction for AI education worldwide. A student and teacher at Stanford, he also develops content for the most popular online courses in machine learning. Learn more
News
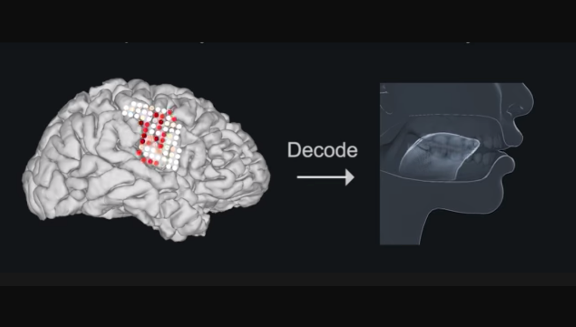
Talking Without Speaking
Neuroscientists translated brain signals directly into artificial speech, synthesizing full sentences based purely on neural impulses.
What happened: Researchers tapped the brains of five epilepsy patients who had been implanted with electrodes to map the source of seizures, according to a paper published by Nature (preprint here). During a lull in the procedure, they had the patients read English-language texts aloud. They recorded the fluctuating voltage as the brain controlled the muscles involved in speaking. Later, they fed the voltage measurements into a synthesizer. You can hear the synthesized speech in this video.
How it works: A pair of three-layer, bidirectional, LSTM recurrent neural networks drove the synthesis.
- One model used the neural activity to predict motions of the lips, jaw, tongue, and larynx.
- The other used those predictions to identify corresponding consonant, vowel, and other sounds.
- The second model’s output fed a synthesizer that rendered speech sounds.
- Listeners on Amazon Mechanical Turk transcribed the synthesized sentences, achieving 83% median accuracy.
Why it matters: The technique could help people who have lost the ability to control their vocal tract due to disorders such as Lou Gehrig’s disease, stroke, or injury. People with such conditions — think of the late physicist Stephen Hawking — can communicate very slowly through systems that track eye movements or facial muscles to spell words one letter at a time. Translating brain impulses directly would allow them to communicate with the ease of normal speech.
Reality check: The researchers did not read minds. Gopala K. Anumanchipalli, Josh Chartier, and Edward F. Chang read brain signals controlling the patients’ muscles. Still, their approach conceivably could be refined to translate brain signals associated with thought.
What’s next: The team plans to test the technology in people who can’t move their face and tongue. It also aims to adapt the system for languages other than English.

Hiding in Plain Sight
Harry Potter’s magical cloak made him invisible to his Hogwarts colleagues. Now researchers have created a sort of invisibility shield to hide people from computer vision.
What’s new: The researchers created an adversarial patch that makes people invisible to the YOLOv2 object detection model. Hold the patch in front of a camera, and YOLOv2 can’t see anything. In this video, the befuddled recognizer seems to scratch its head as researchers pass the patch back and forth.
How they did it: Simen Thys, Wiebe Van Ranst, and Toon Goedemé fed a variety of photos into a YOLOv2 network. They altered the photos to minimize the model’s "objectness" score. The image with the lowest score was an altered picture of people holding colorful umbrellas. They composited this image into photos of people, ran those through the network, and tweaked the patch further to achieve still lower objectness scores.
Why it matters: Much research into adversarial attacks has focused on targets that don’t vary from instance to instance, such as stop signs or traffic lights. Held in front of a person, the new patch blinds YOLOv2 regardless of differences such as clothing, skin color, size, pose, or setting. It can be reproduced by a digital printer, making it practical for real-world attacks.
The catch: The patch works only on YOLOv2. It doesn’t transfer well to different architectures.
What’s next: The researchers contemplate generalizing the patch to confuse other recognizers. They also envision producing adversarial clothing. Perhaps a cloak?
Birth of a Prodigy
Never mind Spotify, here's MuseNet — a model that spins music endlessly in a variety of styles.
What’s new: Computer-generated music composition dates back to the 1950s, but rarely has it been easy on the ears. The best examples, such the recent Google doodle commemorating the birthday of J.S. Bach, stick with a single style. MuseNet has a fair grasp of styles from bluegrass to Lady Gaga, and it can combine them as well.
How it works: Drawing on OpenAI's GPT-2 language model, MuseNet is a 72-layer transformer model with 24 attention heads. This architecture, plus embeddings that help the model keep track of musical features over time, give it a long memory for musical structure. It uses unsupervised learning to predict the next note for up to 10 instruments in compositions up to four minutes long.
To be sure: Project lead (and Deep Learning Specialization graduate) Christine Payne is a Juilliard-trained pianist, and the model’s mimicry of piano masters such as Chopin and Mozart (or both) is especially good. That said, MuseNet inhabits was trained on MIDI files and speaks through a general-purpose synthesizer, so its output often sounds stiff and artificial. Its understanding of harmony and form, while impressive for an algorithmic composer, is shallow, and it often meanders.
Where to hear it: You can hear MuseNet here. You can tinker with it here through May 12. After that, OpenAI plans to retool it based on user feedback with the aim of open-sourcing it. (To build your own algorithmic jazz composer, check out Course Five of the Deep Learning Specialization on Coursera.)
A MESSAGE FROM DEEPLEARNING.AI

Sometimes the most valuable AI projects don't make the best pilot projects. Learn why, and explore how you can implement AI throughout your company, in our AI for Everyone course, available on Coursera.
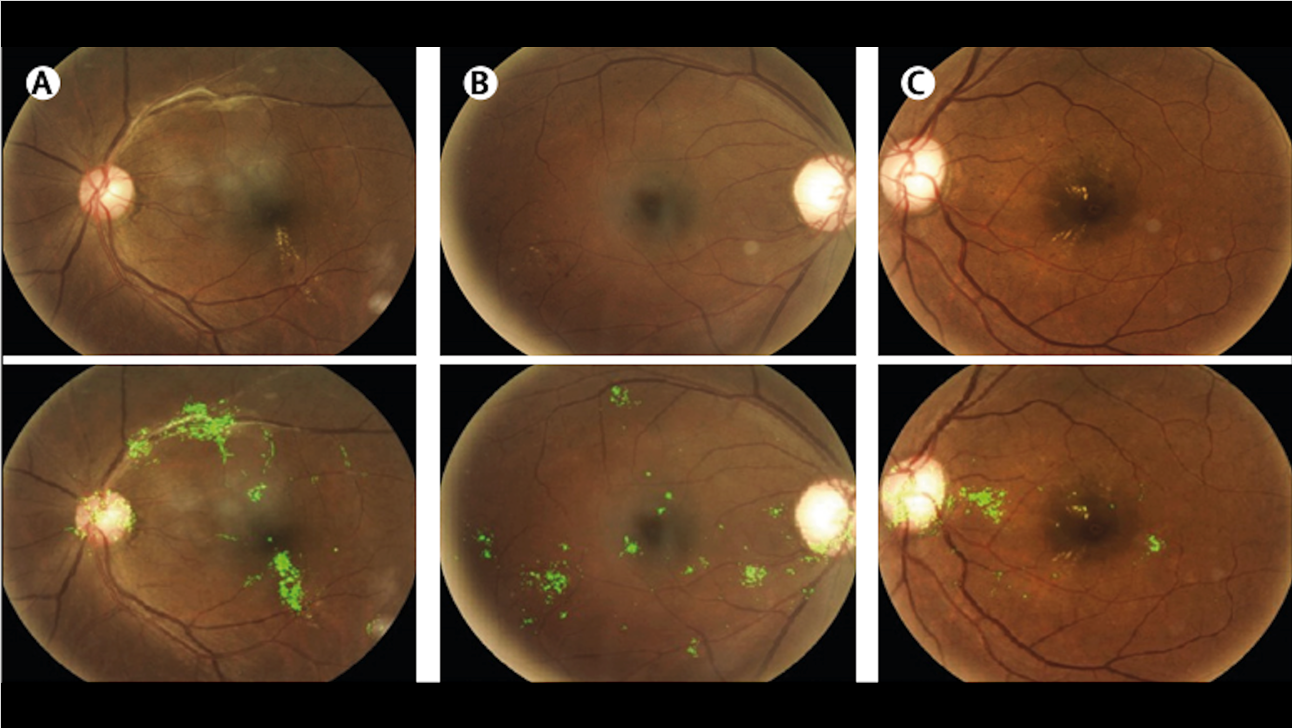
Computer Vision for Human Vision
AI is poised to revolutionize diagnosis of eye disease.
What’s new: Articles are piling up in scientific journals heralding computer vision’s success in detecting conditions such as diabetic retinopathy, a common condition that can cause blindness if it’s not treated in time:
- In a study of 1,574 diabetes patients in Zambia, a neural net diagnosed the condition with accuracy better than 97%.
- Researcher Yannis Paulus found that software running on a smartphone with a retinal scanner compared favorably to examination by a specialist in a clinic.
- Two recent articles in Nature heralded AI’s potential in diabetic retinopathy and other eye diseases.
- DeepMind and IBM lately have touted their progress in detecting these maladies.
Why it matters: Roughly 400 million people suffer from diabetes worldwide, and 10% of them will develop a serious case of retinopathy. Doctors can treat it if they can detect it in time, but there aren’t enough ophthalmologists or clinics to go around. AI running on portable devices could spot cases locally, catching the condition early and conserving specialist attention for severe cases.
Behind the news: The Food and Drug Administration approved its first AI-driven eye scanner for clinical use last year under a fast-track program for novel technologies.
What they’re saying: “Advances in the automated diagnosis of eye conditions . . . have put artificial intelligence in a position to transform eye care. Soon, AI-based systems could augment physicians’ decision-making in the clinic — or even replace physicians altogether.” — Aaron Lee, Dept. of Ophthalmology, University of Washington, in Nature
Bottom line: Many experts expect AI’s march on medicine to start in the radiology lab. But you’re likely to find it in the ophthalmologist’s office even sooner.
Automating Justice
AI tools that help police and courts make decisions about detention, probation, and sentencing have “serious shortcomings," an AI industry consortium warns.
What’s new: The Partnership on AI examined the use of risk-assessment software in criminal justice throughout the U.S. In a new report, it outlines 10 requirements of such systems that are “largely unfulfilled” in the current crop. The organization's requirements include:
- Statistical bias must be measured and mitigated.
- Predictions must be easy to interpret.
- Tools must include confidence estimates with their predictions.
- Designs, architectures, and training data must be open to review.
- Output must be reproducible to enable meaningful challenges.
Behind the news: U.S. authorities increasingly use, and in some cases mandate the use of, automated systems. The aim is to reduce costs and increase rigor in decision-making. Yet such tools have been shown to produce invalid or biased results. They’re used without oversight, largely by people with little technical training.
We’re thinking: The government’s reliance on predictive software doesn’t stop with criminal justice. It's used in child welfare, education, public health, and elsewhere, and it has come up short time and time again. Such tools need to be evaluated with far more technical rigor. The new guidelines are a good place to start.