
Dear friends,
So you’ve trained an accurate neural network model in a Jupyter notebook. You should celebrate! But . . . now what? Machine learning engineering in production is an emerging discipline that helps individual engineers and teams put models into the hands of users.
That’s why I’m excited that DeepLearning.AI is launching Machine Learning Engineering for Production Specialization (MLOps). I teach this specialization along with co-instructors Robert Crowe and Laurence Moroney from Google. It also draws on insights from my team at Landing AI, which has worked with companies in a wide range of industries.
The work of building and putting machine learning models into production is undergoing a dramatic shift from individually crafted, boutique systems to ones built using consistent processes and tools. This specialization will put you at the forefront of that movement.
I remember doing code version control by emailing C++ files to collaborators as attachments with a note saying, “I’m done, you can edit this now.” The process was laborious and prone to error. Thank goodness we now have tools and practices for version control that make team coding more manageable. And I remember implementing neural networks in C++ or Python and working on the first version of distbelief, the precursor to TensorFlow. Tools like TensorFlow and PyTorch have made building complex neural networks much easier.

Building and deploying production systems still requires a lot of manual work. Things like discovering and correcting data issues, spotting data drift and concept drift, managing training, carrying out error analysis, auditing performance, pushing models to production, and managing computation and scaling.
But these tasks are becoming more systematic. MLOps, or machine learning operations, is a set of practices that promise to empower engineers to build, deploy, monitor, and maintain models reliably and repeatably at scale. Just as git, TensorFlow, and PyTorch made version control and model development easier, MLOps tools will make machine learning far more productive.
For me, teaching this course was an unusual experience. MLOps standards and tools are still evolving, so it was exciting to survey the field and try to convey to you the cutting edge. I hope you will find it equally exciting to learn about this frontier of ML development, and that the skills you gain from this will help you build and deploy valuable ML systems.
Keep learning!
Andrew
Machine Learning in Production
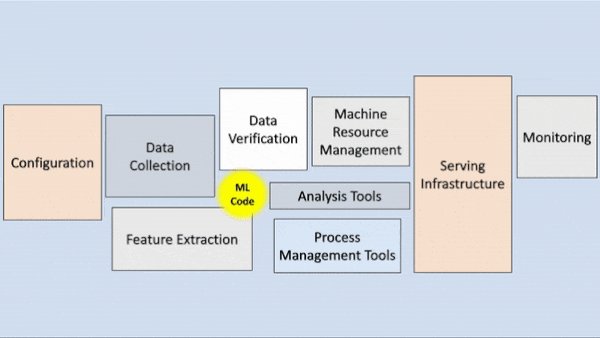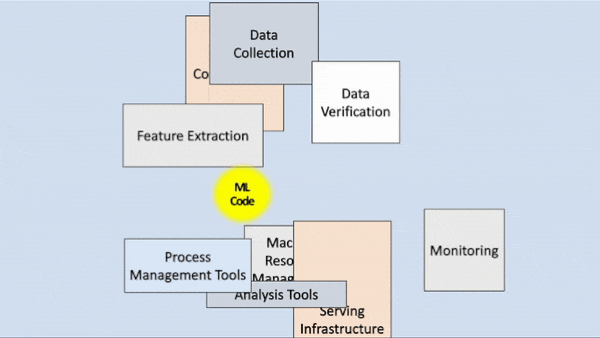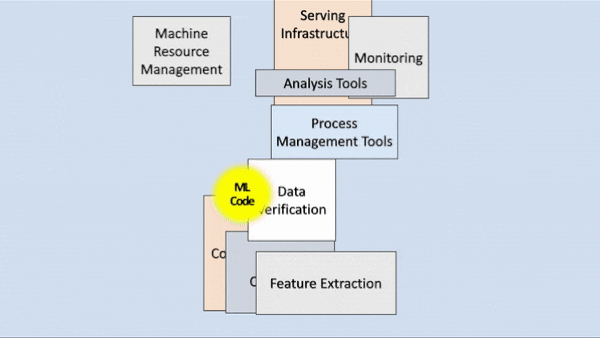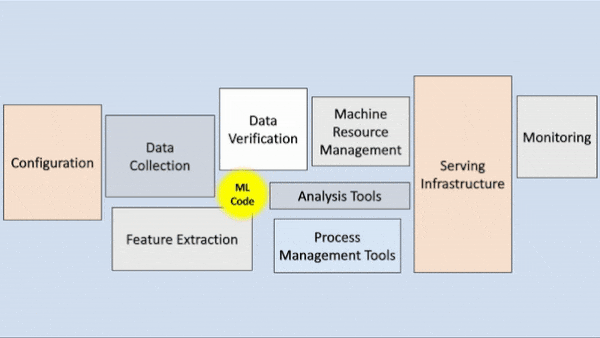 |
Out of the Lab and Into the World
Machine learning usually begins in an experimental setting before making its way into industries from agriculture to waste management. But getting there isn't a simple matter. Engineering in production requires putting a model in front of demanding users and ensuring that its output remains useful as real-world conditions shift. MLOps addresses these issues, but there’s more to shepherding models into the real world — not least, understanding all the steps along the way and developing intuition to take the right approach. In this special issue of The Batch, we pull back the curtain on the challenges, methods, and rewards of machine learning in production.
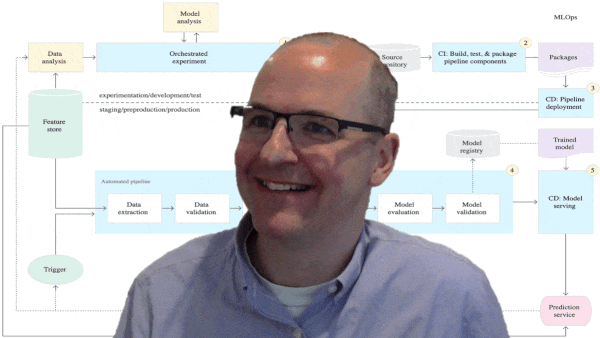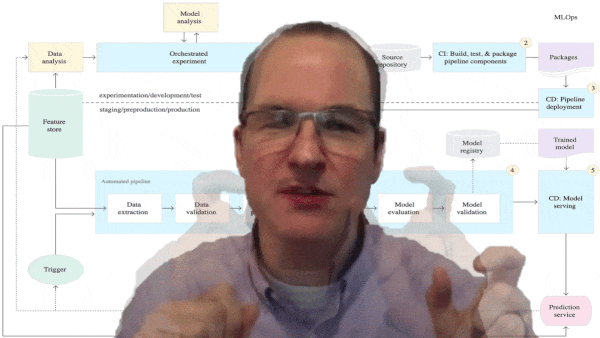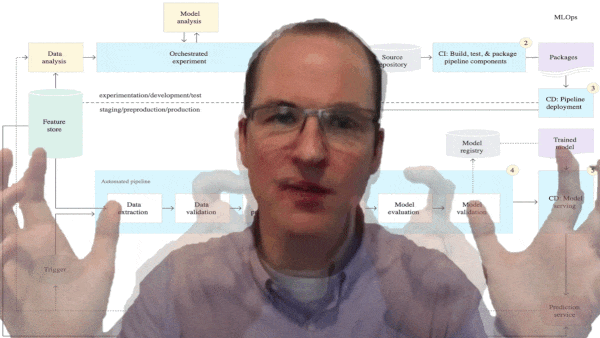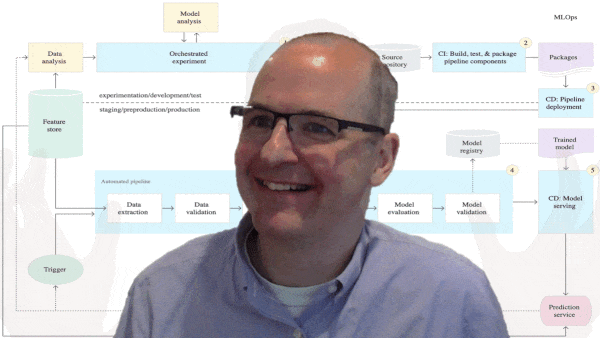 |
MLOps for All
Craig Wiley has journeyed from the hand-deployed models of yore to the pinnacle of automated AI. During a decade at Amazon, he led SageMaker, the company’s web-enabled machine learning platform, from concept to rollout. Today, as chief product manager of Google Cloud’s AI services, he’s making advanced tools and processes available to anyone with a credit card. Funny thing: He spent the early part of his career managing YMCA summer camps. Maybe that’s what enables him to view the AI revolution with a child’s eye, marveling at its potential to renew entire industries and imagining the bright future of streamlined model deployment — so he can build it for the rest of us.
The Batch: There’s a huge gap between machine learning in the lab and production. How can we close it?
Wiley: We used to talk about how to bring the rigor of computer science to data science. We’re beginning to see it with MLOps.
The Batch: People have different definitions of MLOps. What is yours?
Wiley: MLOps is a set of processes and tools that helps ensure that machine learning models perform in production the way the people who built them expected them to. For instance, if you had built models based on human behavior before Covid, they probably went out of whack last March when everyone’s behavior suddenly changed. You’d go to ecommerce sites and see wonky recommendations because people weren’t shopping the way they had been. In that case, MLOps would notice the change, get the most recent data, and start doing recommendations on that.
The Batch: Describe an experience that illustrates the power of MLOps.
Wiley: In 2019, Spotify published a blog saying it used some of our pipelining technology and saw a 700 percent increase in the productivity of its data scientists. Data scientists are expensive, and there aren’t enough of them. Generally we would celebrate a 30 percent increase in productivity — 700 percent borders on absurd! That was remarkable to us.
The Batch: How is it relevant to engineers in small teams?
Wiley: If nothing else, it saves time. If you start using pipelines and everybody breaks their model down into their components, it transforms the way you build models. No longer do I start with a blinking cursor in a Jupyter notebook. I go to my team’s repository of pipeline components and gather components for data ingestion, model evaluation, data evaluation, and so on. Now I’m changing small pieces of code rather than writing a 3,000-line corpus from beginning to end.
The Batch: How far along the adoption curve are we, as an industry?
Wiley: I think the top machine learning companies are those that are using these kinds of tools. At the point where we start struggling to name those companies, we’re getting to the ones that are excited to start using these tools. A lot of the more nascent players are trying to figure out who to listen to. Someone at a data analytics company told me, “MLOps is a waste of time. You only need it if you’re moving it to production, and 95 percent of models never make it into production.” As a Googler and former Amazonian, I’ve seen the value of models in production. If you’re not building models in production, the machine learning you’re doing is not maximizing its value for your company.
The Batch: What comes next?
Wiley: Think about what it was like two or three years after distributed systems were created. You needed a PhD in distributed systems to touch these things. Now every college graduate is comfortable working with them. I think we’re seeing a similar thing in machine learning. In a few years, we’ll look back on where we are today and say, “We’ve learned a lot since then.”
 |
24/7 Phish Fry
Foiling attackers who try to lure email users into clicking on a malicious link is a cat-and-mouse game, as phishing tactics evolve to evade detection. But machine learning models designed to recognize phishing attempts can evolve, too, through automatic retraining and checks to maintain accuracy.
What’s new: Food giant Nestlé built a system that checks incoming emails and sends suspicious ones to the company’s security team. Microsoft’s Azure Machine Learning web platform supplies the tools and processing power.
Problem: Nestlé receives up to 20 million emails in 300,000 inboxes daily. An earlier commercial system flooded analysts with legitimate messages wrongly flagged as phishing attempts — too many to evaluate manually.
Solution: The company built an automated machine learning system that continually learns from phishing attempts, spots likely new ones, and forwards them to security analysts.
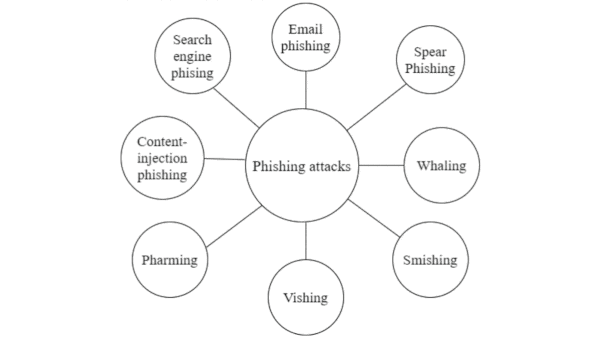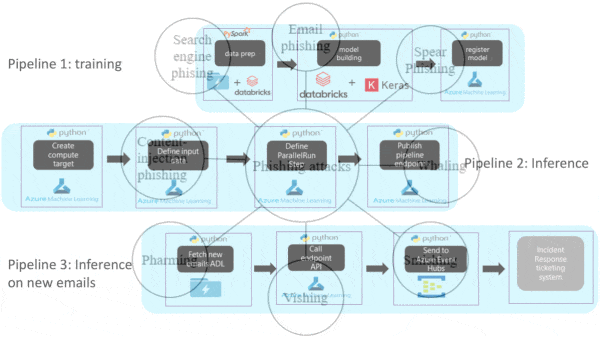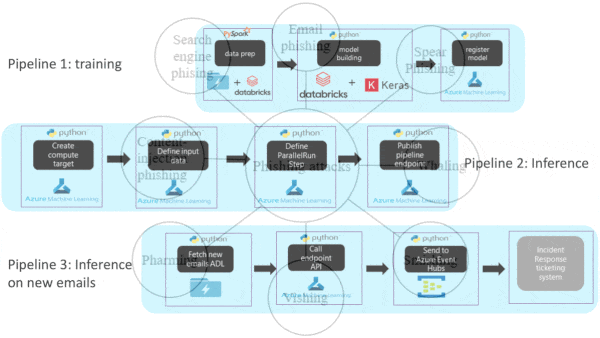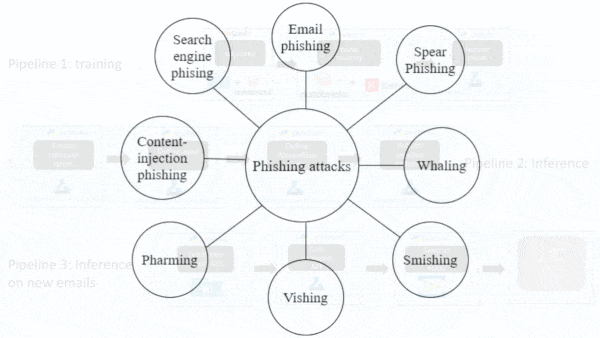
How it works: The system comprises three automated pipelines that run in the cloud. The first manages training, the second evaluates incoming messages, and the third passes the latest risky messages to security.
- The system stores incoming emails in a data lake. A transformer model fine-tuned for the task examines email subject headers to classify phishing attempts. Factors such as the sender’s domain are used to prioritize messages for human attention.
- It processes incoming messages hourly in batches that run in parallel and retrains the model weekly to learn from the latest attacks. It also retrains the model whenever the surrounding code is revised; say, if the software that parses subject headers implements a new tokenization scheme. It evaluates the new model's performance and, if the model performs well, deploys it.
- All models are versioned, registered, associated with the code base at the time, and saved to a database. Engineers can track the impact on performance of changes to the model, data, or code, making it easier to track down bugs, revert changes, and perform experiments.
Results: The system detects malicious emails more quickly and accurately than its commercial predecessor. It flags phishing attempts with 60 percent precision. Previously, most of those would have been missed, the team said.
Why it matters: Running several software pipelines continuously at high volume means a lot of moving parts in a critical application. Automating them and putting in place good tools and processes saves headaches and avoids security threats.
We’re thinking: With machine learning models hard at work fighting phishing, machine learning engineers have more time to go fishing.
 |
Super-Human Quality Control
A computer vision model, continually trained and automatically updated, can boost quality control in factories.
What’s new: Landing AI, a machine learning platform company led by Andrew Ng, helped a maker of compressors for refrigeration check them for leaks. The manufacturer fills the compressor with air and submerges it in water while an inspector looks for telltale bubbles. Landing AI’s system outperformed the inspectors.
Problem: When a visual inspection model detects a flaw where none exists, an engineer adds the example to the training set. When enough new examples have accrued, the engineer retrains the model, compares it with its predecessor and, if the new model shows improved performance, puts it into production — a laborious process that may introduce new errors.
Solution: An automated machine-learning pipeline can accelerate all of these tasks and execute them more consistently.
How it works: The Landing AI team aimed a camera at the water tank and sent the footage to a MIIVII Apex Xavier computer. The device ran a model that looked for bubbles and classified each compressor as okay or flawed, and a different model that watched indicator lights as an inspector activated a robot arm to place good compressors in one area and defective ones in another, and classified that decision.
- The system compared machine and human decisions and sent disagreements to an off-site expert. The expert reviewed the video and rendered a judgement.
- If the expert declared the model incorrect, the system added it to the training set (if it was categorized as a familiar sort of bubble) or a test set (if the problem was unfamiliar, such as an oddly shaped bubble). It retrained the model weekly.
- Before deploying a new model, the system ran it in parallel with the previous version and logged its output to audit its performance. If the new model performed better, it replaced the old one.
- As they iterated on the model, the engineers used a data-centric approach to reduce the percentage of inaccurate inferences. For instance, they placed QR codes on the corners of the water tank, enabling a model to detect issues in the camera’s framing, and lit the tank so another model could detect murky water that needed to be changed. To help the system differentiate between metal beads (artifacts of manufacturing) and bubbles, the team highlighted bubble motion by removing the original colors from three consecutive frames and compositing them into the red, green, and blue channels of an RGB image. Bubbles lit up like a Christmas tree.
Results: After two months of iteration, the team put the system to a test. Of 50,000 cases in which the system expressed certainty, it disagreed with human experts in only five. It was correct in four of those cases. It was insufficiently certain to render a decision in 3 percent of cases, which required human decisions.
Why it matters: Human inspectors are expensive and subject to errors. Shifting some of their responsibility to a machine learning system — especially one that performs better than humans — would enable manufacturers to reallocate human attention elsewhere.
We’re thinking: A human-in-the-loop deployment that maintains a feedback loop between human experts and algorithms is a powerful way to learn — for both people and machines.
A MESSAGE FROM DEEPLEARNING.AI
 |
We’re thrilled to launch the first two courses in the Machine Learning Engineering for Production Specialization (MLOps) on Coursera! This specialization teaches foundational concepts of machine learning plus functional expertise of modern software development and engineering to help you develop production-ready skills. Enroll now
 |
ML in Production: Essential Papers
Deploying models for practical use is an industrial concern that generally goes unaddressed in research. As a result, publications on the subject tend to come from the major AI companies. These companies have built platforms to manage model design, training, deployment, and maintenance on a large scale, and their writings offer insight into current practices and issues. Beyond that, a few intrepid researchers have developed techniques that are proving critical in real-world applications.
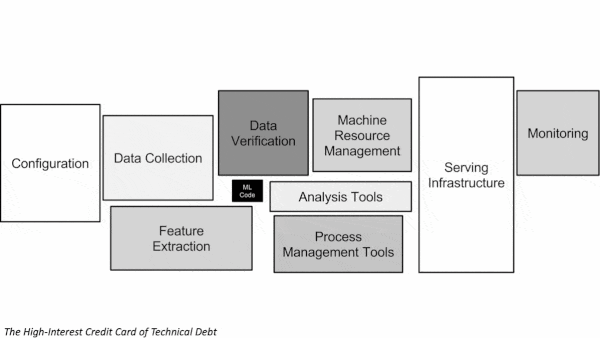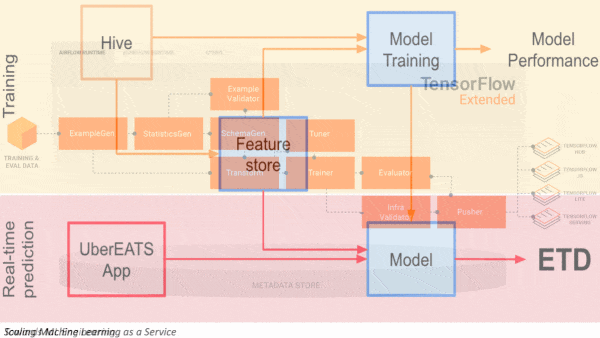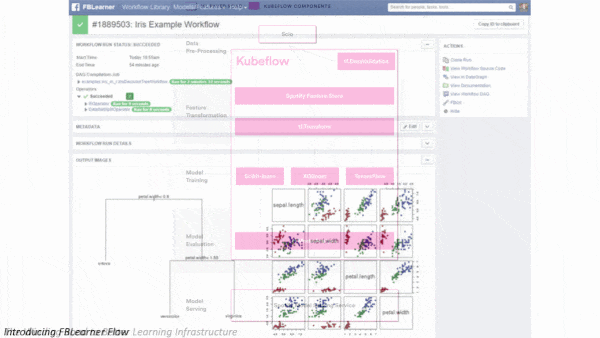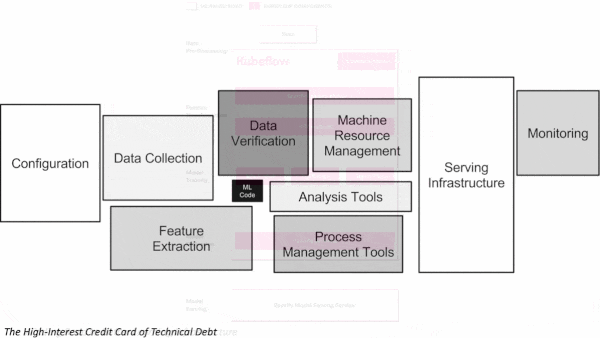
The High-Interest Credit Card of Technical Debt: The notion of technical debt — hidden costs incurred by building a good-enough system that contains bugs or lacks functionality that becomes essential in due course — is familiar in software development. The authors argue that machine learning’s dependence on external code and real-world data makes these costs even more difficult to discover before the bill comes due. They offer a roadmap to finding and mitigating them, emphasizing the need to pay careful attention to inputs and outputs, as changing anything — training data, input structure, external code dependencies — causes other changes to ripple through the system.
Towards ML Engineering: Google offers this synopsis of TensorFlow Extended (TFX), a scaffold atop the TensorFlow programming framework that helps track data statistics and model behavior and automates various parts of a machine learning pipeline. During data collection, TFX compares incoming data with training data to evaluate its value for further training. During training, it tests models to make sure performance improves with each iteration of a model.
The Winding Road to Better Learning Infrastructure: Spotify built a hybrid platform using both TensorFlow Extended and Kubeflow, which encapsulates functions like data preprocessing, model training, and model validation to allow for reuse and reproducibility. The platform tracks each component’s use to provide a catalog of experiments, helping engineers cut the number of redundant experiments and learn from earlier efforts. It also helped the company discover a rogue pipeline that was triggered every five minutes for a few weeks.
Introducing FBLearner Flow: Facebook found that tweaking existing machine learning models yielded better performance than creating new ones. FBLearner Flow encourages such recycling company-wide, lowering the bar of expertise to take advantage of machine learning. The platform provides an expansive collection of algorithms to use and modify. It also manages the intricate details of scheduling experiments and executing them in parallel across many machines, along with dashboards for tracking the results.
Scaling Machine Learning as a Service: Models in development should train on batches of data for computational efficiency, whereas models in production should deliver inferences to users as fast as possible — that’s the idea behind Uber’s machine learning platform. During experimentation, code draws data from SQL databases, computes features, and stores them. Later, the features can be reused by deployed models for rapid prediction, ensuring that feature computation is consistent between testing and production.
A Unified Approach to Interpreting Model Predictions: Why did the model make the decision it did? That question is pressing as machine learning becomes more widely deployed. To help answer it, production platforms are starting to integrate Shapley Additive Explanations (SHAP). This method uses an explainable model such as linear regression to mimic a black-box model’s output. The explainable model is built by feeding perturbed inputs to the black-box model and measuring how its output changes in response to the perturbations. Once the model is built, ranking the features most important to the decision highlights bias in the original model.
 |
Bespoke Models on a Grand Scale
When every email, text, or call a company receives could mean a sale, reps need to figure out who to reply to first. Machine learning can help, but using it at scale requires a highly automated operation.
What’s new: Freshworks, which provides web-based software for managing customer relationships, produces models that prioritize sales leads, suggest the best action to move toward a sale, and related tasks. The decade-old company rolls them out and keeps them updated with help from Amazon’s SageMaker platform.
Problem: To serve 150,000 sales teams that might be in any type of business and located anywhere in the world, Freshworks builds, deploys, and maintains tens of thousands of customized models. That takes lots of processing power, so the company needs to do it efficiently.
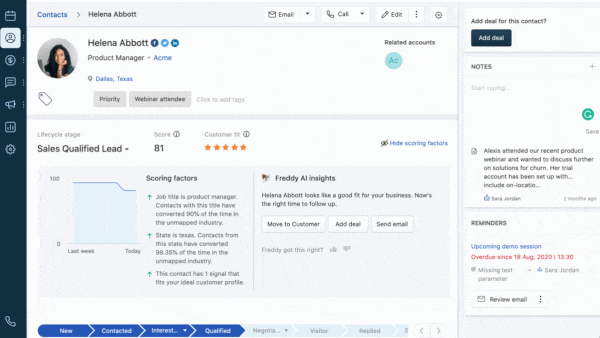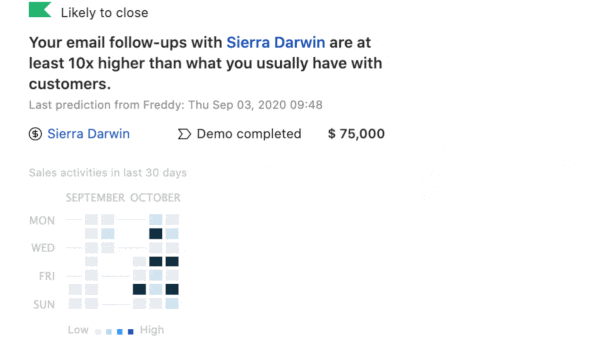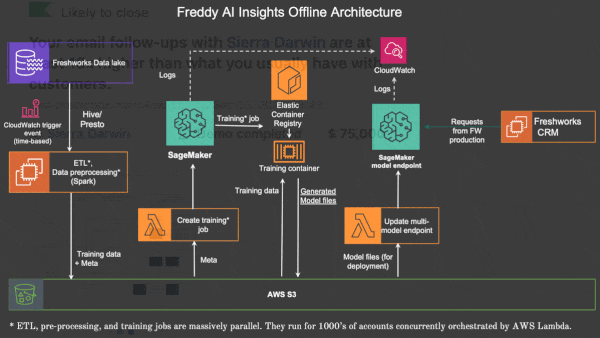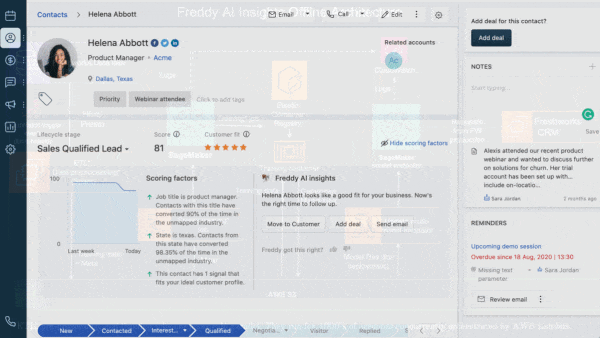
Solution: Instead of training each model sequentially, Freshworks saves time by training them in parallel, as shown in the diagram above. Rather than retraining all models on fresh data weekly — as the company did previously — it evaluates performance continually and automatically retrains those that fall short. When a model isn’t needed, the server it runs on moves on to other jobs, saving costs.
How it works: Freshworks’ system trains and fine-tunes models to order for each client. It uses the client’s data if possible. Otherwise, it uses a model trained for the client’s industry, both industry and region, or both industry and language. The company’s user interface queries models through an API.
- To produce a model, Freshworks automatically builds and evaluates a number of different architectures, including neural networks, linear regression, random forests, and XGBoost. It deploys the best one.
- As the models run and take in new customer data, the system automatically scales servers up or down based on the number of incoming API calls.
- Freshworks is evaluating a feature that constantly evaluates model performance along with incoming data statistics. It flags models that show degraded performance and retrains only those models.
Results: The automated system reduced training time from about 48 hours to about one hour. It boosted accuracy by 10 to 15 percent while cutting server costs by about 66 percent.
Why it matters: Show of hands: Who wants to build, deploy, and maintain thousands of models by hand? Automatically choosing architectures, training them, turning servers on and off, monitoring performance and data, and retraining when needed makes highly customized, highly scalable machine learning more practical and affordable.
We’re thinking: Accurate predictions of who might buy a product or subscribe ought to cut down on unwanted sales calls to the rest of us!