
Dear friends,
Earlier today, I spoke at a DeepLearning.AI event about MLOps, a field that aims to make building and deploying machine learning models more systematic. AI system development will move faster if we can shift from being model-centric to being data-centric. You can watch a video of the event here.
Unlike traditional software, which is powered by code, AI systems are built using both code (including models and algorithms) and data:
AI systems = Code + Data
When a system isn’t performing well, many teams instinctually try to improve the Code. But for many practical applications, it’s more effective instead to focus on improving the Data.
Progress in machine learning has been driven for decades by efforts to improve performance on benchmark datasets, in which researchers hold the Data fixed while improving the Code. But for many applications — especially ones where the dataset size is modest (<10,000 examples) — teams will make faster progress by focusing instead on making sure the dataset is good:
- Is the definition of y given x clear and unambiguous? For example, do different data labelers draw bounding boxes consistently? Do speech transcriptionists label ambiguous audio consistently, for instance, writing “um, yes please” rather than “um … yes please”?
- Does the input distribution x sufficiently cover the important cases?
- Does the data incorporate timely feedback from the production system, so we can track concept and data drift?
It’s a common joke that 80 percent of machine learning is actually data cleaning, as though that were a lesser task. My view is that if 80 percent of our work is data preparation, then ensuring data quality is the important work of a machine learning team.
Rather than counting on engineers to chance upon the best way to improve a dataset, I hope we can develop MLOps tools that help make building AI systems, including building high-quality datasets, more repeatable and systematic. MLOps is a nascent field, and different people define it differently. But I think the most important organizing principle of MLOps teams and tools should be to ensure the consistent and high-quality flow of data throughout all stages of a project. This will help many projects go more smoothly.
I have much more to say on this topic, so check out my talk here. Thanks to my team at Landing AI for helping to crystalize these thoughts.
Keep learning!
Andrew
News

Partners in Surveillance
Police are increasingly able to track motor vehicles throughout the U.S. using a network of AI-powered cameras — many owned by civilians.
What’s new: Flock, which sells automatic license plate readers to homeowners associations, businesses, and law enforcement agencies, is encouraging enforcers to use its network to monitor cars and trucks outside their jurisdiction, according to an investigation by Vice.
How it works: Flock owners can opt to share data with police. In turn, police can share data with Flock’s Total Analytics Law Officers Network, or Talon.
- Talon collects as many as 500 million vehicle scans each month. The network’s cameras store video and send alerts when they spot vehicles flagged on watch lists. In addition to license plate numbers, users can search by model, color, and features like spoilers or roof racks.
- Talon data can also be used in conjunction with the National Crime Information Center, an FBI database that contains records on fugitives, missing persons, and stolen vehicles.
- Over 500 U.S. police departments have access to Talon. Flock claims that it helps solve between four and five cases an hour. The system stores data for only 30 days, but police can download information for use as evidence in a case.
- Roving scanners are mounted on tow trucks and garbage trucks, The Wall Street Journal reported. License plate data played a role in arrests of suspects in the riot at the U.S. Capitol on January 6.
Behind the news: AI-powered cameras are increasingly popular with law enforcement, but their use is fueling concerns about overreach.
- Police used data from Ring, a division of Amazon that sells AI-enhanced surveillance cameras to residences and businesses (but which lack license plate reader technology), to target Black Lives Matter protesters in Los Angeles last summer.
- License plate readers by Vigilant have contributed to arrests for driving vehicles incorrectly identified as stolen.
- In South Africa, critics say that Vumacam’s camera systems, which recognize objects, behaviors, and license plate numbers, reinforce law enforcement biases against Blacks.
Why it matters: Commercial surveillance networks have been deployed without much oversight or consent, and police are rarely accountable for how they use such systems. Permissive policies around these devices amount to warrantless monitoring of millions of innocent people by police as well as fellow citizens.
We’re thinking: While AI can help police catch criminals, we do not condone a silent erosion of civil liberties and privacy. We support clear, consistent guidelines on appropriate uses of face recognition, license plate readers, and other tracking technologies.
Deciphering The Brain’s Visual Signals
What’s creepier than images from the sci-fi TV series Doctor Who? Images generated by a network designed to visualize what goes on in peoples’ brains while they watch Doctor Who.
What’s new: Lynn Le, Luca Ambrogioni, and colleagues at Radboud University and Max Planck Institute for Human and Brain Cognitive Sciences developed Brain2Pix, a system that reconstructs what people saw from scans of their brain activity.
Key insight: The brain uses neurons nearby one another to represent visual features nearby one another. Convolutional neural networks excel at finding and using spatial patterns to perform tasks such as image generation. Thus, a convolutional neural network can use the spatial relationships between active neurons in a brain scan to reconstruct the corresponding visual image.
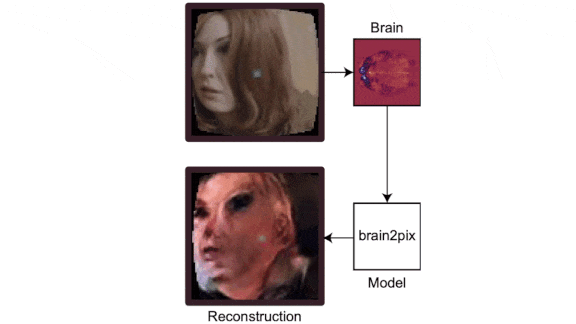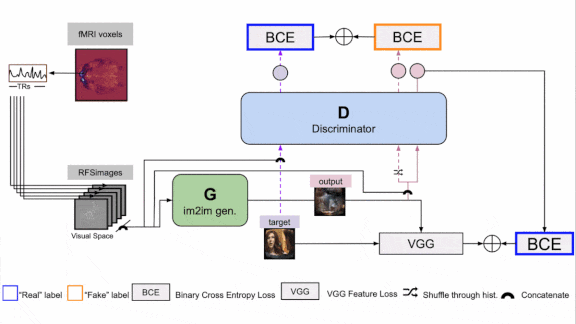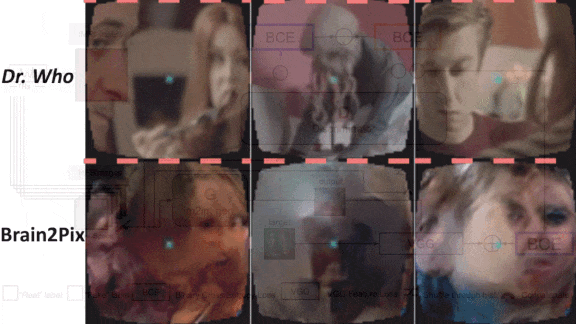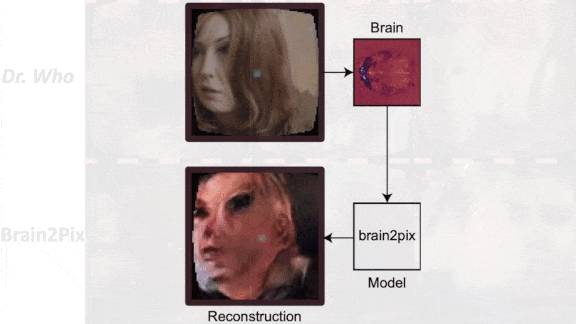
How it works: The authors used a picture-to-picture generative adversarial network (GAN) to try to produce an image of what a person was looking at based on functional magnetic resonance imaging (fMRI): 3D scans that depict blood oxygenation in the brain, which indicates neuron activity. They trained the GAN on Doctor Who fMRI, a collection of video frames from 30 episodes of Doctor Who and corresponding fMRIs captured as an individual watched the show.
- The authors converted each 3D scan into 2D images, each of which represented distinct sections of the brain, using a neuroscientific device known as a receptive field estimator .
- They trained the GAN’s discriminator to classify whether an image came from Doctor Who or the GAN’s generator. They trained the generator with a loss function that encouraged it to translate the 2D images of neuron activity into an image that would fool the discriminator.
- The generator used two additional loss terms. The first term aimed to minimize the difference between the pixel values of a video frame and its generated counterpart. The second term aimed to minimize the difference between representations, extracted by
a pretrained VGG-16, of a video frame and its generated counterpart. - The generator used a convolutional architecture inspired by U-Net in which residual connections passed the first layer’s output to the last layer, second layer’s output to the penultimate layer, and so on. This arrangement helped later layers in the network to preserve spatial patterns in the brain scans.
Results: The researchers used an AlexNet to extract representations of Brain2Pix images and Doctor Who frames and compared the distance between them. Brain2Pix achieved an average distance of 4.6252, an improvement over the previous state-of-the-art method’s average of 5.3511.
Why it matters: The previous state-of-the-art used 3D convolutions directly on the raw fMRIs, yet the new approach fared better. For some problems, engineering features — in this case, converting fMRIs into 2D — may be the best way to improve performance.
We’re thinking: We wouldn’t mind sitting in an fMRI machine for hours on end if we were binge-watching Doctor Who.

Spotlight on Unreproducible Results
A new website calls out AI research that may not lend itself to being reproduced.
What’s new:Papers Without Code maintains a directory of AI systems that researchers tried but failed to reproduce. The site (the name of which is a play on the indispensable Papers With Code), aims to save researchers time wasted trying to replicate results published with insufficient technical detail.
How it works: Users can submit a link to a paper, a link to their attempt to reproduce it, and an explanation of why their effort failed.
- After reviewing the links, the site’s administrators contact the original authors and request data, code, and pointers necessary to reproduce their work. If the authors don’t reply or provide insufficient information, the administrators add the paper to a public list.
- To date, the website has received more than 10 submissions, six of which have been posted. Two authors have uploaded their code. Once a paper passes muster, its author is encouraged to post it to Papers With Code, which documents 40,000 replicated computer science studies.
- The researcher behind Papers Without Code, who goes by the user name ContributionSecure14 on Reddit, started the website after wasting a week trying to replicate a machine learning study.
They advise authors who can’t release their code, data, or infrastructure for proprietary reasons to work directly with others trying to replicate their efforts. “There’s no point in publishing the paper in the public domain if others cannot build off it,” they told TechTalks.
Behind the news: Google engineer Pete Warden proclaimed a “machine learning reproducibility crisis” in 2018. Since then the issue has emerged as a widespread concern.
- Last year, 31 researchers criticized the lack of technical detail in a Google paper that describes a cancer system that purportedly outperformed human doctors.
- One of that paper’s coauthors, Joelle Pineau of McGill University and Facebook, worked with NeurIPS to ensure that papers submitted to the conference come with working code and data. She also published a Machine Learning Reproducibility Checklist.
- Rescience C is a peer-reviewed journal that publishes replication efforts of computer science papers.
Why it matters: Reproducibility is an essential part of science, and AI is one of many fields facing a so-called replication crisis brought on by growing numbers of papers that report unreliable results.
We’re thinking: While we applaud the spirit of this effort, without a transparent review process and a public list of reviewers, it could be used to demean researchers unfairly. We urge other research venues and institutions to take up the cause.
A MESSAGE FROM DEEPLEARNING.AI

Join us on March 25 at 10 a.m. Pacific Time for our second AI+X expert panel, AI Innovation in Healthcare, hosted by Workera in partnership with DeepLearning.AI. Hear industry leaders discuss the latest trends, opportunities, and challenges at the intersection of AI and healthcare.

Chatbots Against Depression
A language model is helping crisis-intervention volunteers practice their suicide-prevention skills.
What’s new: The Trevor Project, a nonprofit organization that operates a 24-hour hotline for LGBTQ youth, uses a “crisis contact simulator” to train its staff in how to talk with troubled teenagers, MIT Technology Review reported.
How it works: The chatbot plays the part of a distraught teenager while a counselor-in-training tries to determine the root of their trouble.
- In-house engineers developed the system with help from Google. The team tested several models before settling on GPT-2.
- The model was pretrained on 45 million web pages and fine-tuned on transcripts of role-playing between trainees and The Trevor Project staffers.
- A different model helps triage incoming calls, also developed in collaboration with Google. When people log in to the chat system, a prompt asks them to describe their feelings. An ALBERT implementation analyzes their response for indicators of self-harm, flags those at highest risk, and prioritizes them to converse with a counselor.
Behind the news: AI is being used in a growing number of mental health settings.
- ReachVet, a program of the U.S. Department of Veterans Affairs, scans military records and generates a monthly list of former military members at high risk of suicide.
- Chatbots like Flow, Lyssn, and Woebot (where Andrew Ng is chairman) aim to alleviate mood disorders like anxiety and depression in lieu of a human therapist.
Why it matters: Suicide rates among LGBTQ teens are two to seven times higher than among their straight peers, and they’re twice as likely to think about taking their own lives, according to the U.S. government. The Trevor Project fields over 100,000 crisis calls, chats, and texts annually. Speeding up the training pipeline could save lives.
We’re thinking: As a grad student at MIT, Andrew tried to volunteer for a crisis call line, but his application was rejected. Maybe training from this system would have helped!
Pictures From Words and Gestures
A new system combines verbal descriptions and crude lines to visualize complex scenes.
What’s new: Google researchers led by Jing Yu Koh proposed Tag-Retrieve-Compose-Synthesize (TReCS), a system that generates photorealistic images by describing what they want to see while mousing around on a blank screen.
Key insight: Earlier work proposed a similar system to showcase a dataset, Localized Narratives, that comprises synchronized descriptions and mouse traces captured as people described an image while moving a cursor over it. That method occasionally produced blank spots. The authors addressed that shortcoming by translating descriptive words into object labels (rather than simply matching words with labels) and distinguishing foreground from background.
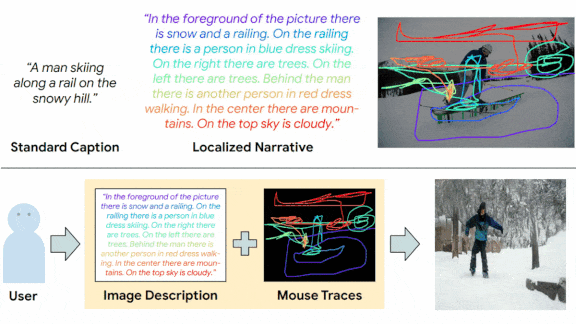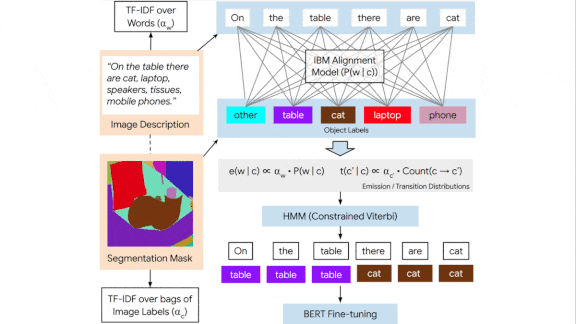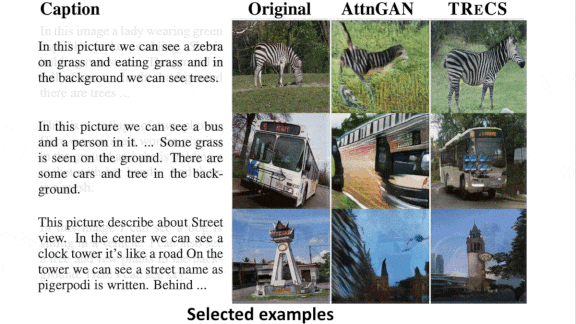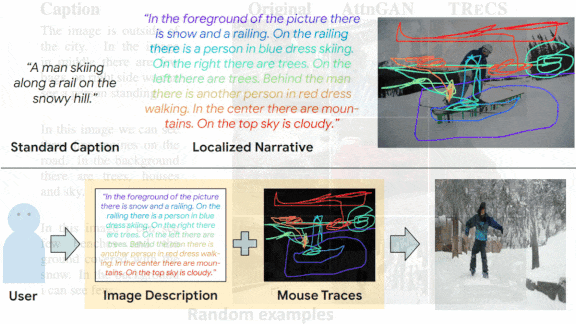
How it works: The Local Narratives dataset provides an inherent correspondence between every word in a description and a mouse trace over an image. TReCS uses this correspondence to translate words into labels of objects that populate a scene. The authors trained the system on the portion of Localized Narratives that used images in COCO and tested it on the portion that used Open Images.
- Given a description, a BERT model assigned an object label to each word in the description. The authors obtained ground-truth labels by matching the mouse traces for each word to object segmentation masks (silhouettes) for the images described. Then they fine-tuned the pretrained BERT to, say, attach the label “snow” to each of the words in “skiing on the snow.”
- For each label assigned by BERT, the system chose a mask from a similar image (say, a photo taken in a snowy setting). The authors trained a cross-modal dual encoder to maximize the similarity between a description and the associated image, and to minimize the similarity between that description and other images. On inference, given a description, the authors used the resulting vectors to select the five most similar training images.
- The system used these five images differently for foreground and background classes (an attribute noted in the mask dataset). For foreground classes such as “person,” it retrieved the masks with the same label and chose the one whose shape best matched the label’s corresponding mouse trace. For background classes such as “snow,” it chose all of the masks from the image whose masks best matched the labels and combined shape of the corresponding mouse traces.
- The authors arranged the masks on a blank canvas in the locations indicated by the mouse traces. They positioned first background and then foreground masks, reversing the order in which they were described. This put the first-mentioned object in front.
- A generative adversarial network learned to generate realistic images from the assembled masks.
Results: Five judges compared TReCS’ output with that of AttnGAN, a state-of-the-art, text-to-image generator that did not have access to mouse traces. The judges preferred TReCS’ image quality 77.2 percent to 22.8 percent. They also preferred the alignment of TReCS output with the description, 45.8 percent to 40.5 percent. They rated both images well aligned 8.9 percent of the time and neither image 4.8 percent of the time.
Why it matters: The authors took advantage of familiar techniques and datasets to extract high-level visual concepts and fill in the details in a convincing way. Their method uncannily synthesized complex scenes from verbal descriptions (though the featured example, a skier standing on a snowfield with trees in the background, lacks the railing and mountain mentioned in the description).
We’re thinking: Stock photo companies may want to invest in systems like this. Customers could compose photos via self-service rather than having to choose from limited options. To provide the best service, they would still need to hire photographers to produce raw material.