
Dear friends,
Engineers need strong technical skills to be successful. But many underestimate the importance of developing strong communication skills as well.
Many AI products are so complex that it’s hard for any single person — no matter how talented — to build the whole thing. As teamwork becomes more central to AI development, clear communication is becoming more important, too.
In large and small companies, I’ve seen senior engineers with no management responsibility (often called individual contributors) whose words carried more weight than those of VPs who managed large teams. They often had a massive positive impact on the projects they took part in. How did they accomplish this? These individuals are generally:
- Technically sophisticated, with a deep understanding of the most promising technical approach to a problem.
- Cross-functional collaborators who can help match technology with business goals.

- Positive contributors to the company’s culture. For example, they foster a transparent and safe environment where ideas are evaluated based on merit and all voices can be heard.
- Clear communicators who help others understand their thinking through speaking or writing.
What if you’re not yet a strong communicator? That’s okay! I used to struggle with my writing and speaking as well, and I still have ample room for improvement. Last week, while I was giving a practice talk on a new way to think about data (yes, I do practice talks), a friend told me that a section of my presentation was confusing. He was right! I try to embrace critical feedback on my communications and hope you will, too.
There’s no need to set an impossible standard for yourself; just aim to improve a little every month. The only person you should compare yourself to is the person you used to be. Let us all keep trying to be better than our previous selves.
Keep learning!
Andrew
News

Drones For Defense
Drone startups are taking aim at military customers.
What’s new: As large tech companies have backed away from defense work, startups like Anduril, Shield AI, and Teal are picking up the slack. They’re developing autonomous fliers specifically for military operations, The New York Times reported. None of these companies has put weapons in their drones, but some have declared their willingness to do so.
What’s Happening: The new wave of AI-powered drones is designed for martial missions like reconnaissance and search and rescue.
- Anduril’s Ghost, pictured above, performs all of its computing on-device using an AI system that reads sensor data, performs object recognition, and controls navigation. The drone’s chassis can be fitted with a variety of equipment including radio surveillance gear. The UK Royal Marines have used Anduril’s drones, and the U.S. military has tested them.
- Shield AI is developing a quadcopter called Nova that specializes in tasks like mapping the interior of buildings or scouting threats. The company also makes a reinforcement learning system for training drones.
- Golden Eagle, a quadcopter from Teal, is geared for surveillance. It uses infrared and visible light cameras to identify and track targets.
Behind the news: The U.S. military and tech industry have a long history of collaboration and cross-pollination. In recent years, however, large tech companies including Google, Microsoft, and Salesforce have faced protests by employees, investors, and the public over their work for the Departments of Defense and Homeland Security.
- Google responded by canceling some defense contracts.
- Some venture capital groups have refused to fund AI that can be weaponized. Others like Andreesen Horowitz, Founders Fund, and General Catalyst support defense-focused startups including Anduril.
- Outside Silicon Valley, grassroots efforts like the Campaign to Stop Killer Robots are working for a global ban on autonomous weapons.
Why it matters: The question of whether and to what extent AI can and should be used for military purposes is a critical one that grows more pressing as technology advances.
We’re thinking: Until a ban is in place — one that has clear boundaries and mechanisms for enforcement — profit-seeking companies are sure to develop lethal AI. The Batch, along with more than 100 countries and thousands of AI scientists, opposes development of fully autonomous lethal weapons.
Seeing People From a New Angle
Movie directors may no longer be confined to the camera angles they caught on video. A new method lets them render an actor from any angle they want.
What’s new: Sida Peng led researchers at Zhejiang University, Chinese University of Hong Kong, and Cornell University to create Neural Body, a procedure that generates novel views of a single human character based on shots from only a few angles.
Key insight: An earlier approach called NeRF extracted a 3D model from images taken by as few as 16 still cameras, which could be used to synthesize an image from a novel angle. The authors took a similar approach but aggregated information not only from different angles but throughout the associated video frames. This enabled their system to match an actor’s pose from any angle, across successive frames, based on input from four cameras.
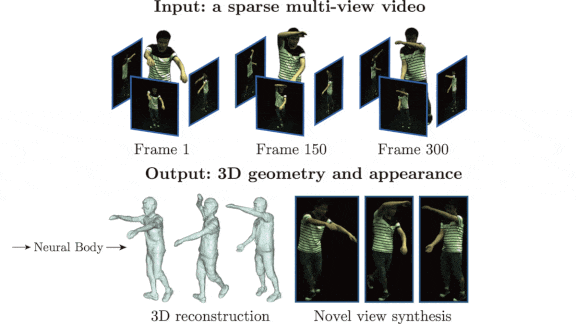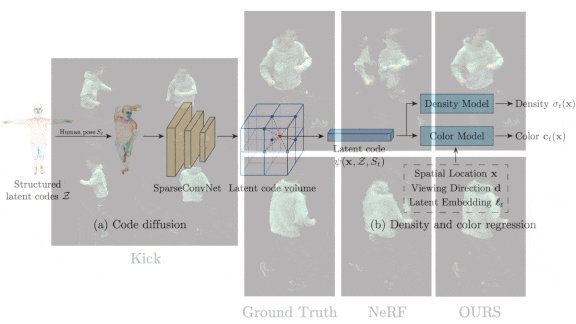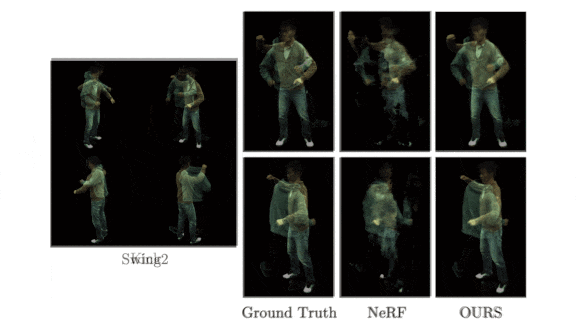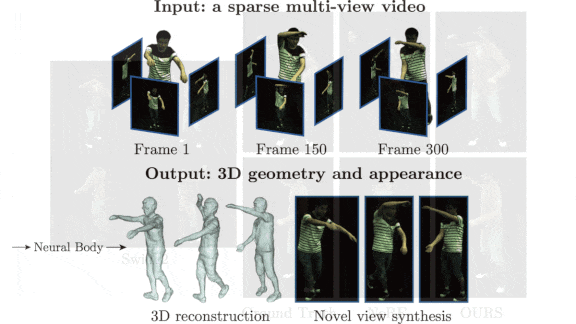
How it works: Neural Body creates a 3D model, poses it, and determines the colors to render from any viewpoint. The authors assembled a dataset of nine scenes shot from 21 angles. To synthesize a fresh angle on a particular scene, they trained the system on four angles chosen at random and tested it on the rest.
- Given clips of a scene shot from four angles, the authors preprocessed the video frames to extract the human figure and remove the background. Then, for each frame, they used Total Capture to pose a deformable human model to match the image. This process generated a mesh model. They assigned a trainable vector to each vertex in the mesh.
- SparseConvNet, a convolutional neural net specialized for 3D point clouds, learned to map (the authors use the word diffuse) the vertex vectors to a separate set of vectors for nearby positions on a 3D grid.
- To determine the color of each pixel from a given viewing angle, the authors traced a ray from the camera through a pixel. At evenly spaced locations along the ray, they calculated representations based on the grid vectors. Given these representations, the locations along the ray, and the viewing angle, two fully connected networks predicted parameters needed to predict the color. Given the parameters, the volume rendering integral equation found the color. They repeated this process for all pixels.
- The vertex representations, the SparseConvNet, and the two fully connected networks were trained together to minimize differences between predicted and actual images for all four videos.
Results: Given a frame from the training set and one of the 17 angles on which the system didn’t train, the authors compared the images generated by Neural Body to the actual images. They measured the peak-signal-to-noise ratio, a gauge of how well a generated image reproduces the original (higher is better). Neural Body achieved 27.87 average peak signal-to-noise ratio compared to NeRF’s 19.63.
Yes, but: The system produces only the character’s image. In practical use, a filmmaker would need to composite the character into a scene.
Why it matters: Models don’t always use available information efficiently during training. By integrating across video frames, rather than simply integrating different camera angles at the same moment in time, Neural Body is able to take advantage of all the information available to it.
We’re thinking: While shooting the Deep Learning Specialization, we tried an obtuse angle, but it was never right.
AI for Business Is Booming
Commercial AI research and deployments are on the rise, a new study highlights.
What’s new: The latest edition of the AI Index, an annual report from Stanford University, documents key trends in the field including the growing importance of private industry and the erosion of U.S. dominance in research.
What’s new: Researchers at the Stanford Institute for Human-Centered Artificial Intelligence compiled AI Index 2021 by analyzing academic research, investment reports, and other data sources. Some standout trends:
- Private investment in AI grew last year by 9.3 percent despite the pandemic’s chilling effect on the global economy. Drug development saw the most explosive growth, reaping nearly $13.8 billion from investors compared to just under $2.5 billion in 2019. Autonomous vehicles came in second with $4.5 billion followed by educational applications with roughly $4.1 billion.
- Sixty-five percent of newly minted PhDs in North America last year took jobs with private companies rather than academia or government, up from 44 percent in 2010. Universities were the top source of U.S. AI research, but corporations published roughly 19 percent of peer-reviewed research papers.
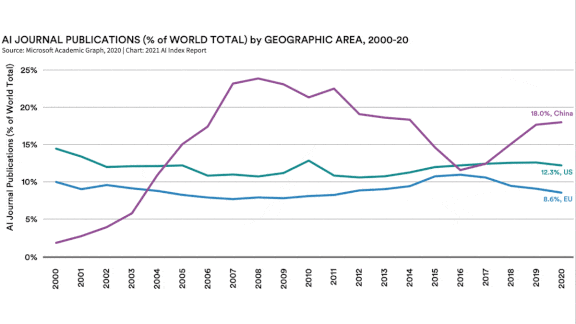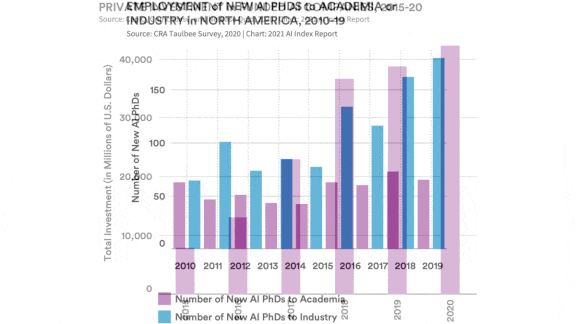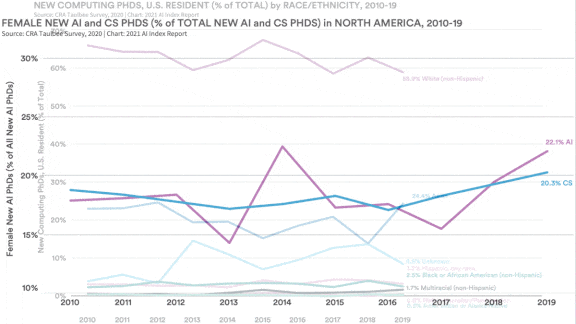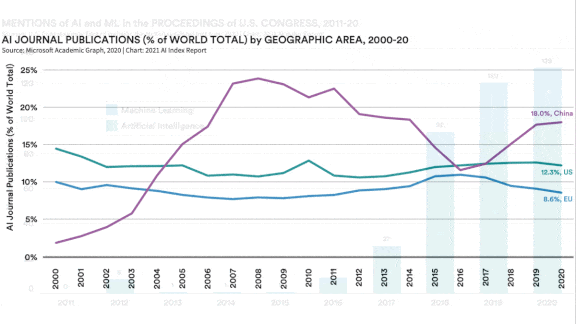
- China has produced the highest volume of AI research for years, but in 2020 it also received the most academic citations. The U.S offered the most undergraduate and master’s programs. Nearly two-thirds of AI PhDs in the U.S. went to students from other countries.
- U.S. legislation and congressional reports mentioned AI 486 times during the 2019-20 session, a threefold increase over the previous session, suggesting that lawmakers are taking a bigger role in determining the technology’s future.
Behind the news: AI is a rising tide, but it’s not yet lifting all boats. Women made up only 16 percent of tenure-track computer science faculty worldwide in 2019 and about 18 percent of AI and computer science PhDs awarded in North America over the last decade. Meanwhile, Hispanics and Blacks accounted for only 3.2 and 2.3 percent respectively of U.S. AI PhDs in 2019.
Why it matters: Private industry’s embrace of AI means more of the technology will be put to real-world use. The growth in corporate research could benefit the field as a whole, though it also highlights the urgent need for well defined standards in technology development, implementation, and auditing.
We’re thinking: The figures for women and minorities in AI are unconscionable. AI is creating tremendous wealth and will continue to do so. But practices are evolving rapidly, and we have only a short time left to make sure this wealth is fairly shared across genders, ethnicities, and nations. We urge governments, companies, and citizens to act quickly to promote AI’s broad positive impact.
A MESSAGE FROM DEEPLEARNING.AI

Become a machine learning engineer with FourthBrain’s 16-week, live, online, instructor-led program. Our March cohort filled up early, and we’re now enrolling for our May 15 cohort on a rolling basis. Submit your application by March 15, 2021 to save your seat. Learn more
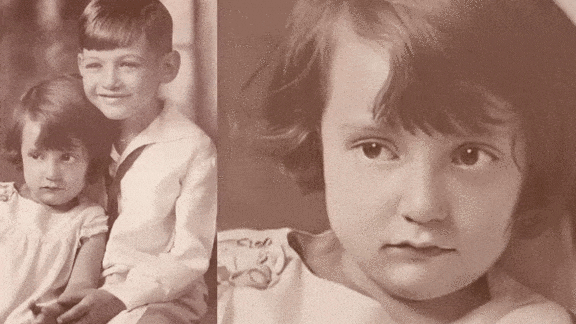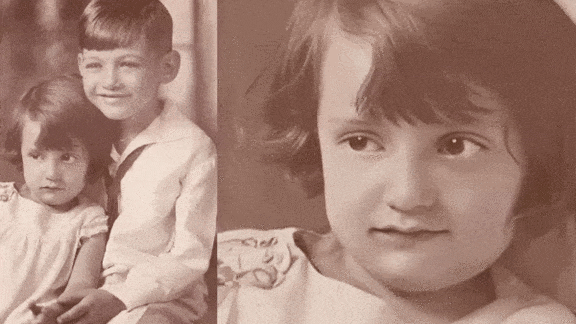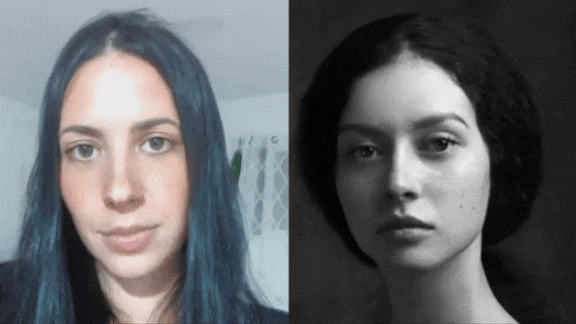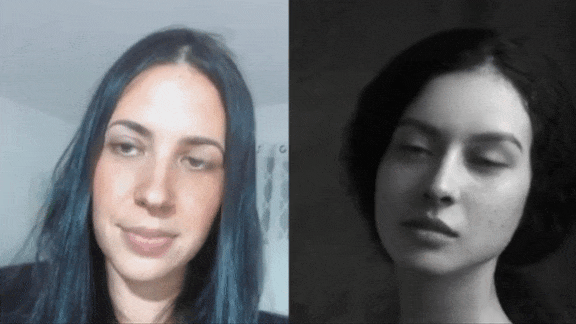
Make Your Ancestors Smile
Machine learning is bringing old photos to life.
What’s new: A new service from genealogy company MyHeritage lets users animate their ancestors’ portraits, making them smile, blink, and turn their heads.
How it works: A MyHeritage account is required to use the service, called Deep Nostalgia. A free account allows users to animate five images, while paying customers can animate an unlimited number.
- Deep Nostalgia accepts an uploaded photo and boosts its resolution.
- It passes the photo to D-ID Live Portrait, which modifies its pixels to match motions in a pre-recorded video.
- The service offers several videos in which a person turns their head, blinks, and smiles. Users can choose one or apply one selected automatically to suit the uploaded face’s orientation.
Behind the news: This is just the latest way AI is helping amateur archivists bring the past to life.
- MyHeritage also licenses DeOldify, a system that uses deep learning to colorize black-and-white photos.
- Denis Shiryaev, a researcher who uses neural networks to colorize archival video footage as previously featured in The Batch, brought his technology to the market via a company called Neural Love.
Why it matters: Seeing your ancestors come alive, even for a few seconds, is a powerful emotional experience — and possibly a lucrative market niche.
We’re thinking: We look forward to a day when our great-grandkids can turn our cell phone videos into haptic holographic projections.
ImageNet Performance: No Panacea
It’s commonly assumed that models pretrained to achieve high performance on ImageNet will perform better on other visual tasks after fine-tuning. But is it always true? A new study reached surprising conclusions.
What’s new: Alexander Ke, William Ellsworth, Oishi Banerjee, and colleagues at Stanford systematically tested various models that were pretrained on ImageNet and fine-tuned to read X-rays. They found that accuracy on ImageNet did not correlate with performance on the fine-tuned tasks. The team also included Andrew Ng and Pranav Rajpurkar, instructor of DeepLearning.AI’s AI for Medicine Specialization.
Key insight: Previous work found that accuracy on ImageNet prior to fine-tuning correlated strongly with accuracy on some vision tasks afterward. But ImageNet images differ from X-rays, and model architecture also influences results — so knowledge gained from ImageNet may not transfer to medical images.
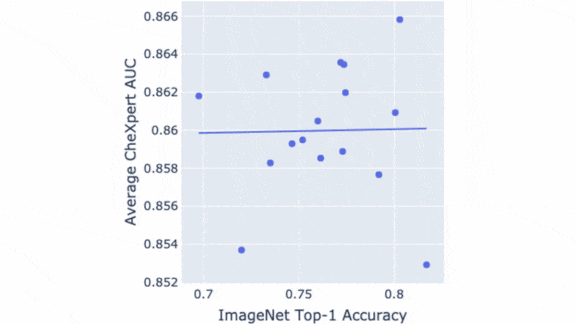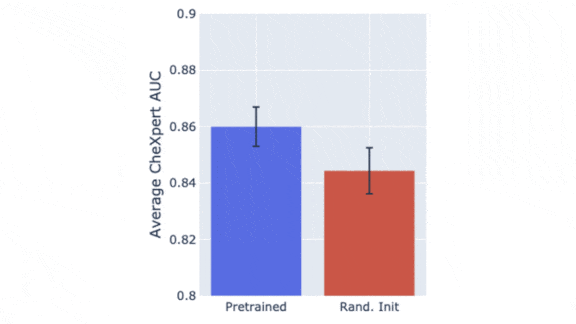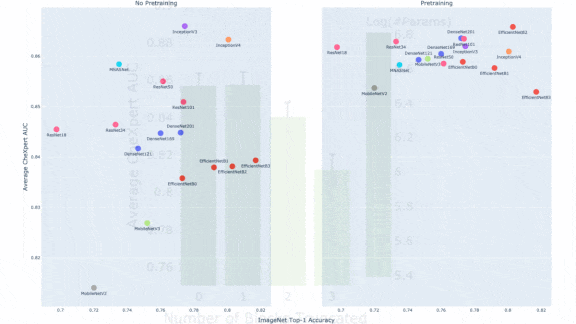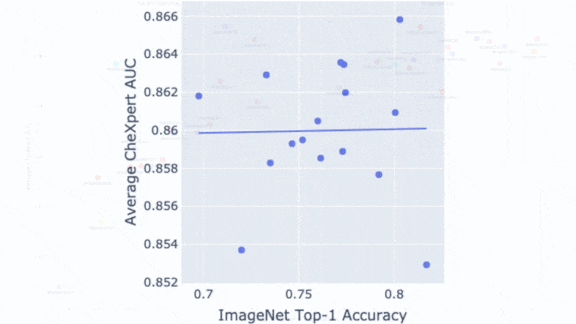
How it works: The authors evaluated the impact of published ImageNet performance, ImageNet training, and parameter count on the fine-tuned performance of six convolutional neural net architectures (including older ones such as ResNet and newer ones such as EfficientNet) in a variety of sizes. They fine-tuned the models to identify six medical conditions using the CheXpert dataset of X-ray images. To compensate for potential variations in implementation, they tested each model’s performance periodically during training, saved copies, and evaluated an ensemble of the 10 best performers. They gauged performance via the area under the curve (AUC), a measure of true versus false positives where 1 is a perfect score.
- To learn whether ImageNet performance correlated with performance on CheXpert, they compared each fine-tuned model’s CheXpert AUC with the pretrained version’s published ImageNet accuracy.
- To find the impact of ImageNet pretraining, they compared models pretrained on ImageNet with randomly initialized versions.
- To learn whether a model’s size correlated with its performance after pretraining and fine-tuning, they compared its parameter count to CheXpert AUC.
- Prior to fine-tuning, they removed up to four blocks from each model and compared CheXpert performance after different degrees of truncation.
Results: The team found no correlation between ImageNet accuracy and average CheXpert AUC scores after fine-tuning. Specifically, for pretrained models, the Spearman correlation was 0.082. Without pretraining, it was 0.059. However, ImageNet pretraining did lead to an average boost of 0.016 AUC in fine-tuned performance. For models without pretraining, the architecture influenced performance more than the parameter count did. For example, the average AUC of MobileNet varied by 0.005 across different sizes, while the difference between InceptionV3 and MobileNetV2 was 0.052 average AUC. Removing one block from a model didn’t hinder performance, but removing more did.
Why it matters: As researchers strive to improve performance on ImageNet, they may be overfitting to the dataset. Moreover, state-of-the-art ImageNet models are not necessarily ideal for processing domain-specific data.
We’re thinking: Language models have made huge advances through pretraining plus fine-tuning. It would be interesting to see the results of a similar analysis in that domain.