
Dear friends,
One of the most important skills of an AI architect is the ability to identify ideas that are worth working on. Over the years, I’ve had fun applying machine learning to manufacturing, healthcare, climate change, agriculture, ecommerce, advertising, and other industries. How can someone who’s not an expert in all these sectors find meaningful projects within them? Here are five steps to help you scope projects effectively.
Step 1: Identify a business problem (not an AI problem). I like to find a domain expert and ask, “What are the top three things that you wish worked better? Why aren’t they working yet?” For example, if you want to apply AI to climate change, you might discover that power-grid operators can’t accurately predict how much power intermittent sources like wind and solar might generate in the future.
Step 2: Brainstorm AI solutions. When I was younger, I used to execute on the first idea I was excited about. Sometimes this worked out okay, but sometimes I ended up missing an even better idea that might not have taken any more effort to build. Once you understand a problem, you can brainstorm potential solutions more efficiently. For instance, to predict power generation from intermittent sources, we might consider using satellite imagery to map the locations of wind turbines more accurately, using satellite imagery to estimate the height and generation capacity of wind turbines, or using weather data to betterpredict cloud cover and thus solar irradiance. Sometimes there isn’t a good AI solution, and that’s okay too.
Step 3: Assess the feasibility and value of potential solutions. You can determine whether an approach is technically feasible by looking at published work, what competitors have done, or perhaps building a quick proof of concept implementation. You can determine its value by consulting with domain experts (say, power-grid operators, who can advise on the utility of the potential solutions mentioned above).
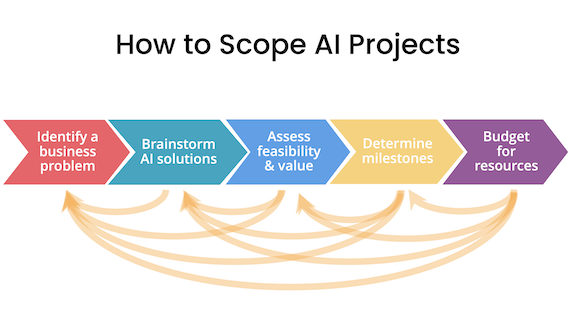
Step 4: Determine milestones. Once you’ve deemed a project sufficiently valuable, the next step is to determine the metrics to aim for. This includes both machine learning metrics such as accuracy and business metrics such as revenue. Machine learning teams are often most comfortable with metrics that a learning algorithm can optimize. But we may need to to stretch outside our comfort zone to come up with business metrics such as those related to user engagement, revenue, and so on. Unfortunately, not every business problem can be reduced to a matter of optimizing test set accuracy! If you aren’t able to determine reasonable milestones, it may be a sign that you need to learn more about the problem. A quick proof of concept can help supply the missing perspective.
Step 5: Budget for resources. Think through everything you’ll need to get the project done including data, personnel, time, and any integrations or support you may need from other teams. For example, if you need funds to purchase satellite imagery, make sure that’s in the budget.
This is an iterative process. If, at any step, you find that the current direction is infeasible, return to an earlier step and proceed with your new understanding.
Is there a domain that excites you where AI might make a difference? I hope these steps will guide you in exploring it — even if you don’t yet have deep expertise in that field. AI won’t solve every problem, but as a community, let’s look for ways to make a positive impact wherever we can.
Keep learning!
Andrew
News

Google Overhauls Ethical AI Team
Having dismissed two key researchers, Google restructured its efforts in AI ethics.
What’s new: Marian Croak, an accomplished software engineer and vice president of engineering at Google, will lead a new center of expertise in responsible AI, the company announced. The move came amid uproar over the exits of her predecessors Timnit Gebru and Margaret Mitchell.
What happened: Google’s Ethical AI group has been in flux since last December when Gebru, the group’s technical co-lead with Mitchell, left the company. Gebru says she was fired, while Google’s latest communiqué refers to Gebru’s “exit.”
- In December, members of Ethical AI demanded that Google CEO Sundar Pichai reinstate Gebru and make other changes. More than 2,600 Google employees signed a letter expressing solidarity with the ethics researcher.
- Google put Croak in charge of the newly established Responsible AI Research and Engineering Center of Expertise, which will oversee Ethical AI and coordinate research into fairness and bias among 10 Google teams.
- One day after announcing the new organization, Google dismissed Margaret Mitchell. She had been under investigation internally for allegedly copying documents related to Gebru’s departure to a personal computer. Mitchell’s termination triggered another wave of employee outrage.
Behind the news: In December, Gebru was on the verge of publishing a paper that criticized large language models including Google’s own BERT. Executives asked her to either retract the paper or remove the names of all Google co-authors.
- Gebru responded with a request that Google take certain actions as a condition of her employment. Her managers interpreted this as an ultimatum and told her they had accepted her resignation. Gebru has said that she did not offer to resign.
- On Friday, Dean apologized in an email to the staff for Google’s handling of Gebru’s exit and announced new policies prompted by an internal review.
Why it matters: Google is a leader in AI and one of the most powerful companies in the world. Its approach to ethical challenges — and its treatment of employees — are highly influential throughout the tech industry.
We’re thinking: Under Gebru and Mitchell, Google’s Ethical AI team developed tools to improve model transparency, examined how social constructs of race manifest in AI, and released a framework for identifying risks posed by models in development. We hope the people who carry on this work will pursue similarly ambitious projects.
Covid-19 Triage
The pandemic has pushed hospitals to their limits. A new machine learning system could help doctors make sure the most severe cases get timely, appropriate care.
What’s new: Anuroop Sriram, Matthew Muckley, and colleagues at Facebook, NYU School of Medicine, and NYU Abu Dhabi developed a system that examines X-ray images to predict which Covid-19 patients are at greatest risk of decline.
Key insight:Previous methods assess Covid risk based on a single chest X-ray. But when making assessments, clinicians often look for relative changes between successive X-rays to determine whether a patient’s condition is improving or deteriorating. The researchers used consecutive X-rays to improve risk assessment.
How it works: The authors trained their system to predict the probability that a patient would die, require intubation, need intensive care, or need more oxygen over the next 24, 48, 72, or 96 hours.
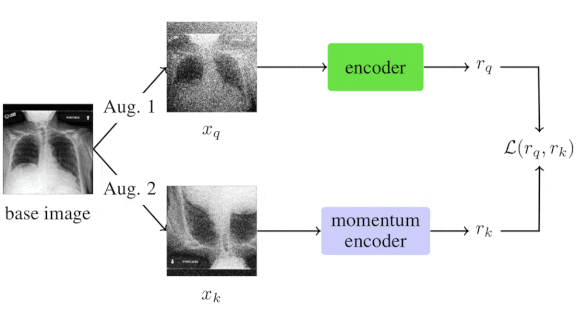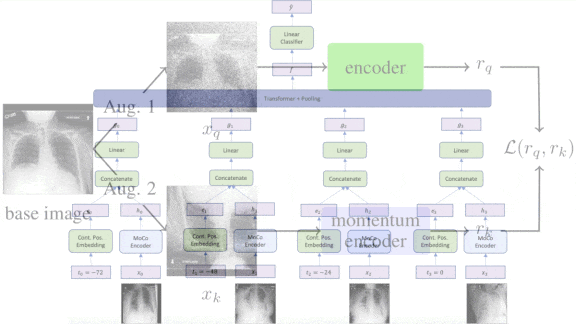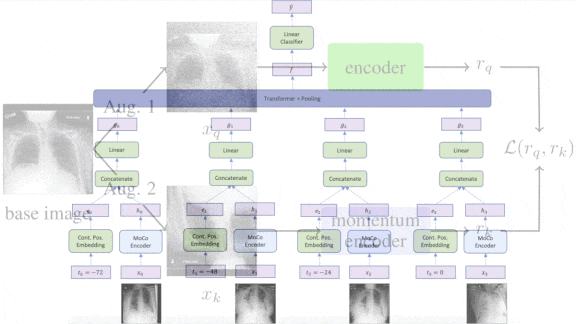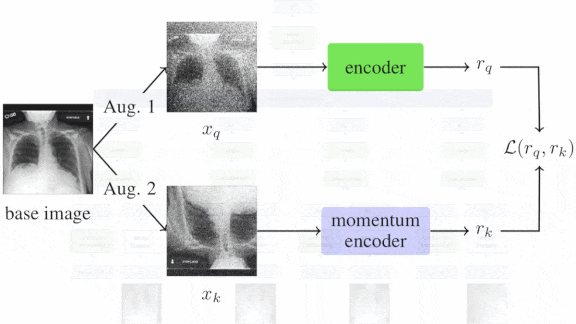
- The authors augmented two datasets that comprise chest X-rays of Covid patients via cropping, flipping, or random noise. Using the augmented data, they pretrained two DenseNet-121 encoders using a contrastive loss function. The contrastive loss encouraged the models to produce similar representations if the two images had the same parent X-ray and dissimilar representations otherwise.
- They fine-tuned the system on NYU Covid, a dataset that contains sequences of chest X-rays labelled with the patients’ outcomes.
- After pretraining, the first encoder generated a representation of each X-ray in a sequence. A transformer processed these representations. The researchers summed its output into a single vector.
- A linear classifier used this vector to make the final prediction.
Results: The system achieved a mean AUC (area under the curve, a measure of true versus false positives where 1 is a perfect score) of 0.785, 0.801, 0.790, and 0.790 when predicting adverse outcomes at 24, 48, 72, and 96 hours into the future, respectively. Those scores were comparable to those of two clinicians who achieved an average AUC of 0.784, 0.787, 0.761 and 0.754.
Why it matters: Pretraining followed by fine-tuning opens up important applications where data is too scarce for simpler learning approaches.
We’re thinking: The pandemic has been an early test of AI’s utility in medicine. The record so far has been mixed, but we’re glad to see research that shows promising results for both fighting Covid and improving healthcare in general.

ID By Eyeglasses?
Smart glasses in the works at Facebook may be equipped with face recognition.
What’s new: The social media colossus plans to market augmented-reality headgear, and it’s considering a feature that would overlay a person’s name on their face, according to Buzzfeed.
What’s happening: Announced by Mark Zuckerberg in 2017 (shown in the video clip above), the glasses are set to drop this year. Some capabilities — including face recognition — may be added later, Facebook vice president Andrew Bosworth told Bloomberg News.
- Bosworth said the technology could remind users of the names of people whom they had met previously. Similarly, it could help people with face blindness, a neurological condition that makes it hard to recognize familiar faces.
- Facebook is assessing the legal ramifications, since this capability may not be lawful everywhere. For instance, an Illinois law against collecting biometric data might bar the product in that state.
- Where local laws don’t pose a barrier, the company may formulate its own rules factoring in the potential for harm, said Facebook diversity officer Maxine Williams.
Behind the news: Facebook’s smart glasses, which will be manufactured by Ray-Ban, will compete against Snapchat Spectacles and Google Glass (lately refocused from consumer to enterprise applications).
Why it matters: Wearable hardware that recognizes faces raises serious questions about privacy. Facebook has an incentive to tread carefully: It was the least trusted of nine major social media platforms in a recent survey.
We’re thinking: A Facebook foray into mass-market face recognition could force U.S. lawmakers finally to issue rules on how the technology can and can’t be used.
A MESSAGE FROM DEEPLEARNING.AI

Join us for “Applied Analytics From End-to-End,” an AI Access conversation with Zachary Hanif, senior director of machine learning at Capital One. Zachary will explore core challenges and show how distributed data engineering and a product-oriented mindset can make an impact. RSVP
Transformer Variants Head to Head
The transformer architecture has inspired a plethora of variations. Yet researchers have used a patchwork of metrics to evaluate their performance, making them hard to compare. New work aims to level the playing field.
What’s new: Yi Tay and colleagues at Google developed Long-Range Arena, a suite of benchmarks designed to standardize comparisons between transformers. The term long-range refers to transformers’ ability to capture dependencies between tokens in an input sequence that are far apart.
Key insight: The power of the original transformer lies in its ability to track relationships between tokens anywhere in an input sequence. But that power comes at a cost: The model slows down and its memory requirement rises dramatically as the length of its input increases. Many variants were created to alleviate this issue. These models cry out for tests that challenge their ability over long sequences.
How it works: The suite comprises six tests designed to probe different aspects of transformer behavior.
- Long ListOps requires a model to calculate the numeric output from a long list of ordered operations; for instance, to determine that [MAX 4 3 [MIN 2 3 ] 1 0 [MEDIAN 1 5 8 9, 2]] equals 5. It investigates how well a model can parse long sequences.
- Character-Level Text Classification is a binary sentiment classification task based on movie reviews in the IMDb dataset. Its objective is to test a model’s accuracy when processing documents up to 4,000 characters long.
- Character-Level Document Retrieval evaluates similarity between two documents using the ACL Anthology Network dataset, which identifies when one paper cites another. It assesses a model’s ability to compress text inputs for comparison.
- Image Classification on Sequences of Pixels classifies objects in CIFAR-10 images that have been flattened into a one-dimensional sequence. This tests how well a model learns spatial relationships between pixels.
- Pathfinder and Pathfinder-X require a model to decide whether two circles are connected by a path that consists of dashes in a generated image. Pathfinder-X increases the difficulty by making the image area 16 times larger. Both tasks test how well a model learns long-range spatial relationships. Pathfinder-X also gauges how the results change if the sequence length is much longer.
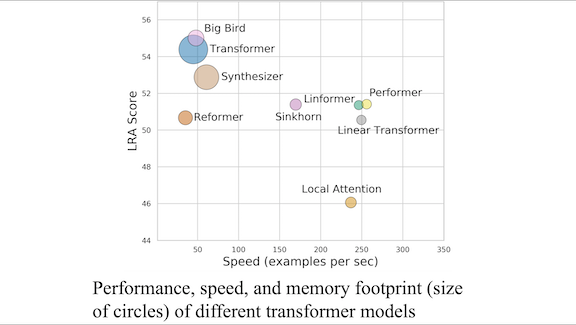
Results: The authors tested 10 transformers. While some shined in one task or another, none was the clear front runner. Big Bird achieved the highest average accuracy – 55.01 percent across five tasks — but it didn’t achieve the top score in any single task. Performer, dominated character-level text classification, performing 5.7 times faster than a vanilla transformer. Linformer used the least memory, 9.58 times less than the vanilla transformer. All models failed Pathfinder-X: Their ability to classify the image was no better than random chance, showing that longer input sequences inhibited performance.
Why it matters: Standardized comparisons not only help application developers choose the right model for their needs, they also provide a deeper understanding of a model’s performance characteristics and spur researchers to improve the state of the art.
We’re thinking: You can get involved, too. The team open sourced its work and encourages others to contribute to the Long-Range Arena leaderboard.
Data Science Is Full of Newbies
Machine learning is spreading from big corporations to smaller companies, and many of its practitioners are relatively new to the technology.
What’s new: Almost one in five data scientists active on Kaggle, which hosts machine learning competitions, have been in the field less than one year, according to the company’s latest State of Data Science and Machine Learning survey. The report covers demographics and employment as well as popular platforms, frameworks, applications, and techniques. The data includes answers from 200,000 people.
What they found: The report tallies responses by 2,675 Kaggle users who identified themselves as employed data scientists.
- A majority of the respondents had less than three years of machine learning experience, and 18 percent had been in the field less than one year.
- 37 percent worked at businesses with fewer than 50 employees, a 7 percent rise over last year’s survey. 51 percent worked on teams of fewer than five people.
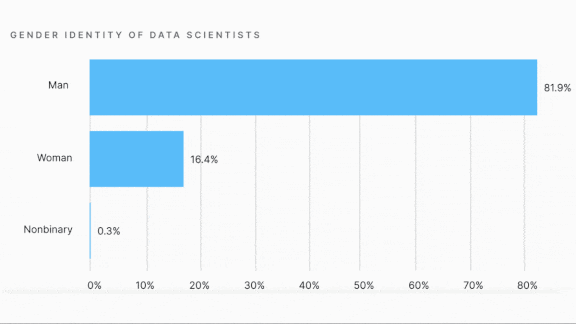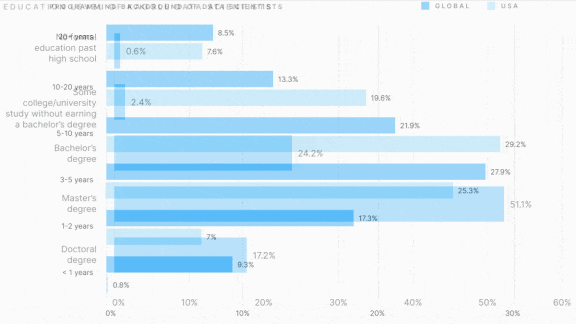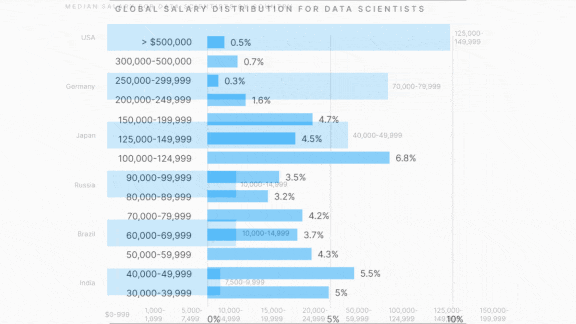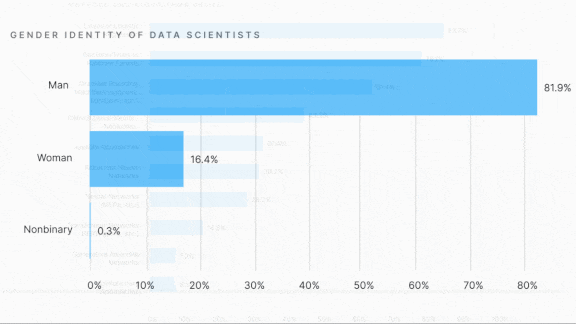
- 81.9 percent of respondents identifed as male.
- Most respondents were in India, making up 21.8 percent of the total. 14.5 percent were in the U.S., and 4.6 percent in Brazil.
- The U.S. is by far the most lucrative place to be a data scientist, as 73 percent of U.S. respondents said they made over $100,000. In India, the median salary range was between $7,500 and $10,000.
Behind the news: Users of the employment site Glassdoor consistently rank data scientist as one of America’s best jobs, citing good pay and working conditions. But just because workers are happy doesn’t mean they’re sitting still. About a third of the engineers who responded to Anaconda’s 2020 State of Data Science survey said they plan to look for a new job in the coming year. The expected turnover is highest in IT, where 44 percent of data scientists either are actively looking for new employment or plan to do so soon.
Why it matters: This survey underlines how data science is diffusing, not only among businesses but among nations. It highlights trends that hiring managers, among others, should bear in mind, including the field’s ongoing gender imbalance.
We’re thinking: All those newcomers to data science represent a huge pool of fresh ideas and new talent coming in to the field.