
Dear friends,
Over the last several decades, driven by a multitude of benchmarks, supervised learning algorithms have become really good at achieving high accuracy on test datasets. As valuable as this is, unfortunately maximizing average test set accuracy isn’t always enough.
I’ve heard too many conversations like this:
Machine learning engineer: It did well on the test set!
Product manager: But it doesn’t work for my application.
Machine learning engineer: But . . . It did well on the test set!
What else is there?
Robustness and generalization: In a production deployment, performance can degrade due to concept drift (where the function mapping from x->y changes; say, the model predicts housing prices y and inflation causes prices to rise) and data drift (where the input distribution changes). One important subset of data drift relates to performance on classes that are rare in or absent from the training set. For example, a speech recognition system may achieve high average accuracy despite poor performance on speakers with a British accent, because the training and test sets included few examples of British speakers. If the product takes off in the U.K. and a lot more British speakers jump in, its accuracy will plummet. A more robust system would fare better.

Performance on relatively important examples: Some examples are more important than others, and even if average test set accuracy is high, a system that performs poorly on important examples may be unacceptable. For example, users might forgive a search engine that doesn’t always return the best results to informational and transactional queries like “apple pie recipe” or “wireless data plan.” But when they enter a navigational query such as “stanford,” “youtube,” or “reddit,” they have a specific website in mind, and the search engine had better return the right URL or risk losing the user’s trust. In theory, weighting test examples according to their importance can address this issue, but it doesn’t always work in practice.
Performance on key slices of data: Say a machine learning system predicts whether a prospective borrower will repay a loan, so as to decide whether to approve applications. Even if average accuracy is high, if the system is disproportionately inaccurate on applications by a specific minority group, we would be foolhardy to blindly deploy it. While the need to avoid bias toward particular groups of people is widely discussed, this issue applies in contexts beyond fairness to individuals. For example, if an ecommerce site recommends products, we wouldn’t want it to recommend products from large sellers exclusively and never products from small sellers. In this example, poor performance on important slices of the data — such as one ethnicity or one class of seller — can make a system unacceptable despite high average accuracy.
My advice: If a product manager tells us that our AI system doesn’t work in their application, let’s recognize that our job isn’t only to achieve high average test accuracy — our job is to solve the problem at hand. To achieve this, we may need visualizations, larger datasets, more robust algorithms, performance audits, deployment processes like human-in-the-loop, and other tools.
Keep learning!
Andrew
News

Eyes On Drivers
Amazon is monitoring its delivery drivers with in-vehicle cameras that alert supervisors to dangerous behavior.
What’s new: The online retail giant rolled out a ceiling-mounted surveillance system that flags drivers who, say, read texts, fail to use seatbelts, exceed the speed limit, or ignore a stop sign, CNBC reported.
How it works: The system, Netradyne Driveri, uses street-facing and in-cab cameras along with an accelerometer and gyroscope to spot 16 unsafe behaviors.
- When it detects an offending behavior, the system warns the driver and automatically uploads a video to Amazon.
- Drivers can upload videos manually to document potentially problematic events such as a person approaching the vehicle or an inaccessible delivery location.
- Netradyne said its system reduces collisions by two thirds, according to The Verge.
Yes, but: Some Amazon drivers said that the system violates their privacy and exacerbates pressure to meet the company’s aggressive delivery schedules.
Behind the news: Amazon has expanded its force of local delivery drivers to more than 400,000 as of November. It has used a similar computer vision system from SmartDrive to monitor its long-haul truckers for sleepiness and distraction. Delivery competitor United Parcel Service also has tested a system, Lytx DriveCam, that monitors drivers of its delivery vans.
Why it matters: Investigations by BuzzFeed and the The New York Times charge that Amazon pressures drivers to make deliveries at a dangerously fast clip, resulting in numerous accidents and several deaths. While in-car surveillance is intrusive, proponents point out that it might help reduce human errors that can occur when people are under stress.
We’re thinking: There are many ways that AI can enhance productivity and safety. Let’s make sure to do it in a way that’s empowering rather than dehumanizing.
Better Language Through Vision
For children, associating a word with a picture that illustrates it helps them learn the word’s meaning. New research aims to do something similar for machine learning models.
What’s new: Hao Tan and Mohit Bansal at University of North Carolina Chapel Hill improved a BERT model’s performance on some language tasks by training it on a large dataset of image-word pairs, which they call visualized tokens, or vokens.
Key insight: Images can illuminate word meanings, but current datasets that associate images with words have a small vocabulary relative to the corpuses typically used to train language models. However, these smaller datasets can be used to train a model to find correspondences between words and images. Then that model can find such pairings in separate, much larger datasets of images and words. The resulting pairings can help an established language model understand words better.
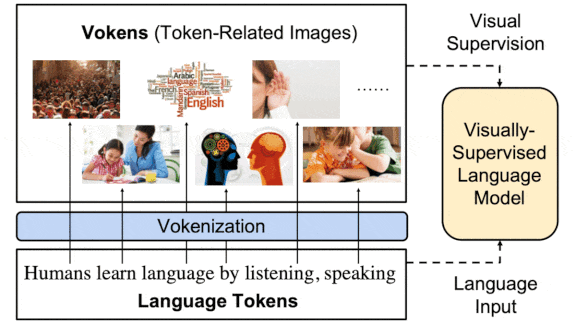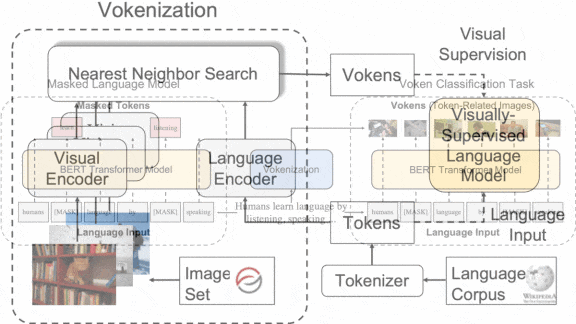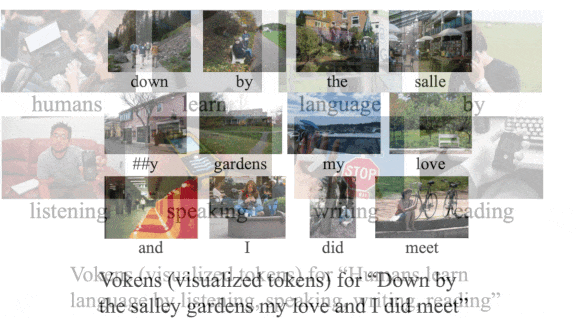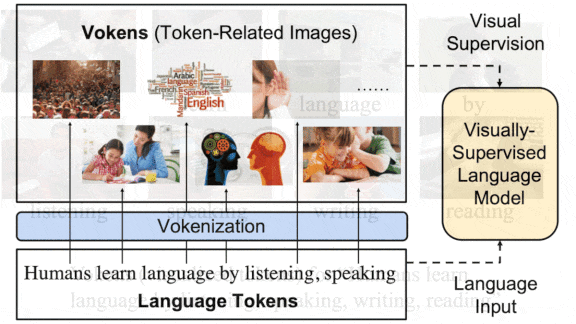
How it works: The authors trained a system called the vokenizer to pair BERT-style tokens — generally individual words or characters — with related images. They used the resulting visualized tokens to train BERT to predict such pairings and fine-tuned it on various language tasks.
- The vokenizer comprised a pretrained ResNeXt-101 vision model and a pretrained BERT, each followed by a two-layer neural network that generated representations separately for input images and tokens. To train it, the authors split COCO, which depicts roughly dozens of object types with captions, into token-image pairs, associating an image with every token in a given caption. They trained the vokenizer to predict pairings by encouraging it to make the distance between pairs of images and tokens larger than the distance between unpaired images and tokens.
- To create a large number of token-image pairs, the vokenizer paired images in the Visual Genome, which depicts millions of objects, with words from English Wikipedia. First it generated a representation for each image. Then, for each token, it used a nearest neighbor search to find the image whose representation was closest.
- Using a separate BERT with an extra fully-connected layer, the authors removed some tokens from Wikipedia sentences at random. They pretrained the model to predict both the missing tokens and the image paired with each token. Then they fine-tuned the model on GLUE (which includes several language understanding tasks), SQuAD (question answering), and SWAG (language reasoning).
Results: BERT pretrained with the token-image pairs outperformed the same architecture trained in the same way but without the pairs on tasks in GLUE, SQuAD, and SWAG. For instance, it achieved 92.2 percent accuracy on SST2, predicting the sentiment of movie reviews, compared to 89.3 percent for BERT without visual training. Similarly, on SQuAD v1.1, it achieved an F1 score of .867 on SQuAD compared to .853 for BERT without visual training.
Why it matters: This work suggests the potential of visual learning to improve even best language models.
We’re thinking: If associating words with images helps a model learn word meaning, why not sounds? Sonic tokens — sokens! — would pair, say, “horn” with the tone of a trumpet and “cat” with the sound of a meow.

Fairness East and West
Western governments and institutions struggling to formulate principles of algorithmic fairness tend to focus on issues like race and gender. A new study of AI in India found a different set of key issues.
What’s new: Researchers at Google interviewed dozens of activists, academic experts, and legal authorities about the ways AI is deployed in India, especially with respect to marginalized groups. In part, their goal was to demonstrate how Western notions of bias and power don’t always apply directly to other cultures.
What they found: The report highlights three ways in which issues surrounding AI in India differ from Western countries and may call for different approaches to achieve fairness.
- Dataset bias: Half the Indian population lacks access to the internet — especially women and rural residents — so datasets compiled from online sources often exclude large swathes of society. Fixing the problem goes beyond data engineering. It requires a comprehensive approach that includes bringing marginalized communities into the digital realm.
- Civil rights: Many Indian citizens are subjected to intrusive AI, unwillingly or unwittingly. For example, some cities use AI to track the operational efficiency of sanitation workers, many of whom come from lower-caste groups. To address perceived abuses, Westerners typically appeal to courts, journalists, or activists. Many Indians, though, perceive such avenues to be largely unavailable.
- Technocracy: India is eager to modernize, which motivates politicians and journalists to embrace AI initiatives uncritically. Compared with Western countries, fewer people in positions of power are qualified to assess such initiatives — a prerequisite to making their fairness a priority.
Behind the news: Other groups have sought to highlight the outsized influence that Western notions of ethics have on AI worldwide.
- The IEEE Standards Association recently investigated how applying Buddhist, Ubuntu, and Shinto-inspired ethics could improve responsible AI.
- A 2019 study looked at how responsible AI guidelines should accommodate the massive influx of people who are newly online, many of whom live in countries like Brazil, India, and Nigeria.
- A report published last year examined the social implications of AI in China and Korea.
Why it matters: Most research into AI fairness comes from a U.S.-centric perspective rooted in laws such as the Civil Rights Act of 1964, which outlaws discrimination based on race, sex, and religion. Guidelines based on a single country’s experience are bound to fall short elsewhere and may even be harmful.
We’re thinking: Many former colonies struggle with legal and educational systems imposed by Western powers. It’s important to avoid repeating similar patterns with AI systems.
A MESSAGE FROM DEEPLEARNING.AI

Level up your AI career with our new event series, AI Access! Join us for “Integrating Design and Technical Innovation in AI-First Products” with Patrick Hebron, director of Adobe’s Machine Intelligence Design group. Patrick will offer a sneak peek at ways AI will transform creative tools and workflows. RSVP
Shortcut to Cancer Treatment
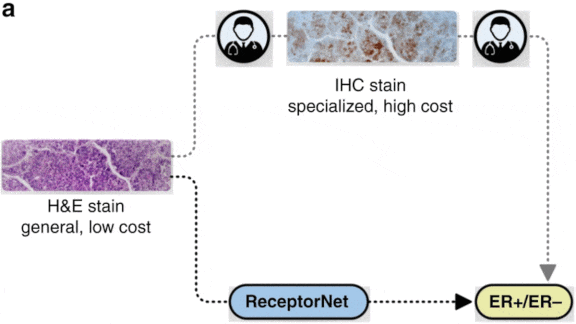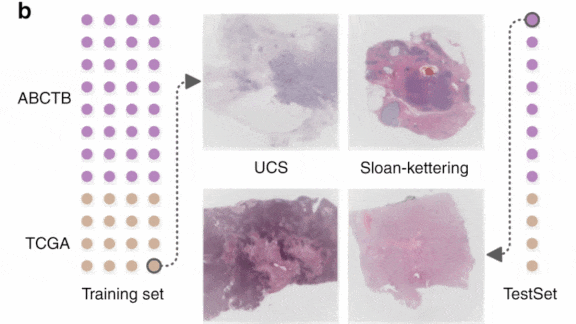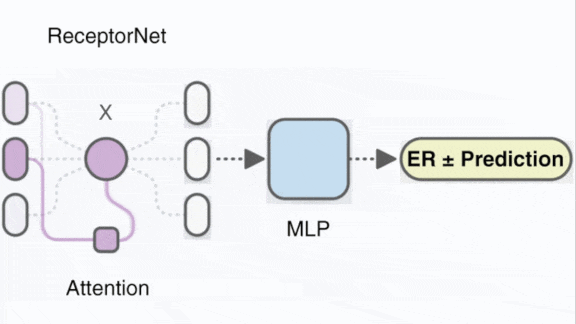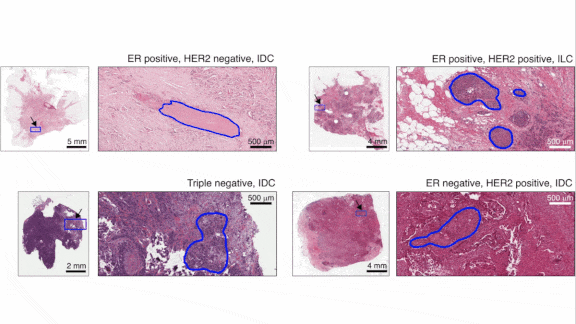
Doctors who treat breast cancer typically use a quick, inexpensive tumor-tissue stain test to diagnose the illness and a slower, more costly one to determine treatment. A new neural network could help doctors to go straight from diagnosis to treatment.
What’s new: The stain in the test for treatment highlights a key visual clue to the choice of therapy that’s otherwise invisible to human pathologists. Nikhil Naik at Salesforce and colleagues at University of Southern California built ReceptorNet to detect that clue in the diagnostic test.
Key insight: The presence of estrogen receptor proteins is a sign that hormone therapy may work. In the diagnostic test, known as hematoxylin and eosin (H&E), these proteins are invisible to the human eye. An attention mechanism, which identifies the most important parts of an input (in this case, a portion of an H&E slide) in determining the output (a label that the proteins are present), can aggregate image areas where they occur so a vision network can classify the slide.
How it works: ReceptorNet comprises a ResNet-50 pretrained on ImageNet followed by an attention layer and a fully connected layer. The researchers trained and tested ReceptorNet on images of H&E slides, and augmentations of them, in the Australian Breast Cancer Tissue Bank and The Cancer Genome Atlas datasets.
- The authors isolated the images’ foreground using Otsu’s method, which distinguishes foreground from background based on variance in each pixel’s grayscale value, to remove background regions. They magnified the foregrounds 20 times and divided them into tiles of 256×256 pixels.
- During training, they fed ReceptorNet 50 randomly sampled tiles per slide. The ResNet extracted representations of each tile and passed them en masse to the attention layer, which weighted their importance. The fully connected layer used the weighted representations to classify slides according to whether they contain estrogen receptors.
- To combat overfitting, the authors used mean pixel regularization, randomly replacing 75 percent of tiles with a single-color image of the dataset’s mean pixel value.
Results: ReceptorNet achieved an area under the curve of 0.92 AUC, a measure of true versus false positives where 1 is a perfect score. The authors experimented with alternatives to the attention layer that didn’t perform as well, which suggests that attention was key.
Yes, but: The authors had access only to H&E images, so they couldn’t compare ReceptorNet’s performance against the test that’s typically used to guide treatment.
Why it matters: ReceptorNet had a label for each tissue slide but not for each tile derived from it. The success of attention in aggregating and evaluating the representations extracted from each tile bodes well for this approach in reading medical images.
We’re thinking: Where else could computer vision augment or replace slow, expensive medical tests?
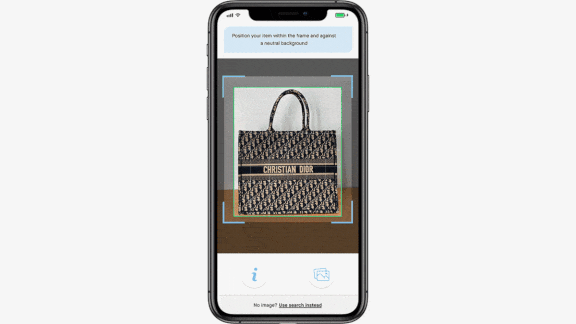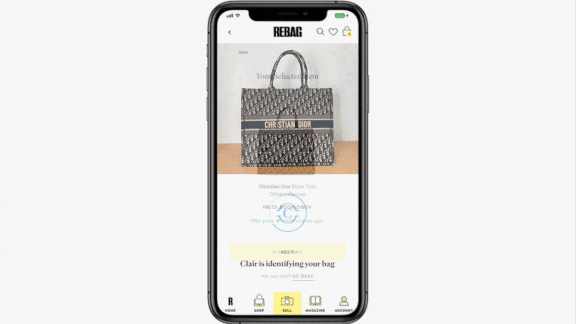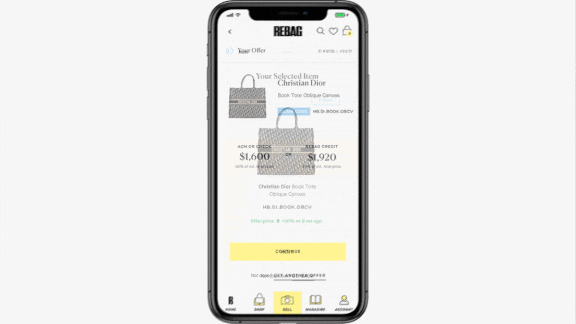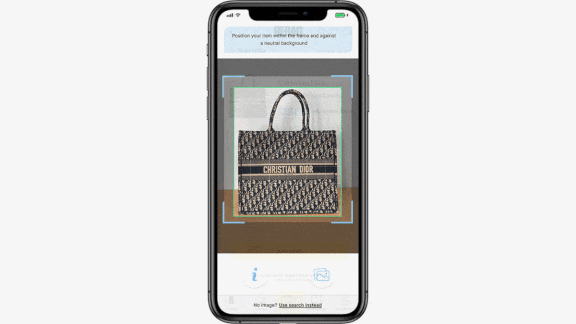
How Much For That Vintage Gucci?
Computer vision is helping people resell their used designer handbags.
What’s new: Rebag, a resale company for luxury handbags, watches, and jewelry, launched Clair AI, an app that automatically appraises second-hand bags from brands like Gucci, Hermes, and Prada, Vogue reported.
How it works: Users take a close-up picture of a handbag against a neutral background. The app finds between one and five potential matches for designer, model, and style.
- Users choose the potential match that comes closest and adds details about the used bag’s condition and color. The system then calculates dollar figures for retail price and trade-in value.
- Users can also submit photos of bags in magazines, videos, or other fashionista’s hands to find out what other people are carrying.
- Rebag’s CEO said in a promotional video that the app achieved 90 percent accuracy rate and took six years and millions of data points to develop.
Behind the news: Rebag’s revenue grew by 50 percent in 2020, riding a surge in demand for second-hand luxury goods. The market for used high-end items like watches, jewelry, fine art, and yachts grew in 2019 by 12 percent to $26.5 billion.
Why it matters: Consumers are mindful of the resale value of high-ticket goods. An app that makes it easier to tap into that market could drive sales of both new and used items — and make it easy to unload the hideous thing that somehow looked fetching last summer.
We’re thinking: We tested this system on the bags in our closet, but it wasn’t impressed by our prized NeurIPS tote.