
Dear friends,
AI researchers keep coming up with impressive innovations: transformer-based language models, self-supervised learning, deep reinforcement learning, small data. All of these developments hold great promise. But some will continue to improve over time and set new directions for AI, and others will turn out to have less impact.
How can you tell which is which?
I remember seeing early data, over a decade ago, that indicated deep learning algorithms could scale up to become very useful. Similarly, I remember thinking that sequence-to-sequence models, when they were first presented and not yet working well, set a new direction. In these instances, my instincts turned out to be right. But I’ve been wrong, too. For example, in the mid-2000s, I thought that mobile manipulation would take off faster than it has so far.
I’ve thought about how to evaluate whether an exciting idea that doesn’t yet work well is likely to become a winner or whether it’s unlikely to improve much for a long time. Over the past decade, three major drivers of improvement in AI performance have been:
- Computational scaling: Does running an algorithm on computers 10 or 100 times faster result in better performance?
- Data scaling: Does feeding an AI system more data improve its performance?
- Algorithmic improvements: Does the data available still hold a significant amount of information that current algorithms do not extract?

I believe these three factors will continue to drive AI performance for years to come. Thus, nascent ideas that can take advantage of them seem more promising to me. If the “only” thing a new algorithm requires to be useful is a 10x improvement in computation speed, you have Nvidia, Intel, and AMD working hard to make that improvement, so it’s a good bet that it will happen.
This reasoning leads me to believe that GPT-3 is setting a new direction for building language models and applications. I see a clear path toward scaling computation (by making models cheaper to run or building bigger ones) and algorithmic improvements. At AI Fund (where I’m managing general partner), we’re seeing many entrepreneurs looking to build new companies using GPT-3.
On the other hand, I don’t expect quantum computing to have a dramatic impact on AI any time soon. I look forward to quantum AI and I’m glad that many groups are investing in it. But it doesn’t appear to ride any of the three drivers above, and I believe it will take a significant amount of time to become practical for machine learning.
Regarding algorithmic improvements, it’s important to note that the information must be in the data for an algorithm to extract it. If someone’s DNA doesn’t contain enough information to determine whether that person will develop diabetes, then no amount of algorithmic work will yield the ability to predict the disease from only the genetic sequence. If humans can perform a task, that’s strong evidence that the data available to humans holds information helpful for completing that task — and that points to the possibility that algorithmic improvements can enable AI to complete it, too.
This is why I believe that small data is a promising area: A handful of pictures contains sufficient information for a human to learn to recognize a new object. This offers hope that improved algorithms will be able to extract that information and learn from far fewer examples than are required today.
When you hear about an exciting category of emerging AI technology, you might ask yourself whether it can ride on the backs of computational scaling, data scaling, and algorithmic improvement. If so, it’s more likely to make a big impact in the future. We can create immense value if we can get better at recognizing new ideas that, although they may not yet work well today, have potential to become tomorrow’s top performers.
Keep learning!
Andrew
News

AI Chip Leaders Join Forces
A major corporate acquisition could reshape the hardware that makes AI tick.
What’s new: U.S. processor giant Nvidia, the world’s leading vendor of the graphics processing units (GPUs) that perform calculations for deep learning, struck a deal to purchase UK chip designer Arm for $40 billion. The transaction faces regulatory approvals and other hurdles, but if it’s completed, it will be the biggest-ever acquisition in the chip industry and one of the biggest technology deals.
Deal drivers: Nvidia’s technology undergirds much of the cloud infrastructure for AI workloads, while Arm’s technology drives inference in 95 percent of smartphones.
- Nvidia said it plans to integrate Arm’s energy-efficient designs with its data center chips.
- It also aims to use the technology to spur the internet of things, a buzzword for devices like smart thermostats, doorbells, speakers, and industrial equipment that are expected to distribute intelligence throughout buildings and infrastructure.
- Nvidia CEO Jensen Huang envisions trillions of AI-equipped devices enabling everything from autonomous heavy machinery to walk-through retail checkout.
- Huang also plans to extend Arm’s licensing practices, which let any company lease its designs, to Nvidia’s GPUs and AI services.
Behind the news: Nvidia developed GPUs to process high-resolution video game graphics in 1999. Nearly a decade later researchers realized their potential for training deep learning models. Since then, the company’s value has multiplied tenfold.
Why it matters: By combining Arm’s energy efficiency with its growing presence in the cloud, Nvidia chips may be able to drive coming generations of multi-trillion parameter models.
Yes, but: Mergers are difficult to pull off, and international tie-ups of this scale especially so. Whether Nvidia can take full advantage of its new possession may remain unclear for a long time. Meanwhile, Arm co-founder Hermann Hauser is urging UK authorities to block the deal on the grounds that it would put Nvidia on the road to monopolizing the chip industry.
We’re thinking: Data centers increasingly require both CPUs to process traditional workloads and GPUs to process deep learning (with help from a CPU). Data center operators would appreciate a vendor that can supply CPUs and GPUs that interoperate smoothly. That’s one reason why CPU producers like Intel and AMD are expanding into GPUs, and why Nvidia wants to buy Arm.
More Efficient Transformers
As transformer networks move to the fore in applications from language to vision, the time it takes them to crunch longer sequences becomes a more pressing issue. A new method lightens the computational load using sparse attention.
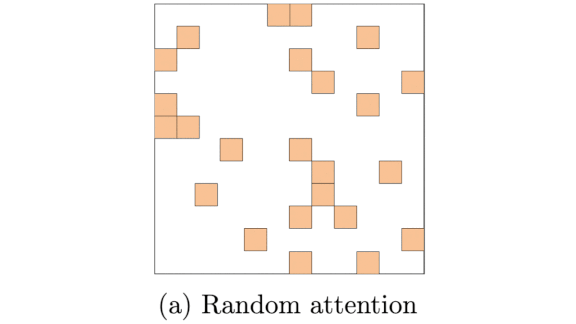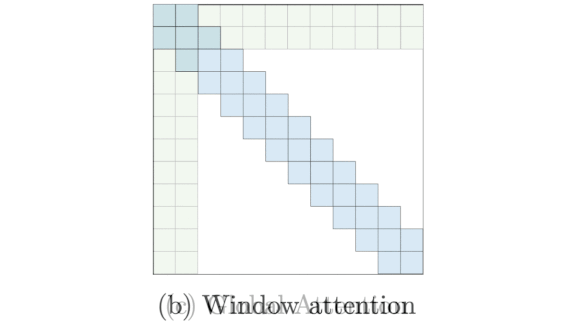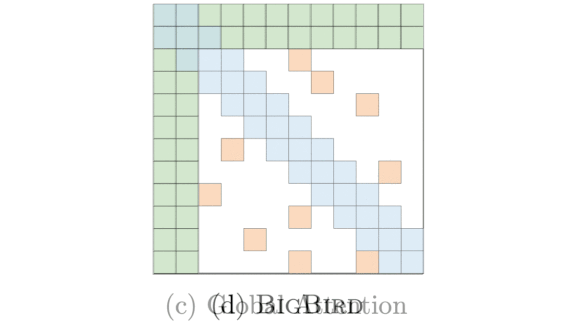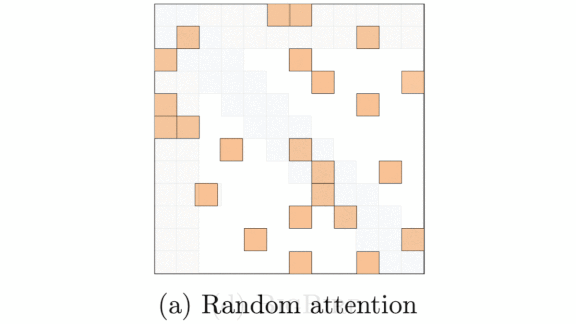
What’s new: BigBird, an attention mechanism developed by a Google team led by Manzil Zaheer and Guru Guruganesh, enables transformers to process long sequences more efficiently. Their work follows a similar effort using an entirely different method, linear attention.
Key insight: Recent research showed that transformers are Turing-complete, meaning they can learn to compute any algorithm, and universal approximators, meaning they can learn nearly any sequence-to-sequence function. The authors focused on approaches to accelerating transformers that maintain these two theoretical properties.
How it works: The basic transformer’s multiheaded self-attention mechanism compares every pair of tokens in an input sequence, so the amount of computation required grows quadratically with sequence length. Where linear attention would shrink the computation budget by reformulating the problem using the kernel trick, BigBird combines three sparse attention mechanisms that keep the number of comparisons constant: window attention, global attention, and random attention.
- Window attention compares only nearby tokens. This is important because nearby tokens affect one another.
- Global attention compares a constant number of tokens to every other token. Across multiple layers, it offers an indirect way to consider how every token relates to every other token, even though all tokens aren’t compared directly.
- Random attention compares a randomly selected number of tokens. This prevents a transformer from missing important details that windowed and global attention don’t cover, according to graph theory.
- This combination makes BigBird Turing-complete and a universal approximator.
Results: A model equipped with BigBird processed text sequences eight times longer than a RoBerta baseline while using 16GB of memory. A Longformer model designed for long sequences required 48GB and half the batch size to process the same sequence length. Longer sequences enabled BigBird to achieve masked language modeling (MLM) score, in which lower numbers indicate a better prediction of words missing from text, of 1.274 MLM compared with the Roberta baseline’s 1.469 MLM. BigBird also outperformed RoBerta on Natural Questions, HotpotQA, TriviaQA, and WikiHop.
Yes, but: To achieve such results, BigBird required more hyperparameter fine-tuning and architecture search than typical self-attention.
Why it matters: The ability to process longer sequences efficiently points toward faster training, lower memory requirements, higher benchmark scores, and potentially new applications that require keeping track of book-length sequences. The benefits of Turing completeness and universal approximation are theoretical for now, but BigBird ensures that they won’t fall by the wayside.
We’re thinking: The paper is 50 pages long. Now maybe transformer models, at least, can read it in one sitting.

YouTube vs. Conspiracy Theorists
Facing a tsunami of user-generated disinformation, YouTube is scrambling to stop its recommendation algorithm from promoting videos that spread potentially dangerous falsehoods.
What’s new: The streaming giant developed a classifier to spot conspiracy theories, medical misinformation, and other content that may cause public harm. Wired detailed the effort.
How it works: In a bid to boost total viewership to one billion hours each day, YouTube years ago tweaked its recommendation algorithm to favor videos that racked up high engagement metrics such as long watch times and lots of comments. Those changes inadvertently rewarded videos that express extreme, inflammatory, and often misleading perspectives. Since then, the company has largely automated recognition and deletion of videos that promote violence or are deemed pornographic, which violate its rules. But potentially harmful clips that don’t break those rules, like conspiracy theories, posed a tougher challenge.
- Reviewers watched videos and answered a questionnaire that asked whether they contained various types of offensive or borderline content including conspiracy theories, urban legends, or contradictions to scientific consensus. Doctors reviewed the facts in videos with medical content.
- YouTube’s engineers turned the answers into labels, and used the dataset to train a classifier. The model learned to recognize problematic clips based on features including titles, comments, and videos viewed before or after.
- Given a new video, the classifier assigns a score that represents how extreme it is. The recommendation algorithm then adds this score to other weights when deciding whether to include the video in a given user’s queue.
- The system reduced overall watch time of conspiracy videos and similar content by 70 percent last year, the company said.
Behind the news: YouTube’s recommendation algorithm has a problematic history.
- In 2019, researchers found that it recommended videos of children wearing swimsuits to users who had just viewed sexually suggestive content about adults.
- Last September, a trio of YouTubers demonstrated that the company’s system wouldn’t sell advertising in non-explicit videos with words like gay or lesbian in the title, thus depriving their creators of revenue.
- After the U.S. Justice Department released the findings of its investigation into President Trump’s alleged collusion with Russia during his election campaign, former YouTube engineer Guillaume Chaslot found that the site’s recommendation algorithm favored videos about the investigation from Russia Today, a news site funded by the Russian government.
Why it matters: YouTube is the world’s biggest video streaming service by far, and the titles it recommends inform — or misinform — millions of people.
We’re thinking: There’s danger in any company taking on the role of arbiter of truth and social benefit, but that doesn’t mean it shouldn’t moderate the content it delivers. As the world faces multiple crises from Covid-19 to climate change, it’s more important than ever for major internet companies to stanch the flow of bad information.
A MESSAGE FROM DEEPLEARNING.AI

You’re invited! Join Ian Goodfellow, Animashree Anandkumar, Alexi Efros, Sharon Zhou, and Andrew Ng for GANs for Good, a virtual expert panel to celebrate the launch of our new GANs Specialization. September 30, 10:00 a.m. to 11:30 a.m. Pacific Daylight Time. Sign up now
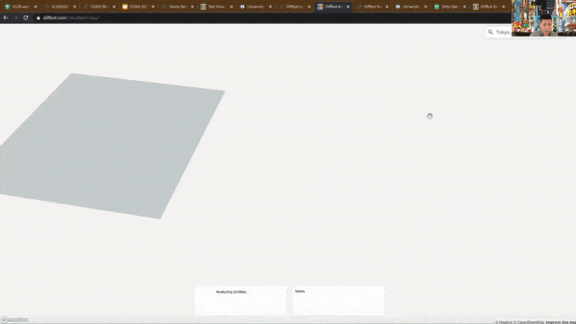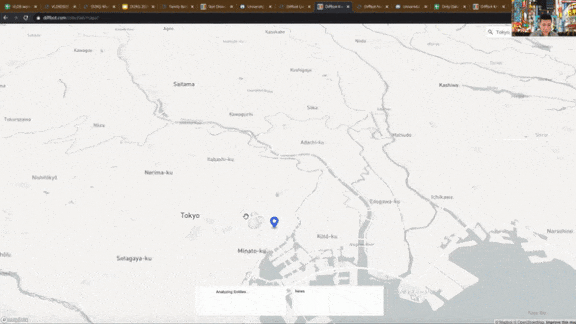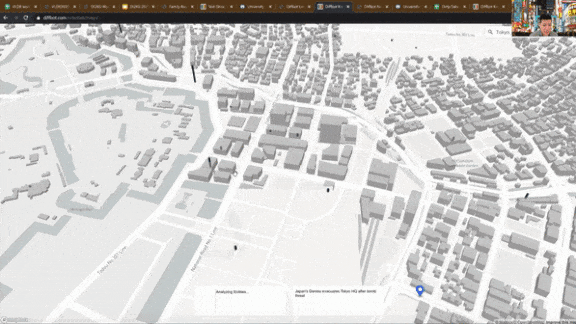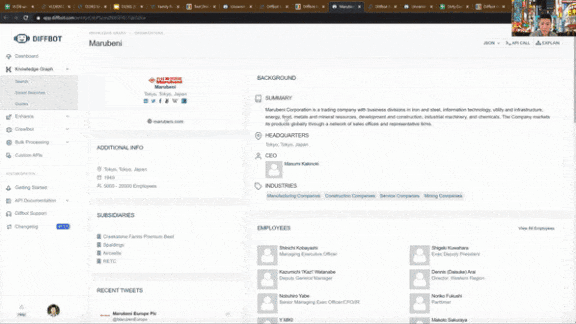
The Internet in a Knowledge Graph
An ambitious company is using deep learning to extract and find associations from all the information on the internet — and it isn’t Google.
What’s new: Diffbot, a Stanford offshoot founded in 2008, built a system that reads web code, parses text, classifies images, and assembles them into what it says is the world’s largest knowledge graph, according to MIT Technology Review.
How it works: Diffbot’s web crawler rebuilds the graph every four to five days, adding roughly 150 million new subject-object-verb associations monthly. The graph encompasses more than 10 billion entities — people, businesses, products, locations, and so on — and a trillion bits of information about those entities.
- The company uses image recognition to classify content into 20 categories such as news, discussion, and images.
- It analyzes any text to find statements made up of a subject, verb, and object and stores their relationships. Its knowledge graph has captured subject-verb-object associations from 98 percent of the internet in nearly 50 languages. The image recognition tool also picks up implicit associations such as that between a product and its price.
- A suite of machine learning techniques including knowledge fusion (which weighs the trustworthiness of various sources) associates new information and overwrites outdated information, the Diffbot founder and CEO Mike Tung told The Batch.
- The company’s customers can sift the graph using a query language, point-and-click interface, or geographic map (as shown above). The system automatically corrects misspellings and other inconsistencies.
Behind the news: Over 400 companies including Adidas, Nasdaq, and SnapChat use Diffbot’s technology to understand their customers and competition, and to train their own models. Researchers can apply for free access.
Why it matters: A knowledge graph that encompasses the entire internet could reveal a wealth of obscure connections between people, places, and things. This tool could also be useful for machine learning engineers who aim to train models that have a good grasp of facts.
We’re thinking: Knowledge graphs have proven to be powerful tools for companies such as Google and Microsoft, but they’ve received little attention in academia relative to their practical impact. Tools to automatically build large knowledge graphs will help more teams reap their benefits.
Guess What Happens Next
New research teaches robots to anticipate what’s coming rather than focusing on what’s right in front of them.
What’s new: Santhosh K. Ramakrishnan and colleagues at Facebook and University of Texas at Austin developed Occupancy Anticipation (OA), a navigation system that predicts unseen obstacles in addition to observing those in its field of view. For instance, seeing the corner of a bed, the model evaluates whether a clear path around the bed is likely to exist. The system won the Habitat 2020 PointNav Challenge, which tests a robot’s ability to navigate a complex environment autonomously using only sensory input.
Key insight: The PointNav Challenge supplies a robot with an indoor destination (such as, “two meters west and four north”) often blocked by unknown obstacles, like furniture, outside the line of sight. Knowledge of these obstacles would enable the robot to generate an efficient route to the destination. The next-best thing is predicting their presence.
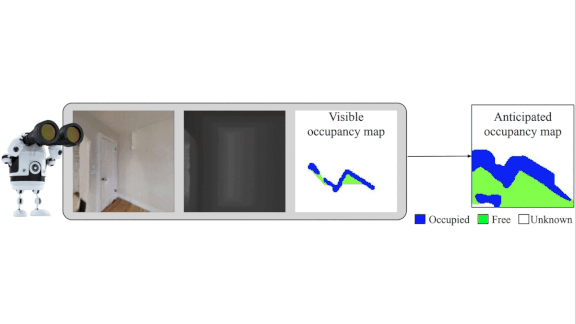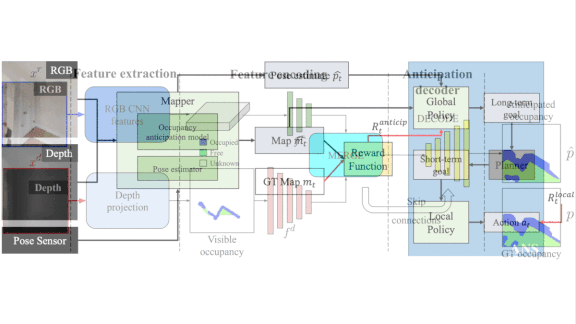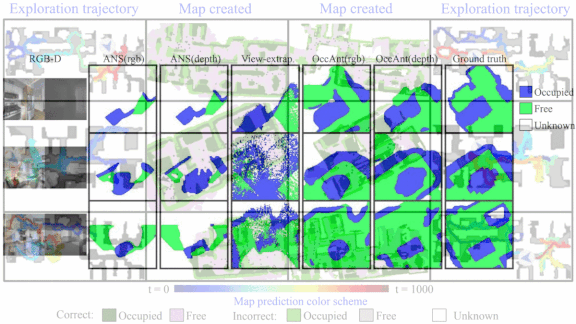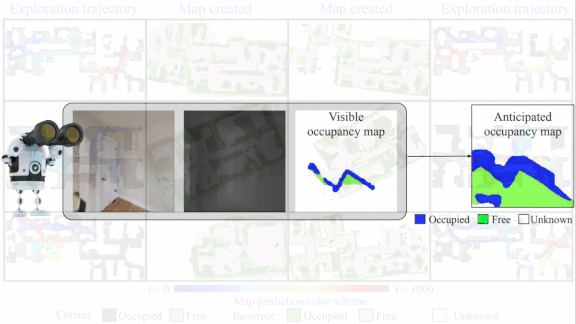
How it works: OA receives inputs from the robot’s depth sensor, front-facing camera, and state (its position and whether its wheels are turned and moving). It learns to minimize the distance and length of path to the destination. The system incorporates a version of Active Neural Slam (ANS), which won last year’s PointNav Challenge, modified to let OA take advantage of its predictive capabilities.
- Based on input from the depth sensor, an image processing network draws an aerial map of known obstacles. A U-Net extracts features from the map and camera image to predict whether an unseen obstacle lies out of view. For instance, a wall’s edges may be out of view, but the model can estimate, based on past experience, how far away the next door or corner is likely to be.
- On its own, ANS would search for the shortest path to the destination by exploring intermediate locations that help the robot view more of the environment, but OA prefers intermediate locations that help the system predict hidden obstacles. This strategy can decrease the amount of exploration necessary. For instance, if the robot can predict the table’s edges, it doesn’t need to circle the table to confirm that it doesn’t hide a shortcut that goes through it.
- Once OA chooses an intermediate location, it drives the robot there collecting known obstacles along the way. It repeats the process until the robot reaches its destination.
Results: The PointNav Challenge ranks methods according to the metric known as success weighted by path length (SPL), which takes a value between 0 and 1, higher being better. SPL measures the average success rate but penalizes successes resulting from longer paths. OA achieved 0.21 SPL to wallop the second-place ego-localization, which achieved 0.15 SPL.
Why it matters: Reinforcement learning agents must balance exploration and sticking to a known method. Exploration can reveal shortcuts, but they can also waste time. OA offers an elegant solution, since an agent can bypass areas where it predicts unseen obstacles.
We’re thinking: The way Nova drops toys around the Ng residence, even PointNav champs wouldn’t stand a chance.
A MESSAGE FROM DEEPLEARNING.AI

We’re thrilled to announce the launch of Course 4 of our Natural Language Processing Specialization on Coursera! Enroll now