
Dear friends,
Did you ever spend days obsessing over a technical problem? If so, I applaud you. Determined pursuit of solutions to hard problems is an important step toward building deep expertise.
I’ve been privileged to have worked with several of today’s AI leaders when they were still students. Every one of them spent days, weeks, and months relentlessly trying out different approaches to a range of problems, coming up with hypotheses and performing experiments to hone their intuition. This gave them a thorough understanding of machine learning.
It takes many judgement calls to build an effective AI system. How do you tune a particular hyperparameter? What are the tradeoffs between model size, real-time throughput, and accuracy for an application? What type of data pre-processing will yield the best results? When facing complex questions, engineers with deep expertise will come up with better answers.

Lately I’ve been thinking about how to train neural networks on small amounts of data. I try to find quiet time to brainstorm, and sometimes I end up with many pages of handwritten notes. After I’ve obsessed over a problem during the day, before I fall asleep I remind my brain that I want to make progress on it. Then, if I’m lucky, I awaken in the morning with new ideas.
The world is complex and becoming more so. We need people, in AI and other disciplines, who will take the time and effort to build deep expertise. When a worthy problem taps you on the shoulder, I encourage you to give it your attention. Give yourself the time you need to explore a solutions, and keep at it. It’s not a weird thing to do. Even if you don’t succeed — as a student, I spent countless hours trying, and failing, to prove P ≠ NP, and I don’t regret a minute of it — the journey will make you better.
Keep learning!
Andrew
News

Deep Learning Is in the Air
An aviation startups is using neural networks to put air freight on autopilot.
What’s new: Xwing, a California startup, is test-flying an autonomous pilot system aboard cargo aircraft with an eye toward crewless commercial flights in 2022, the Wall Street Journal reported.
How it works: A suite of models reads sensor data while the plane is in motion. When the models detect another plane or an obstacle, they funnel the information to a rules-based flight control system, which adjusts course, Xwing CEO Marc Piette told The Batch.
- The company installed its system aboard a fleet of Cessna Grand Caravans modified with extra sensors and computing power. These propeller-driven planes typically carry around 3,300 pounds of freight over relatively short distances.
- Sensors mounted on the aircraft include electro-optical and infrared cameras, radar, lidar, and GPS. Some sensors capture annotated data; for example, radar labels other aircraft. This allows automated annotation of camera images, enabling the company to generate large datasets quickly and save on manual annotation.
- Human pilots sit in the cockpit as emergency backups. Xwing hopes to make the system fully autonomous with oversight by people on the ground, who can take control if necessary.
Behind the news: Several companies are racing toward regulatory approval for autonomous freight transport, including Amazon, which this week gained permission to deliver packages using drones. The remaining issues are not technical. Commercial airliners routinely fly on autopilot, and last year a Cessna outfitted with an AI-powered autopilot from Reliable Robotics performed the first autonomous take-off, flight, and landing over an urban area. However, regulations and public concerns have kept human pilots in cockpits. Xwing and its proponents believe that restriction may lift before long, starting with approval for flights over water or uninhabited areas. The company’s reliance on existing aircraft may help expedite the process.
Why it matters: Small planes move cargo between outlying areas and central hubs. Autonomous systems could make service faster, more frequent, and less costly.
We’re thinking: Air, land, or sea: Where will fully autonomous vehicles first enjoy widespread deployment?
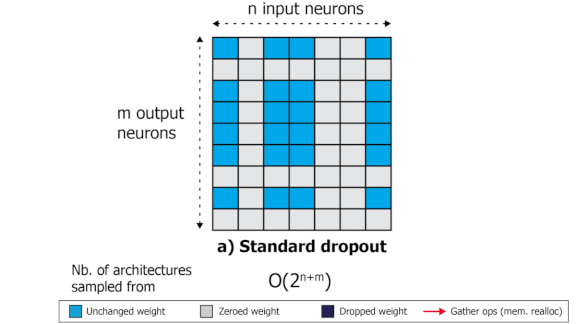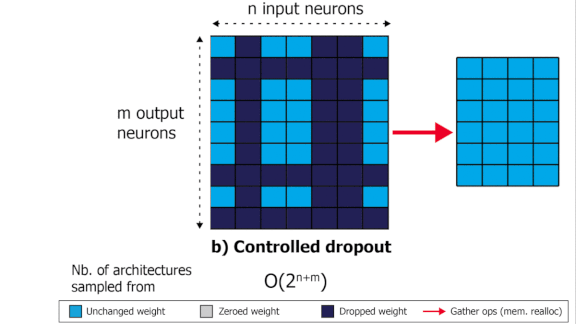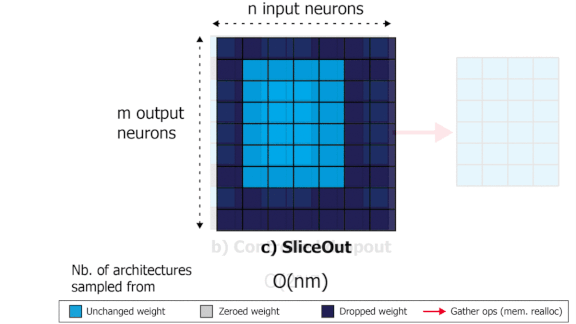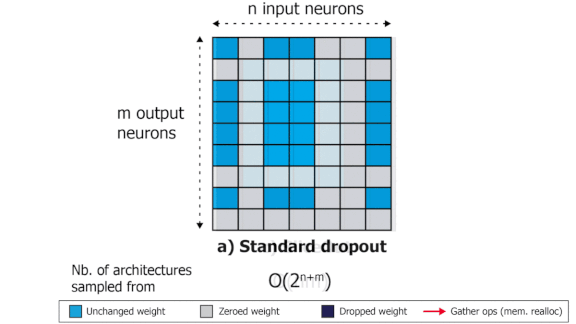
Dropout With a Difference
The technique known as dropout discourages neural networks from overfitting by deterring them from reliance on particular features. A new approach reorganizes the process to run efficiently on the chips that typically run neural network calculations.
What’s new: Pascal Notin and colleagues at Oxford and Cohere.ai introduced an alternative, SliceOut, that boosts neural network speed with little or no compromise to accuracy.
Key insight: Most operations in deep learning consist of multiplying a matrix of weights by a vector of activations or features. Deleting an input feature means a row of the weight matrix has no effect. Similarly, deleting an output feature means a column has no effect. But the resulting matrix forces the chip that’s processing the calculations to shuttle data in and out of memory, which takes time. By deleting — and keeping — only features that are contiguous in memory, the authors avoided time-consuming memory reallocations.
How it works: In its simplest form, dropout zeroes out a random selection of parameter values or, equivalently, by zeroing out the corresponding weights.
- Controlled dropout saves some processing power by collecting the remaining non-zero weights into a new, smaller weight matrix — but that still requires reallocating memory.
- SliceOut selects contiguous portions of the matrix and zeroes out everything else. This scheme is massively more efficient.
- By analyzing how GPUs compute convolutional and transformer layers, the authors developed SliceOut variants for those layers as well.
Results: The researchers evaluated SliceOut in an image-recognition task using CNNs trained on CIFAR-100, SliceOut matched dropout’s test accuracy but ran trained 33.3 percent faster and required 27.8 percent less memory. SliceOut achieved time savings of 8.4 percent and memory savings of 9 percent with transformer networks on the One Billion Word Benchmark and saved double-digit percentages in fully connected layers on MNIST.
Why it matters: Larger networks often achieve better results in a variety of tasks, but they require regularization techniques to avoid overfitting. SliceOut could enable gargantuan models to run faster than dropout allows without a hardware upgrade.
We’re thinking: As the organizers of Pie & AI, we’ll always try to make sure there’s a slice for you.

Wimbledon in a Box
Covid shut down the tennis tournament at Wimbledon this year, but a new model simulates showdowns between the sport’s greatest players.
What’s new: Stanford researchers Kayvon Fatahalian and Maneesh Agrawala developed Vid2Player, a system that simulates the footwork, positioning, and strokes of tennis pros like Roger Federer, Serena Williams, and Novak Djokovic. Users choose players and, if they want, control their location and stroke at the beginning of each shot cycle, creating a realistic match.
How it works: Vid2Player has three main parts: a behavioral model for each player, a clip search, and a renderer.
- The authors extracted sprites, or two-dimensional bitmap graphics, that represent various players from an annotated dataset of matches recorded at Wimbledon in 2018 and 2019. They used Mask R-CNN to find every pixel in each video frame that corresponds to the player and his or her racket. Then Deep Image Matting turned the pixels into sprites. Additional preprocessing made the sprites more consistent.
- Rather than control the players manually, users can leave it to the behavioral models. These models are made up of kernel density estimators, a type of non-parametric model similar to a histogram.
- The clip search finds a video segment that best matches the selected movements and shots. The rendering module paints the appropriate sprite onto a virtual tennis court.
- Vid2Player continues to generate player motions until one player makes a mistake or fails to return the ball.
Realistic rallies: Five tennis experts who evaluated Vid2Player said it produced more realistic action than previous efforts. Similar systems like Tennis Real Play and Vid2Game draw from video databases to simulate on-court action under user control. However, they don’t search for clips that most closely match what a player would do in a given situation.
Why it matters: Apart from filling the hole in this year’s tennis season, simulations like this could allow fans to create never-before-seen matchups like Federer versus Williams. Or our favorite: Federer vs. Federer. (Federer won.)
We’re thinking: We’re in love-love with this model!
A MESSAGE FROM DEEPLEARNING.AI
Course 4 of the Natural Language Processing Specialization is launching this month! Make sure to complete Courses 1 through 3!

U.S. Proposes National AI Centers
The White House called for new funding for AI research including a constellation of research centers. Nonetheless, the U.S. government’s annual spending on the technology still would lag behind that of several other nations.
What’s new: The 2021 U.S. budget proposal includes $180 million to establish seven new artificial intelligence research institutes funded through the National Science Foundation, Department of Agriculture, and other agencies. Private-sector partners including Dell, Facebook, and Netflix would contribute another $300 million. The proposal awaits approval by Congress.
Focused research: The new institutes target both basic research and industrial applications:
- The Institute for Foundations in Machine Learning at the University of Texas would seek to push the state of the art in machine learning.
- MIT would host an institute that applies AI to vexing problems in physics.
- The Institute for Research on Trustworthy AI in Weather, Climate, and Coastal Oceanography at the University of Oklahoma would focus on predicting extreme weather, mapping the ocean, and conserving natural resources.
- The University of Illinois would run two institutes, one using machine learning to discover new materials and medicines, the second focused on applying computer vision, machine learning, and robotics to agriculture.
- UC Davis would start an institute to study how AI can improve food security.
- The University of Colorado would launch an institute to explore how AI can help teach middle and high school students.
Behind the news: The White House has said it would boost AI spending by $2 billion in the next two years. The 2020 U.S. budget allocated around $850 million to nonmilitary spending on AI research and $4 billion to military AI spending. Other nations match or exceed these figures:
- The European Union plans to spend €1.5 billion (roughly $1.8 billion) in machine learning research between 2018 and 2020. That’s in addition to efforts by member states like France, which aims to spend the same amount by 2022.
- The EU is also pushing for combined private and public sector AI funding of €20 billion (nearly $24 billion) annually.
- The Chinese government spends between ¥13.5 billion (around $2 billion) and ¥57.5 billion (roughly $8.5 billion) annually on military and civilian AI research, according to a 2019 study by Georgetown University.
- By 2022, South Korea expects to spend ₩2.2 trillion (around $1.8 billion) to build out the country’s AI research infrastructure and train AI professionals.
Yes, but: American tech giants are pouring billions more into AI. A 2018 study estimated that the top 10 tech companies, all based in the U.S., have spent a combined $8.6 billion acquiring AI startups since 1998, and some spend lavishly on research.
Why it matters: The U.S. government sees itself in an arms race for dominance in AI. It has a head start, thanks mostly to the country’s strong private tech sector. However, a recent report concluded that spending must reach $25 billion annually to keep up with perceived rivals.
We’re thinking: Early funding for deep learning from the National Science Foundation and Defense Advanced Research Projects Agency (Darpa) was critical in establishing the technology. The last thing the world needs is another arms race, but — at a time when U.S. government funds for research have been flat — we’d like to see AI get more public support.
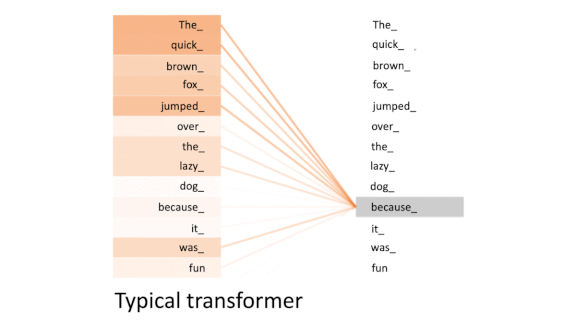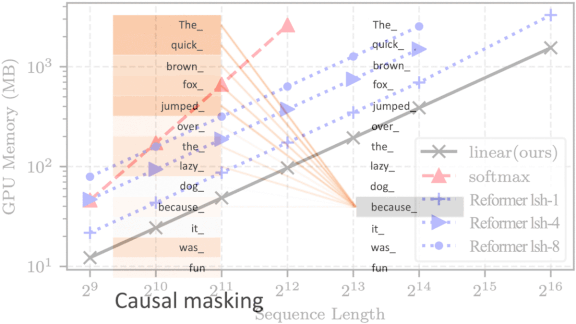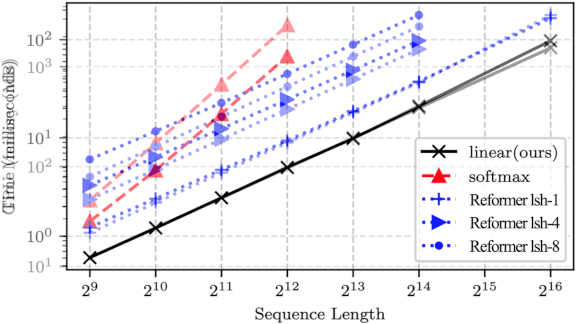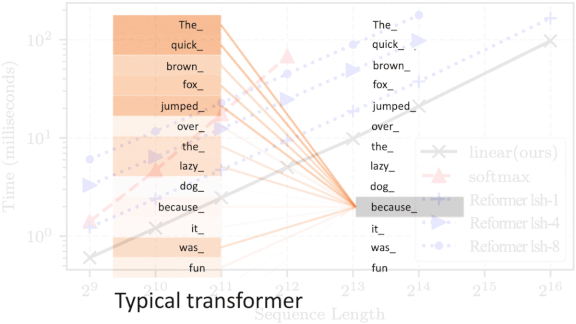
The Transformation Continues
Transformer networks are gaining popularity as a high-accuracy alternative to recurrent neural networks. But they can run slowly when they’re applied to long sequences. New research converts transformers into functional RNNs for a major speed boost.
What’s new: Angelos Katharopoulos and colleagues at Idiap Research Institute, École Polytechnique Fédérale de Lausanne and University of Washington accelerated transformers nearly a thousand-fold by outfitting them with linear attention.
Key insight: Researchers have used transformers instead of RNNs to analyze sequences, primarily sequences of words but also sequences of pixels. However, the number of calculations performed by the straightforward implementation of a transformer rises quadratically as sequence length increases, while calculations performed by RNNs rise linearly. The authors modified a transformer to act like an RNN’s hidden state. This modification, along with a clever speedup, allows the transformer’s computations to scale linearly with sequence length.
How it works: Transformers extract features that capture the relationship between elements in the sequence. These features depend on comparisons between a single token to every other token in the sequence.
- The authors noticed that similarities among tokens could be reformulated as a dot product in an alternative feature space (a technique known as the kernel trick).
- The kernel trick enables linear attention to combine intermediate calculations into a single matrix that’s shared among all feature comparisons. The matrix’s size remains constant regardless of the number of tokens in the sequence, which avoids the quadratic slowdown.
- To mimic an RNN, the researchers compared the latest input token only to earlier tokens rather than all tokens in a sequence. This technique, called causal masking, lets the transformer reuse the matrix in consecutive time steps instead of recomputing the entire layer as usual. Thus the matrix acts like the hidden state of an RNN.
Results: Linear attention generated synthetic MNIST images over 400 times faster than Reformer, the pace-setting transformer in this task. And it was more accurate, too. In speech recognition on the WSJ dataset, linear attention achieved a lower error rate (8 percent) compared to both Reformer (9.3 percent) and a bi-LSTM (10.9 percent).
Why it matters: This work demonstrated advantages over typical transformers without incurring any apparent costs. It remains to be seen whether these benefits extend to all situations.
We’re thinking: Estimates of the cost of training gargantuan transformer-based language models run to millions of dollars. It sure would be nice to trim those budgets by a few orders of magnitude.