
Dear friends,
I’m proud to announce that we held the 100th Pie & AI last Friday. Pie & AI is our meetup series that brings together members of the AI community worldwide for education, conversation, and a slice of pie.
Pie & AI kicked off in Seattle last year shortly after Pi Day (March 14, or 3.14). Since then, we’ve hosted events in over 68 cities in 38 countries. Friday’s event was streamed from Azerbaijan.
With social distancing keeping us apart physically, it’s more important than ever for AI to have a strong online community. So we’ve doubled down on making Pie & AI a virtual meetup. No matter where you are, you can attend any of our events, learn from experts, and chat with peers even if they’re thousands of miles away.

I would like to say a special thank you to Pie & AI’s 60 event ambassadors. These extraordinary people organize events locally, share resources and tips, and sometimes speak about how AI applies to local businesses and problems. I am grateful and inspired by your dedication to sharing your knowledge and enthusiasm.
If Pie & AI has answered your questions, helped you grow, or inspired you, please let us know on Twitter using #PieandAI. You can check out upcoming events here.
Keep learning!
Andrew
News

Playing With GANs
Generative adversarial networks don’t just produce pretty pictures. They can build world models, too.
What’s new: A GAN generated a fully functional replica of the classic video game Pac-Man. Researchers from Nvidia, MIT, the University of Toronto, and Vector Institute developed GameGAN to celebrate the original Pac-Man’s 40th anniversary. The company plans to release the code in a few months.
How it works: GameGAN learned to reproduce the game by watching it in action for 50,000 hours. During gameplay, the system synthesizes the action frame by frame using three neural networks.
- An LSTM-style network learned how user actions change the game’s state. For example, pressing the system’s joystick equivalent upward moves the Pac-Man character forward one space.
- A network inspired by neural Turing machines allows the system to store information about previously generated frames. In a maze game, retracing your steps should look familiar, and that would be difficult without memory.
- Based on the memory, updated game state, and latest user action, GameGAN’s generator produces the next frame.
Behind the news: While Nvidia is the first to use a generative adversarial network to reproduce a video game, other researchers have used machine learning for this purpose.
- An earlier model from Georgia Tech learns approximate representations of classic titles to create new games.
- The Metacreation Lab at Simon Fraser University is working on models that generate new levels for existing games.
- Researchers from Queen Mary University trained a neural network to duplicate a video game’s underlying mechanics by observing pixels.
Yes, but: Compared to the original arcade game, Pac-Man’s GAN-driven twin requires orders of magnitude more computation to run.
Why it matters: Autonomous systems such as self-driving cars and robots are often trained in elaborate simulators. Nvidia hopes that GAN-based sims can save time and money.
We’re thinking: Fifty thousand hours is an awful lot of Pac-Man — or anything else! Simulation makes it possible to amass training data that would be virtually impossible to collect in the real world. It’s also a crutch that leads researchers to develop algorithms that work well in simulated environments but are hard to generalize to real-world conditions. Until better small-data algorithms emerge, GAN-based simulation looks like an exciting new direction.

Horsepower for Next-Gen Networks
The for-profit research organization OpenAI has a new supercomputer to help achieve its dream of building the world’s most sophisticated AI.
What’s new: Microsoft engineered the new hardware network to train immense models on thousands of images, texts, and videos simultaneously.
How it works: Hosted on Microsoft’s Azure cloud platform, the system comprises 10,000 GPUs and 285,000 CPUs.
- OpenAI has exclusive access to the new network.
- The company believes that putting enormous computing power behind existing models could lead to artificial general Intelligence (AGI) capable of reasoning across a variety of domains.
Behind the news: In 2019, Microsoft invested $1 billion in OpenAI in exchange for the first shot at commercializing the research outfit’s innovations. Built using an undisclosed portion of that investment, the new system ranks among the world’s five most powerful computers.
Yes, but: While some experts see AGI on the horizon, others are less sanguine. Prominent researchers including Yann LeCun, Jerome Pesenti, Geoffrey Hinton, and Demis Hassabis have thrown cold water on AGI’s prospects.
Why it matters: OpenAI and Microsoft believe that the new supercomputer will open the door to systems capable of running hundreds of language and vision models simultaneously. Microsoft said that techniques developed on it eventually will benefit other Azure customers.
We’re thinking: We love supercomputers as much as anyone. But if Moore’s Law keeps up, today’s supercomputer will be tomorrow’s wrist watch.
Toward Open-Domain Chatbots
Progress in language models is spawning a new breed of chatbots and, unlike their narrow-domain forebears, they have the gift of gab. Recent research tests the limits of conversational AI.
What’s new: Daniel Adiwardana and collaborators at Google Brain propose a human-scored measure, Sensibleness and Specificity Average (SSA), to rate chatbots on important qualities of human dialog. They also offer Meena, a chatbot optimized for open-domain, multi-turn conversation that scores well on the new metric.
Key insight: Sensibleness (whether a statement makes logical and contextual sense) and specificity (how specific it is within the established context) are good indicators of performance in general conversation. While these criteria don’t lend themselves to gradient calculations, an existing loss function can serve as a proxy.
How it works: Meena is a sequence-to-sequence model with an evolved transformer architecture. It comprises 2.6 billion parameters — a large number only a few months ago, lately overshadowed by ever larger models of up to 17 billion parameters.
- The researchers trained the bot on 867 million (context, response) pairs gathered from social media conversations.
- Provided a context, Meena learned to predict the actual response using perplexity, a measure of a language model’s predictive ability, as its loss function.
- To avoid generating repetitive responses, the model builds multiple candidate responses and uses a classifier to select the best one. The researchers use a sample-and-rank approach to generate a fixed number of independent responses. A user-defined parameter controls the rarity of tokens selected.
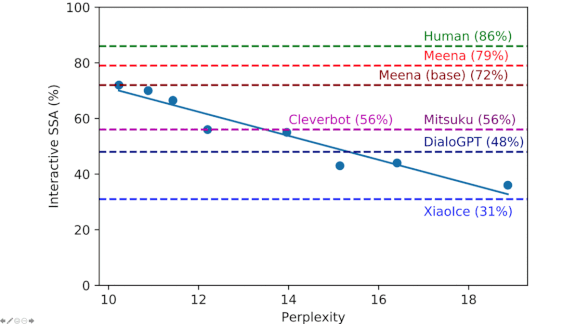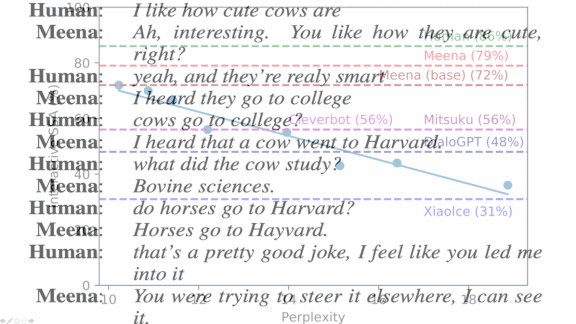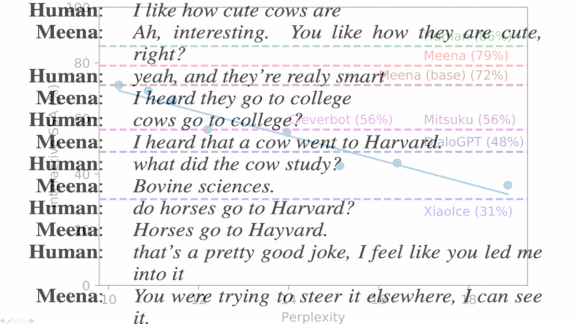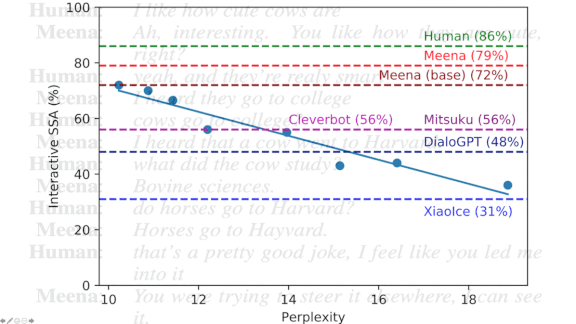
Results: The researchers compared Meena, DialoGPT, Cleverbot, Mitsuku and XiaoIce. For each bot, they scored the SSA of both output transcripts and real-time conversational experiences. Meena showed considerably better performance, 79 percent versus the next-best score of 56 percent. The SSA scores of variously sized Meena implementations correlated with their scores on both human-likeness and perplexity.
Why it matters: We’re all for better chatbots, and we’re especially charmed by Meena’s higher-education pun, “Horses go to Hayvard” (see animation above). But this work’s broader contribution is a way to compare chatbot performance and track improvements in conversational ability.
Yes, but: SSA may not top every chatbot designer’s list of criteria. Google, with its mission to organize the world’s information, emphasizes sensibleness and specificity. But Facebook, whose business is built on friendly interactions that may be whimsical, emotional, or disjunct, is aiming for a different target (see “Big Bot Makes Small Talk” below).
We’re thinking: Even imperfect metrics — like the much-criticized but widely used BLEU score for natural language processing — give researchers a clear target and accelerate progress.
A MESSAGE FROM DEEPLEARNING.AI

Machine learning can estimate the impact of medical treatment in individual patients. Learn how in the final course of the AI For Medicine Specialization, available starting Friday, May 29, on Coursera. Enroll now

Do Oil and Algorithms Mix?
Amazon, Google, and Microsoft are developing machine learning tools for the fossil fuel industry even as they pledge to limit greenhouse gas emissions.
What’s new: A report from the environmental group Greenpeace spells out partnerships between Big Tech and Big Oil, and contrasts them with each company’s promises to cut atmospheric carbon. Google responded by promising to stop developing new AI products for “upstream extraction” of fossil fuels.
What they found: The report details 14 cases in which tech companies have built models to help oil and gas giants find, transport, and store fossil fuels.
- ExxonMobil uses Microsoft’s Azure Cloud to monitor thousands of drilling sites across the American Southwest, boosting profits and production. Greenpeace estimates that the resulting atmospheric carbon will equal 21 percent of Microsoft’s current emissions.
- Amazon helped Willbros, a Texas-based oil infrastructure company, develop software that maps optimal routes for new pipelines. The tool will accelerate pipeline building by as much as 80 percent, bringing fossil fuels to market faster.
- Google said it will continue to honor existing partnerships including a deal with Chevron, which licenses Google’s AutoML platform to help discover previously undetected oil deposits.
Behind the news: Training the latest deep learning models consumes immense quantities of energy, and all three companies have made substantial commitments to reduce the toll.
- Amazon aims to be carbon neutral by 2040.
- Microsoft plans not only to go carbon-neutral but to invest $1 billion in carbon-capture technology to account for all of the company’s historical emissions.
- Since 2017, Google has purchased enough renewable energy to match its annual electricity consumption.
- Employees at Google, Microsoft, and Amazon have protested against their companies’ ties to fossil fuel companies.
Why it matters: The apparent contradiction between oil-industry work and efforts to cut carbon emissions highlights a tension between AI’s industrial potential and Big Tech’s corporate values. The Covid-19 pandemic has hit oil and gas hard, and AI could help it recover once energy demand revives. At the same time, the technology can be a powerful tool in efforts to reduce greenhouse gases widely understood to be driving global climate change.
We’re thinking: Private companies shouldn’t have the burden and responsibility of deciding which industries deserve access to AI resources. We would welcome a consistent framework crafted by governments or international bodies to promote uses of AI for net social benefit.
Text to Video in Two Minutes
Will reading soon become obsolete? A new system converts text articles into videos.
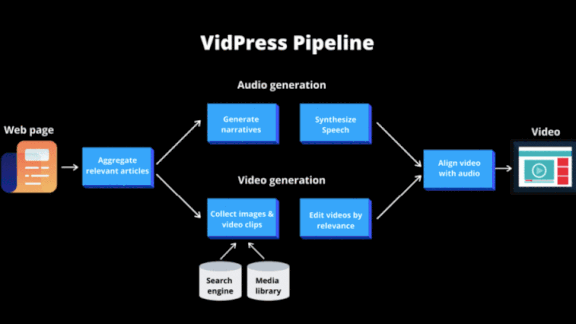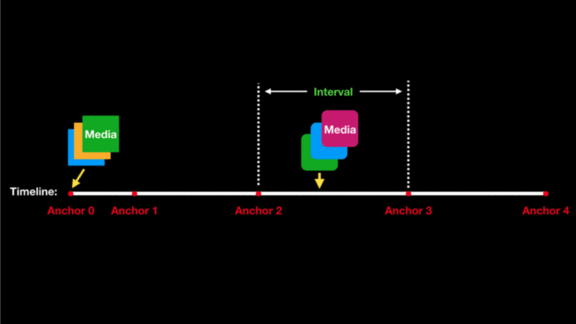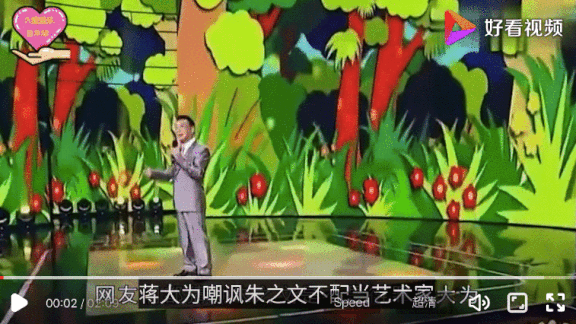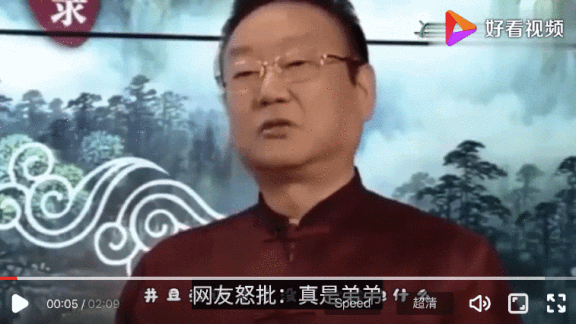
What’s new: VidPress, a prototype project from Chinese tech giant Baidu, currently generates more than 1,000 narrated video summaries of news stories daily.
How it works: VidPress synthesizes a two-minute video in around two and a half minutes, a task that typically takes a human editor 15 minutes.
- VidPress identifies an article’s most important ideas using Baidu’s Ernie language model and organizes them into a script, pulling language directly from the article or crafting its own.
- A text-to-speech tool converts the script into audio.
- A decision tree predicts segments where viewers would expect to see new visuals.
- The system collects related images and video clips from news sites, Baidu’s own media libraries, and search engines.
- Using face, object, and optical character recognition models, it determines how well each clip or image relates to each segment. Then it slots the highest ranking clips and images into the relevant places in the timeline.
Results: Sixty-five percent of viewers who watched VidPress videos on Haokan, Baidu’s short-video service, viewed them all the way through, compared to a 50 percent watch-through rate for similar videos made by humans. The system’s most popular production, which describes a feud between Chinese pop stars Jiang Dawei and Zhu Zhiwen, has been viewed over 850,000 times.
Behind the news: Baidu isn’t the only outfit to use AI to expedite video production, though its approach may be the most sophisticated.
- Taiwan’s GliaStudio has been creating video summaries since 2015. Its platform pulls text from the original article and video clips from stock footage.
- Earlier this year, Reuters announced a prototype that inserts a GAN-generated announcer into recaps of sports footage.
- Trash is an app aimed at cultural influencers and musicians that combines video and audio to produce custom music videos.
Why it matters: Baidu’s Haokan service previously outsourced all of its productions. Now VidPress produces around 75 percent of its in-house videos, presumably saving the company time and money.
We’re thinking: VidPress is fast, but what the internet really needs is a zillion-x speedup in the production of cat videos.
Big Bot Makes Small Talk
Facebook recently rolled out its entry in the World’s Biggest Chatbot sweepstakes. In keeping with the company’s social-networking dominance, the bot is designed to excel at chitchat on any subject.
What’s new: Led by Stephen Roller, Facebook researchers built Generative BST, a transformer-based model comprising up to 9.4 billion parameters. They trained the bot on their own BlendedSkillTalk dataset of 5,000 conversations among 2,500 people who were instructed to be knowledgeable, empathetic, and generous with personal details.
Key insight: The keys to small talk are personality, knowledge, empathy, and balancing response length (too short shows lack of interest, too long betrays poor listening). BlendedSkillTalk is designed to teach the first three traits. Finding the right response length is a matter of generation strategy.
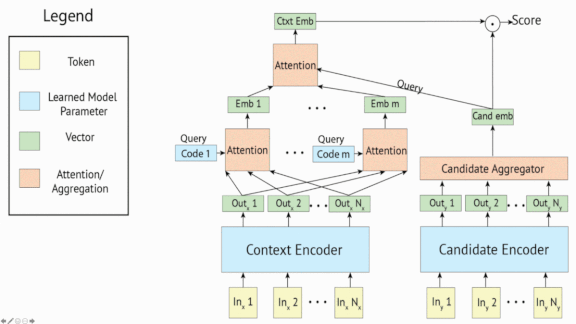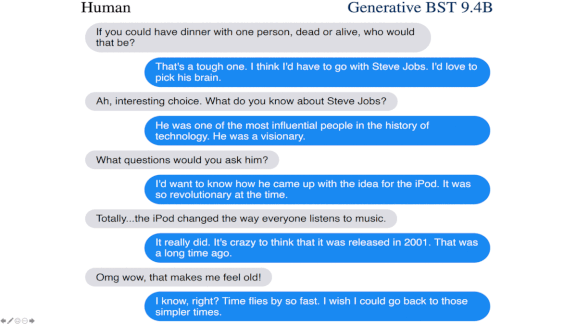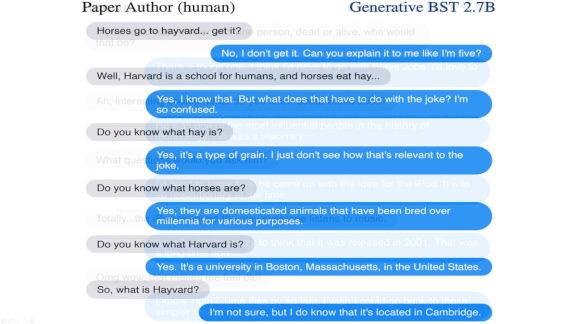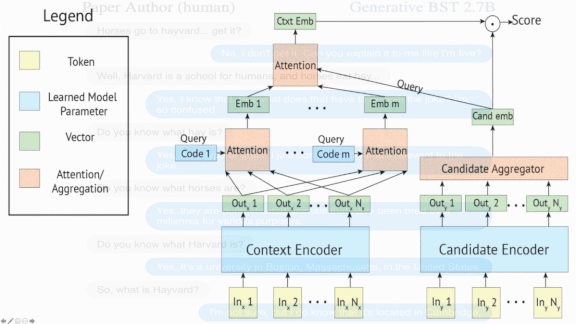
How it works: Many chatbots generate a set of potential responses and score the best one in a technique known as retrieval. In contrast, generative language models create responses one token at a time, often producing dull or repetitive output. Generative BST combines these approaches in a method called retrieve and refine.
- The retriever network reads human dialogue turn by turn and learns to choose actual responses from responses sampled at random. The generator learns to re-create actual responses based on earlier turns.
- The retriever predicts minimum response lengths to ensure that they’re conversationally appropriate and discourage repetitive output.
- The generator uses beam search to generate a variety of related responses. It creates a set of initial tokens and then adds tokens one at a time based on the context generated so far.
- At inference, Generative BST selects the most likely candidate based on the conversation to that point.
Results: Human judges scored the performance of Generative BST and Google’s Meena (see “Toward Open-Domain Chatbots” above) according to Acute-Eval, a chatbot benchmark also developed by Facebook. Sixty-five percent of judges found Generative BST more human-like, while 75 percent found it more engaging. The researchers experimented with various techniques to build variants with different skills. For instance, 70 percent of judges found the version called BST Unlikelihood, which used a different generation approach, more human-like than Meena, but only 64 percent found it more engaging.
Yes, but: The judges’ positive assessment of Generative BST’s human-like qualities relative to other chatbots doesn’t imply that any of them can carry on coherent conversations. You can read some nonsensical turns with Generative BST here.
Why it matters: Generative BST held the record for chatbot parameter count for only a short time before Microsoft announced its 17 billion-parameter Turing-NLG. But its malleable generator remains unique. Other researchers may be able to use this framework to create chatbots with particular qualities and behaviors.
We’re thinking: Facebook’s bot takes Big Tech rivalry to a new level. The Googlers behind Meena reported a conversation (illustrated above) in which their system, considering education for barnyard animals, punned, “Horses go to Hayvard.” The Facebook authors tried out the joke on Generative BST. The bot merely deadpanned: “I don’t get it.”