
Dear friends,
I recently received an email from one of you who lives far from the major AI hubs, saying, “I feel like I’m all alone.”
I want to tell you all: Even if it sometimes feels like you’re facing the challenges of work and life in isolation, you are not alone! I am here for you, and all of us are in this together. Most software engineers are working from home and connecting digitally with colleagues, mentors, and friends. In this time of social distancing, the AI community has the potential to come out even stronger and more tightly knit.

There are many ways to regain a feeling of connection with your peers. I invite you to join our virtual Pie & AI events. Read and reply on a Coursera forum, or discuss your ideas on Reddit or Twitter. Send a message to a favorite researcher asking questions about their work. Poke around open source projects to see what you can contribute.
Some of my teams are split across the U.S. and Colombia. Ironically, sheltering in place has brought them closer, because now it’s exactly as convenient for a U.S. team member to communicate with one in Columbia as one in the U.S. The playing field has leveled.
Let’s all keep finding ways to connect and help each other through this time.
Keep learning!
Andrew
News

New Behaviors Derail Old Training
The pandemic has radically altered online shopping behavior, throwing a wrench into many AI systems.
What’s new: AI inventory trackers, recommendation algorithms, and fraud detection systems trained on pre-pandemic consumer behavior have been flummoxed by the wildly different ways people now browse, binge, and buy, according to MIT Technology Review.
What’s happening: Companies are scrambling to retrain machine learning systems for the new normal.
- Amazon’s recommender typically promotes items the company itself can ship. With its distribution network under strain, the algorithm seems to be promoting products from sellers who handle their own shipments.
- Featurespace, which provides fraud detection technology for financial and insurance companies, revamped its behavior models to account for surges in demand for things like power tools and gardening supplies. Such spikes used to trigger alerts. Now they’re business as usual.
- AI consulting firm Pactera Edge says an upswing in bulk orders broke a client’s predictive inventory systems. Another client found its public-sentiment analysis software distorted by all the gloomy news.
- Phrasee, a company that generates ad copy using natural language processing, tweaked its algorithm to avoid phrases that could spark panic (“going viral”), raise anxiety (“stock up!”), or promote risky behavior (“party wear”).
Behind the news: E-commerce is one of the pandemic’s few beneficiaries: Growth in online sales in April tripled over the same month last year, according to an analysis by electronic payments processor ACI Worldwide.
Why it matters: Beyond its terrible human toll, Covid-19 is making yesterday’s data obsolete. The AI community must find ways to build resilient systems that can adjust as conditions change.
We’re thinking: In our letter of April 29, we pointed out that AI often suffers from a gap between proofs of concept and practical deployments because machine learning systems aren’t good at generalizing when the underlying data distribution changes. Covid-19 is bringing about such changes on a grand scale, and our systems are showing their brittleness. The AI community needs better tools, processes, and frameworks for dealing with this issue.
Small Data the Simple Way
Few-shot learning seeks to build models that adapt to novel tasks based on small numbers of training examples. This sort of learning typically involves complicated techniques, but researchers achieved state-of-the-art results using a simpler approach.
What’s new: An MIT-Google collaboration led by Yonglong Tian and Yue Wang discovered that simple classifiers with access to an embedding that represents similar tasks can outperform the best few-shot techniques.
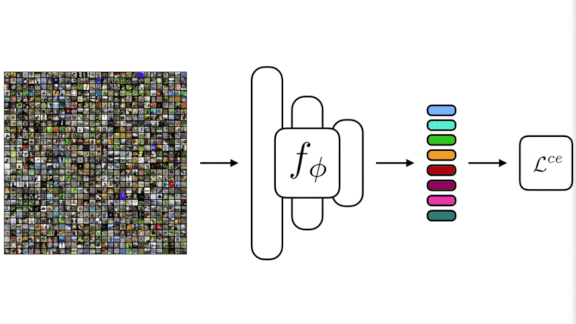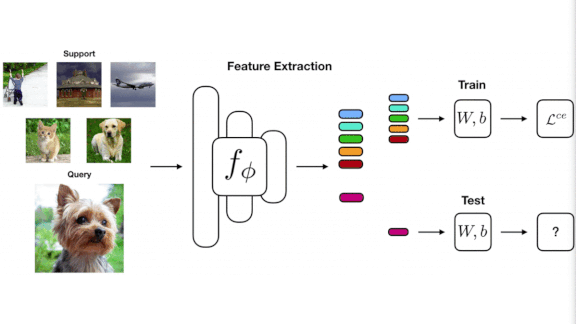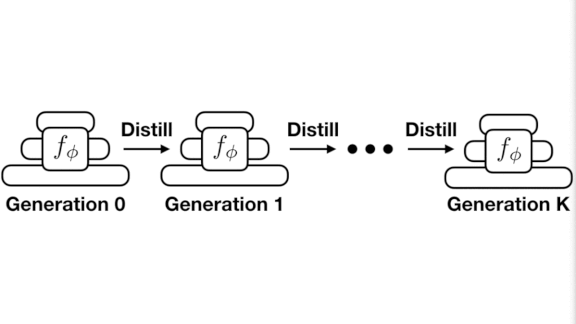
Few-shot learning: A typical few-shot learning algorithm might receive, for example, 100 different supervised learning tasks with a small training set per task. One task could be recognizing dogs based on, say, 600 images of dogs. Another might be recognizing buses based on a similar number of examples. By drawing on commonalities among the 100 tasks, the algorithm aims to do well on a 101st task using a similarly limited training set.
Key insight: Previous methods for extracting commonalities from a set of training tasks were complex. The authors found that simply training a shared feature extractor on a number of tasks, with few training examples of each, allowed a rudimentary algorithm to learn to perform well on novel tasks, also with few training examples.
How it works: The researchers used conventional supervised learning to train a network to classify images that represent 100 different classes, using 600 images of each class. Simple classifiers for each task had the same architecture and parameters up to the final hidden layer.
- After training, the network’s output layer was removed and the final hidden layer was used as a feature extractor.
- A logistic regression model used features from the extractor to learn from a small number of examples of a novel class.
- The researchers improved the system’s accuracy via knowledge distillation; that is, using an existing model to train a new one. The first feature extractor’s output fed a second, and the second learned to recreate the first’s output. They performed this operation repeatedly.
Results: The researchers tested their method against state-of-the-art few-shot models on four datasets derived from ImageNet or CIFAR10. Their method gained around 3 percentage points of accuracy, averaging around 79 percent.
Why it matters: This work aligns few-shot learning more closely than earlier methods with supervised learning and multi-task learning. The use of common techniques throughout machine learning could spur more rapid progress than specialized approaches.
We’re thinking: Many potential applications of deep learning hinge on models that can learn from small data. We’re glad to have a simple approach to the problem.
Crowdsourcing a Cure
Researchers are drawing up blueprints for drugs to fight Covid-19. Machine learning is identifying those most likely to be effective.
What’s new: Covid Moonshot, an international group of scientists in academia and industry, is crowdsourcing designs for molecules with potential to thwart the coronavirus. The project is using a deep learning platform to decide which to synthesize for testing. Any intellectual property it develops will be donated to the public domain.
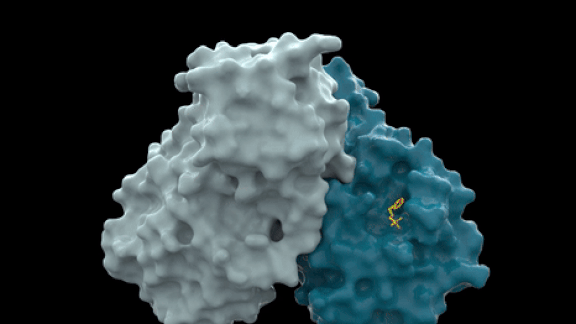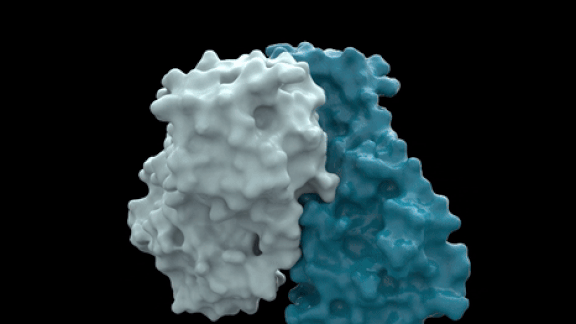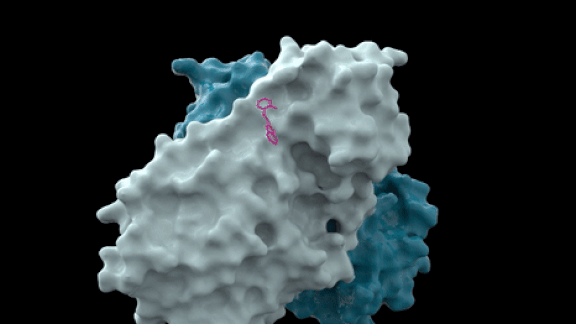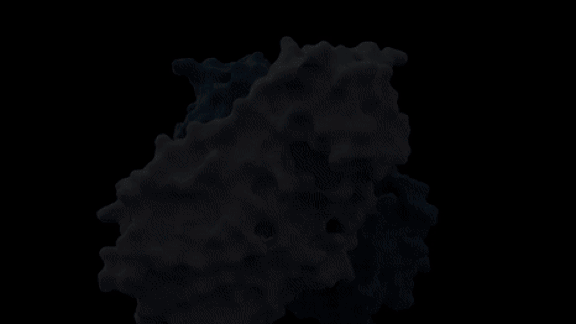
How it works: The group began in March as a partnership between PostEra, a UK-based startup, and Diamond Light Source, a British government science lab. PostEra issued a call for submissions of compounds that incorporate specific chemical fragments that bind to a protein the virus uses to replicate, as pictured above. It has received over 4,500 proposals so far.
- PostEra’s semi-supervised learning system models chemical reactions to determine which compounds are practical to manufacture.
- Designs that pass this analysis are sent to one of two drug manufacturers that have agreed to produce the substances at minimal cost.
- These companies send them to university labs for testing.
- Molecules that prove successful against Covid-19 in a petri dish will move to preclinical trials with lab animals. PostEra hopes to begin this stage within the next few months.
Results: The organization’s manufacturing partners have synthesized over 700 compounds, of which nearly a third have been tested in the lab. Twenty-eight of these inhibited the virus, and eight were especially potent.
Why it matters: This pandemic doesn’t appear to be going away any time soon. AI that predicts the most viable treatments could help limit the damage.
We’re thinking: When you combine citizen science with AI, amazing things can happen.
A MESSAGE FROM DEEPLEARNING.AI
Interested in learning more about AI applications in medicine? Build your own diagnostic and prognostic models in our AI for Medicine Specialization. Enroll now

AI’s Got Talent
Music that features a “singing” koala bear took the prize in one of Europe’s highest-profile AI competitions yet.
What’s new: A team of Australian programmers, designers, and musicians won the inaugural AI Song Contest — a stand-in for this year’s cancelled Eurovision Song Contest — with a koala-tinged track called “Beautiful the World.” You can listen to it here.
How it works: Dutch broadcasters organized the AI Song Contest to fill the void after the 2020 Eurovision Song Contest, which drew 182 million viewers last year, was called off due to worries about Covid-19. AI-proficient judges rated each entry on the creativity and extent of the machine learning involved. Eurovision’s parent company oversaw the balloting. More than 16,000 people watched the competition on May 12.
- The rules required that machine learning be used to generate at least some musical elements, but humans were allowed to arrange them.
- The winner, Uncanny Valley, created a new musical instrument by training a tool from Google’s Project Magenta on noises made by indigenous Australian wildlife including koala bears, kookaburras, and Tasmanian devils.
- The instrument played melodies generated by a neural network trained on 200 songs from prior Eurovision contests.
- The group wrote its lyrics using a GPT-2 implementation trained on words from past Eurovision songs, then trained a neural voice synthesizer to sing them in tune.
Behind the music: Thirteen teams from Europe, the UK, and Australia submitted one song each. Some of our favorites:
- The Dutch team behind the R&B jam “Abbus” trained their neural nets on thousands of pop and folk songs as well as hundreds of Eurovision songs. They ran the resulting instrumental tracks through another model trained to pick out Eurovision winners.
- The makers of “I Write a Song” went for novelty. They penalized their model if it generated melodies too similar to past Eurovision hits.
- A trio of Americans living in Berlin employed seven different neural networks to generate music and lyrics, including a fake news generator that helped with the words for the techno-tinged “I’ll Marry You, Punk Come.”
Why it matters: Although it attracted a small fraction of Eurovision’s usual crowd, the contest shined a bright spotlight on AI’s rising role in the arts.
We’re thinking: What gave the Australian teammates their winning edge? They had the right koalafications.
Human-Level X-Ray Diagnosis
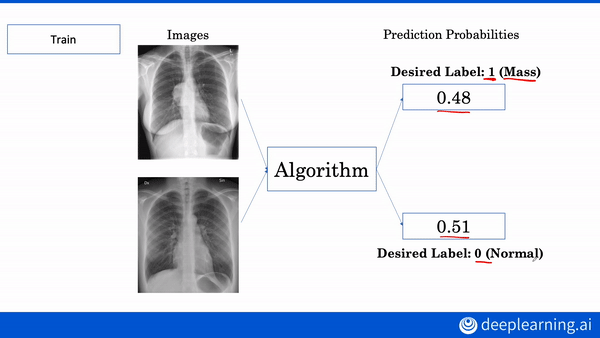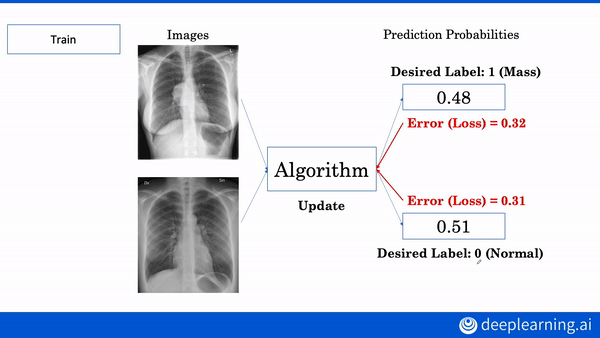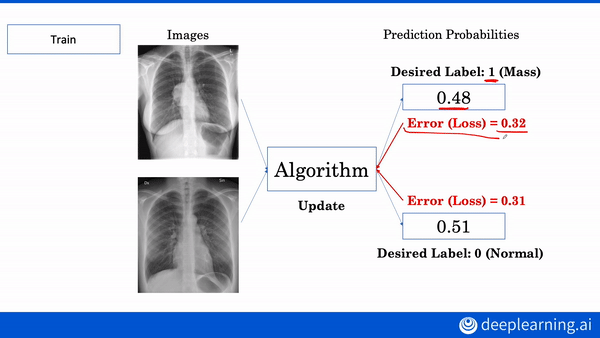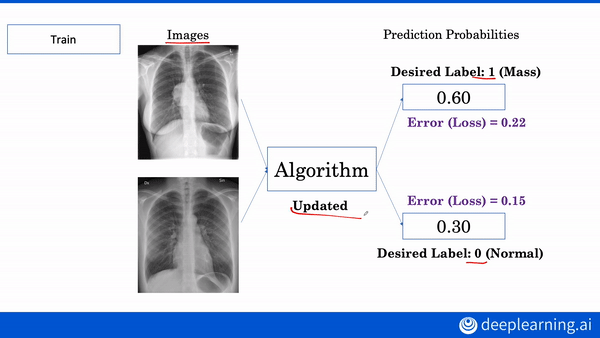
Like nurses who can’t decipher a doctor’s handwriting, machine learning models can’t decipher medical scans — without labels. Conveniently, natural language models can read medical records to extract labels for X-ray images.
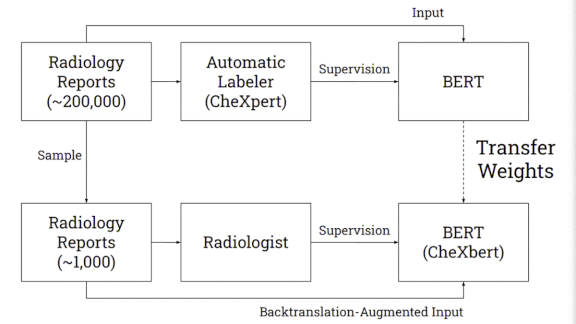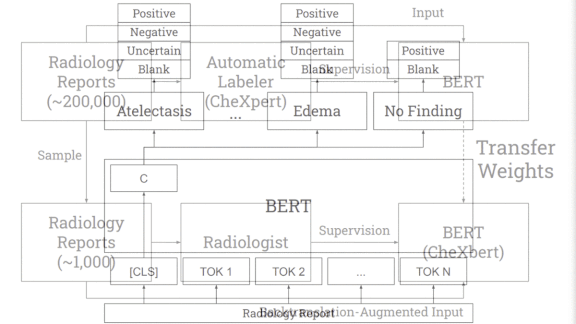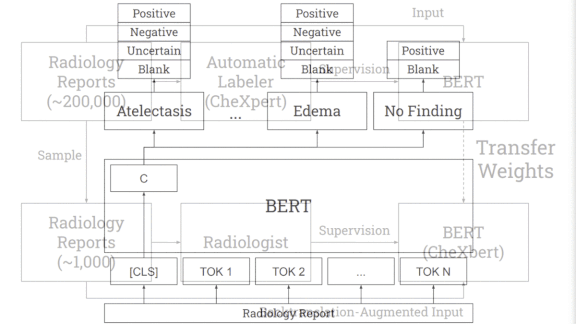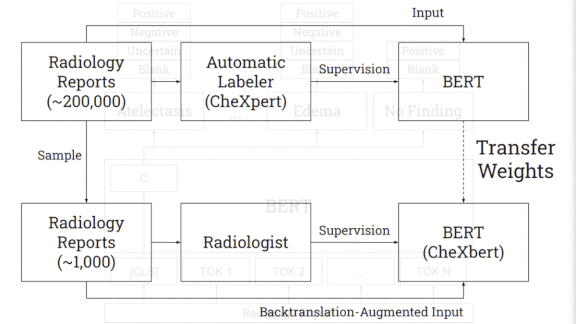
What’s new: A Stanford team including Akshay Smit and Saahil Jain developed CheXbert, a network that labels chest X-rays nearly as accurately as human radiologists. (Disclosure: The authors include Pranav Rajpurkar, teacher of deeplearning.ai’s AI for Medicine Specialization, as well as Andrew Ng.)
Key insight: A natural language model trained on a rule-based system can generalize to situations the rule-based system doesn’t recognize. This is not a new insight, but it is novel in the authors’ application.
How it works: CheXbert predicts a label from 14 diagnostic classes in the similarly named CheXpert dataset: one of 12 conditions, uncertain, or blank. CheXpert comes with a rule-based labeler that searches radiological reports for mentions of the conditions and determines whether they appear in an image.
- The researchers started with BlueBERT, a language model pre-trained on medical documents.
- They further trained the model on CheXpert’s 190,000 reports to predict labels generated by CheXpert’s labeler.
Then they fine-tuned the model on 1,000 reports labeled by two board-certified radiologists. - The fine-tuning also included augmented examples of the reports produced by the technique known as back translation. The researchers used a Facebook translator to turn the reports from English into German and back, producing rephrased versions.
Results: CheXbert achieved an F1 score of 0.798 on the MIMIC-CXR dataset of chest X-rays. That’s 0.045 better than CheXpert’s labeler and 0.007 short of a board-certified radiologist’s score.
Yes, but: This approach requires a pre-existing, high-quality labeler. Moreover, the neural network’s gain over the rule-based system comes at the cost of interpretability.
Why it matters: A doctor’s attention is too valuable to spend relabeling hundreds of thousands of patient records as one-hot vectors for every possible medical condition. Rule-based labeling can automate some of the work, but language models are better at determining labels.
We’re thinking: Deep learning is poised to accomplish great things in medicine. It all starts with good labels.

Information Warfare: Covid Edition
Facebook’s AI can’t spot Covid-19 disinformation on its own. But with human help, it can slow the spread.
What’s new: Facebook uses a combination of humans and neural nets to crack down on messages that make false claims about Covid-19, which may have deadly consequences. Some of the spurious posts are illustrated above.
How it works: Building a classifier to spot coronavirus disinformation is hard because, as information about the disease evolves, so does the disinformation. Facebook relies on people from 60-plus partner organizations to flag misleading posts and ads, such as false claims that drinking bleach cures the virus, social distancing doesn’t help prevent its spread, and dark-skinned people are especially resistant. Algorithms identify copies of the human-flagged items, even if they’ve been slightly altered.
- In April, fact-checkers flagged 7,500 false messages about Covid-19. Facebook’s AI systems added warning labels to 50 million related posts.
- The social network uses a computer vision program to track and label misleading images.
- Facebook’s data suggests that warning labels deter 95 percent of would-be readers from viewing the flagged content.
Behind the news: The company’s latest models had improved its success rate identifying hateful images and memes. It’s easier to train an algorithm to find hate speech because there’s much more of it than misinformation about Covid-19, Facebook said.
Why it matters: In March, the activist organization Avaaz tracked the proliferation of 100 misleading Covid-19 posts on the social network that it judged harmful for undermining public health measures. The articles collectively were viewed 117 million times. The group said Facebook had taken as long as 22 days to flag some stories. Such delays potentially exacerbate infection rates and lengthen the time before people can gather safely for work or recreation.
We’re thinking: It can be hard even for humans to recognize fakery. But Facebook, as one of the world’s most powerful distributors of information, has a unique responsibility to help its members understand the difference.