
Dear friends,
The Covid-19 pandemic is a tragedy that demands urgent and humane response. It’s also pushing us toward new ways of gathering and sharing information — and that may be a faint silver lining that might grow brighter over time.
Many important conferences are being canceled. Just as the rise of online video brought a new generation of online education, I believe the rise of livestreaming and videoconferencing will bring a new generation of online conferences.
For many years, attendees at top conferences have asked themselves: Why do we travel to one location, when it means:
- Significant cost
- Increased carbon emissions
- Limitations on attendance due to venue size
- Limitations imposed by the host country’s visa policies

Just as MOOCs today are a lot more than video, online conferences will be much richer than livestreamed video. Perhaps we’ll have regional chat rooms where attendees in the same country can share local resources even while they listen to a keynote. Or we will generate live transcripts through automatic speech recognition that attendees can tag with live commentary. Up- and downvoting one another’s questions will be routine, and some answers will be crowdsourced.
I don’t expect online conferences to replace in-person events, which still have an important role. Rather, they’ll complement them. With more team members (including many in my organizations) working from home, the time is ripe to experiment with these ideas and move toward lower costs, smaller carbon footprints, democratized access, and stronger communities. If you have thoughts, let us know at hello@deeplearning.ai.
Wash your hands, stay safe, and keep learning!
Andrew
DeepLearning.ai Exclusive
Help Us Improve The Batch
We want to make sure we’re giving you the most useful newsletter in AI. Please answer a few questions to let us know what you’d like to see more (or less) of. Take the brief survey
News

AI Gets a Grip
Amputees can control a robotic hand with their thoughts — plus machine learning.
What’s new: University of Michigan researchers developed a system that uses signals from an amputee’s nervous system to control a prosthetic hand.
How it works: The researchers grafted bits of muscle onto the severed nerve bundles at the ends of amputees’ forearms, then implanted electrodes into the muscle. They amplified and recorded the electric signals transmitted to the nerves when the recipients thought about, say, making a fist, pointing a finger, or rotating a thumb. Then they trained a pair of models to match the signals with the corresponding hand motions.
- A naive Bayes classifier learned to associate nerve signal patterns with common hand shapes.
- The researchers asked the subjects to mimic a virtual thumb as it made back-and-forth and side-to-side motions on a computer screen. A Kalman filter took in the electrical signals and the position and velocity of the avatar and learned to control the digit.
- Once trained, the software enabled the subjects to pick up and move objects and play Rock, Paper, Scissors.
Behind the news: Other research groups are using similar methods to control robotic prostheses. Some promising approaches:
- Epineural electrodes wrap around nerves like a cuff to track signals from the brain.
- Intraneural electrodes tap into nerves using needles, so researchers can target brain signals more precisely.
- Targeted muscle reinnervation re-routes nerves from a severed limb into a nearby muscle. Sensors attached to the skin pick up the signals and transmit them to a prosthesis.
Why it matters: Nearly two million Americans have lost a limb, along with millions more worldwide. More responsive prostheses could dramatically improve their quality of life.
We’re thinking: Will they train robotic hands to do COVID-19-safe, palms-together namaste greetings?
Less Labels, More Learning
In small data settings where labels are scarce, semi-supervised learning can train models by using a small number of labeled examples and a larger set of unlabeled examples. A new method outperforms earlier techniques.
What’s new: Kihyuk Sohn, David Berthelot, and colleagues at Google Research introduced FixMatch, which marries two semi-supervised techniques.
Key insight: The technique known as pseudo labeling uses a trained model’s most confident predictions on unlabeled examples for subsequent supervised training. Consistency regularization penalizes a model if its predictions on two versions of the same data point — say, distorted variations on the same image — are dissimilar. Using these techniques in sequence enables a model to generalize insights gained from unlabeled data.
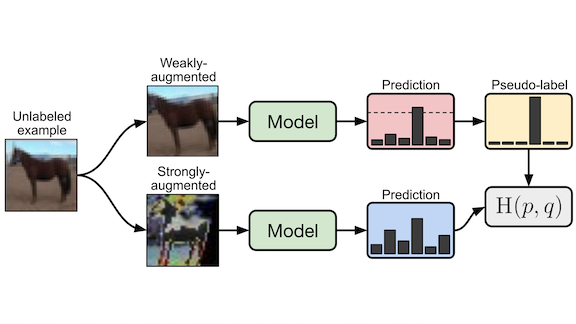
How it works: FixMatch learns from labeled and unlabeled data simultaneously. It learns from a small set of labeled images in typical supervised fashion. It learns from unlabeled images as follows:
- FixMatch modifies unlabeled examples with a simple horizontal or vertical translation, horizontal flip, or other basic translation. The model classifies these weakly augmented images. If its confidence exceeds a user-defined threshold, the predicted class becomes a pseudo label.
- FixMatch generates strongly augmented versions of the pseudo-labeled images by applying either RandAugment (which samples image augmentations randomly from a predefined set) or CTAugment (which learns an augmentation strategy as the model trains). Then it applies Cutout, which removes portions randomly.
- The new model learns to classify the strongly augmented images consistently with the pseudo labels of the images they’re based on.
Results: FixMatch achieved state-of-the-art performance for semi-supervised learning on several benchmarks devised by the researchers. (They removed labels from popular image datasets to create training sets with between four and 400 labels per class.) An alternative semi-supervised approach performed slightly better on some benchmarks, though it’s not obvious under what circumstances it would be the better choice.
Why it matters: Google Research has been pushing the envelope of semi-supervised learning for image classification with a series of better and better algorithms. FixMatch outperforms its predecessors in the majority of comparisons, and its simplicity is appealing.
We’re thinking: Small data techniques promises to open the door to many new applications of AI, and we welcome any progress in this area.

Secret Identity
Hoping to keep surveillance capitalists from capitalizing on your face? Safeguard your selfies with a digital countermeasure.
What’s new: Researchers at the University of Chicago and Fudan University devised a program that subtly alters portrait photos to confuse face recognition models without distorting the image to the human eye.
How it works: Named after the Guy Fawkes mask beloved by privacy advocates, Fawkes cloaks faces by imposing patterns that, to machines, look like someone else.
- Fawkes compares a portrait photo to another person’s picture, using a feature extractor to find the areas that differ most. Then it generates a perturbation pattern and uses it to alter individual pixels.
- A penalty system balances the perturbations against a measure of user-perceived image distortion to make sure the effect is invisible to humans.
- An additional algorithm stress-tests Fawkes’ cloaks to make sure they fool models that use different feature extractors.
Results: The researchers uploaded 50 cloaked photos of the same person to face recognition services from Amazon, Megvii, and Microsoft, which trained on the data. All three failed to identify the person in 32 uncloaked validation images — a 100 percent success rate. However, Fawkes had a hard time fooling models that were already familiar with a given face, having already trained on many uncloaked images. The models developed amnesia, though, after ingesting a fake social media account that exclusively contained cloaked (and renamed) photos.
Yes, but: Fawkes isn’t fool-proof.
- The researchers were able to build models that saw through the system’s output. In fact, one such model cut its effectiveness to 65 percent.
- Models trained on photos of a single person in which 15 percent of the pictures were uncloaked were able to identify the person more than half of the time.
Why it matters: We need ways, whether legal or technical, to enable people to protect their privacy. The U.S. startup Clearview.ai made headlines in January when the New York Times reported that its surveillance system, trained on billions of photos scraped from social media sites without permission, was widely used by law enforcement agencies and private businesses.
We’re thinking: If this method takes off, face recognition providers likely will find ways to defeat it. It’s difficult to make images that humans can recognize but computers can’t.
A MESSAGE FROM DEEPLEARNING.AI
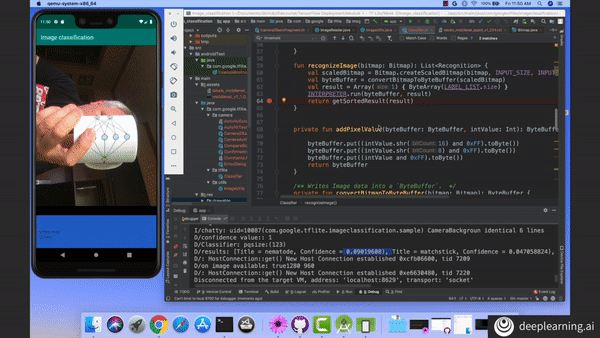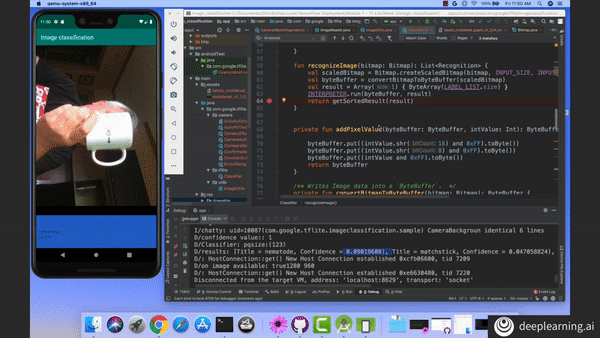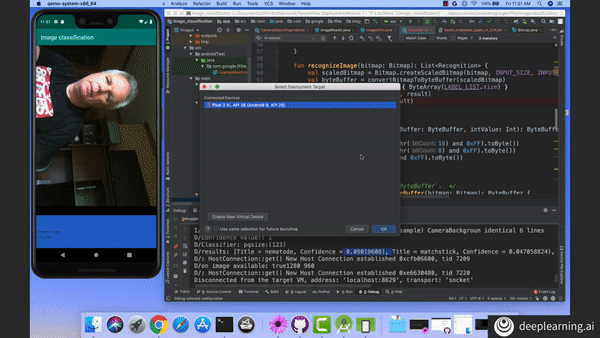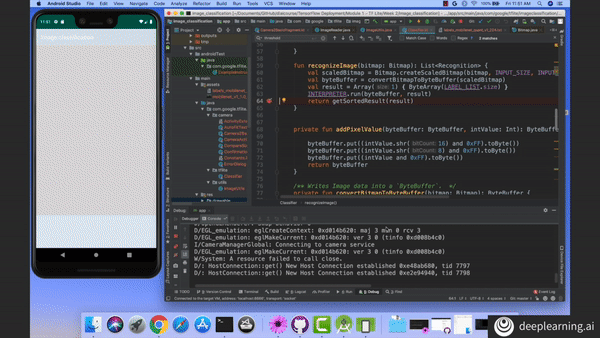
Test your image classification models with your phone’s camera! Learn how to deploy models with TensorFlow Lite in Course 2 of the TensorFlow: Data and Deployment Specialization. Enroll now

Clothes Make the GAN
Fashion models recently sashayed down Paris Fashion Week catwalks in outfits designed by deep neural nets.
What’s new: Swedish design firm Acne Studios based its 2020 fall/winter men’s line on output from a generative adversarial network.
How it works: AI artist Robbie Barrat trained a GAN to generate images of high-fashion outfits by feeding it thousands of pictures of models wearing Acne’s past work. The results were often surreal (though not much more so than Acne’s usual designs).
- Acne’s creative director chose some favorites and adapted them for the real world. He used big patches of sewn-on cloth to recreate the generated images’ bold color swatches, for instance, and unraveled fabric to mimic their glitchy textures.
- Many jackets in the generated images featured large, curved openings at the waist, apparently because the network conflated pockets with hemlines.
Behind the news: Barrat, a 20-year-old machine learning engineer, worked on Nvidia’s self-driving car program and Stanford’s Khatri Lab biomedical research team. He has used AI to generate landscapes and nudes as well as lyrics in the style of Kanye West. In 2017, a trio of French art students used one of his models to create an artwork that sold for nearly half a million dollars.
Why it matters: In the fashion industry, AI is the new black.
- Indian fast-fashion company Myntra uses a model called Ratatouille to design t-shirts and kurtas (a long-sleeved, collarless shirt popular in south Asia).
- Christopher Wylie, who coded (and subsequently blew the whistle on) Cambridge Analytica’s effort to glean political insights from Facebook posts, is using his data-mining savvy to target customers for clothing giant H&M.
Yes, but: Acne’s GAN-driven outfits didn’t wow all the critics in Paris. Vogue’s Luke Leitch wrote: “So the good news is that, on the evidence of this highly original Acne menswear collection, clothes design is not a human profession under threat from AI anytime soon.”
We’re thinking: If we didn’t already know, we never would have guessed that these clothes were designed by a GAN. We’re not sure whether that’s a testament to the designers’ genius or our hopeless fashion sense.
Guest Speaker
Deepfake videos in which one person appears to speak another’s words have appeared in entertainment, advertising, and politics. New research ups the ante for an application that enables new forms of both creative expression and misinformation.
What’s new: Linsen Song with researchers at China’s National Laboratory of Pattern Recognition, SenseTime Research, and Nanyang Technological University produced a model that makes a person on video appear to speak words from a separate audio recording with unprecedented realism. You can see the results in this video.
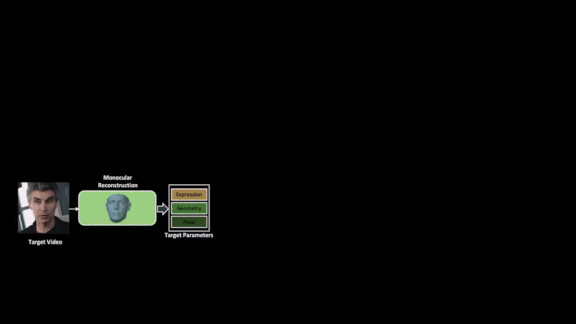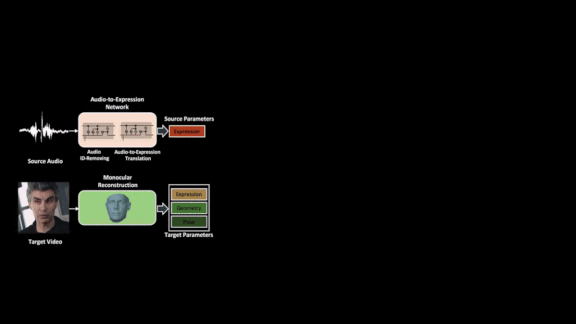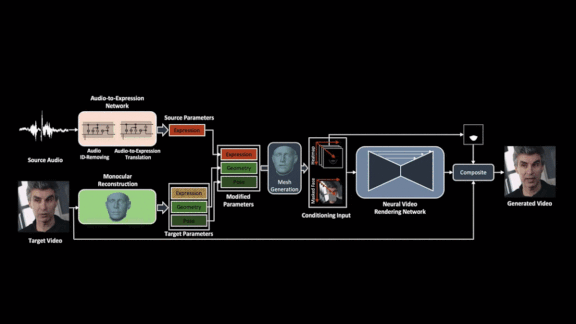
Key insight: Most people’s mouths move similarly when pronouncing the same words. The model first predicts facial expressions from the audio recording. Then it maps those predictions onto the target speaker’s face.
How it works: This approach works with any target video and source audio, synthesizes new motions, and maps them to a model of the target’s face frame by frame.
- The audio-to-expression network learns from talking-head videos to predict facial motions from spoken words.
- A portion of the network learns to remove personal quirks from the recorded voices, creating a sort of universal speaking voice. That way, individual vocal idiosyncrasies don’t bias the predicted mouth movements.
- Software associated with the FaceWarehouse database of facial expression models extracts features of the target speaker’s face, such as head pose and positions of lips, nose, and eyes. The model generates a 3D mesh combining predicted mouth movements from the source audio with the target face.
- In each target video frame, U-net architecture replaces the original mouth with a reconstruction based on the FaceWarehouse meshes.
Results: To test the model’s effectiveness quantitatively, the researchers evaluated its ability to resynthesize mouth movements from their original audio tracks in a video dataset. The model reduced the error in expression (average distance between landmark features) to 0.65 from a baseline of 0.84. In a qualitative study, viewers judged generated videos to have been real 65.8 percent of the time — a high score considering that they identified real videos as real 77.2 percent of the time.
Why it matters: Putting new words in a talking head’s mouth is getting easier. While previous approaches often impose prohibitive requirements for training, this method requires only a few minutes of video and audio data. Meanwhile, the results are becoming more realistic, lending urgency to the need for robust detection methods and clear rules governing their distribution.
We’re thinking: Let’s get this out of the way: We never said it!
Machine Learning Churning
Many of this year’s hottest AI companies are taking the spotlight from last year’s darlings.
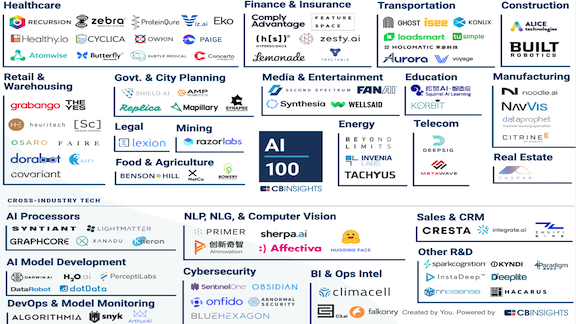
What’s new: CB Insights, which analyzes early-stage companies, published its annual list of the 100 “most promising” startups in AI.
Highlights: Startups in the AI 100 have raised $7.4 billion collectively. Most are headquartered in the U.S., but others are based in 13 countries including Canada, China, and the UK.
- Around 80 percent of the list is new this year. Entire categories turned over, including not only AI strongholds like Cybersecurity and Transportation but also Food & Agriculture, Media & Entertainment, and Retail & Warehousing.
- Several of the survivors are in the Healthcare sector, including Atomwise, Butterfly, Owking, Paige.ai, and Viz.ai.
- Healthcare has the largest number of companies, 13 in all. Retail is second with nine, which is roughly double last year’s tally.
- The list includes 10 unicorns, or companies valued at more than $1 billion, down from 15 last year.
- Among the most richly funded are U.S. autonomous vehicle developer Aurora ($693 million), UK AI-chip designer Graphcore ($536 million), and Lemonade, an American insurance company that uses AI to find fraudulent claims ($480 million).
- For the first time, the list highlights AI startups making products and services that address a variety of industries. Such “cross-industry tech” includes model development, computer vision, natural language processing, business intelligence, cybersecurity, and sales.
Methodology: CB Insights chooses the AI 100 based on a basket of metrics, some of them indirect or subjective, such as the “sentiment” of news coverage. It scores a company’s potential to succeed using a proprietary system based on funding, the overall health of its industry, and its “momentum.”
Why it matters: AI is a hot industry, but not yet a stable one.
We’re thinking: Don’t let the churn scare you. If you join a startup that doesn’t make it, as long as you keep learning, you’ll be in a better position to choose another that won’t repeat the same mistakes — or to start your own.