
Dear friends,
A barrier to faster progress in generative AI is evaluations (evals), particularly of custom AI applications that generate free-form text. Let’s say you have a multi-agent research system that includes a researcher agent and a writer agent. Would adding a fact-checking agent improve the results? If we can’t efficiently evaluate the impact of such changes, it’s hard to know which changes to keep.
For evaluating general-purpose foundation models such as large language models (LLMs) — which are trained to respond to a large variety of prompts — we have standardized tests like MMLU (multiple-choice questions that cover 57 disciplines like math, philosophy, and medicine) and HumanEval (testing code generation). We also have the LMSYS Chatbot Arena, which pits two LLMs’ responses against each other and asks humans to judge which response is superior, and large-scale benchmarking like HELM. These evaluation tools took considerable effort to build, and they are invaluable for giving LLM users a sense of different models’ relative performance. Nonetheless, they have limitations. For example, leakage of benchmarks datasets’ questions and answers into training data is a constant worry, and human preferences for certain answers does not mean those answers are more accurate.
In contrast, our current options for evaluating applications built using LLMs are far more limited. Here, I see two major types of applications.
- For applications designed to deliver unambiguous, right-or-wrong responses, we have reasonable options. Let’s say we want an LLM to read a resume and extract the candidate’s most recent job title, or read a customer email and route it to the right department. We can create a test set that comprises ground-truth labeled examples with the right responses and measure the percentage of times the LLM generates the right output. The main bottleneck is creating the labeled test set, which is expensive but surmountable.
- But many LLM-based applications generate free-text output with no single right response. For example, if we ask an LLM to summarize customer emails, there’s a multitude of possible good (and bad) responses. The same holds for an agentic system to do web research and write an article about a topic, or a RAG system for answering questions. It’s impractical to hire an army of human experts to read the LLM’s outputs every time we tweak the algorithm and evaluate if the answers have improved; we need an automated way to test the outputs. Thus, many teams use an advanced language model to evaluate outputs. In the customer email summarization example, we might design an evaluation rubric (scoring criteria) for what makes a good summary. Given an email summary generated by our system, we might prompt an advanced LLM to read it and score it according to our rubric. I’ve found that the results of such a procedure, while better than nothing, can also be noisy — sometimes too noisy to reliably tell me if the way I’ve tweaked an algorithm is good or bad.

The cost of running evals poses an additional challenge. Let’s say you’re using an LLM that costs $10 per million input tokens, and a typical query has 1000 tokens. Each user query therefore costs only $0.01. However, if you iteratively work to improve your algorithm based on 1000 test examples, and if in a single day you evaluate 20 ideas, then your cost will be 20*1000*0.01 = $200. For many projects I’ve worked on, the development costs were fairly negligible until we started doing evals, whereupon the costs suddenly increased. (If the product turned out to be successful, then costs increased even more at deployment, but that was something we were happy to see!)
Beyond the dollar cost, evals have a significant time cost. Running evals on 1000 examples might take tens of minutes or even hours. Time spent waiting for eval jobs to finish also slows down the speed with which we can experiment and iterate over new ideas. In an earlier letter, I wrote that fast, inexpensive token generation is critical for agentic workflows. It will also be useful for evals, which involve nested for-loops that iterate over a test set and different model/hyperparameter/prompt choices and therefore consume large numbers of tokens.
Despite the limitations of today’s eval methodologies, I’m optimistic that our community will invent better techniques (maybe involving agentic workflows like reflection for getting LLMs to evaluate such output.
If you’re a developer or researcher and have ideas along these lines, I hope you’ll keep working on them and consider open sourcing or publishing your findings.
Keep learning!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

Learn how to build and customize multi-agent systems in “AI Agentic Design Patterns with AutoGen,” made in collaboration with Microsoft and Penn State University. Use the AutoGen framework and implement four agentic design patterns: Reflection, Tool Use, Planning, and Multi-Agent Collaboration. Sign up for free
News

Heart-Risk Model Saves Lives
A deep learning model significantly reduced deaths among critically ill hospital patients.
What’s new: A system built by Chin-Sheng Lin and colleagues at Taiwan’s National Defense Medical Center analyzed patients’ heart signals and alerted physicians if it detected a high risk of death. It reduced deaths of high-risk patients by 31 percent in a randomized clinical trial.
How it works: Researchers trained a convolutional neural network, given an electrocardiogram (a measurement of the heart’s electrical activity), to estimate a risk score. The system compares a patient’s risk score against those of other patients. Scores that rank in the 95th percentile or higher are considered high risk of death within 90 days.
- The authors tested the system on 16,000 patients at two hospitals for 90 days.
- Patients in the experimental group were measured by electrocardiograms, which were fed to the system. If the system identified a high-risk patient, it alerted their attending physician.
- The control group received typical care. The model monitored their electrocardiograms, but physicians saw its output only after the trial was over.
Results: 8.6 percent of patients in the control group and 8.9 percent of patients in the experimental group raised a high-risk alert during the trial. In the experimental group, 16 percent of high-risk patients died; in the control group, 23 percent of high-risk patients died. Overall, in the experimental group, 3.6 percent of patients died; in the control group, 4.3 percent of patients died. The model was trained to predict mortality from all causes, but it showed unusually strong predictive capability for heart-related deaths. Examining causes of death, the authors found that 0.2 percent of patients in the experimental group died from heart-related conditions such as cardiac arrest versus 2.4 percent in the control group.
Behind the news: Hospitals use AI-powered alert systems to identify patients in need of urgent medical attention. Such systems monitor emergency room patients for sepsis, predict whether those patients need intensive care, and predict the risk that discharged patients will require further care. They help hospitals to allocate resources by directing attention where it’s needed most urgently.
Why it matters: It’s rare for any kind of medical intervention to reduce mortality in a subgroup by 31 percent. The authors speculate that the system not only helped direct attention to patients urgently in need of attention but also may have identified electrocardiogram features that doctors typically either don’t understand well or can’t detect.
We’re thinking: This relatively low-cost AI system unambiguously saved lives over three months at different hospitals! We look forward to seeing it scale up.

Self-Driving on Indian Roads
Few makers of self-driving cars have braved the streets of India. Native startups are filling the gap.
What’s new: Indian developers are testing autonomous vehicles on their nation’s disorderly local roads. To cope with turbulent traffic, their systems use different technology from their Western and East Asian counterparts, IEEE Spectrum reported.
How it works: In Indian cities, two-, three-, and four-wheelers share the road with trucks, pedestrians, and animals. Drivers often contend with debris and potholes, and many don’t follow rules. These conditions demand vehicles outfitted with technology that’s more flexible (and less expensive) than the interwoven sensors, models, and 3D maps employed by self-driving cars designed for driving conditions like those found in the United States.
- Where typical self-driving cars combine visible-light cameras, radar, lidar, and GPS, vehicles built by Swaayatt Robots view the world solely through off-the-shelf cameras. The company’s software creates a probabilistic representation of their environment. Although this is normally computationally intensive, Swaayatt claims to have found a low-cost way to do it. Trained via multi-agent reinforcement learning, its systems use game theory to model road interactions and computer vision to fill in missing lane markings. A video shows one of the company’s SUVs navigating narrow roads in its home city of Bhopal.
- Minus Zero focuses on highway driving. Its zPod vehicle navigates using cameras and a GPS sensor. Rather than a series of models dedicated to a single task such as object detection or motion planning, zPod employs a world model that recognizes important details in its surroundings and plans accordingly. The company partnered with Indian truck manufacturer Ashok Leyland to deploy the technology in the next several years.
- RoshAI specializes in retrofitting existing vehicles with autonomous capabilities. It offers separate systems that map a vehicle’s surroundings, control speed and steering, and generate simulations for testing. It aims to retrofit conventional vehicles at lower cost than the price of an integrated self-driving car.
Behind the news: Bringing self-driving cars to India has political as well as technical dimensions. Many Indians hire full-time drivers, and the country’s minister of roads and highways has resisted approving the technology because of its potential impact on those jobs. Drivers cost as little as $150 per month, which puts self-driving car makers under pressure to keep their prices very low. Moreover, India’s government insists that vehicles sold there must be manufactured locally, posing a barrier to foreign makers of self-driving cars.
Why it matters: Rather than starting with an assumption that traffic follows orderly patterns with many edge cases, Indian developers assume that traffic is essentially unpredictable. For them, events that most developers would consider outliers — vehicles approaching in the wrong lanes, drivers who routinely play chicken, domestic animals in the way — are common. This attitude is leading them to develop robust self-driving systems that not only may be better suited to driving in complex environments but also may respond well to a broader range of conditions.
We’re thinking: Former Uber CEO Travis Kalanick said that India would be “the last one” to get autonomous cars. These developers may well prove him wrong!
Knowledge Workers Embrace AI
AI could offer paths to promotion and relief from busywork for many knowledge workers.
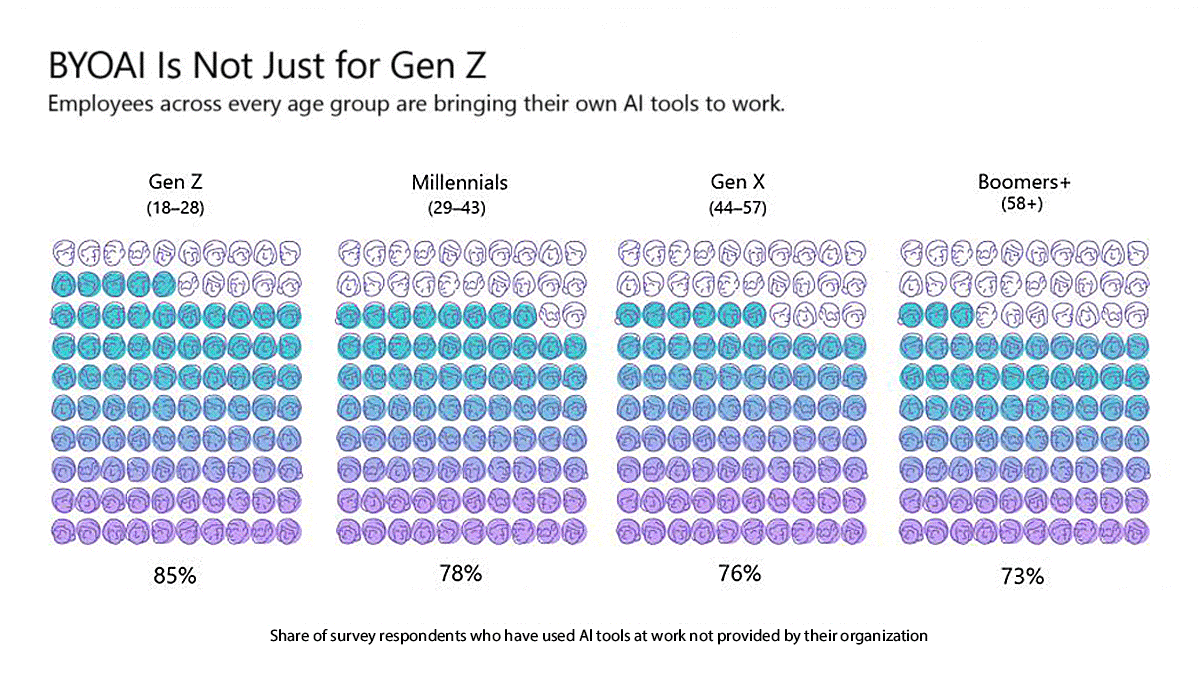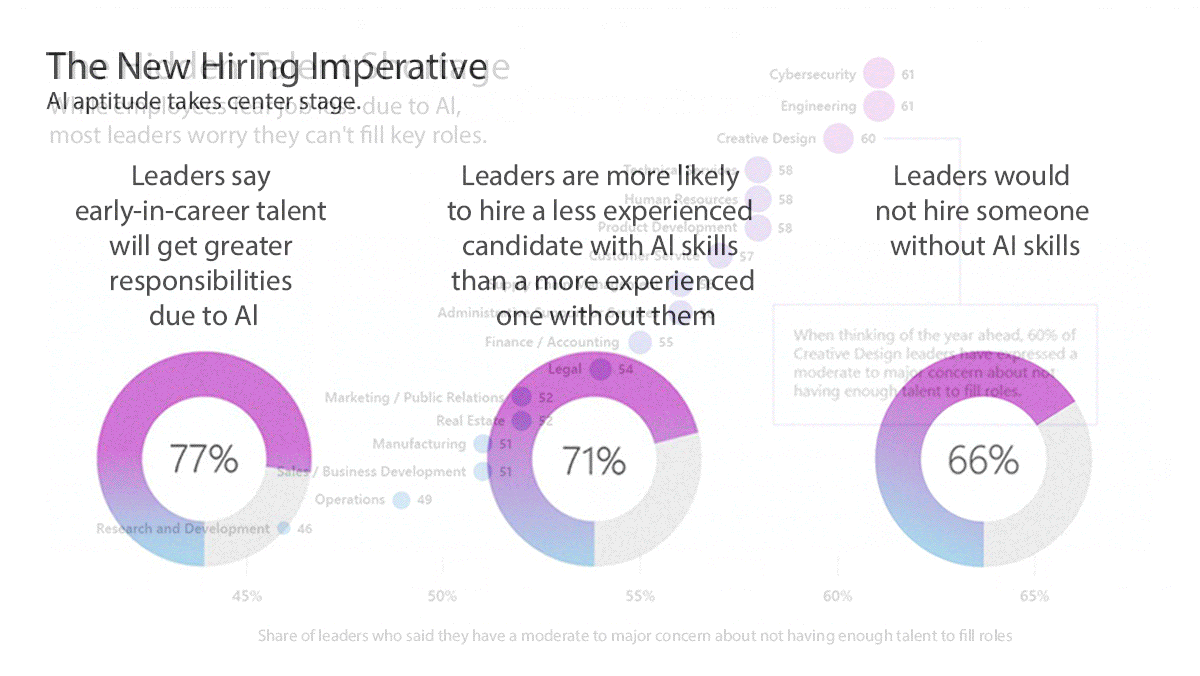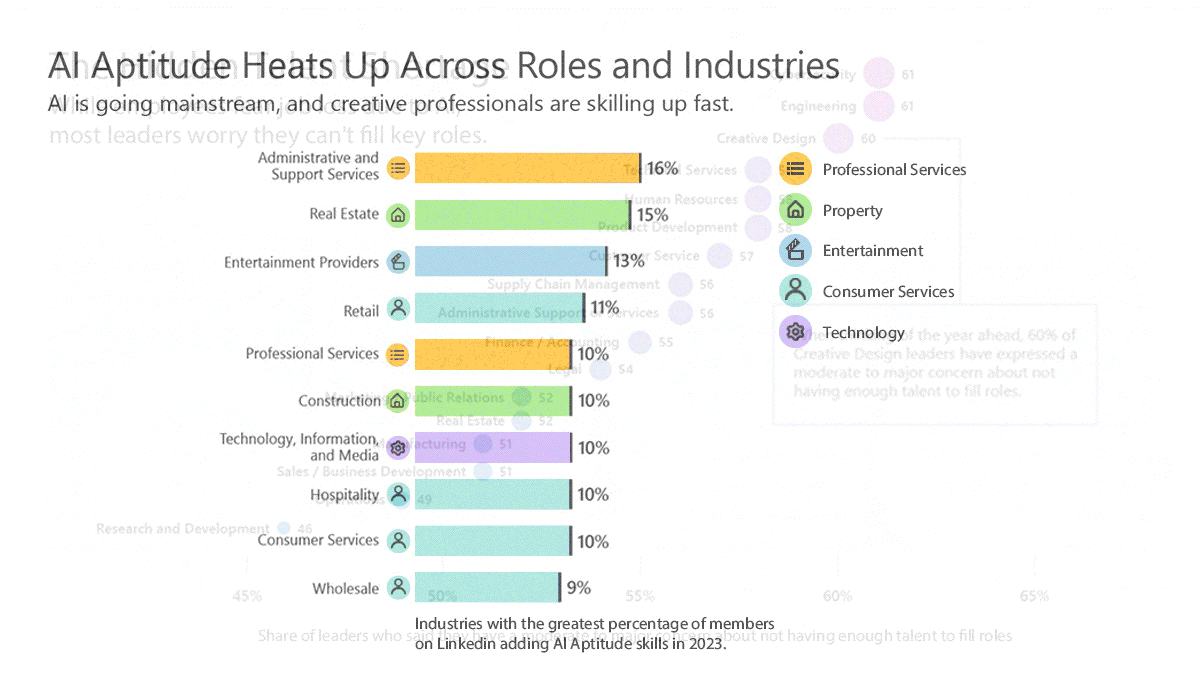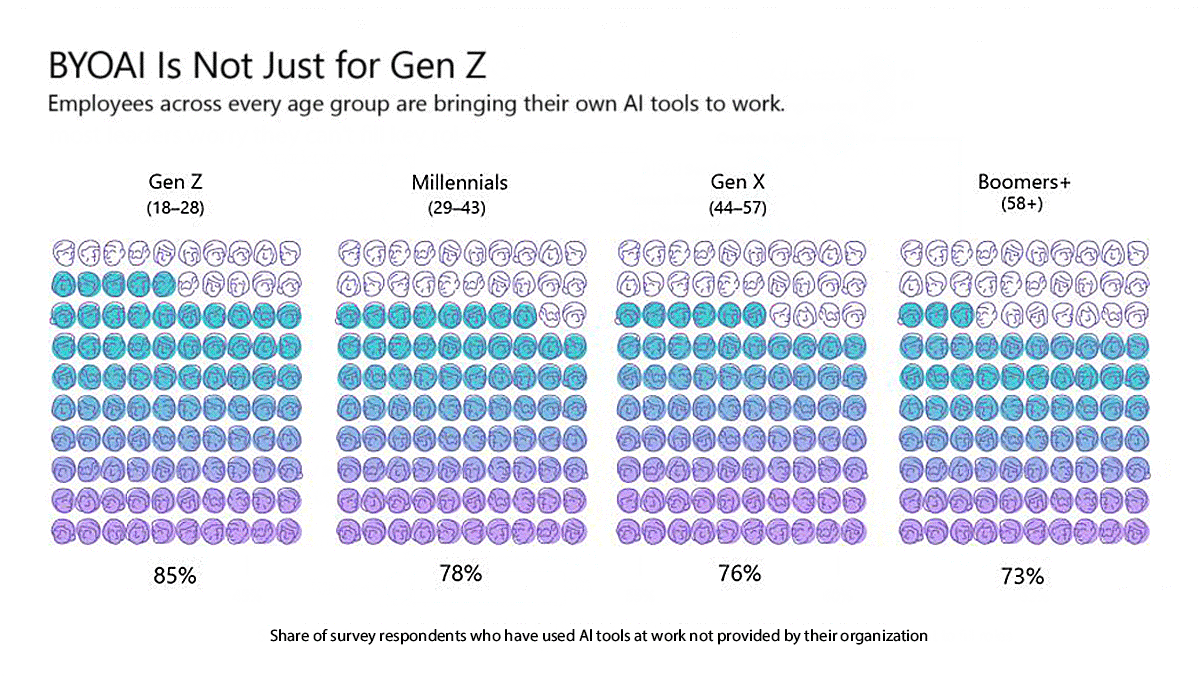
What’s new: 75 percent of knowledge workers worldwide use AI even if they need to supply their own tools, according to survey conducted by Microsoft and Linkedin.
How it works: The authors questioned 3,800 workers in 31 countries throughout the Americas, Europe, Asia, and Australia, asking whether and how they used consumer-grade generative systems like Microsoft Copilot and OpenAI ChatGPT. Majorities of all age groups used AI at work, including 85 percent of respondents 28 or younger and 73 percent of those 58 or older.
- Of those who said they used AI at work, 46 percent had started within the past six months, and 78 percent had started without mandates from employers or managers. More than 80 percent said AI tools helped them save time, focus on the most important work, be more creative, and enjoy work more.
- One motivation for using AI was to keep up with basic tasks such as replying to emails and summarizing meetings. In a separate survey, Microsoft found that, over six months, Copilot users spent more time working in creative applications than managing work communications and created or edited 10 percent more documents in Word, Excel, or PowerPoint.
- The survey identified a group that had used AI several times a week and saved at least 30 minutes daily. These users were 68 percent more likely than average to experiment with different ways to use AI and 66 percent more likely to redesign their workflows. Such users were 53 percent more likely to have received encouragement and training in AI from their employer.
- Some employees saw AI as a double-edged sword. 53 percent worried that it made them replaceable. 52 percent of AI users were reluctant to admit using AI for important tasks. Yet 69 percent said that AI could help them get promoted more quickly, and 76 percent said they needed AI skills to stay competitive in the job market.
- 66 percent of executives at the vice president level or above said they wouldn’t hire an applicant who didn’t know how to use basic generative AI tools. Junior and less-experienced candidates were more likely to get hired and receive increased responsibility if they had AI skills. Hiring managers reported updating job descriptions and requirements appropriately.
Behind the news: The survey results agree with those of other studies of AI’s impact on the workplace. In January, the International Monetary Fund projected that AI would affect 40 percent of all jobs worldwide (either complementing or replacing them), including 60 percent of jobs in countries like the UK and U.S. that have greater percentages of knowledge workers. A 2023 research paper argued that white-collar occupations were most likely to be affected by generative AI, in contrast to previous waves of automation that primarily affected blue-collar jobs. Automation driven by AI increased overall employment, evidence gathered by the European Central Bank shows.
Why it matters: AI is transforming work from the bottom up. Executives and managers want employees who know how to use the technology, but only 39 percent of the people who already do so received training from their employers. Company-wide encouragement to experiment with and take advantage of AI leads to the best outcomes.
We’re thinking: Knowing how to use AI tools is a plus in the current job market. Knowing how to build applications using AI opens another world of doors.
Richer Context for RAG
Text excerpts used in retrieval augmented generation (RAG) tend to be short. Researchers used summarization to pack more relevant context into the same amount of text.
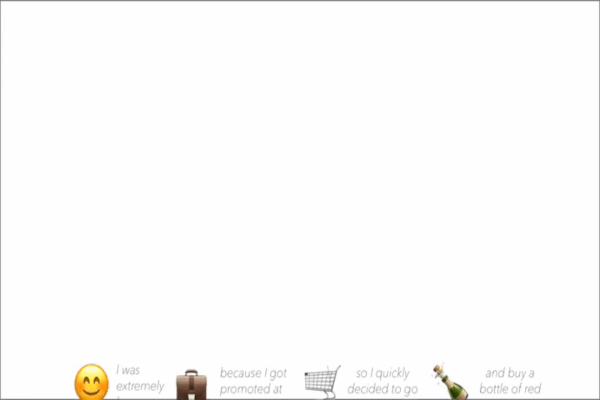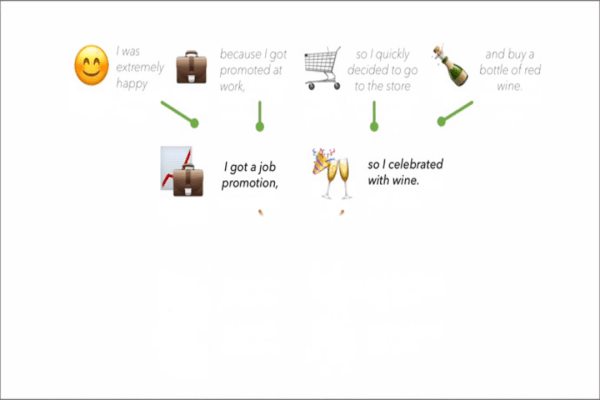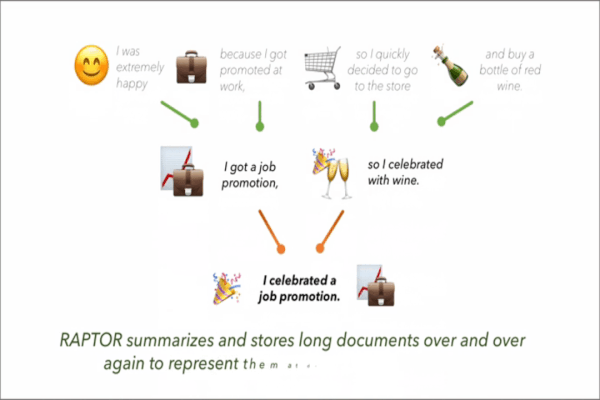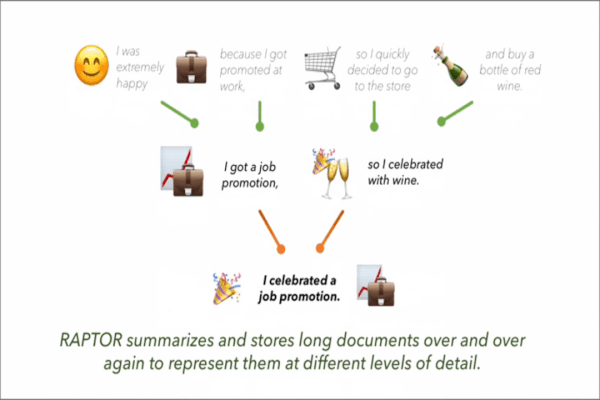
What’s new: Parth Sarthi and colleagues at Stanford built Recursive Abstractive Processing for Tree-Organized Retrieval (RAPTOR), a retrieval system for LLMs. RAPTOR can choose to deliver original text or summaries at graduated levels of detail, depending on the LLM’s maximum input length.
Key insight: RAG improves the output of large language models by gathering from documents and/or web pages excerpts that are relevant to a user’s prompt. These excerpts tend to be brief to avoid exceeding an LLM’s maximum input length. For instance, Amazon Bedrock’s default excerpt length is 200 tokens (words or parts of a word). But important details may be scattered throughout longer passages, so short excerpts can miss them. A summarizer can condense longer passages into shorter ones, and summarizing summaries can condense large amounts of text into short passages.
How it works: RAPTOR retrieved material from QASPER, a question answering corpus that contains around 1,600 research papers on natural language processing. The authors processed QASPER through an iterative cycle of summarizing, embedding, and clustering. The result was a graduated series of summaries at ever higher levels of abstraction.
- The authors divided the corpus into excerpts of 100 tokens each. The SBERT encoder embedded the excerpts.
- A Gaussian mixture model (GMM) clustered the embeddings into groups of similar excerpts. GPT-3.5-turbo summarized each group of excerpts.
- This cycle repeated — SBERT embedded the summaries, GMM clustered the embeddings into groups, and GPT-3.5-turbo summarized each group of summaries — until no further groups could be formed.
- At inference, to retrieve passages relevant to a user’s prompt, the system computed the cosine similarity between SBERT’s embedding of the prompt and the embedding of each excerpt and summary. It ranked the excerpts and summaries according to their similarity to the prompt, retrieved the highest-scoring ones, and prepended them to the input. It stopped when adding another excerpt or summary would exceed the LLM’s maximum input length.
- The LLM received the concatenated prompt plus excerpts and/or summaries and generated its response.
Results: Paired with a variety of LLMs, RAPTOR exceeded other retrievers in RAG performance on QASPER’s test set. Paired with the UnifiedQA LLM, RAPTOR achieved 36.7 percent F1 score (here, the percentage of tokens in common between the output and ground truth), while SBERT (with access to only the 100-token excerpts) achieved 36.23 percent F1 score. Paired with GPT-4, RAPTOR achieved 55.7 percent F1 score (setting a new state of the art for QASPER), DPR achieved 53.0 percent F1 score, and providing paper titles and abstracts achieved 22.2 percent F1 score.
Why it matters: Recent LLMs can process very long inputs, notably Gemini 1.5 (up to 2 million tokens) and Claude 3 (200,000 tokens). But it takes time to process so many tokens. Further, prompting with long inputs can be expensive, approaching a few dollars for a single prompt in extreme cases. RAPTOR enables models with tighter input limits to get more context from fewer tokens.
We’re thinking: This may be the technique that developers who struggle with input context length have been long-ing for!