
Dear friends,
Last week, I described four design patterns for AI agentic workflows that I believe will drive significant progress this year: Reflection, Tool use, Planning and Multi-agent collaboration. Instead of having an LLM generate its final output directly, an agentic workflow prompts the LLM multiple times, giving it opportunities to build step by step to higher-quality output. In this letter, I'd like to discuss Reflection. For a design pattern that’s relatively quick to implement, I've seen it lead to surprising performance gains.
You may have had the experience of prompting ChatGPT/Claude/Gemini, receiving unsatisfactory output, delivering critical feedback to help the LLM improve its response, and then getting a better response. What if you automate the step of delivering critical feedback, so the model automatically criticizes its own output and improves its response? This is the crux of Reflection.
Take the task of asking an LLM to write code. We can prompt it to generate the desired code directly to carry out some task X. After that, we can prompt it to reflect on its own output, perhaps as follows:
Here’s code intended for task X: [previously generated code]
Check the code carefully for correctness, style, and efficiency, and give constructive criticism for how to improve it.
Sometimes this causes the LLM to spot problems and come up with constructive suggestions. Next, we can prompt the LLM with context including (i) the previously generated code and the constructive feedback and (ii) ask it to use the feedback to rewrite the code. This can lead to a better response. Repeating the criticism/rewrite process might yield further improvements. This self-reflection process allows the LLM to spot gaps and improve its output on a variety of tasks including producing code, writing text, and answering questions.
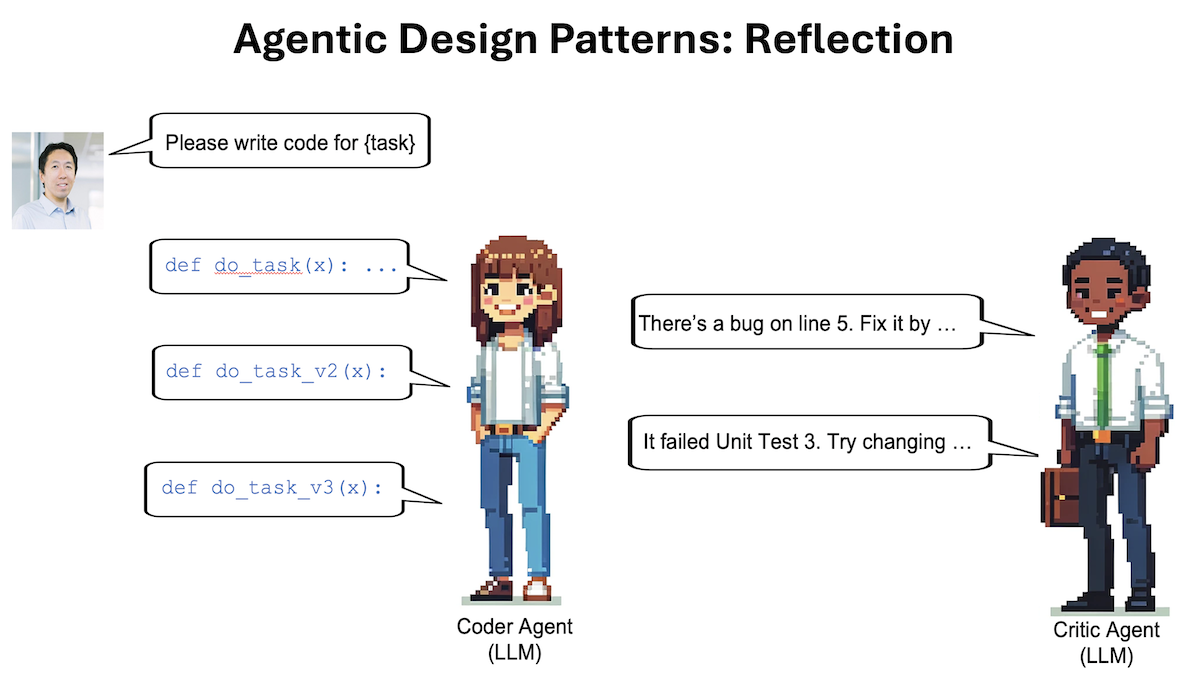
And we can go beyond self-reflection by giving the LLM tools that help evaluate its output; for example, running its code through a few unit tests to check whether it generates correct results on test cases or searching the web to double-check text output. Then it can reflect on any errors it found and come up with ideas for improvement.
Further, we can implement Reflection using a multi-agent framework. I've found it convenient to create two different agents, one prompted to generate good outputs and the other prompted to give constructive criticism of the first agent's output. The resulting discussion between the two agents leads to improved responses.
Reflection is a relatively basic type of agentic workflow, but I've been delighted by how much it improved my applications’ results in a few cases. I hope you will try it in your own work. If you’re interested in learning more about reflection, I recommend these papers:
- “Self-Refine: Iterative Refinement with Self-Feedback,” Madaan et al. (2023)
- “Reflexion: Language Agents with Verbal Reinforcement Learning,” Shinn et al. (2023)
- “CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing,” Gou et al. (2024)
I’ll discuss the other agentic design patterns in future letters.
Keep learning!
Andrew
P.S. New JavaScript short course! Learn to build full-stack web applications that use RAG in “JavaScript RAG Web Apps with LlamaIndex,” taught by Laurie Voss, VP of Developer Relations at LlamaIndex and co-founder of npm.
- Build a RAG application for querying your own data.
- Develop tools that interact with multiple data sources and use an agent to autonomously select the right tool for a given query.
- Create a full-stack web app step by step that lets you chat with your data.
- Dig further into production-ready techniques like how to persist your data, so you don’t need to reindex constantly.
News
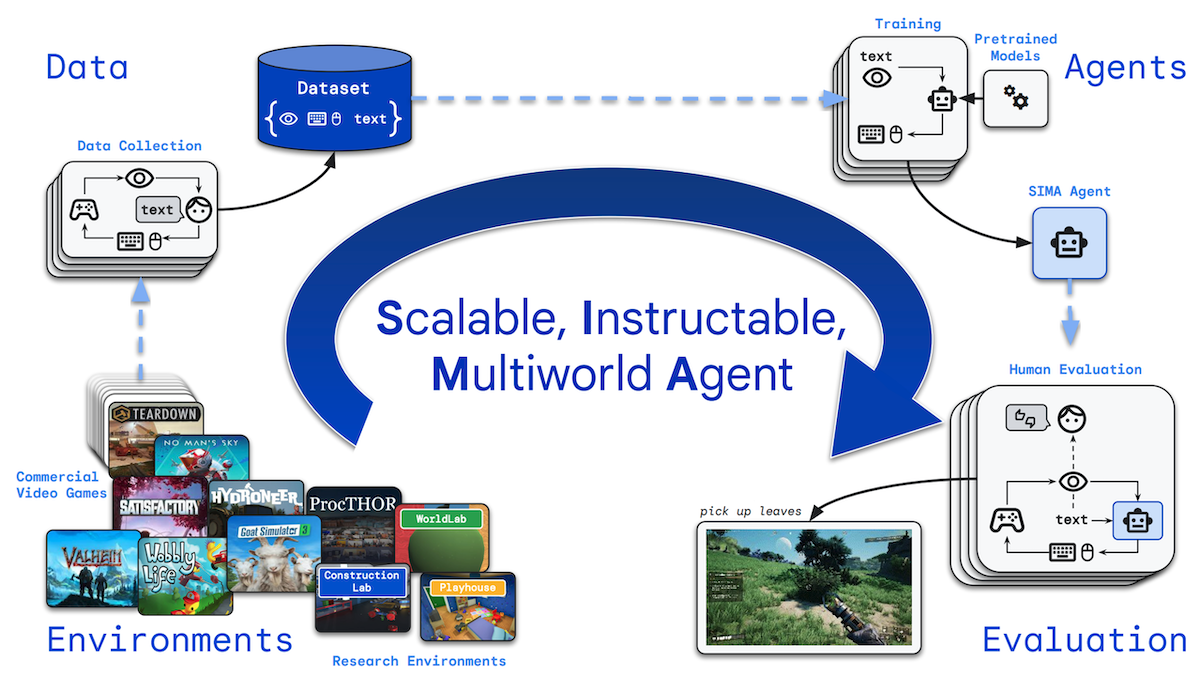
One Agent, Many Environments
AI agents are typically designed to operate a particular software environment. Recent work enabled a single agent to take actions in a variety of three-dimensional virtual worlds.
What's new: A team of 90 people at Google and University of British Columbia announced Scalable Instructable Multiworld Agent (SIMA), a system that learned to follow text instructions (such as “make a pile of rocks to mark this spot” or “see if you can jump over this chasm”) in seven commercial video games and four research environments.
How it works: SIMA’s architecture consists of several transformers and a vanilla neural network. The authors trained it to mimic human players using a dataset of gameplay broken into 10 second tasks, including onscreen images, text instructions, keyboard presses, and mouse motions. The video games included Goat Simulator 3 (a third-person game in which the player takes the form of a goat), No Man’s Sky (a first- or third-person game of exploration and survival in outer space), Hydroneer (a first-person game of mining and building), and others.
- Given a text instruction and a frame of onscreen imagery, SPARC (a pair of transformers pretrained on text-image pairs to produce similar embeddings of similar text and images) produced text and image embeddings. Given recent frames, Phenaki (a transformer pretrained to predict future frames in a video) generated a video embedding.
- Given the image, text, and video embeddings, a collection of transformers learned to produce a representation of the game. (The authors don’t fully describe this part of the architecture.)
- Given the game representation, a vanilla neural network learned to produce the corresponding keyboard and mouse actions.
Results: Judges evaluated SIMA’s success or failure at completing nearly 1,500 instructions that spanned tasks in nine categories like action (“jump”), navigation (“go to your ship”), and gathering resources (“get raspberries”). In Goat Simulator 3, SIMA completed 40 percent of the tasks. In No Man’s Sky, the judges compared SIMA’s performance to that of the human players whose gameplay produced the training data. SIMA was successful 34 percent of the time, while the players were successful 60 percent of the time. Judges also compared SIMA to versions that were trained to be experts in a single game. SIMA was successful more than 1.5 times more often than the specialized agents.
Behind the news: SIMA extends Google’s earlier successes building agents that rival or beat human players at individual games including Go, classic Atari games, and StarCraft II.
Why it matters: Training agents to follow directions in various environments, seeing the same things humans would, is a step toward building instructable agents that can work in any situation. The authors point to potential applications in robotics, simulations, and gaming; wherever an agent might need to be guided through diverse challenges.
We're thinking: This work shows that an agent trained on multiple games can perform better than an agent trained on just one, and that the richer the language inputs in a gameworld, the better the agent can perform. With only a handful of training environments under its belt, SIMA doesn’t demonstrate superhuman performance, but it gets the job done a surprising amount of the time!
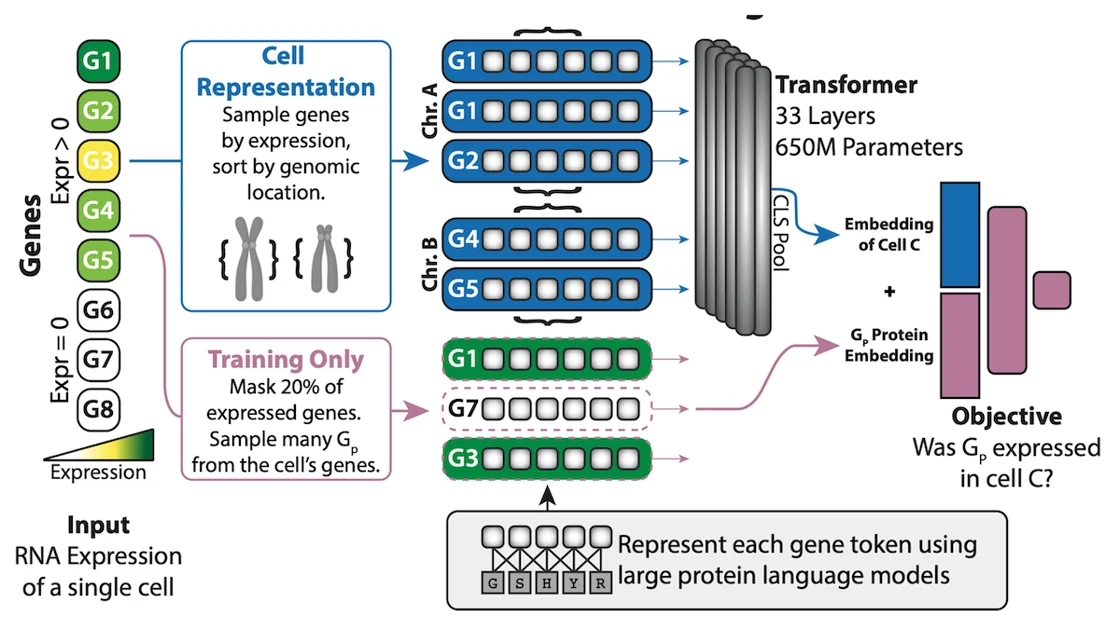
Cross-Species Cell Embeddings
Researchers used an AI system to identify animal cell types from gene sequences, including a cell type that conventional approaches had discovered only in the past year.
What’s new: Biologists at Stanford trained a system to produce embeddings that represent individual cells in an organism. This enabled them to find cell types that have common function in different animals; for instance, the Norn cell, a type of kidney cell that biologists had previously theorized but discovered only in 2023.
How it works: Universal Cell Embedding (UCE) comprises two transformers that produce embeddings of genes and cells respectively, plus a classifier based on a vanilla neural network. The authors trained the classifier, given embeddings of a gene and cell, to classify whether or not the cell produces the protein coded by that gene. The training dataset included RNA sequences of 36.2 million cells from eight animal species (humans and mice accounted for 33.9 million) along with related protein structures.
- The authors represented each cell as a sequence of gene embeddings, laid out in the order in which they appear in the cell’s genome. Instead of including all of a cell’s genes, the authors sampled 1,024 genes known to encode proteins. A pretrained ESM-2 transformer computed each gene’s embedding based on the protein(s) — that is, amino acid sequence(s) — it produces.
- The authors randomly masked 20 percent of the gene embeddings. Given the masked sequence, a vanilla transformer learned to compute an embedding of the cell.
- For each gene in the cell, the authors concatenated its embedding with the cell embedding. Given the combined embeddings, the vanilla neural network learned to classify whether the genes encoded a protein.
Results: Cell embeddings produced by UCE enabled the authors to identify cell types in animal species that weren’t in the training set. For instance, the authors embedded a dataset of mouse cells and applied UMAP clustering to differentiate the types. They labeled the clusters as specific cell types (including Norn cells, which biologists took more than a century to find) based on the presence of certain genes that distinguish one cell type from another. Using the labels, they trained a logistic classifier. They applied the classifier to their training dataset and found Norn cells, among other cell types, in species other than mice. They verified the findings by looking for genes that tend to show up only in Norn cells.
Why it matters: UCE’s embeddings encode biologically meaningful information about individual cells, enabling a clustering algorithm to group them into recognized cell types. The fact that the recently discovered Norn cell was among those clusters suggests that UCE may yield further discoveries that accelerate development of new medicines, lab processes, and research methods. In fact, the model found Norn cells — which are known to occur in the kidney — in organs where they have not been seen before. If this result turns out to be valid, UCE will have made a discovery that has eluded biologists to date.
We’re thinking: It’s a truism that a machine learning model is only as good as its data. That makes this work all the more impressive: Its training data included a handful of species, yet it generalized to others.
NEW FROM DEEPLEARNING.AI

Join our short course on “JavaScript RAG Web Apps with LlamaIndex” to learn how to build full-stack JavaScript web applications that let you chat with your data. Harness the capabilities of large language models and retrieval augmented generation (RAG)! Enroll for free

U.S. Deploys AI-Assisted Targeting
The United States military is using computer vision to target enemy positions in the Red Sea and elsewhere.
What’s new: Maven, a system that analyzes satellite and geolocation data, has been used to identify targets in real-world conflicts, Bloomberg reported. The system was developed primarily by Palantir and integrates technology from Amazon, Microsoft, information technology firms ECS Federal and L3Harris, aerospace firms Maxar and Sierra Nevada, and other unnamed companies.
How it works: The 18th Airborne Corps, a U.S. Army unit organized for rapid deployment around the world, used Maven in live-fire training exercises. The system helped locate surface vessels in the Red Sea, rocket launchers in Yemen, and potential airstrike targets in Iraq and Syria. The U.S. used it to help Ukraine’s armed forces to locate Russian equipment, anonymous sources said.
- Maven melds various data streams into a top-down image of a geographic area. Satellites provide still images and video, and radar and infrared observations enable the system to see through clouds and other obstructions. It can also integrate non-visual information such as location data from mobile devices and social media posts.
- Computer vision models identify military equipment such as aircraft and tanks, highlighting significant changes to object locations. They can register a buildup of equipment that may indicate a new, or newly active, military base.
- The system displays a map that outlines potential targets in yellow and friendly forces, schools, hospitals, and other no-strike zones outlined in blue. Human decision-makers review output and authorize responses.
Behind the news: Google initially developed Maven for the U.S. Defense Department around 2017. Palantir inherited the project after Google, facing protests by employees who did not want to contribute to government intelligence systems, declined to renew its contract in 2018. The U.S. military now has more than 800 active AI projects with a wide range of technology partners and contractors. Other countries are deploying similar technology: Israel and Ukraine have used AI-assisted targeting in their ongoing conflicts.
Yes, but: Some U.S. military experts worry about Maven’s accuracy. In tests, Maven successfully identified objects about 60 percent of the time, while human analysts working with the 18th Airborne Corps did so 84 percent of time. Moreover, the system’s training data emphasizes deserts, and its success rate drops in other types of environments.
Why it matters: Maven and similar systems offer some advantages over human analysts. They can observe and integrate multiple data streams simultaneously, and they can identify potential targets much more quickly. It’s likely that more data will make these systems more accurate. On the other hand, they represent a further step toward automated warfare in which automated assistance could come to displace human decision-making.
We’re thinking: Automated targeting is increasingly used in military applications, and less-sophisticated systems have been in use for decades. However, humans should always be in control of decisions to fire. We support a global ban on fully autonomous weapons.

Robo-Football From Simulation to Reality
Humanoid robots can play football (known as soccer in the United States) in the real world, thanks to reinforcement learning.
What’s new: Tuomas Haarnoja and colleagues at Google and University of Oxford trained an agent to play one-on-one football in a simulated environment. They applied the agent to 20-inch hardware robots on a scaled-down field. You can see it in action here.
Key insight: In reinforcement learning, an agent improves as it explores various motions. However, such exploration risks damaging expensive hardware. By training in a simulation, the agent can attempt a diversity of motions without risking a physical robot. Once the agent is trained, it can make the leap from simulation to reality.
How it works: The agent learned in a virtual world to control the robot’s motion given (i) a simulated robot’s state (including the position, velocity, and acceleration of each of 20 joints), (ii) the current game state (including the location and velocity of the ball and opponent), (iii) the game state at each of the last five time steps, and (iv) the agent’s five previous actions. Training proceeded via reinforcement learning in two stages.
- During the first stage of training, the authors trained two teachers, both of which were vanilla neural networks. (i) The first teacher learned to predict movements that help a simulated robot score goals against an untrained opponent that immediately fell over. The teacher earned rewards for scoring and was penalized for falling over or letting the opponent score, among other rewards and penalties. (ii) The second teacher learned to make a fallen simulated robot stand up. It received larger rewards for smaller differences, and smaller rewards for larger differences, between the robot’s joint positions and the joint positions for key robot poses recorded during a manually designed process of standing up.
- The second stage of training involved another agent, also a vanilla neural network. This agent played a match against a previous version of itself in which each agent controlled a simulated robot. It received rewards for moving the robot’s joints in ways that helped it win the match or resembled the two teachers’ movements; this encouraged the agent to score goals and stand up after falling. To better approximate real-world conditions, the authors randomly perturbed the simulation, adding noise to the sensors that measured the robot’s actions and delaying parts of the simulation. They also restricted the joints’ range of motion to prevent the simulated robot from acting in ways that would damage a hardware robot.
- At inference, the trained agent controlled an off-the-shelf Robotis OP3 humanoid robot, which costs around $14,000.
Results: The agent learned not only to turn and kick but also to anticipate the ball’s motion and block an opponent’s shots. It scored penalties against a stationary goalie with 90 percent success in simulation and 70 percent success in the physical world. It stood up in 0.9 seconds on average, while a manually designed agent stood up in 2.5 seconds. Its maximum walking speed of 0.69 meters per second beat the manually designed agent’s 0.27 meters per second. However, its kicks propelled the ball at 2.0 meters per second on average, slower than the manually designed agent’s 2.1 meters per second.
Why it matters: Controlling humanoid robots is challenging, as they’re less stable than quadrupeds. Just getting them to do one type of motion, such as jumping, can require dedicated research. This work drives humanoid robots in complex motions by combining established training methods: training in a noisy simulation, self-play, and using teacher agents to reward particular actions.
We’re thinking: This work demonstrates that robots get a kick out of machine learning.
Data Points
The latest AI updates of the week include:
👉 Stability AI’s Stable Video 3D
👉 Sakana’s evolution-inspired model merging technique
👉 The new Blackwell B200 GPU by Nvidia
And much more.
Read Data Points, your weekly AI news digest.