
Dear friends,
Last week brought reports that the European Union is considering a three- to five-year moratorium on face recognition in public places. Face recognition is a problematic technology with significant potential for misuse, and I celebrate the EU’s effort to protect human rights and civil society. But the blunt instrument of a long moratorium is a terrible idea.
Five years is an eternity in AI, and implementing this proposal would all but guarantee that EU teams fall behind their colleagues in the U.S., China, and other nations.
Contrary to popular belief, face recognition is not a solved problem. Although many teams have achieved good performance on face recognition benchmarks such as LFW, the technology still has a long way to go. Open source software makes it easy to recognize faces from a front-facing still image, but a number of hard problems remain to be solved, including multi-camera tracking, re-identification (when someone exits the frame and then re-enters), robustness to occasional camera outages, and automatic multi-camera calibration. Such capabilities will advance significantly in the next few years.
Countries that have the foundation to develop this technology will pull ahead of those that don’t. It would be ironic if the EU, having slowed its own work on face recognition, were to end up having to license it from American and Chinese companies.
The Universal Declaration of Human Rights remains one of the most inspirational documents I have ever read. I won’t pretend that forming good regulations is easy; it is hard because it entails hard tradeoffs. We must make sure that privacy-respecting societies don’t fall behind in technology development precisely because of those laudable values. Instead of hobbling them, we must enable them to leap ahead in a way that propagates those values.
Keep learning!
Andrew
News

Virtual Creatures Come to Life
When artificial intelligence meets biology, even the simplest life forms can be mind-blowing.
What happened: Researchers at Tufts and the University of Vermont programmed an evolutionary algorithm to design virtual organisms with specific capabilities. Then they implemented the designs using animal cells to produce living machines, as illustrated in this video.
How it works: The algorithm designed organisms to meet one of four behavioral goals: locomotion, object manipulation, object transportation, and collective behavior.
- For each goal, the algorithm started with randomly assembled virtual organisms. Then it replaced those that performed poorly with mutated copies of better-performing versions, and so on for 100 trials.
- The virtual organisms consisted of two building blocks: Elements that contract and those that passively hold the structure together.
- The researchers built the most successful virtual organisms using cells harvested from frogs. In these biological versions — globs of tissue around 1 millimeter wide — pumping heart cells substituted for contracting elements and skin cells replaced structural ones.
- The team set these tiny Frankensteins loose in petri dishes and monitored how closely the copies replicated the behaviors of their virtual progenitors. The biological versions usually required a few iterations before they performed as expected.
Why it matters: The authors envision a “scalable pipeline for creating functional novel life forms.” They believe their approach could yield bugs that perform a variety of tasks, like digesting spilled oil or gathering ocean-borne plastic particles. They could also deliver medicine, identify cancer, or clear away arterial plaque.
We’re thinking: We humbly request an army of biobots designed to scrub bathrooms.
Better Than Backprop
End-to-end backpropagation and labeled data are the peanut butter and chocolate of deep learning. However, recent work suggests that neither is necessary to train effective neural networks to represent complex data.
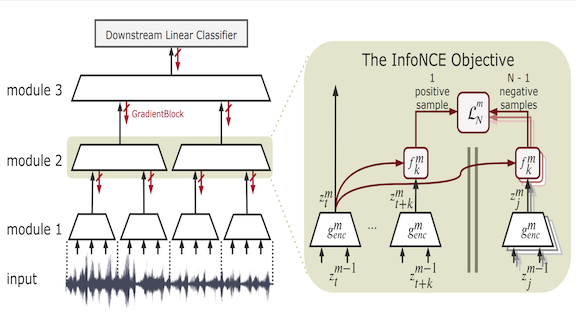
What’s new: Sindy Löwe, Peter O’Connor, and Bastiaan Veeling propose Greedy InfoMax (GIM), an unsupervised method for learning to extract features that trains only one layer at a time.
Key insight: The information bottleneck theory (IB) suggests that neural networks work by concentrating information like a data-compression algorithm. In data compression, the amount of information retained is measured in mutual information (MI) between original and compressed versions. IB says that neural nets maximize MI between each layer’s input and output. Thus GIM reframes learning as a self-supervised compression problem. Unlike earlier MI-based approaches, it optimizes each layer separately.
How it works: GIM works on modular networks, in which each layer learns to extract features from its input and passes its output to the next available layer, and so on down to the final layer. GIM doesn’t require labels, but if they’re available, a linear classification model can learn from GIM’s compressed output in a supervised manner.
- GIM uses the previous layer’s output as the next layer’s input to train each layer independently. This differs from the usual backpropagation in which all layers learn at once.
- The researchers devised a task that teaches layers to extract features that maximize MI. Given a subsequence of input data that has been compressed according to the current weights, the layer predicts the next element in the compressed sequence, choosing from a random selection drawn from the input including the correct choice. High success demonstrates that the layer is able to compress the input.
- The process effectively removes redundancy between nearby regions of the input. For example, a recording of a song’s chorus may repeat several times, so it’s possible to represent the recording without capturing the repetitions.
Results: The researchers pitted Greedy InfoMax against contrastive predictive coding. In image classification, GIM beat CPC by 1.4 percent, achieving 81.9 percent accuracy. In a voice identification task, GIM underperformed CPC by 0.2 percent, scoring 99.4 percent accuracy. GIM’s scores are state-of-the-art for models based on mutual information.
Why it matters: Backprop requires storing forward prediction, backward gradients, and weights for an entire network simultaneously. InfoMax handles each layer individually, making it possible to accommodate much larger models in limited memory.
Behind the news: Layerwise training or pre-training has been around for at least a decade. For example, stacked autoencoders use reconstruction error as an alternative unsupervised mechanism to control intelligent data compression. Many past approaches are more focused on pre-training and assume that, once each layer has been trained individually, they will be trained together with a supervised task.
We’re thinking: Many machine learning applications use a large pretrained network as an initial feature extractor and then apply transfer learning. By maximizing MI between layers, this approach could use more data to train and build still larger networks.
Steal Your Face
What if you could identify just about anyone from a photo? A controversial startup is making this possible.
What happened: Hundreds of U.S. law enforcement agencies are using a face ID service that matches photos against a database of billions of images, the New York Times reported.
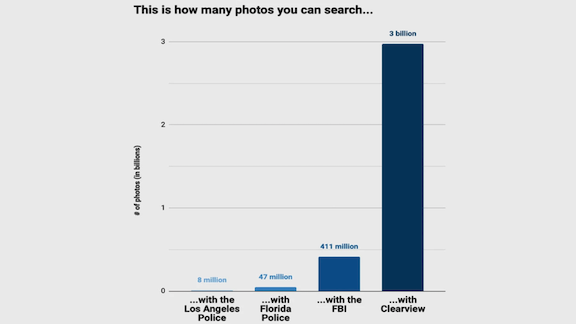
How it works: Clearview AI scraped photos from Facebook and other social media sites, employment sites, mugshot archives, news sites, and message boards. The company’s promotional materials say it holds over 3 billion images, a repository far bigger than law-enforcement databases, as shown in the image above.
- The company trained a neural network to convert faces into geometric vectors representing the distance between a person’s eyebrows, the angle of the cheekbones, and so on.
- The network compares such vectors in a submitted photo with those in the database and returns matching photos along with the URLs they came from. Frequently these are on social-media pages, making it possible to connect a name to the face.
- More than 600 U.S. law enforcement agencies have licensed the application, which has been used to investigate crimes from shoplifting to murder. The company also contracts with corporate customers.
Behind the news: Clearview AI was founded in 2016 by an Australian programmer with backing from tech investor Peter Thiel. The company has raised $7 million, according to the funding tracker Pitchbook.
Yes, but: The New York Times outlines a number of concerns.
- Scraping photos violates terms of service for most social media companies, including Facebook, Instagram, and Twitter.
- Some experts worry the service invites misuse. “Imagine a rogue law enforcement officer who wants to stalk potential romantic partners,” one expert said.
- Clearview AI doesn’t report an error rate. The model could make false matches, putting innocent people in jeopardy.
We’re thinking: We need regulations that balance development and deployment of useful technologies against their potential for abuse and harm. Face identification vendors should be required to report performance metrics, and police departments should be required to use models that pass federally established guidelines and perform background checks of personnel who have access to the technology.
A MESSAGE FROM DEEPLEARNING.AI

Get your model running on iOS and Android devices. Take the first step in Course 2 of the TensorFlow: Data and Deployment Specialization. Enroll now

HR’s Robot Helper
For some college graduates, landing a first job means making a good impression on a chatbot.
What’s new: University guidance counselors around the U.S. are preparing students for interviews with AI-powered screening algorithms, according to CNN.
How it works: Companies like Yobs and HireVue filter candidates for hundreds of corporate customers. Applicants submit videos of themselves answering pre-determined questions. The software then rates their language skills as well as non-verbal elements like tone, pitch, and emotional tenor. HireVue also evaluates body language and facial expressions.
- Acing an interview with an algorithm requires updating age-old social skills, like making eye contact with a laptop camera and making sure the computer’s speakers hear your upbeat, confident tone of voice.
- Software company Big Interview is developing an AI-scoring system to help prepare students for interviews with bots. Yobs offers a similar service.
Yes, but: Training job hunters to look at the camera and project confidence is a good idea whether they’re talking to a bot or a human being. But critics question whether current AI is capable of reliably matching verbal or body language with traits that make for a good hire. Princeton University computer science professor Arvind Narayanan called AI applicant-screening programs “elaborate random number generators” in a talk last year.
Why it matters: Millions of college graduates enter the global job market every year. Good AI could help hiring managers pluck the most qualified candidates from a deluge of resumes. Bad AI could knock many great applicants out of the running.
We’re thinking: AI screening systems still need to prove themselves effective and reasonably bias-free. Meanwhile, we welcome tools that can improve, at scale, job opportunities for deserving individuals who otherwise might not hear from a recruiter.
Upgrading Softmax
Softmax commonly computes probabilities in a classifier’s output layer. But softmax isn’t always accurate in complex tasks — say, in a natural-language task, when the length of word vectors is much smaller than the number of words in the vocabulary. A new function renders more accurate predictions with lower computational cost than earlier alternatives.
What’s new: Zhilin Yang, Thang Luong, and Ruslan Salakhutdinov at Carnegie Mellon University, with Quoc Le at Google Brain, developed an efficient solution to the so-called softmax bottleneck: Mixtape.
Key insight: A previous proposal, Mixture of Softmaxes, (MoS) is a weighted sum of multiple softmaxes, and thus slow to train. Mixtape reformulates MoS as a single softmax of weighted sums. With a clever way of calculating the weights, that rearrangement avoids the bottleneck with much speedier execution.
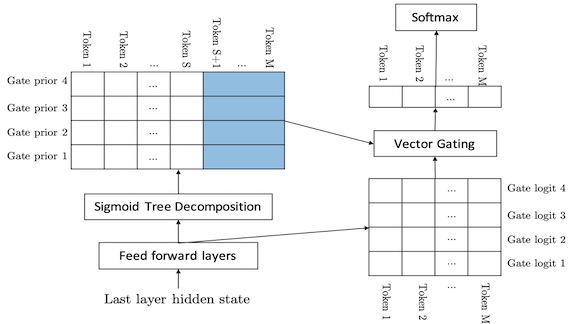
How it works: Mixtape’s weighted sum depends on the word it is evaluating — a not-so-obvious way to formulate the problem. The weights must be generated efficiently to avoid losing the computational advantage over MoS.
- Mixtape calculates weights for the weighted sum using a sigmoid tree decomposition. The sigmoid tree is a binary tree in which each node is a sigmoid. The tree’s leaves provide the weights. This is more efficient than using a softmax to calculate weights.
- Some of the weights are shared among infrequent output classes, which further boosts efficiency.
- This sharing does create potential for a bottleneck, but far less, and with less inaccuracy, than softmax.
Results: The researchers compared transformer-based models with output layers employing Mixtape, MoS-15, or softmax. The tasks included recreating a text sample and translating a sentence from English to German or French. On text generation, MoS-15 (which entails 15 softmax calculations) and Mixtape improved perplexity — a measure of the model’s predictive certainty — by around 3, achieving a score of 56. MoS-15 slightly outperformed Mixtape. However, Mixtape required only slightly more training time than softmax, whereas MoS-15 required twice as long.
Why it matters: Much research has focused on extracting meaningful features of input, but features are less useful if the output layer can’t classify them properly. Mixtape should allow models to take better advantage of features they extract without sacrificing AWS credits.
We’re thinking: Mixtape can do better than softmax with only a little more training time. We may see Mixtape overtake softmax in some applications.

Bad Recommendations
YouTube is a great place to learn about new ideas — including some that have been thoroughly discredited.
What’s new: YouTube’s recommendation algorithm is helping spread misinformation about climate change, according to research by Avaaz, a self-funded activist group.
What they found: The researchers aimed to learn which videos YouTube was likely to feature in its “Up next” recommendations for videos resulting from three searches: “climate change,” “global warming,” and the more skeptical phrase “climate manipulation.” Working between August and December, they entered the search terms into a YouTube service that lists related videos. Then they used a data visualization tool to find the 100 most likely recommendations.
- The researchers watched the videos and flagged as “misinformation” those that contradict scientific consensus according to the Intergovernmental Panel on Climate Change, U.S. government agencies, and peer-reviewed research.
- For videos returned by searches on “climate change” and “global warming,” the percentage of recommendations containing misinformation were 8 and 16 percent respectively. For videos returned by a search on “climate misinformation,” the number was 21 percent.
- Ads by organizations like the World Wildlife Federation as well as major advertisers like L’Oreal and Warner Bros. often accompany videos that contradict scientific findings.
- The report’s proposals include giving advertisers the ability to stop their ads from running alongside misleading videos, limiting algorithmic recommendation of such videos, and making YouTube’s internal data on recommendations available to independent researchers.
The response: YouTube defended its recommendation software and questioned the study’s methodology. It pointed out that it displays a link to Wikipedia’s “Global Warming” page under many climate-related videos.
Behind the news: In June, YouTube overhauled its algorithms to give users more control over recommendations. Those changes cut the time viewers spent watching such content by 70 percent. The move followed earlier efforts to block videos espousing miracle cures or conspiracy theories.
Why it matters: YouTube’s recommendations are a potent force for spreading information (and misinformation). They were credited with driving around 70 percent of the site’s viewing time in 2018.
We’re thinking: It’s great to see YouTube and other companies working to reduce misinformation. But the AI community’s work is far from done. We need incentive mechanisms that don’t just reward numbers of views, but shift incentives toward distributing factual information and rational perspective to the extent they can be determined fairly.