
Dear friends,
I’ve always believed in democratizing access to the latest advances in artificial intelligence. As a step in this direction, we just launched “Generative AI for Everyone” on Coursera. The course assumes no programming or AI background, and I hope it will be useful to students, teachers, artists, scientists, engineers, leaders in business and government, and anyone else who simply wants to know how to apply generative AI in their work or personal life. Please check it out and encourage your friends to take a look, especially those with a nontechnical background.
Just as web search and word processing have become essential skills in the workplace, using generative AI soon will become a baseline skill set expected by every employer. This highly accessible, general-purpose technology is suitable for numerous tasks. It’s already used in copyediting, customer service, brainstorming, summarizing documents, and more. And many more uses are yet to be identified.
The course covers:
- How generative AI (particularly large language models, or LLMs) works, and what it can and cannot do
- A nontechnical description of advanced techniques, including RAG (retrieval augmented generation, which gives an LLM access to additional, proprietary information) and fine-tuning, and when to use these techniques
- Best practices for the use of LLMs, either via a web interface (such as ChatGPT or BARD) or by incorporating them into a larger application (such as software that calls an LLM API)
- How to identify opportunities for AI augmentation or automation by breaking down jobs into tasks and evaluating their potential for automation — I described this in a previous letter, but the course goes into greater detail and explains how this can bring cost savings and revenue growth
- Responsible AI and generative AI’s impact on jobs and society

If you’re an engineer: I designed this course to be accessible to nontechnical professionals partly to help technical people work with them more easily. With earlier waves of technology, I found that the gap in understanding between technical and nontechnical people got in the way of putting the technology to use. So if you already have a good understanding of generative AI, please encourage your nontechnical colleagues to take this course. They will learn a lot, and I hope this will help you collaborate more productively!
You can check out the course here.
Keep learning!
Andrew
News

White House Moves to Regulate AI
U.S. President Biden announced directives that control AI based on his legal power to promote national defense and respond to national emergencies.
What’s new: The White House issued an executive order that requires AI companies and institutions to report and test certain models and directs federal agencies to set standards for AI. The order follows a six-month process of consultation with the AI community and other stakeholders.
How it works: The executive order interprets existing law — specifically the Cold War-era Defense Production Act, a Cold War-era law that gives the president powers to promote national defense and respond to emergencies — and thus can be implemented without further legislation. It focuses on foundation models, or general-purpose models that can be fine-tuned for specific tasks:
- Safety: Developers must notify the government when they train a model whose processing budget exceeds 1026 integer or floating-point operations, which corresponds roughly to 1 trillion parameters, with a lower limit for training on biological sequences. (These are preliminary values to be updated regularly.) In addition, developers must watermark generated outputs and share results of safety tests conducted by so-called red teams.
- Privacy: The federal government will support tools to protect users’ privacy and evaluate AI developers’ collection of personal information. The order calls on Congress to pass comprehensive data-privacy legislation, reflecting the president’s limited power in this area.
- Civil rights: Federal administrators of benefits, contractors, and landlords are barred from using algorithms to discriminate against members of protected groups. The Department of Justice and civil rights offices of various government agencies will set best practices for the use of AI in criminal justice and civil rights investigations.
- Competitiveness: A new National AI Research Resource will support researchers with processing power, data, tools, and expertise. The Federal Trade Commission will assist small business owners in commercializing AI developments. Immigration authorities will lower barriers to workers with expertise in critical areas like software engineering.
- Global leadership: The administration will work with other countries and nongovernmental organizations to set international standards for safety and risk management as well as an agenda for applying AI to solve global problems.
Behind the news: The executive order was long in the making and joins other nations’ moves to limit AI.
- In May, the White House met with the CEOs of Alphabet, Anthropic, Microsoft, and OpenAI, to consult with those companies and urge them to adopt actions consistent with the administration’s AI Bill of Rights and Risk Management Framework.
- The following month, President Biden convened a summit with AI researchers and announced a public working group on AI.
- In July, the White House reached voluntary agreements with 7 AI companies to follow administration guidelines.
- This week, an international roster of regulators, researchers, businesses, and lobbyists convene for the UK’s global summit on AI safety. China already has imposed restrictions on face recognition and synthetic media, and the European Union’s upcoming AI Act is expected to restrict models and applications deemed high-risk.
Why it matters: While Europe and China move aggressively to control specific uses and models, the White House seeks to balance innovation against risk, specifically with regard to national defense but also social issues like discrimination and privacy. The executive order organizes the federal bureaucracy to grapple with the challenges of AI and prepares the way for national legislation.
We’re thinking: We need laws to ensure that AI is safe, fair, and transparent, and the executive order has much good in it. But it’s also problematic in fundamental ways. For instance, foundation models are the wrong focus. Burdening basic technology development with reporting and standards places a drag on innovation. It makes more sense to regulate applications that carry known risks, such as underwriting tools, healthcare devices, and autonomous vehicles. We welcome regulations that promote responsible AI and look forward to legislation that limits risks without hampering innovation.
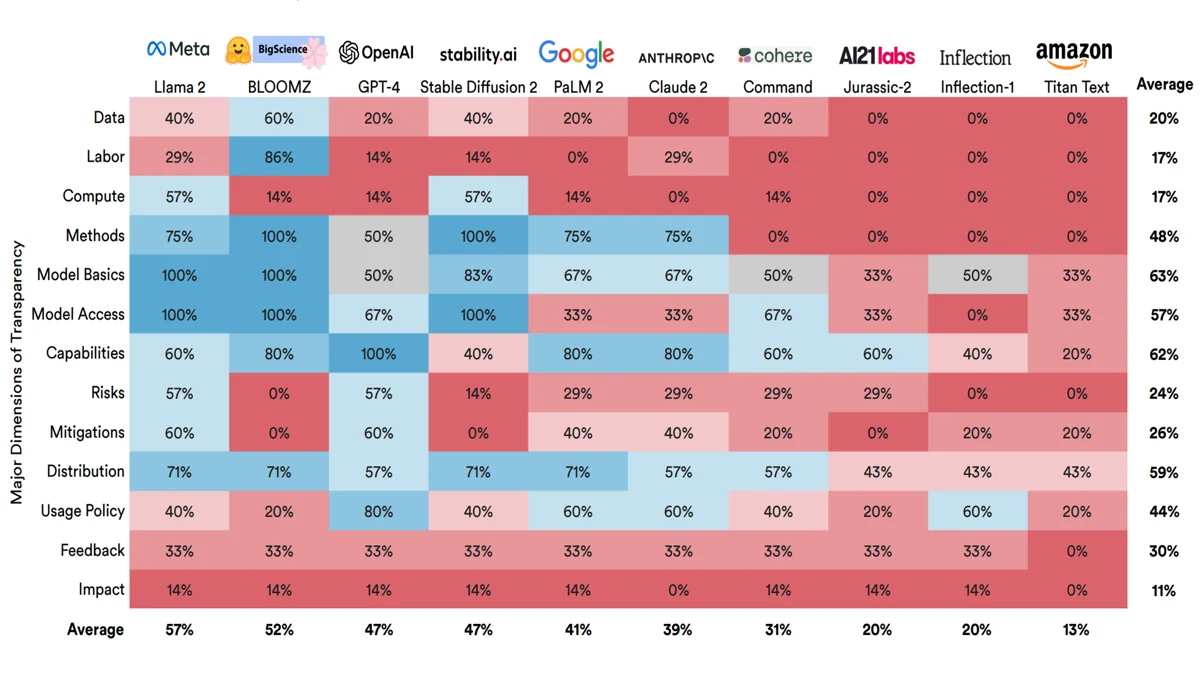
What We Know — and Don’t Know — About Foundation Models
A new index ranks popular AI models in terms of information their developers provide about their training, architecture, and usage. Few score well.
What’s new: The Stanford Center for Research on Foundation Models published its debut Foundation Model Transparency Index, scoring 10 popular models on how well their makers disclosed details of their training, characteristics, and use.
How it works: Rishi Bommasani, Kevin Klyman, and colleagues at Stanford, MIT, and Princeton examined 10 foundation models — that is, models that can be pretrained for general purposes and fine-tuned for specific tasks — from 10 companies. They scored each model by asking 100 yes-or-no questions that covered training, model architecture and behavior, and policies regarding access and usage.
- Training: Roughly one-third of the questions asked questions related to training, like whether factors like processing, hardware, and training data used to build the model are disclosed. They also asked whether external parties have access to the dataset and whether steps were taken to protect data privacy or intellectual property.
- Architecture and behavior: Around one-third of the questions enquired about the trained model, such as whether a developer disclosed details about a model’s architecture, capabilities, and limitations. They also asked whether independent researchers were able to test the model and evaluate its risks and trustworthiness.
- Access and usage: The final third of the questions asked about how the model can be used, including whether the model is available to all prospective users, whether restrictions apply to such uses, and whether use requires an explicit license. They also gauged whether users are notified that they’re interacting with an AI model, whether user data is stored, whether a log of versions is provided, and whether a list of applications based on the model is available.
Results: The index assigned each model a score between 1 and 100. Meta’s Llama 2 ranked most transparent with a score of 54. BigScience’s BLOOM-Z came in just behind with a score of 53. At the bottom of the list were Inflection’s Inflection-1, which scored 21, and Amazon’s Titan Text, which scored 12.
- Three of the four highest-scoring models — Llama 2, BLOOMZ, and Stability.AI’s Stable Diffusion 2 — were released with model weights. Meanwhile, the six lowest-scoring models were closed models.
- On average, the models showed the greatest transparency with respect to access and usage. They were least transparent with respect to training.
- Transparency ratings did not correlate with company size. For instance, the top spots were occupied by Llama 2 from the giant Meta and BLOOMZ from BigScience, a much smaller organization.
Yes, but: Because the index is limited to yes/no questions, it doesn’t allow for partial credit. In addition, the questions are weighted equally, so lack of transparency in an important area (say, access to training data) costs only one point in a model’s overall score. It’s easy to imagine companies gaming the scores rather than addressing the most meaningful deficits.
Behind the news: Researchers at MIT, Cohere For AI, and 11 other organizations recently launched the Data Provenance Platform, a project that audits and categorizes training datasets. The effort offers a Data Provenance Explorer for evaluating sources, licenses, creators, and other metadata with respect to roughly 1,800 text datasets.
Why it matters: AI has a transparency problem, and the rise of models that serve as foundations for other models exacerbates the issue. Without disclosure of fundamental factors like architectures, datasets, and training methods, it’s impossible to replicate research, evaluate cost per performance, and address biases. Without disclosure of applications based on a given foundation model, it’s impossible to weigh those applications’ capabilities and limitations. A consistent set of criteria for evaluating transparency may encourage greater disclosure.
We’re thinking: The rise of open source AI has been accompanied by an opposite rise in commercial concerns that have little incentive to reveal the inner workings of their models. An index encourages everyone to provide detailed information about the systems they build, and we hope it will help engineers who care about transparency to persuade their teammates. We look forward to refinements and expansion to cover models that aren’t included among the initial 10.
A MESSAGE FROM DEEPLEARNING.AI

Andrew Ng’s new course, “Generative AI for Everyone,” is live on Coursera! Learn how to use generative AI in your life and work, what this technology can (and can’t) do, and how to put it to use in the real world. Enroll today to get started!

Cruise Control
The state of California pulled the parking brake on Cruise driverless vehicles.
What’s new: The California Department of Motor Vehicles (DMV) suspended Cruise’s permit to operate vehicles in the state without safety drivers. The General Motors subsidiary responded by halting its robotaxi operations across the United States.
How it works: The California DMV acted following an early October incident in San Francisco. A Cruise driverless car struck and trapped a pedestrian who had been thrown into its path by a separate hit-and-run.
- The California DMV concluded that “Cruise's vehicles may lack the ability to respond in a safe and appropriate manner during incidents involving a pedestrian."
- Cruise initially failed to provide a complete video record of the incident, the agency said. A Cruise spokesperson responded in a statement to the press that the company had shared this material proactively and swiftly.
- The department gave Cruise five days to appeal the suspension. Instead, Cruise voluntarily suspended operations across the U.S. Previously, Cruise had deployed robotaxis without safety drivers throughout San Francisco, California, and in limited areas of Phoenix, Arizona; Austin, Texas; and Houston, Texas.
- Cruise said it would continue to test self-driving vehicles with safety drivers onboard.
Behind the news: Cruise’s deployment of driverless taxis in San Francisco has been troubled.
- In August, the California Public Utilities Commission — a different California government agency — authorized Cruise and Google’s self-driving subsidiary Waymo to charge for driverless taxi rides throughout San Francisco around the clock. Days after receiving the permit, a Cruise taxi struck a San Francisco emergency vehicle. The California DMV ordered Cruise to reduce its fleet by half.
- In April, a Cruise vehicle rear-ended a San Francisco city bus. The company responded by issuing a software update.
- San Francisco residents repeatedly have reported Cruise cars stalled in city streets.
- In December 2022, the National Highway Traffic Safety Administration — a U.S. federal agency — opened a probe (which is ongoing) into reports that Cruise cars caused accidents by braking abruptly. Last month, the agency started a second investigation into the vehicles’ risk to pedestrians.
Why it matters: Cruise’s latest trouble is a serious setback not just for GM, but for the self-driving car industry, which has been criticized for overpromising and underdelivering. The California DMV’s act has energized politicians, activists, and other public figures who oppose driverless taxis.
We’re thinking: The AI community must lean into transparency to inspire the public’s trust. California determined that Cruise was not fully forthcoming about its role in the incident — a serious breach of that trust. Voluntary suspension of operations is a welcome step toward restoring it. We hope the company takes the opportunity to conduct a comprehensive review.

Synthetic Data Helps Image Generators
Text-to-image generators often miss details in text prompts, and sometimes they misunderstand parts of a prompt entirely. Synthetic captions can help them follow prompts more closely.
What’s new: James Betker, Gabriel Goh, Li Jing, and Aditya Ramesh at OpenAI, along with colleagues at Microsoft, improved a latent diffusion model’s performance by training it on an image-caption dataset including model-generated captions that were more detailed than those typically scraped from the web. They used the same technique to train DALL·E 3, the latest version of OpenAI’s text-to-image generator.
Key insight: Text-to image generators learn about the relationships between images and their descriptions from datasets of paired images and captions. The captions in typical image-caption datasets are limited to general descriptions of image subjects, with few details about the subjects and little information about their surroundings, image style, and so on. This makes models trained on them relatively insensitive to elaborate prompts. However, language models can generate captions in great detail. Training on more-detailed synthetic captions can give an image generator a richer knowledge of the correspondence between words and pictures.
How it works: Rather than reveal details about DALL·E 3’s architecture and training, the authors describe training a latent diffusion model.
- The authors trained a transformer language model on an unspecified dataset of image-caption pairs. The transformer learned to generate typical captions from image embeddings produced by CLIP.
- To enable the language model to produce more elaborate captions, they fine-tuned it on a smaller, handmade dataset in which the captions described in detail subjects, surroundings, backgrounds, colors, styles, and so on.
- Using the fine-tuned language model, authors generated synthetic captions for 95 percent of 1 billion images from an unspecified image-caption dataset. They retained 5 percent of the original human-made captions.
Results: The authors trained separate latent diffusion models on datasets containing 95 percent generated captions and 100 percent human-made captions. They used the models to generate 50,000 images each and used OpenAI’s CLIP to calculate a similarity score (higher is better) between the prompts and generated images. The model trained on synthetic captions achieved 27.1 CLIP similarity, while a model trained on human-made captions achieved 26.8 CLIP similarity.
Testing DALL·E 3: The authors also tested human responses to images generated by DALL·E 3, Midjourney 5.2, and Stable Diffusion XL v1.0. Shown images based on 170 prompts selected by the authors, human judges found DALL·E 3’s output more true to the prompt and more appealing. Shown images based on 250 captions chosen at random from MSCOCO, they found DALL·E 3’s output most realistic. In a similar test, DALL·E 3 achieved a higher score on the Drawbench dataset than Stable Diffusion XL v1.0 and DALL-E 2. (No word on how DALL·E 3 compared to Midjourney in this experiment.)
Why it matters: Synthetic data is used increasingly to train machine learning models. The market research firm Gartner says that output from generative models will constitute 60 percent of data used in AI development by 2024. While synthetic data has been shown to boost performance in typical training methods, recursively training one model on another model’s output can distort the trained model’s output distribution — a scenario that could manifest over time as more models trained on synthetic data are used to generate data to train subsequent models.
We’re thinking: Using one AI model to help another to learn seems to be an emerging design pattern. For example, reinforcement learning from AI feedback (RLAIF) uses AI to rate output from large language models, rather than reinforcement learning from human feedback (RLHF). It’s a fair bet that we’ll see many more techniques along this line.
A MESSAGE FROM LANDING AI

Learn how to identify and scope vision applications, choose a project type and model, apply data-centric AI, and develop an MLOps pipeline in “Building Computer Vision Applications” with Andrew Ng. Join us on Monday, November 6, 2023, at 10 a.m. Pacific Time. Register here
Data Points
A Google multimodal app generator is in the works, according to leaked information
The application, called Stubbs, reportedly generates complete apps with functional code and may be powered by the Gemini LLM or an even more advanced system. Its potential to handle text, images, code, and structured content, while providing various output previews, could introduce a new era of multimodal capabilities. (Bedros Pamboukian’s Medium blog)
Research: An analysis of the changing legal terrain of synthetic data
Researchers examine the legal challenges arising from the growing usage of synthetic data. artificially generated data disrupts the balance between utility, privacy, and human rights enshrined in existing laws. The authors call for legal reforms to address the unique dynamics of synthetic data. (SSRN)
Economist built an interactive book on economics using GPT-4
Tyler Cowen, an economics professor and author of economics blog Marginal Revolution, launched a generative book. The project, called GOAT: “Who is the Greatest Economist of all Time, and Why Does it Matter?” offers readers an interactive experience, allowing them to query, rewrite, and customize its content. The book also provides insights into the work and lives of prominent economists like Adam Smith and John Stuart Mill. (Marginal Revolution)
Search engine You.com now allows personalization on its AI assistant
"Smart Learn," the platform’s AI assistant, now adapts to users' preferences and habits over time. Smart Learn promises to improve response quality while respecting privacy and allowing users to control their personalization settings. The feature is currently in beta for YouPro members, and early access is available. (You.com)
Nvidia reports that the U.S. ordered sudden restrictions on AI chip exports to China
Originally slated to take effect November 16, the measures are part of Joe Biden's administration's efforts to prevent countries like China, Iran, and Russia from acquiring high-end AI chips designed by Nvidia and other manufacturers. While Nvidia has not disclosed the reason for the expedited timeline, it assured investors that global demand remained strong and the accelerated licensing requirements were not expected to significantly impact its near-term financial results. (BBC)
Research: Researchers use machine learning to detect urban decay and improve city planning
Scientists from the University of Notre Dame and Stanford University built a scalable method for measuring urban decay. Traditional methods of evaluating urban quality involve sociodemographic and economic characteristics, but these new techniques employ AI and street view images to identify objects like potholes, garbage, graffiti, and broken windows. The goal of the research is to gauge the condition of urban areas and better inform urban policy and planning. (University of Notre Dame)
Negotiations over the European Union’s AI Act reach their final stages
The EU institutions, including the Council, Parliament, and Commission, have tackled high-risk AI applications' classification and supervision of models. However, negotiations on prohibitions and law enforcement are still pending. The focus will now shift to the upcoming trilogue on December 6, where a political agreement is anticipated, although not guaranteed. Additionally, nine technical meetings are scheduled to address complex aspects of the AI law. (Euractiv)
Research: Study reveals prevalence of sycophancy in AI assistants' responses
Sycophancy refers to AI models favoring responses that align with user beliefs over truthful ones. The research found consistent sycophantic tendencies across multiple text-generation tasks in five AI assistants. The study further revealed that both human evaluators and preference models often prefer sycophantic responses, sometimes at the cost of accuracy. (Arxiv)
OpenAI, Anthropic, Google, and Microsoft establish $10 million AI safety fund
Leading companies in the AI field appointed Chris Meserole, formerly of the Brookings Institute, as Executive Director of the Frontier Model Forum. This industry body aims to ensure the safe and responsible development of advanced AI models globally. They also created an AI Safety Fund, committing over $10 million to support AI safety research. The fund will back independent researchers, prioritizing model evaluation to enhance AI system safety. (OpenAI)
Research: Researchers trained a neural network to enhance Wikipedia’s credibility
Researchers developed a system called "SIDE" to bolster Wikipedia's verifiability by identifying citations that might not adequately support their claims and recommending better alternatives from the web. This neural network-based system, trained on existing Wikipedia references, showed promising results, with human testers preferring SIDE's recommendations to the originally cited references in 70% of cases. Additionally, a demo within the English-speaking Wikipedia community revealed that SIDE's first citation recommendation was twice as likely to be preferred for the top 10% of claims most likely to be unverifiable. (Nature)