
Dear friends,
Andrej Karpathy, one of the Heroes of Deep Learning who currently works at OpenAI, quipped, “The hottest programming language is English.” While I appreciate the sentiment, I don’t want the ease of instructing computers in English to discourage anyone from learning to code. Someone who is multilingual — who perhaps speaks English as a first language and Python as a second language — can accomplish much more than someone who knows only how to prompt a large language model (LLM).
It’s increasingly possible to tell a computer what you want in English (or whatever human language you’re most fluent in) and it will understand well enough to give you what you asked for. Even before LLMs, Siri and Alexa could respond to basic commands, and the space of English instructions that computers can follow is rapidly expanding. But coding is still immensely valuable. If anything, with the advent of LLMs, the value of coding is rising. Let me explain why.
Today, almost everyone has data: big companies, small companies, and even high school students running biology experiments. Thus, the ability to get a custom AI system to work on your own data is valuable. And while prompting an LLM can produce answers for a huge range of questions and generate everything from essays to poems, the set of things you can do with coding plus prompting is significantly larger, for now and the near future.
Let’s say I want a summary of every letter I’ve ever written in The Batch. I can copy-paste one letter at a time into an LLM like ChatGPT and ask for a summary of each, but it would be much more efficient for me to write a simple piece of code that iterates over all letters in a database and prompts an LLM to create summaries.

In the future, I hope recruiters will be able to write a few lines of code to summarize candidate reviews, run speech recognition on conversations with references, or execute whatever custom steps are needed in the recruiting workflow. I hope teachers will be able to prompt an LLM to generate learning tasks suited to their lesson plan, and so on. For many roles, coding + prompting will be more powerful than prompting via a web interface alone.
Furthermore, English is ambiguous. This contributes to why an LLM’s output in response to a prompt isn’t fully predictable. In contrast, most programming languages are unambiguous, so when you run a piece of code, you reliably (within reason) get back the same result each time. For important applications where reliability is important — say, deciding when to purchase an expensive plane ticket based on real-time prices, or sending a party invitation to everyone in your company — it’s safer to use code to carry out the final step committing to the action, even if an LLM were involved in researching destinations or drafting the invitation.
I believe we’re entering an era when everyone can benefit by learning to code. LLMs have made it more valuable than ever. Writing code that calls an LLM has made it easier to build intelligent applications than it was before LLM APIs became widely available. Specifically, everyone can benefit by learning to code AI applications, as I wrote with Andrea Pasinetti, CEO of Kira Learning, an AI Fund portfolio company.
If you don’t yet code, consider taking a Python course to get started. If you already code, I hope you will encourage others to take up this skill. This is a good time to help everyone learn to speak Python as a second language!
Keep learning,
Andrew
News

U.S. Film Industry Limits AI
Screenwriters and movie studios reached a landmark agreement that restricts uses of AI to produce scripts for television and movies.
What’s new: The Writers Guild of America (WGA) negotiated a new three-year contract with the Alliance of Motion Picture and Television Producers (AMPTP), ending a strike that began in May. The contract allows both writers and studios to use AI within certain restrictions.
How it works: WGA members went on strike partly over concern that studios would use AI to replace screenwriters. The contract incorporates many of their demands.
- Writers hired by studios can use AI tools as writing aids with the studio’s consent. They can't be required to use text generators, but they must follow studio guidelines for using such tools.
- If a studio asks a writer to refine a model's output, it can’t reduce the writer’s compensation or credit and it must declare that AI created the output. It can't give AI credit for stories or writing. If a studio uses a large language model to generate a story idea or draft and screenwriters turn it into a final script, the studio can’t retain rights to the generated work.
- Studios can train machine learning models on a writer’s work. (This provision was motivated at least partly by studios’ worry that tech giants like Amazon and Netflix, with whom they compete, are training screenwriting models on existing scripts.)
- Because generative technology is rapidly developing, the writers' union retains the right to claim studios’ use of future technology violates the agreement.
The actors’ strike continues: In July, the Screen Actors Guild (SAG-AFTRA) also went on strike citing similar concerns. Many actors fear that studios will use generated replicas of performers, undercutting their compensation and credits.
- On Monday, the actors’ union began formal negotiations with the studios.
- Studio representatives informally proposed allowing studios to use AI-generated likenesses with an actor’s consent. The actors’ union argues that less-renowned performers might be pressured to consent, enabling studios to use their likenesses indefinitely.
- Some actors have licensed their voices and likenesses to producers (including studios) for digital doubles. The union aims to control this practice.
Why it matters: The writers’ agreement is a landmark deal in a high-profile industry. It could serve as a template not only for actors but also workers in other creative industries including publishing, music, graphics, gaming, and software development.
We’re thinking: Generative AI is making many industries and individuals more productive. The new contract protects writers for three years while leaving space for both writers and studios to experiment with ways to do that in film and television. We hope that this agreement is followed by one that focuses on growing the pie — creating more great movies with less effort — while addressing how to divide the larger pie fairly among writers, studios, and technologists.

Amazon and Anthropic Form Alliance
Amazon cut a multi billion-dollar deal with AI startup Anthropic, giving it a powerful ally in the generative arms race.
What’s new: Amazon committed to investing as much as $4 billion in Anthropic. In return, Amazon Web Services (AWS) became the primary provider of Anthropic’s Claude and other models.
How it works: Amazon will invest $1.25 billion in Anthropic immediately. Amazon may invest an additional $2.75 billion depending on undisclosed conditions. Amazon gained an undisclosed minority stake in the startup but not a seat on the board of directors. Other terms were not disclosed.
- Anthropic, whose Claude and Claude 2 large language models became available on AWS’ Bedrock foundation-model service in April and July, agreed to expand its offerings.
- Amazon developers will be able to incorporate Anthropic models into their work, and Anthropic will share its expertise in AI safety.
- AWS customers will have early access to customized, private, and fine-tuned versions of future Anthropic models.
- AWS will replace Google as Anthropic’s primary cloud provider. Anthropic will spend an unspecified sum on AWS and use Amazon’s Trainium and Inferentia chips, which are optimized to process transformer architectures.
Behind the news: Founded in 2021 by ex-OpenAI employees, Anthropic is an independent research lab that focuses on building safe, beneficial AI models. Having received hundreds of millions of dollars from Google and other investors, it became one of the industry’s most highly funded startups. It was valued at $4.1 billion in March.
- Anthropic trained Claude using a process called constitutional AI that asks a model to critique its own output according to a constitution, or set of principles, and suggest revisions that align better with those principles. Claude’s constitution incorporates principles drawn from the United Nations Declaration of Human Rights and Apple’s data-privacy policy.
- In July, Anthropic joined Google, Microsoft, and OpenAI to form the Frontier Model Forum, an industry body that promotes responsible AI.
Why it matters: Competition around generative AI is white-hot. Cloud providers need to offer cutting-edge models, while AI startups need access to processing power. Microsoft Azure paired up with OpenAI. Google has strong internal generative capabilities. That leaves Amazon as a natural partner for Anthropic.
We’re thinking: Which other high-profile AI startups would make dance partners for enterprising cloud providers? Topping the list are AI21 Labs (already working with Amazon Bedrock), Cohere (also available on Bedrock), and Inflection (funded by Microsoft).
A MESSAGE FROM DEEPLEARNING.AI

Learn the best practices for finetuning large language models and customize them with real-world data sets in our short course, “Finetuning Large Language Models.” Enroll for free

Video Sharing Goes Generative
YouTube is reinventing itself for the era of generative AI.
What’s new: The Google-owned video platform is adding generated topic ideas, backgrounds, music suggestions, and audio translations. These capabilities will be available in late 2023 or early 2024.
How it works: The new features are designed to assist video producers in planning, designing, and publishing their works.
- A model called AI Insights for Creators recommends potential topics and outlines based on a video maker’s past uploads and trending topics.
- The Dream Screen option generates images and short videos from prompts. Producers can incorporate its output into the backgrounds of TikTok-like YouTube Shorts.
- A tool based on Google’s Aloud translates spoken recordings from English into Spanish or Portuguese. The tool transcribes English audio, producing an editable text script. Then it translates the script and renders the audio in the desired language.
- Another model will recommend background music based on a text description of a video.
Meanwhile, at TikTok: YouTube rival TikTok requires users to clearly label synthetic videos that depict realistic scenes. The guidelines also prohibit synthetic likenesses of private individuals (public figures are allowed unless they are the subject of abuse or misinformation). To help contributors comply, the company announced a tool that enables uploaders to manually label their videos as “AI-generated.” TikTok is also testing a system that detects AI-generated or AI-edited elements in a video and automatically adds the label.
Why it matters: YouTube depends on crowdsourced content. Generative tools could make the platform’s contributors more productive, attracting more viewers and boosting revenue all around.
We’re thinking: While generative tools may engage the crowd, generated content that’s as compelling as human-produced content could upend YouTube’s business.
More Scraped Data, Greater Bias
How can we build large-scale language and vision models that don’t inherit social biases? Conventional wisdom suggests training on larger datasets, but research challenges this assumption.
What’s new: Abeba Birhane at Trinity College Dublin, a colleague at Michigan State University, and two independent researchers analyzed publicly available text-image datasets for their proportion of hateful content (that is, content that belittles based on race or gender) and audited models trained on them for racial bias. They found that larger training sets can push models toward greater bias.
Key insight: The largest available datasets of text and images are collected indiscriminately, with little curation after the fact. Removing objectionable material from such immense corpora is challenging. Researchers often rely on automatic filters like the CLIP similarity between images and text to filter out bad data. To create larger datasets, they often relax those filters. Consequently, larger datasets can harbor a higher proportion of objectionable material than smaller datasets, and training on them could yield models whose performance is more biased.
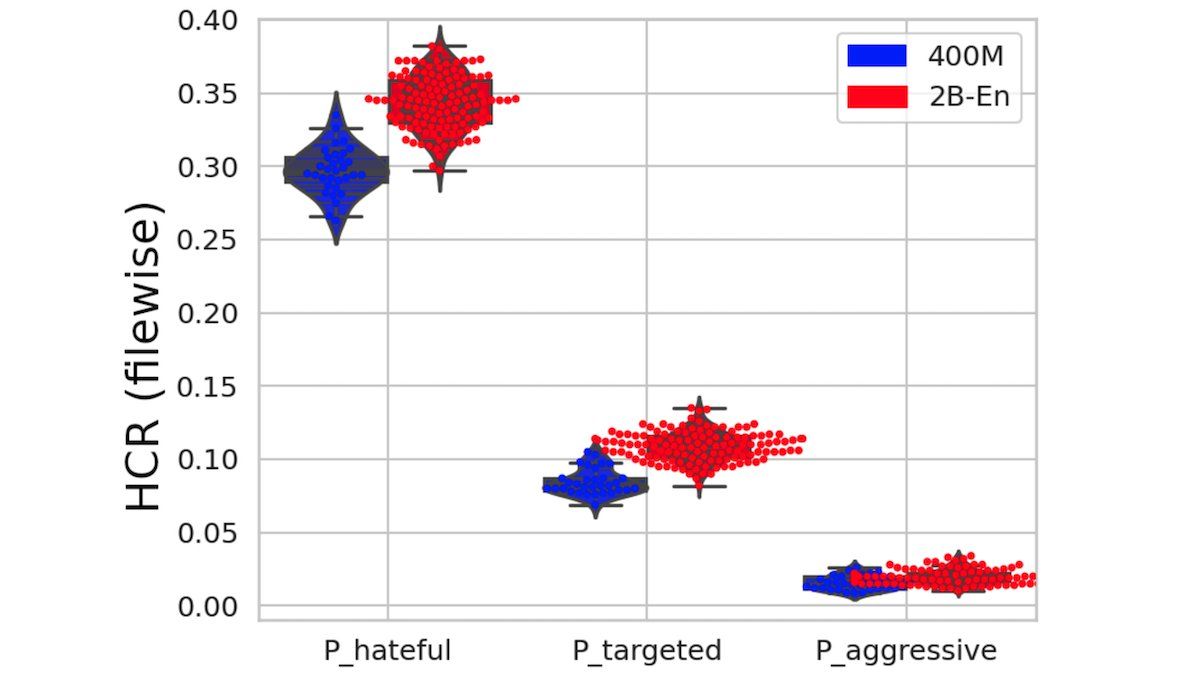
How it works: The authors compared hateful language in LAION 400M, which comprises 400 million image-text pairs scraped from the web, to similar data in LAION 2B-en, which includes 2 billion image-text pairs also scraped from the web. They also analyzed racial biases present in models trained on both datasets.
- To identify hateful language, the authors ran pysentimiento, a Python library for sentiment analysis, on the text of each text-image example to find the probability that it belonged to one of three categories: hateful, targeted (that is, hateful and aimed at a specific person or group), or aggressive. They assessed each dataset according to its Hate Content Rate (HCR), the proportion of examples whose probability of being hateful, targeted, or aggressive surpassed a threshold value.
- To compare racial bias, they trained identical OpenCLIP architectures on each dataset. Then they used the models to classify headshots of nearly 600 individuals along with their self-identified race and gender as eight classes that included “human being,” “gorilla,” “suspicious person,” and “criminal.” They evaluated the models’ bias based on the percentage of faces associated with a given race and gender they classified with a label other than “human being.”
Results: The authors found a statistically-significantly lower proportion of hateful content in the smaller dataset. LAION-400M’s HCR in the “hateful” category was up to 0.1 percent lower relative to LAION-2B. The probability that a model would classify a face as “human being” fell from 18.6 percent for OpenCLIP-400M to 9.4 percent for OpenCLIP-2B, and the probabilities of classification as “criminal” and “suspicious person” rose. OpenCLIP-400M classified a portrait of a black man as a criminal 14 percent of the time, while OpenCLIP-2B did so 77.4 percent of the time. Despite the increase in biased classifications, OpenCLIP-2B achieved 1.5 percent higher accuracy on ImageNet.
Why it matters: Increasing numbers of open source models and consumer-facing products are trained on large, web-scraped datasets. For example, Stable Diffusion was trained largely on the 5B version of LAION. This work throws up a red flag for machine learning practitioners to consider the bias such training can impart, the harm such models might do, and the methods used to collect and curate large datasets.
We’re thinking: This work goes to show that data-centric AI is applicable even to the largest datasets. It's easier to focus on higher-quality data sources when collecting 400 million examples than 2 billion examples.
Data Points
Google introduced a way for publishers to opt-out from training AI
The Google-Extended control setting allows website administrators to manage access to their data and other content. Now publishers can choose whether to contribute to the refinement of AI tools like Bard and Vertex AI. (Google)
IBM launched generative AI models and bolsters intellectual property protection
The company announced the general availability of the watsonx Granite model series, a collection of models designed to enhance generative AI integration into business operations, and the extension of standard intellectual property protections to all watsonx AI models. (IBM)
Google accidentally leaked Bard conversations in public search results
URLs linking to users’ interactions with Bard were indexed by Google's search engine, allowing anyone to access them. While some defended the incident by noting that individuals chose to share links to their chats with each other, others argued that users expected their exchanges to be private. Google acknowledged the issue to be an error. (Fast Company)
Getty Images released an image generator trained on licensed images
"Generative AI by Getty Images," a tool powered by NVIDIA and exclusively trained on Getty Images' creative content library, promises to ensure usage rights for AI-generated content, including royalty-free licenses, indemnification, and perpetual worldwide usage. (Getty)
Cloudflare introduced a set of tools for streamlined model deployment
The suite includes "Workers AI," which allows users to access nearby GPUs hosted by Cloudflare's partners for AI model execution on a pay-as-you-go basis, "Vectorize," which provides a database for storing vector embeddings generated by AI models, and "AI Gateway," which offers observability and cost management features for AI applications. (TechCrunch)
The European Central Bank (ECB) is experimenting with AI for basic operations
The ECB's pursuit of technological advancements also attempts to address concerns related to reliability, transparency, and legal implications associated with AI use. The institution is collaborating with other major central banks, including the Federal Reserve, the Bank of England, and the Monetary Authority of Singapore. (Financial Times)
The Central Intelligence Agency (CIA) developed its own chatbot
The CIA's Open-Source Enterprise division is intended to help intelligence analysts sift through vast amounts of open source intelligence for quicker data dissemination. The initiative is part of a broader government effort to harness AI capabilities (and compete with China). (Bloomberg)