
Dear friends,
We ended a busy week in Colombia hosting a Pie & AI meetup in Medellín. I met hundreds of engineers and business professionals excited to take the next step in their AI careers. I was energized by the enthusiasm the Colombia community had for collaborating and for supporting each other to build up the local AI ecosystem. AI is still young enough that many cities can still become hubs of AI talent, but the city has to make smart investments, and the community has to work hard and keep learning, which Colombia is doing. I hope the future will bring many more global AI hubs.

I also drank a lot of coffee on this trip. I don’t know whether it was because the coffee really was fresher or if it was a placebo effect, but Colombian coffee tasted better in Colombia than when I drink it at home!
Keep learning,
Andrew
News
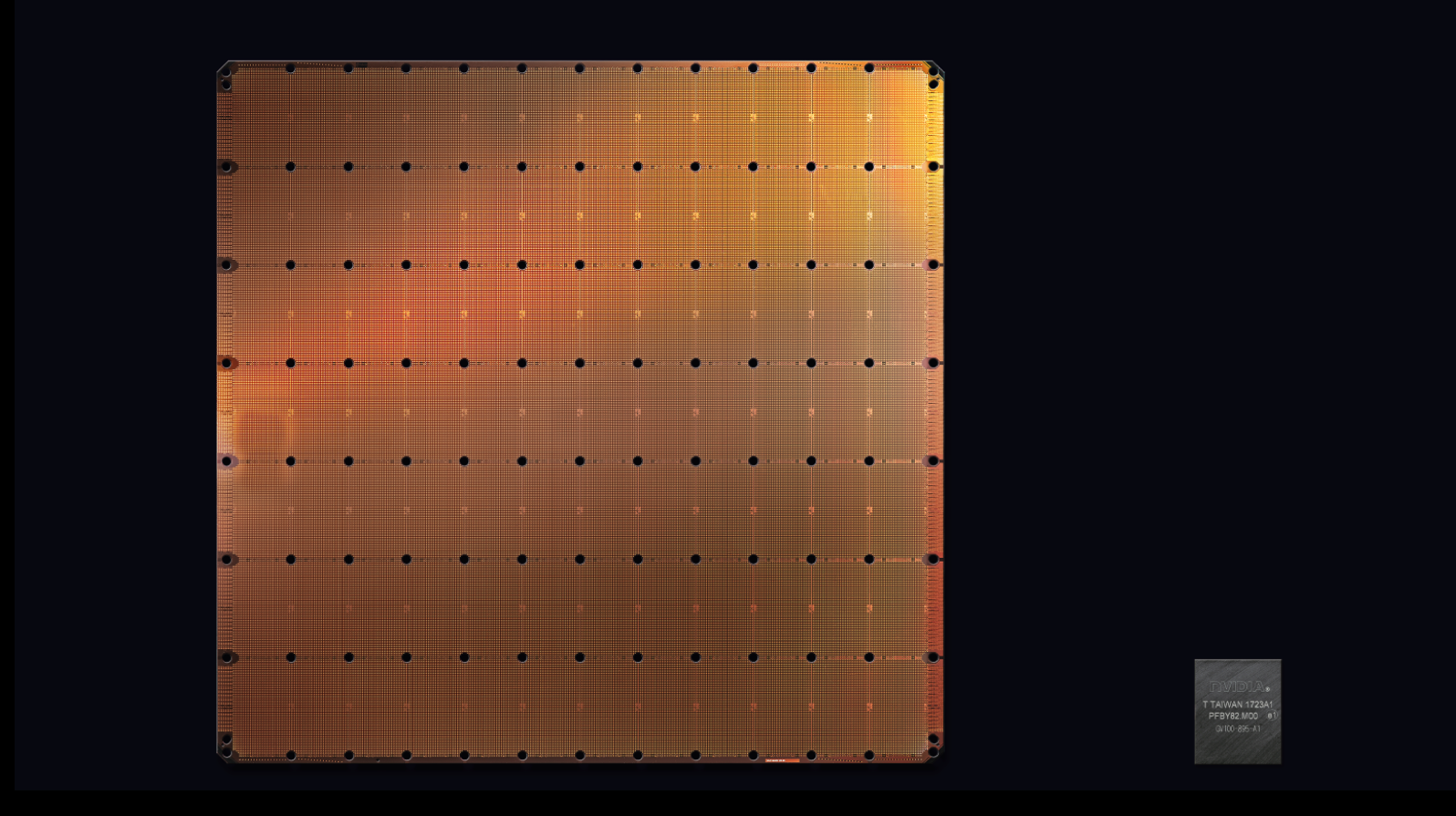
Size Matters
Silicon Valley startup Cerebras shifted out of stealth mode to unveil its flagship product: an enormous chip designed from the ground up to accelerate neural networks.
What’s new: The Cerebras Wafer Scale Engine is aimed at data centers, where the company claims it will perform AI computations 100 to 1,000 times faster than alternatives. The chips will be housed in servers equipped with a special cooling system to dissipate the chip’s heat. They’re scheduled to reach the market next month for an undisclosed price.
Why it’s different: Where many chips are measured in millimeters, this monster is 56 times larger than Nvidia’s top-of-the-line GPU and bigger than a standard iPad. It comprises more than 400,000 cores and 18 gigabytes of memory right on the chip. That’s equivalent to 84 GPUs communicating with one another 150 times more efficiently than usual, with an additional boost thanks to the ability to handle sparse linear algebra.
How it works: Nvidia’s chip architecture is extraordinarily efficient at performing the predictable, repetitive matrix multiplications required by neural networks. Yet it has practical limitations: It must hold an entire neural network in off-chip memory and communicate with other chips through external interfaces that are far slower than communication on the chip itself.
- By putting all computing resources on a single piece of silicon, the new chip makes it possible to process neural networks at top speed.
- For even higher efficiency, it processes sparse networks by pruning unnecessary calculations.
Behind the news: Deep learning’s rapid growth has prompted a top-to-bottom redesign of computing systems to accelerate neural network training.
- Cerebras is a front runner among a plethora of startups working on AI chips.
- And not only startups: Amazon, Facebook, Google, and Tesla have all designed chips for in-house use.
- Among traditional chip companies, Nvidia has progressively retooled its GPUs to accelerate deep learning, Intel is rolling out its competing Nervana technology, and Qualcomm has been building inferencing engines into its smartphone chips.
- Cerebras is the only one to opt for a wafer-scale chip. Soon, it may become the first company to have overcome the considerable technical hurdles to putting a wafer-scale chip into production.
Why it matters: If the new hardware works as advertised, it will open virgin territory for neural networks several orders of magnitude bigger than today’s largest models. Larger models have been shown to yield higher accuracy, and the additional headroom may well allow new kinds of models that wouldn’t be practical otherwise.
We’re thinking: The advent of Nvidia GPUs two decades ago spurred innovations in model architecture that boosted the practical number of network layers from handfuls to 1,000-plus. Cerebras’ approach portends fresh architectures capable of solving problems that are currently out of reach. We don’t yet know what those models will look like, but we’re eager to find out!
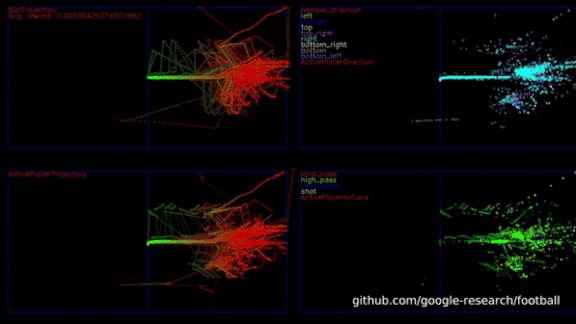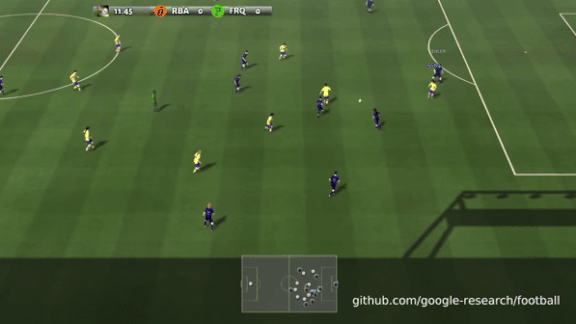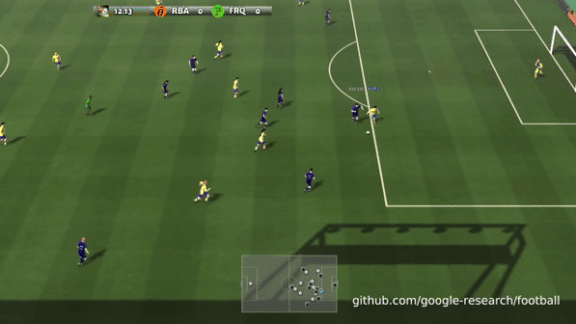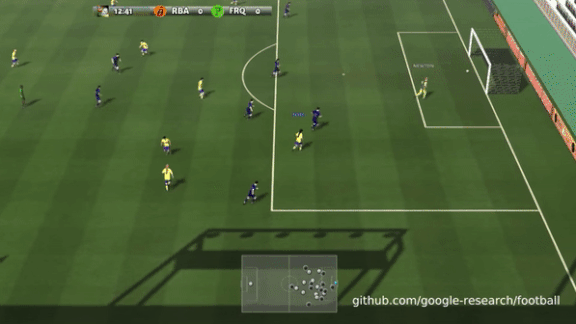
Get Your Kicks With DRL
Researchers typically test deep reinforcement learning algorithms on games from Space Invaders to StarCraft. The Google Brain team in Zurich adds another option: football, also known as soccer.
What’s new: Google Research Football allows experiments on a variety of RL techniques in a single environment: self playing, stochastic environment, multi-agent cooperation, and several styles of state representation. Check out the video here.
Key insight: Popular games generally are either easy to win or offer rewards that are too sparse. Most don’t allow for cooperative agents or graduated degrees of difficulty that would help the agents learn basic strategies. Google Research Football is designed to solve all these problems in one go, and it’s open source to boot.
How it works: Karol Kurach and his team provide a physics-based soccer simulator with full-length, 11-player games at a range of difficulty levels. They also offer short scenarios from simple (single player scoring in an empty net) to complex (team coordination to score from a corner kick). Users can build their own scenarios as well.
- The game state can be represented in three ways: a vector encapsulating 115 features, a full pixel-wise frame, and a “super mini map” of coordinates and speed of every player as well as the ball.
- Players can perform 16 actions, including directional movement, passing, dribbling, and shooting.
- The authors implement three state-of-the-art RL algorithms, two using policy gradients (PPO and IMPALA) and one that uses Q-learning (Ape-X DQN), and report their performance on Google Research Football.
Observations: The algorithms supplied quickly solve the easy situations, but they struggle on medium and hard settings even after long periods of training. Performance also depends on the input representation and the number of agents involved.
Why it matters: GRF is a challenge even for today’s best RL algorithms. It gives researchers a multi-agent environment where they can work on improving agents by having them compete with one another, and it provides resources for building more capable agents through increasing degrees of difficulty in an environment that resembles the real world.
We’re thinking: This might be a good time to take to the virtual field and compete for the football leaderboard, as reinforcement learning begins to take on the world’s most popular sport.
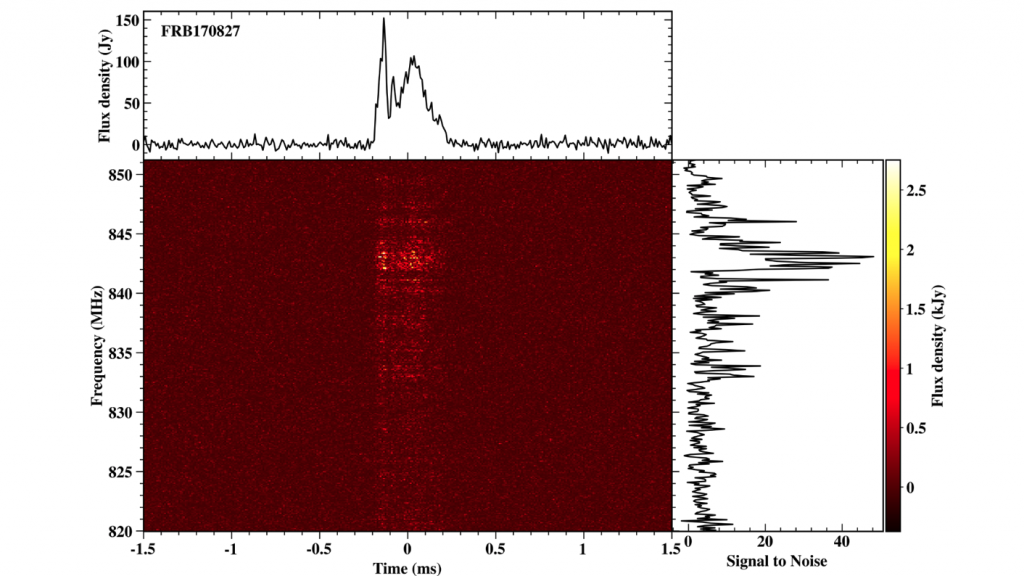
In a Galaxy Far, Far Away
The origin of the brief, high-intensity signals from outer space called fast radio bursts baffles astronomers. Now AI is generating real-time data to help solve the mystery.
What’s new: A machine learning model deployed at the Molonglo Radio Telescope in Australia detected five fast radio bursts in unprecedented detail.
How it works: The Molonglo telescope uses a standard program to flag incoming electromagnetic waves as fast radio burst candidates. However, the mystery signals share the same frequency band as cell phones, lightning storms, and solar emissions, so the system is prone to false positives. Researcher Wael Farah developed a machine learning model to pick out the most viable candidates.
- Farah first trained the model on recordings of pulsars. Those signals resemble fast radio bursts, but scientists have many more recordings of them and know enough about them to train the model to differentiate them.
- The model compares incoming signals against known features of fast radio bursts, such as the rate at which their higher frequencies disperse as they cross the cosmos.
- The model pared down each day’s fast radio burst candidates from tens of thousands to tens, a manageable number for the telescope’s human staff to verify.
Results: Since the model debuted in April, 2018, it has flagged the most energetic fast radio burst and the one with the broadest spectrum, and it has captured the most detailed view of the signals’ rapidly fluctuating voltage.
Behind the news: Earlier this year, American scientist Brian Metzger won a $3 million Breakthrough Prize for his work on a theory about the genesis of fast radio bursts — not SOSes from an alien intelligence, sadly, but shock waves produced by young neutron stars with dense magnetic fields.
Why it matters: Testing ideas about fast radio bursts requires more, and more detailed, data. Farrah’s model delivers it.
We’re thinking: Telescopes collect a crushing torrent of data. With the help of AI, human astronomers might manage to analyze them before the universe’s Big Crunch.
A MESSAGE FROM DEEPLEARNING.AI

You may know how to set up a train/dev/test set, but there’s still more to learn. Take the Deep Learning Specialization and learn how to avoid major pitfalls.

Second Sight
Unlike bats, humans can’t see with their ears. Now an app is giving sightless pedestrians the ability to navigate by ear.
What’s new: Microsoft’s Artificial Intelligence and Research Laboratory offers a free iPhone app called Soundscape. Unlike earlier efforts that tried to identify objects visually, the app orients pedestrians in space by calling out nearby buildings, businesses, landmarks, and road crossings as the walker approaches.
How it works: Essentially a navigation app. But unlike conventional navigation apps that issue directions to a destination (“Turn left here!”), Soundscape narrates points of interest along the way. That helps people who don’t see well to explore like a sighted person can — for example, popping into a bakery that caught their attention on the way to work, or simply taking a random walk.
- Soundscape interprets a phone’s GPS signals and accelerometer to determine the user’s location, trajectory, and facing direction. It pulls labels from a map to describe the surrounding environment.
- Then it speaks these descriptions in stereo. If the user passes a store on the left, the narrator’s voice sounds in their left ear. If the user approaches a crosswalk on the right, they’ll hear about it in their right ear.
- Users can also set homing beacons. Select a destination — say, the entrance ramp to their favorite coffee shop. The app provides a soft, snappy drum beat that increases in volume as you approach the destination. It adds a rhythmic ping when you face the destination directly.
Behind the news: Project lead Amos Miller, a developer and product strategist at Microsoft, lost his sight as an adult due to a genetic condition. You can hear an interview with him in this podcast.
Why it matters: Several previous apps for visually impaired people attempt to replace human vision with computer vision: Point a camera at an object or person, and the app classifies what it sees. That approach has yet to catch on, leaving the field ripe for fresh approaches.
We’re thinking: Soundscape isn’t just for the sight-impaired. It may be worth a try the next time you visit a new city and want to take in the sights without constantly referring to a map.
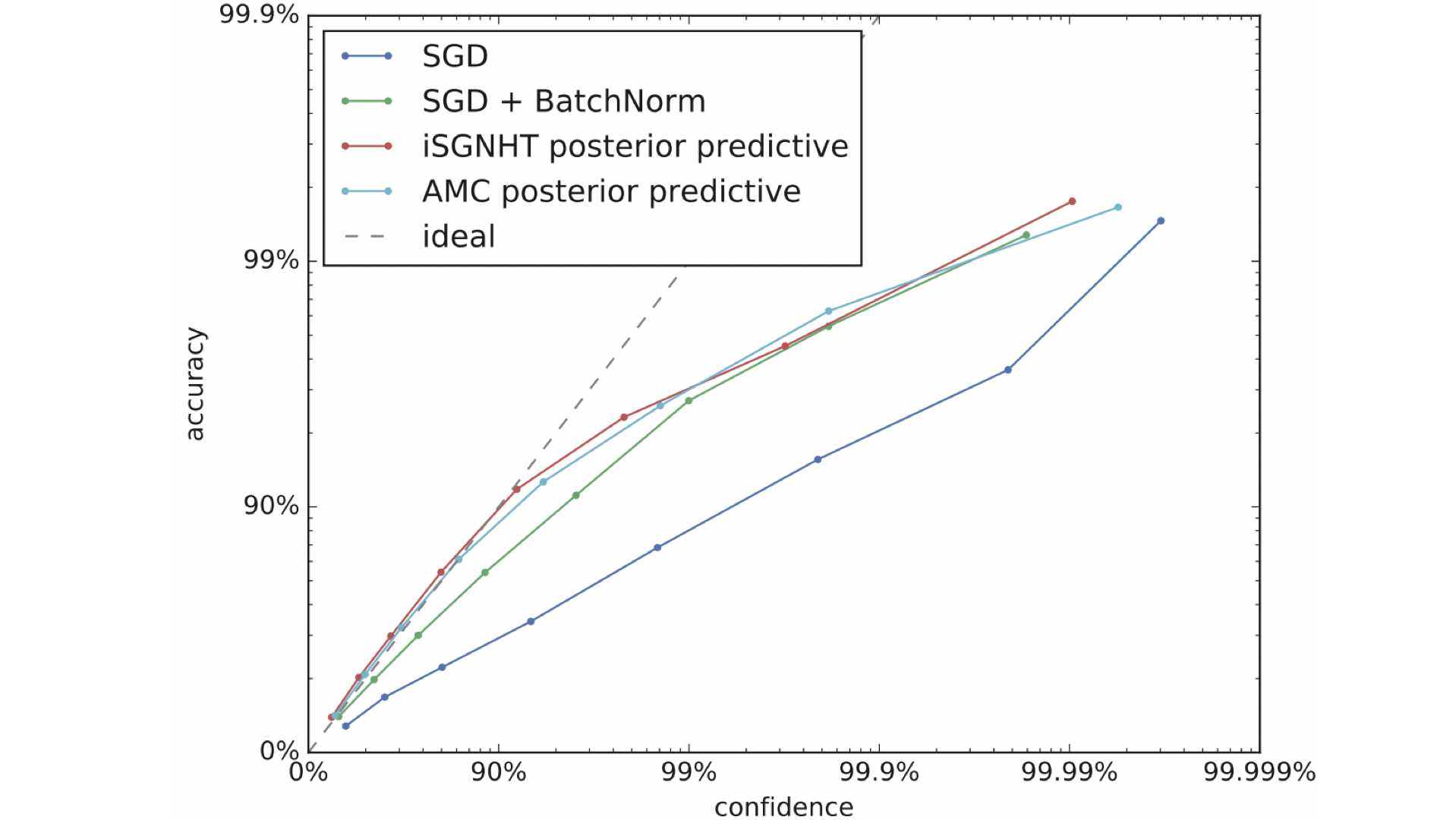
Scaling Bayes
Neural networks are good at making predictions, but they’re not so good at estimating how certain they are. If the training data set is small and many sets of model parameters fit the data well, for instance, the network may not realize this explicitly, leading to overly confident predictions. Bayesian models, on the other hand, theoretically can sample from the posterior distribution of parameters. However, the computational load becomes overwhelming as the number of parameters rises. New research allows Bayesian modeling of uncertainty to be applied even to large networks.
What’s new: Researchers at Google Brain built neural networks that integrate a Bayesian backpropagation method known as Stochastic Gradient Markov Chain Monte Carlo, fixing issues with noisy updates and slow convergence that affected earlier work. Their technique, Adaptive Thermostat Monte Carlo (ATMC), is the first based on SG-MCMC that scales to larger data sets such as ImageNet.
Key insight: Previous research using SG-MCMC failed to find training procedures that were robust to noise arising from parameter sampling in Bayesian methods. ATMC compensates for these issues by adjusting momentum and noise applied to parameter updates.
How it works: Non-Bayesian learning techniques compute the loss from outputs and labels only. Bayesian techniques add a prior distribution on learnable parameters. All methods based on SG-MCMC are derived from a stochastic differential equation that modifies a neural network’s parameter distribution based on the sampled output.
- ATMC samples learnable parameters from the distribution, and the network backpropagates its errors.
- Then it modifies the computed gradients to ensure that noisy sampling doesn’t overly influence shifts in the parameter distribution.
- It makes convergence faster and more stable than prior variations of SG-MCMC by dynamically adjusting momentum and noise added to each parameter update.
- In addition, the authors provide an adjusted ResNet architecture better suited for Bayesian training. The new model replaces batch normalization with SELU activation and uses a different weight initialization.
Results: ATMC is the first SG-MCMC method successfully trained on ImageNet. An ATMC-trained network gains a 1 percent increase over a batch-normalized ResNet in ImageNet top-1 accuracy.
Why it matters: Estimating uncertainty can be crucial in applications such as medical imaging and autonomous driving. ATMC confers this capability on neural networks even when learning large, complex data sets such as ImageNet.
We’re thinking: Bayesian methods have been studied longer than neural networks, and they still define the state of the art in some tasks. The fusion of Bayesian models and neural networks is still evolving. ATMC suggests that such hybrids could deliver the advantages of both approaches.