
Dear friends,
In April, DeepLearning.AI launched a short course, “ChatGPT Prompt Engineering for Developers,” taught by OpenAI’s Isa Fulford and me.
I’m thrilled to announce three more short courses, available today:
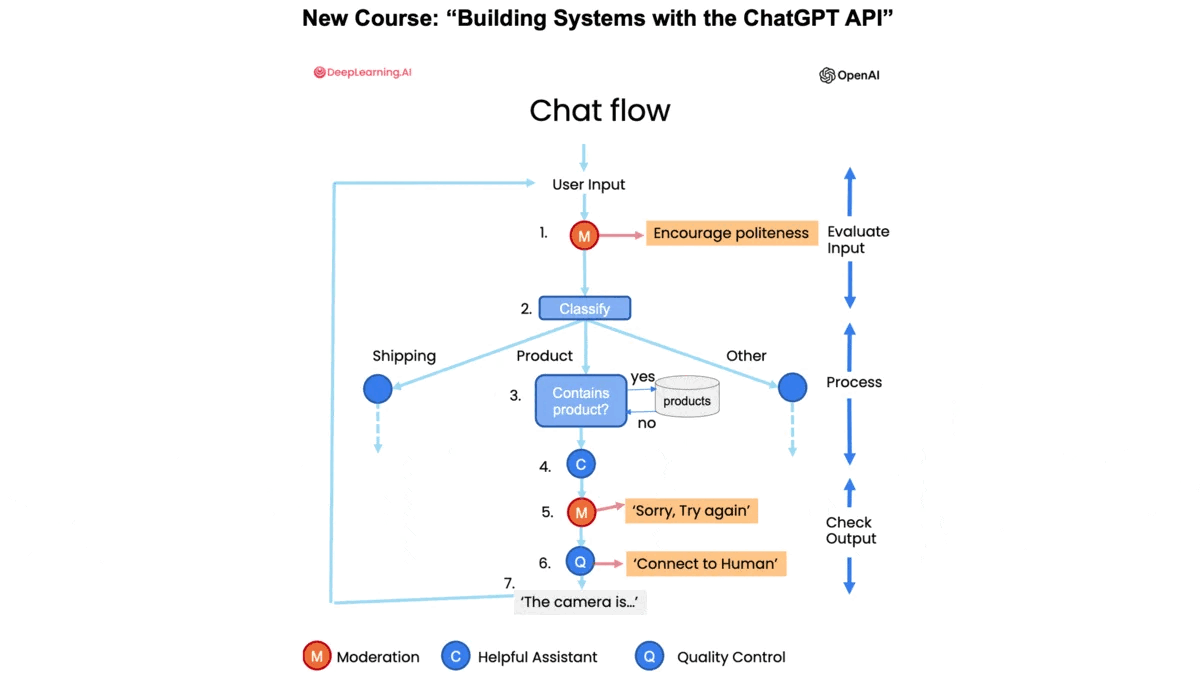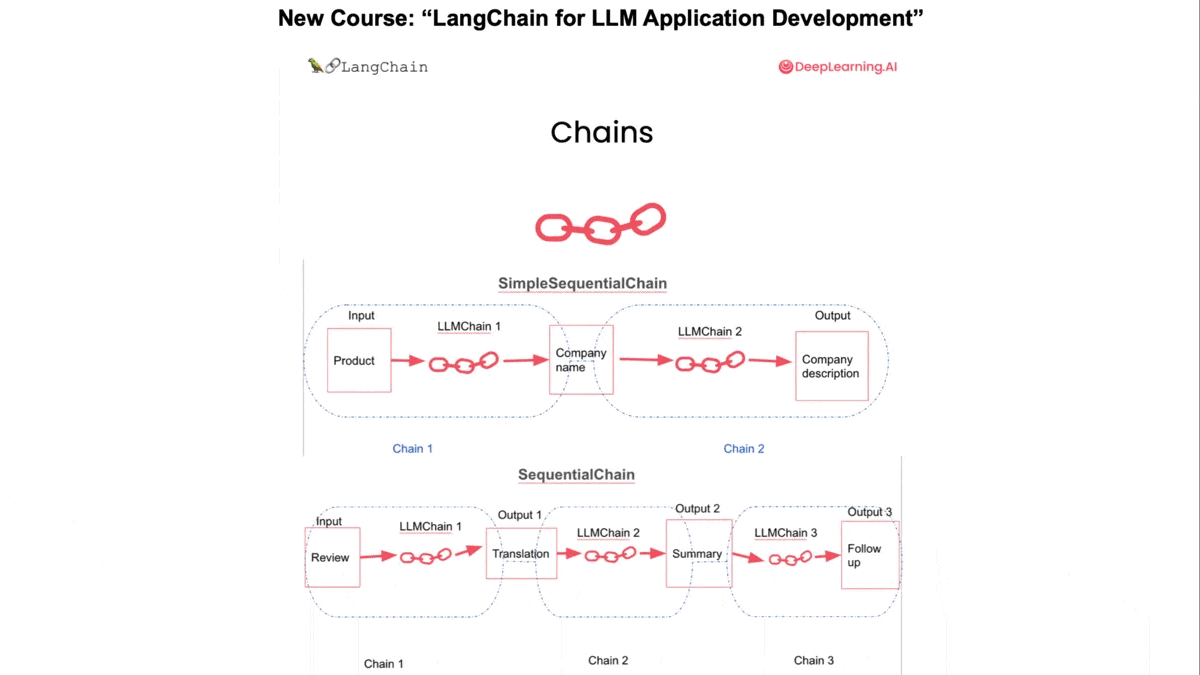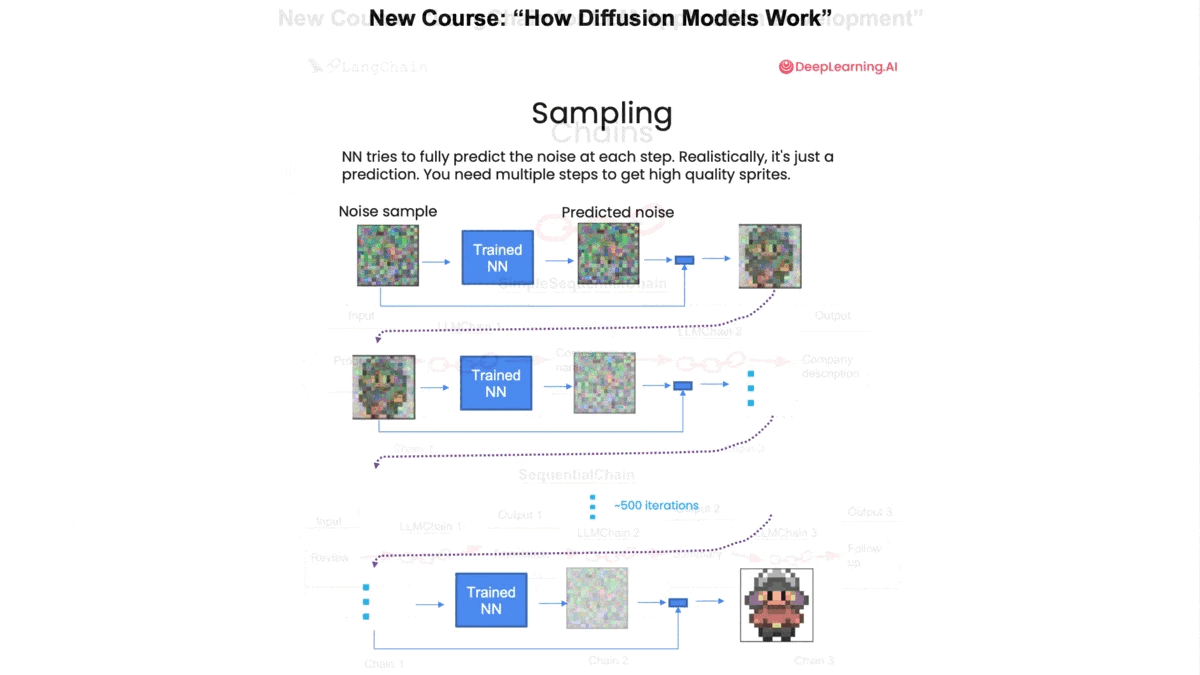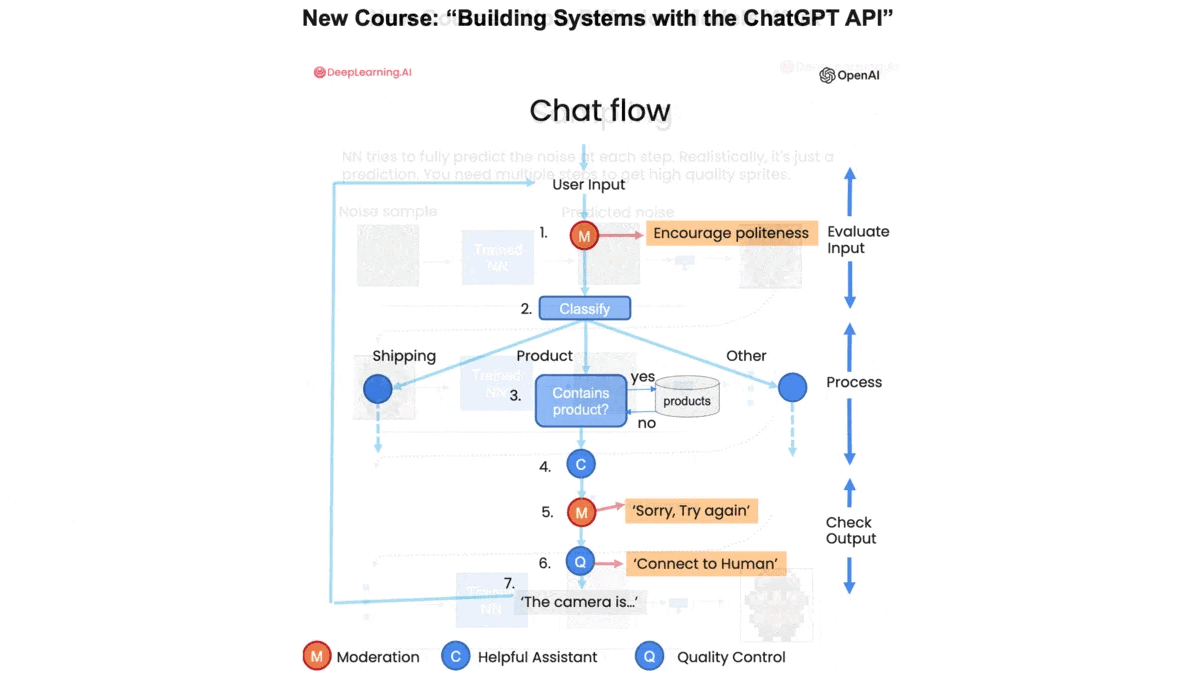
- “Building Systems with the ChatGPT API” taught by returning instructor Isa Fulford and me: This course goes beyond writing individual prompts and shows you how to break down a complex task — such as building a customer-service assistant system — into simpler tasks that you can accomplish via multiple API calls to a large language model (LLM). You’ll also learn how to check LLM outputs for safety and accuracy and how to systematically evaluate the quality of an LLM’s output to drive iterative improvements. You’ll come away with a deeper understanding of how LLMs work (including tokenization and how the chat format works) and how this affects your applications, and gain a solid foundation for building applications using LLMs.
- “LangChain for LLM Application Development” taught by LangChain CEO Harrison Chase and me: LangChain is a powerful open-source tool for building applications using LLMs. Complex applications — for example, a QA (Question Answering) system to answer queries about a text document — require prompting an LLM multiple times, parsing the output to feed to downstream prompts, and so on; thus, there’s a lot of “glue” code needed. You’ll learn how to use LangChain’s tools to make these operations easy. We also discuss the cutting-edge (and experimental) agents framework for using an LLM as a reasoning engine that can decide for itself what steps to take next, such as when to call an external subroutine.
- “How Diffusion Models Work” taught by Lamini CEO Sharon Zhou: Diffusion models enable Midjourney, DALL·E 2, and Stable Diffusion to generate beautiful images from a text prompt. This technical course walks you through the details of how they work, including how to (i) add noise to training images to go from image to pure noise, (ii) train a U-Net neural network to estimate the noise so as to subtract it off, (iii) add input context so that you can tell the network what to generate, and (iv) use the DDIM technique to significantly speed up inference. You’ll go through code to generate 16x16-pixel sprites (similar to characters in 8-bit video games). By the end, you’ll understand how diffusion models work and how to adapt them to applications you want to build. You’ll also have code that you can use to generate your own sprites!
The first two courses are appropriate for anyone who has basic familiarity with Python. The third is more advanced and additionally assumes familiarity with implementing and training neural networks.
Each of these courses can be completed in around 1 to 1.5 hours, and I believe they will be a worthy investment of your time. I hope you will check them out, and — if you haven’t yet— join the fast-growing community of developers who are building applications using Generative AI!
Keep learning,
Andrew
News

Rising Calls for Regulation
Amid growing worries about AI’s power, tech leaders and politicians alike are arguing for regulating the technology.
What’s new: Leaders of OpenAI, Microsoft, and Google spoke publicly in favor of regulation and met privately with world leaders. Meanwhile, national governments proposed new guardrails for generative AI.
Execs rally: Corporate leaders hit the road to spread words of caution.
- OpenAI CEO Sam Altman embarked on a world tour to express support for new laws including the European Union’s forthcoming AI Act. He called for a global regulatory body to oversee superintelligent machines in an open letter with co-founders Greg Brockman and Ilya Sutskever. Earlier in May, Altman testified in favor of regulating AI before the U.S. Congress.
- In addition, OpenAI will award 10 grants of $100,000 each to develop AI governance frameworks. The company is considering applications until June 24.
- Microsoft president Brad Smith echoed Altman’s calls for a U.S. agency to regulate AI.
- Separately, Google CEO Sundar Pichai agreed to collaborate with European lawmakers to craft an “AI pact,” a set of voluntary rules for developers to follow before EU regulations come into force.
Regulators respond: Several nations took major steps toward regulating AI.
- At its annual meeting in Japan, the Group of Seven (G7), an informal bloc of industrialized democratic governments, announced the Hiroshima Process, an intergovernmental task force empowered to investigate risks of generative AI. G7 members, which include Canada, France, Germany, Italy, Japan, the United Kingdom, and the United States, vowed to craft mutually compatible laws and regulate AI according to democratic values. These include fairness, accountability, transparency, safety, data privacy, protection from abuse, and respect for human rights.
- U.S. President Joe Biden issued a strategic plan for AI. The initiative calls on U.S. regulatory agencies to develop public datasets, benchmarks, and standards for training, measuring, and evaluating AI systems.
- Earlier this month, France’s data privacy regulator announced a framework for regulating generative AI.
Behind the news: China is the only major world power that explicitly regulates generative AI. In March, EU officials rewrote the union’s AI Act, which has not yet been enacted, to classify generative AI models as “high-risk,” which would make them subject to bureaucratic oversight and regular audits.
Why it matters: As generative AI’s capabilities grow, so do worries about its potential pitfalls. Thoughtful regulations and mechanisms for enforcement could bring AI development and application into line with social benefit. As for businesses, well defined guidelines would help them avoid harming the public and damaging their reputations and head off legal restrictions that would block their access to customers.
We’re thinking: Testifying before the U.S. Congress, Sam Altman recommended that startups be regulated more lightly than established companies. Kudos to him for taking that position. The smaller reach of startups means less risk of harm, and hopefully they will grow into incumbents subject to more stringent regulation.

Pop Star Invites AI Imitation
A popular musician is inviting fans to clone her voice. Result: a flood of recordings that sound just like her.
What’s new: Experimental pop star Grimes released GrimesAI-1, a generative audio tool that allows anyone to make recordings of their own singing or speech sound like her voice. As of May 24, users had generated more than 15,000 cloned vocal tracks and submitted more than 300 fully produced songs to streaming services, The New York Times reported.
How it works: GrimesAI-1 is available on elf.tech, a website built by Grimes and artist-management company CreateSafe.
- GrimesAI-1 was trained on vocal recordings of the artist’s voice both unprocessed and altered with effects such as reverb.
- Users can upload existing vocal recordings or use the tool to record new performances. Users can add backing music using the audio production applications of their choice. Then they can click a button to upload their creations to streaming services.
- In a tweet, Grimes invited people to try to earn money using her AI-cloned voice in exchange for half of any resulting royalties.
Behind the news: Generative audio tools like Murf.ai and Respeecher are fueling a surge of cloned songs in the styles of popular artists. In April, Universal Music Group, one of the world’s largest owners of music rights, asked streaming services including YouTube and Spotify to take down AI-generated songs.
Why it matters: Some voice actors license their voices for use in AI-generated likenesses. Grimes has gone one step further, giving her fans the tools and terms they need to mimic her voice — and perhaps even make money.
We’re thinking: While major players in the music industry aim to shut off the spigot of generated music, Grimes is collaborating with her fans. That sounds like a more productive and democratic response.
A MESSAGE FROM DEEPLEARNING.AI

Three new courses on generative AI are live. Take them for free for a limited time! Sign up today

Scanner Sees Guns, Misses Knives
An automated security-screening system failed to detect a weapon that went on to be used in an attack.
What’s new: Administrators at Proctor High School in Utica, New York, decommissioned an AI-powered weapon detector by Evolv Technologies after a student snuck a knife into the school, BBC reported. The school installed the system in 2022 for $3.7 million.
How it works: Evolv’s system uses ultra low-frequency radio sensors mounted in pillars to scan visitors at a building’s entrance. The AI model was trained on roughly 50,000 scans to classify objects including guns, knives, and bombs. The system can screen 3,600 people per hour, purportedly 10 times the rate of a walk-through metal detector. The company’s customers include museums, theme parks, stadiums, and schools.
The incident: On October 31, 2022, a student carried a hunting knife through Evolv’s scanner. Later that day, the student attacked a fellow student, who sustained serious stab wounds.
- Following the attack, Proctor High School’s district conducted an internal investigation and found that Evolv had failed to detect knives on three earlier occasions.
- Proctor High School replaced Evolv’s system with traditional metal detectors. Twelve other schools in the district continue to use the system. District leaders said replacing them would be prohibitively expensive.
- In 2021, the U.S. National Center for Spectator Sports Safety and Security tested Evolv’s technology and found that it detected guns 100 percent of the time and knives 42 percent of the time.
Why it matters: Although no AI system can be expected to function perfectly all the time, systems that perform critical tasks like detecting weapons must meet a very high bar. The manufacturer has a responsibility to perform rigorous tests of the system’s effectiveness and distribute the results to prospective and actual customers.
We’re thinking: Our hearts go out to the community and family of the student who was injured. We hope that such systems will improve, and beyond that, we hope society evolves to a point where screening for weapons is unnecessary. It’s a travesty that children in the U.S., unlike most countries, live in fear of a violent attack on their schools. $3.7 million could go a long way toward paying for books, equipment, and teacher salaries.

Text-to-Image Editing Evolves
Text-to-image generators like DALL·E 2, Stable Diffusion, and Adobe’s new Generative Fill feature can revise images in a targeted way — say, change the fruit in a bowl from oranges to bananas — if you enter a few words that describe the change plus an indication of the areas to be changed. Others require a revised version of the prompt that produced (or could produce) the original image. A new approach performs such revisions based solely on a brief text command.
What's new: Tim Brooks and colleagues at UC Berkeley built InstructPix2Pix, a method that fine-tunes a pretrained text-to-image model to revise images via simple instructions like “swap oranges with bananas” without selecting the area that contained oranges. InstructPix2Pix works with traditional artwork (for which there is no initial prompt) as well as generated images.
Key insight: If you feed an image plus an edit instruction into a typical pretrained image generator, the output may contain the elements you desire but it’s likely to look very different. However, you can fine-tune a pretrained image generator to respond coherently to instructions using a dataset that includes a prompt, an image generated from that prompt, a revised version of the prompt, a corresponding revised version of the image, and an instruction that describes the revision. Annotating hundreds of thousands of images in this way could be expensive, but it’s possible to synthesize such a dataset: (i) Start with a corpus of images and captions, which stand in for prompts. (ii) Use a pretrained large language model to generate revised prompts and instructions. (iii) Then use a pretrained image generator to produce revised images from the revised prompts.
How it works: The authors fine-tuned Stable Diffusion, given an input image and an instruction, to revise the image accordingly. They built the fine-tuning dataset using the GPT-3 language model, Stable Diffusion text-to-image generator, and Prompt-to-Prompt, an image generator that revises generated images based on a revised version of the initial prompt (no masking required). Images and captions (used as prompts) came from LAION-Aesthetics V2 6.5+.
- The authors sampled 700 captions (for example, “a girl riding a horse”). They manually added 700 instructions (“have her ride a dragon”) and revised prompts (“a photograph of a girl riding a dragon”). Using this data, they fine-tuned GPT-3 to take a caption and generate a revised prompt and corresponding instruction.
- The authors selected around 455,000 LAION captions outside of the initial 700 and used them to prompt Stable Diffusion to produce an initial image. They also fed the prompts to GPT-3, which generated revised prompts and corresponding instructions. Given the initial images and revised prompts, Prompt-to-Prompt generated revised images.
- They generated 100 variations of each revised image and kept the one that best reflected the initial image and the instruction according to a similarity metric based on CLIP, which maps corresponding text-image pairs to the same representations. The metric compares the vector difference between CLIP’s representations of the initial and revised prompts to the vector difference between CLIP’s representations of the initial and revised images. The two vectors should point in the same direction. This process yielded a fine-tuning set of around 455,000 sets of initial images, revised images, and instructions.
- The dataset enabled the authors to fine-tune Stable Diffusion to produce an edited image from an initial image and instruction.
Results: Qualitatively, InstructPix2Pix revised the initial images appropriately with respect to subject, background, and style. The authors compared InstructPix2Pix to SDEdit, which revises images based on detailed prompts, according to the vector-difference method they used to choose revised images for the fine-tuning set. Revising an undisclosed set of images, InstructPix2Pix achieved a higher similarity of ~0.15, while SDEdit achieved ~0.1. (The score represents similarity between the difference in the initial and revised prompts and the difference in the initial and revised images.)
Why it matters: This work simplifies — and provides more coherent results when — revising both generated and human-made images. Clever use of pre-existing models enabled the authors to train their model on a new task using a relatively small number of human-labeled examples.
We're thinking: Training text generators to follow instructions improved their output substantially. Does training an image generator to follow instructions have a similar impact?
Data Points
Reddit users exposed a ChatGPT hack
Redditors led OpenAI’s chatbot to generate random responses by asking it to repeat a letter multiple times. Users explained that ChatGPT tends to avoid token repetition due to a “frequency penalty” applied during its training. (Futurism)
Deepfakes flooded Turkish social media ahead of elections
Prior to the country's runoff voting, fact-check organizations discovered numerous manipulated videos, including fabricated sex tapes, circulated by supporters of both presidential candidates. (Wired)
AI-generated photo triggers stock sell-off
The fake picture, which showed a government building near the Pentagon engulfed in black smoke, caused markets to dive. Prices recovered after experts confirmed that the image was not real. (The New York Times)
Reports identify hundreds of websites with AI-generated content
The findings encompass a variety of content categories including product reviews, medical advice, and news, highlighting concerns about the new era of online misinformation. (The New York Times)
Research: AI-powered device restored a paralyzed person’s ability to walk
Researchers established communication between the brain and spinal-cord region responsible for walking in a patient with chronic tetraplegia. They used AI algorithms to form a “digital bridge” between the two parts of the patient’s body. (Financial Times)
AI was the protagonist of the Microsoft Build 2023 event
During its annual developer conference, Microsoft announced the expanded use of generative AI across its services. Announcements included integration of Copilot, the company’s AI assistant, into Windows 11, Office 365, and Edge. (The Verge)
AI-generated ads passed an advertising Turing Test
A panel of marketing experts achieved an accuracy rate of 57 percent when attempting to identify AI ads vs. human-made ads during the BrXnd Conference, which focuses on the role of AI in marketing. (NewScientist)
Buzzfeed launched Botatouille, a culinary chatbot
The chatbot is available on Tasty, the digital media company’s food app It’s designed to help users discover meal recipes, solve cooking questions, and learn culinary techniques. (The Guardian)
Universal Music Group announced partnership to produce generated music
The music corporation will license Endel’s technology, allowing its artists and labels to produce soundscapes that purportedly enhance listeners’ wellness. (Pitchfork)
New Zealand’s National Party used AI in attack ads
The party acknowledged that it had used generated images to portray crime victims, healthcare workers, thieves, and others. (The Guardian)
ML Commons launched DataPerf, a data-centric platform for building better machine learning
DataPerf provides benchmarks, competitions, and leaderboards for data-centric AI algorithms, aiming to overcome dataset limitations and foster future advancements in machine learning. (ML Commons)
Eating disorder helpline replaced staff with a chatbot
The National Eating Disorder Association laid off its hotline workers and implemented a chatbot named Tessa. The workers had formed a union days earlier. (Gizmodo)