
Dear friends,
Last week, the tech news site The Information reported an internal controversy at Google. Engineers were concerned that Google’s Bard large language model was trained in part on output from OpenAI’s ChatGPT, which would have violated OpenAI’s terms of use. The output purportedly was hosted on ShareGPT, a website where users share conversations with ChatGPT. (Google denies the report.) A decade ago, Google accused Microsoft of copying its search results to enhance Bing.
Training a machine learning model on a different model’s output can be a useful technique, but it also raises engineering, business, and legal questions. When is it okay?
Engineering recipes for training learning algorithms on generated data are still being developed. When I led a large automatic speech recognition (ASR) team, there were rumors — that we never proved or disproved — that a competitor was using our system to generate transcripts to train a competing system. It was said that, rather than using our ASR system’s output directly as labeled training data, our competitor used a lightweight process to manually clean up errors and make sure the data was high-quality.
Lately, I’ve seen many developers experiment with use cases such as prompting a large model (say, 175B parameters) to generate high-quality outputs specialized to an application such as customer support, and using this data to fine-tune a smaller model (say, ~10B parameters) that costs less per inference. UC Berkeley trained Koala using data from ShareGPT, and Stanford trained Alpaca by fine-tuning Meta’s LLaMA on data generated with assistance from OpenAI’s text-davinci-003.
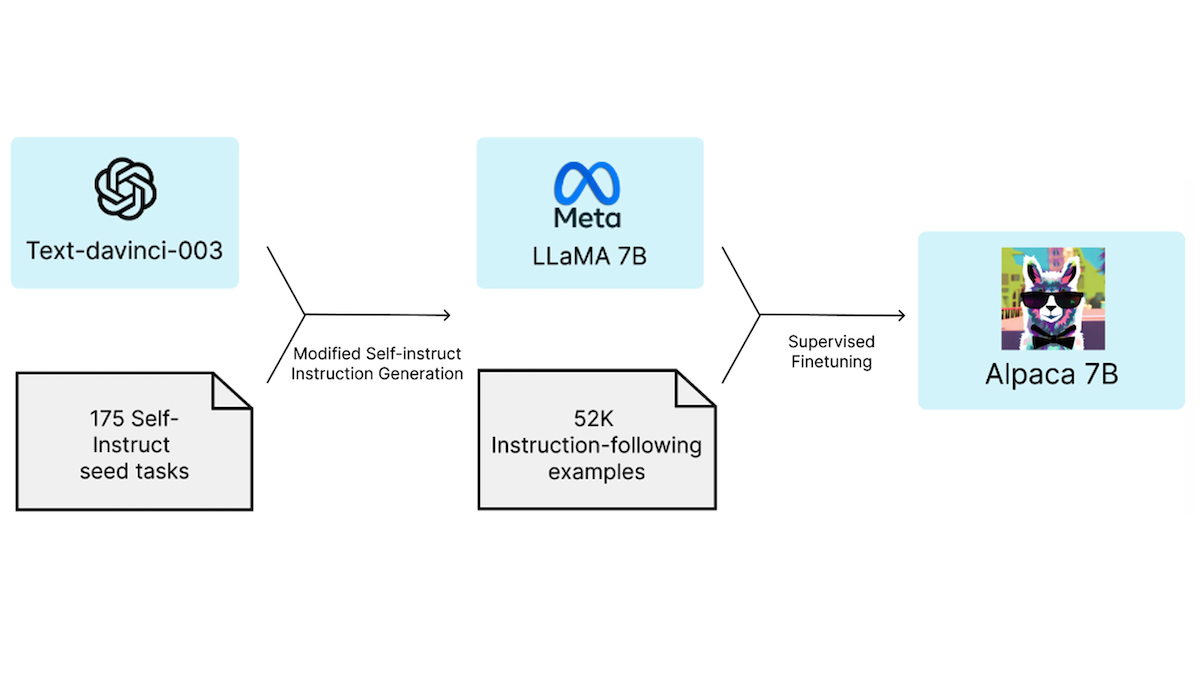
Such recipes raise important business questions. You may have spent a lot of effort to collect a large labeled training set, yet a competitor can use your model’s output to gain a leg up. This possibility argues that, contrary to conventional tech-business wisdom, data doesn’t always make your business more defensible. Specifically, if a market leader spent significant resources to get its performance up to a certain level, and if the market leader’s product generates data that makes it cheaper for competitors to catch up, then the market leader’s initial effort spent gathering data is a weak defense against competitors.
In addition, the legal and ethical questions around this practice need clearer answers. OpenAI’s terms of use forbid anyone to “use output from the Services to develop models that compete with OpenAI.” To my mind, this raises legal questions such as:
- If Google or another company has not agreed to OpenAI’s terms of use, and it scrapes text from ShareGPT that someone else shared, is it bound by OpenAI’s terms?
- Are terms that restrict competitor’s access to your services enforceable in light of antitrust and fair-use laws?
(To state the obvious, I am not a lawyer. Don’t construe anything I say as legal advice!)
In the era of generative AI, we’ll see many creative use cases for intentionally using one model to generate data to train another. This is an exciting technical trend, even as we keep in mind the need to move forward in ways that are legal and fair.
Keep fine-tuning!
Andrew
P.S. On Friday, April 7, Yann LeCun and I will hold a live online discussion about a proposed six-month pause in cutting-edge AI research. The proposal raises questions about AI’s future and, if implemented, would have a huge impact on developers and businesses. Please join us.
News

AI Shows Its Metal
Neural networks are predicting how metal will deform under pressure to pilot robots through the tricky process of fabricating aircraft.
What’s new: Machina Labs crafts metal using AI-guided robotic arms, Bloomberg reported. The company recently inked contracts with the United States Air Force, the U.S. National Aeronautics and Space Administration, and Hermeus, which makes hypersonic airplanes.
How it works: The system combines robot arms, sensors, and machine learning models to form, trim, finish, and polish metal sheets according to a computer-aided design. Working in pairs, robot arms on either side of a sheet apply pressure to sculpt deformations up to four feet deep. The system works on aluminum, steel, and titanium in varying thicknesses and sizes upward of 4 feet by 12 feet. A basic two-arm setup costs $2.5 million.
- Unspecified neural networks plan an arm’s path, determine how much force to apply, and predict how the metal will respond to pressure and how it might spring back.
- Laser scans compare the robots’ progress to the design specification in real time. A neural network adjusts the arm’s motion to compensate for differences.
- Based on the scans, the system creates a digital twin that’s used to check quality. Random forest and Bayesian models detect defects and forecast a maintenance schedule.
Behind the news: Most sheet-metal manufacturing is performed manually by skilled workers. Some parts can be mass-produced, but manual labor is still required to build molds. Both processes are slow, laborious, and expensive — a problem exacerbated by a shortage of craftspeople.
Why it matters: Large machines like airplanes and automobiles are expensive to manufacture. Robots guided by deep learning models can bring costs down by fabricating parts quickly and precisely and by recognizing defects before they leave the factory.
We’re thinking: This application of deep learning is riveting.
Better Pay for Data Workers
Contract workers who help train the algorithms behind Google Search won a pay raise.
What’s new: Employees of U.S. contractors who evaluate the quality of Google Search’s results, knowledge panels, and ads will earn $15 per hour, a raise of roughly $1, Bloomberg reported.
Pay raise: The Alphabet Workers Union (AWU), an unofficial labor union that represents U.S.- and Canada-based employees of Alphabet, its subsidiaries, vendors and contractors, negotiated the raise. The deal will affect around 5,000 workers, most of whom work remotely for Seattle-area RaterLabs.
- This raise follows one that occurred in January, when RaterLabs agreed to pay its employees between $14 and $14.50 per hour. Previously, they earned a minimum of $10 an hour.
- AWU won both raises by pressuring Google to extend its 2019 Wages and Benefits Standard, which originally didn’t apply to contractors. The standard calls for all U.S.-based employees to earn at least $15 per hour beginning in 2020.
- AWU plans to negotiate for other benefits described in the standard including health insurance and paid time off.
Behind the news: Large AI developers like Google and OpenAI often outsource rote tasks like labeling data and evaluating outputs. The contractors have come under fire for underpaying workers.
- Workers have accused Appen, RaterLabs parent company, of delaying payments. (Appen, whose clients include Google, YouTube, and Facebook, pays much of its U.S.-based workforce around $10 an hour, less than the minimum wage in more than half of U.S. states.)
- Workers in Venezuela and North Africa contend that Scale AI, a company that labels data for clients including Lyft, Nuro, Microsoft, OpenAI, and Skydio, has arbitrarily withheld or reduced their pay.
- OpenAI reportedly hired Sama, which is based in Kenya, to rate the output of its ChatGPT text generator, aiming to reduce the model’s toxic output. Sama paid its employees between $1.32 and $2 per hour, roughly equivalent to minimum wage for service-sector jobs in Nairobi.
Why it matters: AI products like search engines, language models, and autonomous vehicles can earn billions for the companies that develop them. Yet many of the workers who contribute to them receive relatively low wages.
We’re thinking: We’re glad to see wages rising for workers whose input is crucial to building AI systems. For a thoughtful treatment of tech labor issues, we recommend Gray and Suri’s excellent book, Ghost Work: How to Stop Silicon Valley from Building a New Global Underclass.
A MESSAGE FROM DEEPLEARNING.AI

Special event! Join Yann LeCun and Andrew Ng on Friday, April 7, 2023, at 9:30 a.m. Pacific Time to discuss a proposed pause in cutting-edge AI research. Let’s examine the pros and cons of the Future of Life Institute’s proposal! Register here

Repatriating Talent
A South African startup aims to lure talented engineers who left the continent to work abroad.
What’s new: Johannesburg research lab Lelapa.ai bills itself as a haven for African AI engineers who want to work on challenges that aren’t on Silicon Valley’s agenda, Wired reported. The company purports to focus on languages such as isiZulu that big-tech natural language models don’t accommodate.
How it works: Lelapa develops AI models for other businesses and nonprofits. The company has raised $2.5 million from institutions including Mozilla Ventures, Africa-centric investor Atlantica Ventures, and private investors including Google AI chief Jeff Dean. Current projects include:
- Vulavula, a service that provides multilingual intent detection, translation, and transcription
- An unnamed data-mining service for Open Restitution Africa, a nonprofit that retrieves African artifacts held in overseas museums
- A machine translation service that helps mothers connect with healthcare professionals
Behind the news: Lelapa’s founders include some organizers of Deep Learning Indaba, a machine learning conference most recently held in Tunisia, and Masakhane, a nonprofit that promotes open-source models and datasets for African languages. Co-founder Jade Abbott was profiled in DeepLearning.AI’s Working AI blog series.
Why it matters: Over 74 percent of foreign-born students who receive a PhD in AI from a school in the United States remain in the U.S. after graduating, last year’s State of AI report found. Lelapa’s founders hope their project will help Africa reclaim some of this talent, nurture native AI startups, and address systemic inequities in AI development.
We’re thinking: Sub-Saharan Africa accounts for 15 percent of the world’s population but fewer than 1 percent of AI patents and conference publications, according to the State of AI report. Organizations like Lelapa can help the region realize its potential.

Collaborative Text Generator
Text from current language models can be useful as a rough draft, but that leaves the polishing to human writers. A language model learned how to generate and respond to editorial directions.
What’s new: Timo Schick and colleagues at Meta proposed Plan, Edit, Explain, and Repeat (PEER), a text generator designed to collaborate with human writers.
Key insight: Data that demonstrates the motivations, execution, and results of editing is hard to come by. Wikipedia, in which every article includes a history of edits as well as comments on them, comes close, but an editor trained solely on Wikipedia would be limited to encyclopedia-style text. However, a model trained on Wikipedia to undo revisions can synthesize a supplemental dataset of unrevised and revised examples. Applying the undo function to varied text can generate synthetic “unedited” drafts for training the editor.
How it works: PEER comprises four T5 large language models: PEER-Edit (which executed revisions), PEER-Undo (which undid revisions), PEER-Explain (which explained revisions), and PEER-Document (which generated synthetic primary-source documents as a basis for revisions). The authors trained them on Wikipedia, 6.9 million examples that include texts before and after a revision, a revision plan (a directive to revise the text, such as “add information about the scandal”), an explanation (a reason for the revision, which may duplicate the revision plan), and cited documents (primary sources on which the text is based).
- Given an unrevised text and three cited documents, PEER-Edit learned to generate a revision plan and the revised text.
- PEER-Undo took the revised text and the same cited documents, and learned to generate the revision plan and unrevised text.
- PEER-Explain took the unrevised text, revised text, and cited documents and learned to generate an explanation.
- PEER-Document took the unrevised text, revised text, and revision plan and learned to generate one of the documents.
- The authors used the trained models to generate synthetic datasets based on articles in Wikinews (crowdsourced news articles) and StackExchange (questions and answers on topics including cooking, gardening, and politics). Using PEER-Undo, they generated synthetic unrevised texts to be paired with the published articles. PEER-Explain and PEER-Document generated the plans and documents.
- They further trained PEER-Edit on the generated datasets as well as Wikipedia.
- At inference, PEER-Edit took in unrevised text and generated a plan and a revised text. To collaborate with humans, it can either revise a text based on a user’s plan or generate a plan for a user to execute. Users can perform these tasks in any combination, any number of times.
Results: The authors evaluated PEER-Edit using SARI, a measure of similarity between two revised versions of a text relative to the unrevised original (higher is better). Comparing generated revisions to ground-truth revisions of Wikinews, the Wikipedia-trained PEER-Edit (175 billion-parameters) achieved 49.3 SARI, and the same architecture trained on the synthetic Wikinews dataset achieved 51.6 SARI. Both were more similar to the human revisions than was the unrevised text, which achieved 32.8 SARI. They also evaluated PEER-Edit on six tasks such as grammar correction and removal of biased words. Averaged across these tasks, a 175-billion parameter model achieved 44.3 SARI and a 3 billion-parameter version achieved 43.6 SARI. Prompted to perform the same tasks, InstructGPT (1.3 billion parameters) achieved 39.4 SARI, and Tk-Instruct (3 billion parameters, fine-tuned to correct grammar and simplify text) achieved 23.5 SARI.
Yes, but: Text generators can produce factually false statements. While PEER-Edit sometimes corrected misinformation, it also fabricated falsehoods, which it backed up by fabricating citations.
Why it matters: Training text generators to provide explanations for their decisions and citations for the facts they use may lead to more interpretable models.
We’re thinking: The raw output of generative models is fun and exciting, but imagine their potential as collaborators with creative people!
Data Points
Yoshua Bengio, Emad Mostaque, and others called for a moratorium on cutting-edge AI research
More than 1,000 AI leaders and researchers signed an open letter urging AI labs to pause the development of the most advanced systems for six-months, citing “risks to society.” (The New York Times)
Italy banned ChatGPT over privacy concerns
The Italian Data Protection Authority blocked OpenAI's chatbot for unlawfully collecting users’ personal data and lacking an age-verification system to protect minors. The regulator is set to investigate whether the company complied with the European Union’s General Data Protection Regulation (GDPR). (Politico)
UK proposes flexible rules to regulate AI
The Department for Science, Innovation and Technology (DSIT) published a white paper to guide the responsible use of AI in the UK. There will be no AI watchdog. Instead, a set of principles will guide existing regulators. (TechCrunch)
Research: Meta proposed an artificial visual cortex and adaptive sensorimotor coordination Meta announced key developments designed to enable AI-powered robots to function autonomously in the real world: A perception model trained on videos of people performing everyday tasks, called VC-1, and a technique that empowers robots to adjust their actions to varying environments, called ASC. (SiliconAngle)
Research: AI used to develop a molecular syringe to deliver proteins into human cells
Researchers harnessed DeepMind’s AlphaFold model, which predicts the 3D shapes of protein molecules, to adapt spikes from bacteria to deliver potentially therapeutic proteins into cells. This technique could pave the way for improved drug delivery systems and expand the applications of gene-editing techniques like CRISPR–Cas9. (Nature)
BuzzFeed’s AI writer “As Told to Buzzy” is generating complete articles The news and entertainment outlet recently started publishing AI-generated content, initially limiting it to quizzes. But the company’s text generator has produced more than 40 articles on travel, all of which feature identical expressions and structures. (Futurism)