
Dear friends,
Last week’s letter focused on coming up with AI project ideas, part of a series on how to build a career in the field. This letter describes how a sequence of projects might fit into your career path.
Over the course of a career, you’re likely to work not on a single AI project, but on a sequence of projects that grow in scope and complexity. For example:
- Class projects: The first few projects might be narrowly scoped homework assignments with predetermined right answers. These are often great learning experiences!
- Personal projects: You might go on to work on small-scale projects either alone or with friends. For instance, you might re-implement a known algorithm, apply machine learning to a hobby (such as predicting whether your favorite sports team will win), or build a small but useful system at work in your spare time (such as a machine learning-based script that helps a colleague automate some of their work). Participating in competitions such as those organized by Kaggle is also one way to gain experience.
- Creating value: Eventually, you gain enough skill to build projects in which others see more tangible value. This opens the door to more resources. For example, rather than developing machine learning systems in your spare time, it might become part of your job, and you might gain access to more equipment, compute time, labeling budget, or head count.
- Rising scope and complexity: Successes build on each other, opening the door to more technical growth, more resources, and increasingly significant project opportunities.
 |
In light of this progression, when picking a project, keep in mind that it is only one step on a longer journey, hopefully one that has a positive impact. In addition:
- Don’t worry about starting too small. One of my first machine learning research projects involved training a neural network to see how well it could mimic the sin(x) function. It wasn’t very useful, but was a great learning experience that enabled me to move on to bigger projects.
- Communication is key. You need to be able to explain your thinking if you want others to see the value in your work and trust you with resources that you can invest in larger projects. To get a project started, communicating the value of what you hope to build will help bring colleagues, mentors, and managers onboard — and help them point out flaws in your reasoning. After you’ve finished, the ability to explain clearly what you accomplished will help convince others to open the door to larger projects.
- Leadership isn’t just for managers. When you reach the point of working on larger AI projects that require teamwork, your ability to lead projects will become more important, whether or not you are in a formal position of leadership. Many of my friends have successfully pursued a technical rather than managerial career, and their ability to help steer a project by applying deep technical insights — for example, when to invest in a new technical architecture or collect more data of a certain type — allowed them to exert leadership that helped the project significantly.
Building a portfolio of projects, especially one that shows progress over time from simple to complex undertakings, will be a big help when it comes to looking for a job. That will be the subject of a future letter.
Keep learning!
Andrew
DeepLearning.AI Exclusive

Working AI: Making the Pivot
There's more to Kulsoom Abdullah than meets the eye: She's a competitive weightlifter and an avid traveler. She's also a former network security professional, but she never felt comfortable in that role. In the latest edition of Working AI, Kulsoom explains how she shifted to AI and never looked back.
Read her story
News

What AI Employers Want
A website that aggregates AI jobs revealed the roles that are most in-demand.
What’s new: Ai-jobs.net published its second annual list of the job titles that appeared most frequently in its listings. The site, which pulls from various hiring platforms and sells ads to employers, is maintained by Foorilla, a Zurich-based consultancy.
What they found: The list covers over 100 job titles in more than 2,500 listings posted between June 2021 and June 2022. The rankings are approximate because the listings in the site’s database change by the hour, an ai-jobs.net representative told The Batch. The snapshot used to compose the rankings is available here.
- The most common titles were data engineer (555 positions listed), data analyst (418), data scientist (398), and machine learning engineer (177).
- Autonomous vehicle specialists also were in high demand. Employers sought to fill titles including autonomous vehicle system test specialist (17 positions listed), autonomous vehicle system map specialist (11), and autonomous vehicle operations lead (8).
- 76 job titles appeared fewer than 10 times. These include financial data analyst (9), machine learning developer (7), and MLOps engineer (4).
- The top four titles in 2022 were also the most popular in 2021. However, last year the fifth most popular title was big data engineer. This year, the phrase “big data” disappeared from the top 20.
Why it matters: AI jobs continue to proliferate! Machine learning engineer was the fourth-fastest growing U.S. job title on the professional social network Linkedin between January 2017 and July 2021, but demand is growing for many other titles.
We’re thinking: Look at all the times the word “data” appears in the top titles! This speaks to the growing importance of systematically engineering the data used in AI systems.

Keep Your AIs on the Road
The European Union passed a law that requires new vehicles to come equipped with automated safety features.
What’s new: The new Vehicle General Safety Regulation compels manufacturers of new vehicles to include as standard features automatic speed control, collision avoidance, and lane-keeping. The systems cannot collect biometric data, and drivers must be able to switch them off. The law, which does not apply to two- or three wheeled vehicles, will take effect in July 2024.
How it works: Some requirements apply to all vehicles. Others govern light and heavy commercial vehicles:
- All vehicles must implement speed assistance. They must monitor safe and legal driving speed based on road signs, weather conditions, and other external cues. They must also provide feedback to speeding drivers (for instance an audio warning or reverse pressure on the acceleration pedal) In addition, they must detect when nearby vehicles drive in reverse.
- All vehicles must monitor drivers for distraction and drowsiness.
- They must keep a record of the vehicle’s state similar to an aircraft’s black box.
- Passenger cars and light commercial vehicles such as vans must include automatic lane keeping and braking to avoid collisions.
- Heavy commercial vehicles such as buses and trucks must implement warnings for lane keeping and braking; automated control is not required. They must detect hazards in blind spots and provide warnings of potential collisions with pedestrians and cyclists.
Behind the news: Automated safety features are increasingly common. In the U.S., 30 percent of new vehicles sold in the fourth quarter of 2020 were able to accelerate, decelerate, and steer on their own.
- The European Parliament plans later this year to legalize the sale of up to 1,500 fully autonomous vehicles per model per year.
- Canada is exploring a requirement that new cars include automated braking, lane keeping, and speed assistance.
- U.S. lawmakers proposed a law that would require driver-monitoring systems.
Why it matters: The European Commission estimates that 19,800 people died in road accidents in 2021. AI-powered safety features may help the governing body reach its goal of halving road fatalities by 2030 and eliminating them altogether by 2050.
We’re thinking: Although these regulations were designed to address important safety concerns, some of them, such as automatic speed monitoring and feedback, can also reduce vehicle emissions, which would be good for the planet.
A MESSAGE FROM DEEPLEARNING.AI
 |
Why did Mahsa Zamanifard, a sales executive with an interest in data analysis, enroll in Andrew Ng’s Machine Learning course? Let her tell you herself! #BreakIntoAI too with the new Machine Learning Specialization
Cutting the Carbon Cost of Training
You can reduce your model’s carbon emissions by being choosy about when and where you train it.
What’s new: Researchers at the Allen Institute for AI, HuggingFace, Microsoft, the University of Washington, Carnegie Mellon University, and the Hebrew University of Jerusalem developed a tool that measures atmospheric carbon emitted by cloud servers while training machine learning models. After a model’s size, the biggest variables were the server’s location and time of day it was active.
How it works: The authors’ calculations account for kilowatt hours used by a cloud computing system, emissions from the local electrical grid, and emissions while manufacturing and disposing of the system’s hardware. They based their method on an approach developed by the Green Software Foundation.
- The authors trained or fine-tuned 11 language and vision models: two BERTs, one 6.1 billion-parameter Transformer language model (which they trained only to 13 percent completion), three DenseNets with parameter counts ranging from 8 million to 20 million, and five Vision Transformers from 20 million to 632 million parameters.
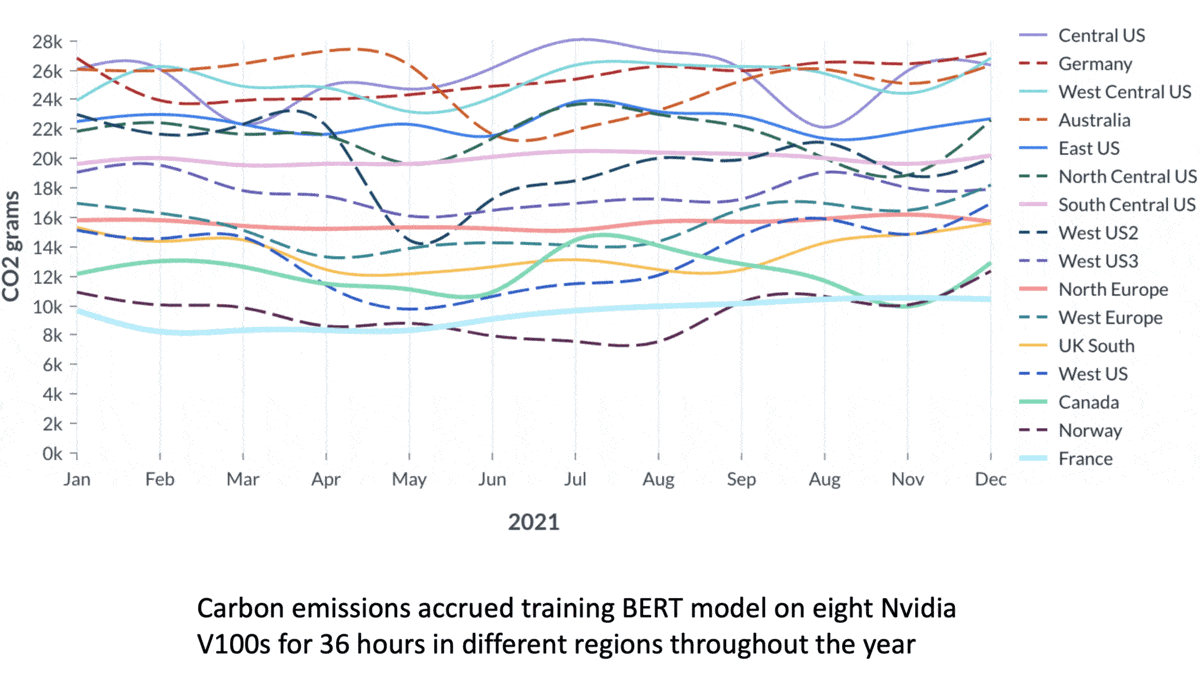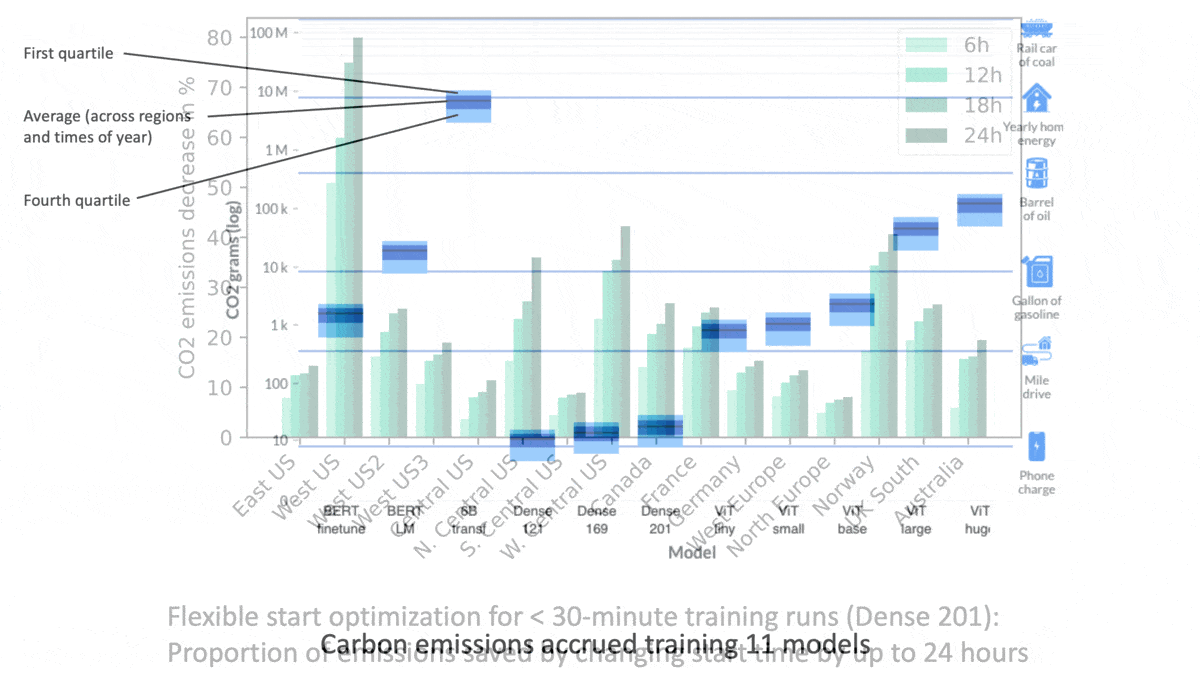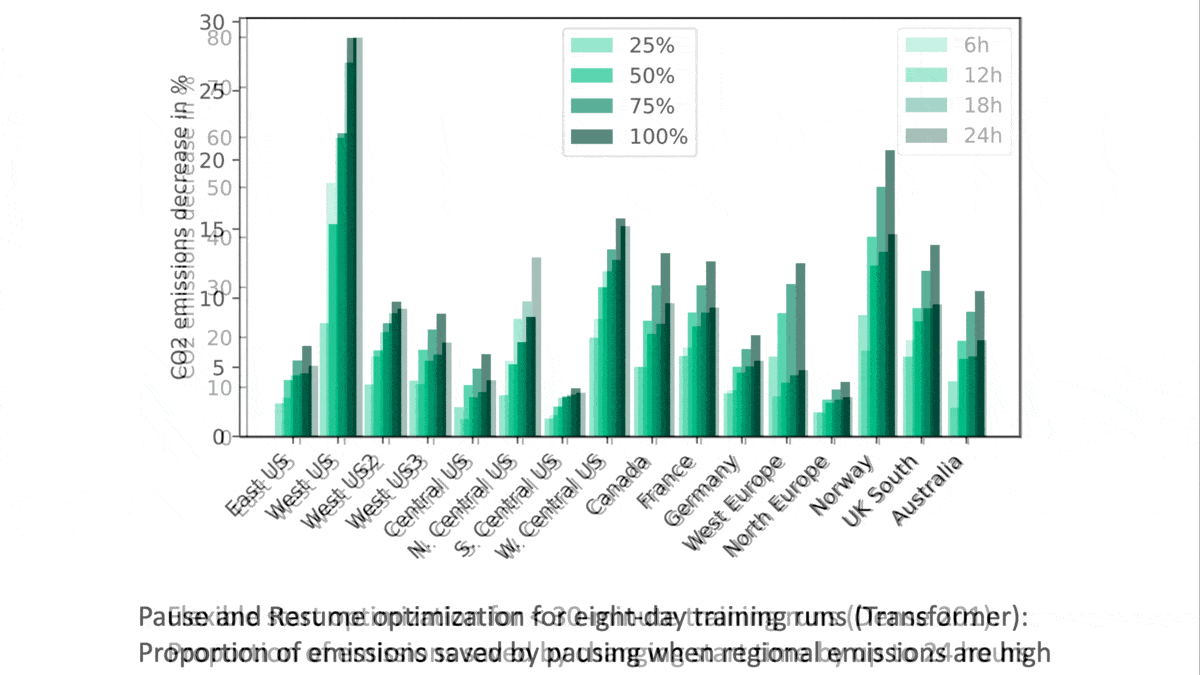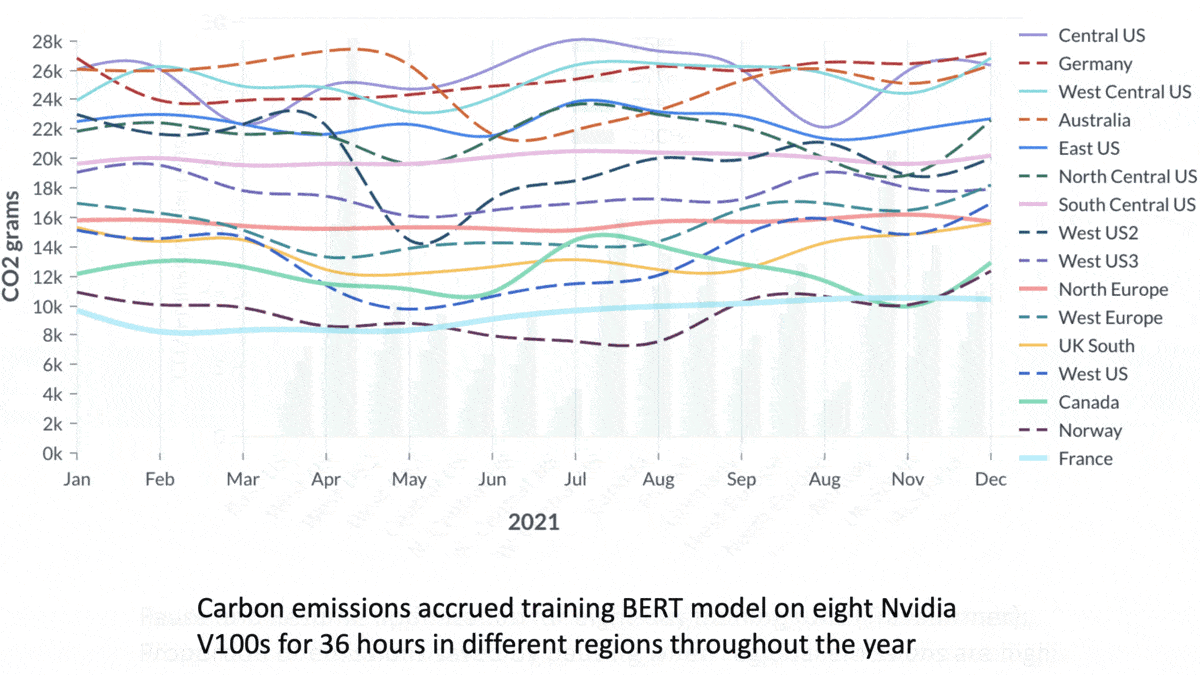
- They drew on data that described the carbon cost of generating electricity in eight U.S. regions, six European regions, and one region each in Canada and Australia. They used historical data to analyze how emissions would differ depending on the time of day or year.
- They tested the impact of two emissions-reduction options offered by Microsoft’s Azure Cloud. Flexible Start starts processing at times that are expected to reduce carbon emissions. Pause and Resume processes intermittently during low-emission time frames.
Results: Training a model in a low-emissions region like France and Norway could save over 70 percent of the carbon that would be emitted in a carbon-heavy region like the central United States or Germany.
- The time of day had a subtle impact on emissions. Starting a training run at midnight, for instance, increased emissions by 8 percent compared to starting at 6:00 a.m.
- The Azure Cloud options had little impact on emissions released in training smaller models over short periods of time (less than 30 minutes). However, when training the 6.1 billion-parameter transformer over eight days, they cut emissions by up to 25 percent.
Yes, but: A 2021 study found that large transformers consume more energy, and yield more carbon emissions, during inference than training.
Behind the news: Energy consumption and the associated carbon emissions are growing concerns as machine learning models and datasets balloon.
- A 2019 study of deep learning’s carbon footprint found that training a single large language model could release the same quantity of CO2 as a car over five years of driving.
- Last year, the MLPerf processing benchmark added an energy-efficiency test.
Why it matters: Atmospheric carbon is causing changes in climate that are devastating many communities across the globe. Data centers alone accounted for 1 percent of electricity consumed globally in 2020 (although the portion of data center usage devoted to AI is unknown). Machine learning engineers can do their part to reduce carbon emissions by choosing carefully when and where to train models.
We’re thinking: It's impractical to expect every team to minimize carbon emissions by choosing times and locations to process training jobs. We urge cloud providers to consider pricing and other signals that would help — better yet, incentivize — engineers to cut emissions.
 |
Learning From Metadata
Images in the wild may not come with labels, but they often include metadata. A new training method takes advantage of this information to improve contrastive learning.
What’s new: Researchers at Carnegie Mellon University led by Yao-Hung Hubert Tsai and Tianqin Li developed a technique for learning contrastive representations that trains image classifiers on image metadata (say, information associated with an image through web interactions or database entries rather than explicit annotations).
Key insight: In contrastive learning, a model learns to generate representations that position similar examples nearby one another in vector space, and dissimilar examples distant from one another. If labels are available (that is, in a supervised setting), a model learns to cluster representations of examples with the same label and pushes apart those with different labels. If labels aren’t available (that is, in an unsupervised setting), it can learn to cluster representations of altered examples (say, flipped, rotated, or otherwise augmented versions of an image, à la SimCLR). And if unlabeled examples include metadata, the model can learn to cluster representations of examples associated with similar metadata. A combination of these unsupervised techniques should yield even better results.
How it works: The authors trained separate ResNets on three datasets: scenes of human activities whose metadata included 14 attributes including gender, hairstyle, and clothing style; images of shoes whose metadata included seven attributes like type, materials, and manufacturer; and images of birds whose metadata included 200 attributes that detail beak shape and colors of beaks, heads, wings, and breasts, and so on.
- Given a set of images and metadata, the authors divided the images roughly evenly into many groups with similar metadata.
- To each group, they added augmented variants (combinations of cropping, resizing, recoloring, and blurring) of every image in the group.
- The ResNet generated a representation of each image. The loss function encouraged the model to learn similar representations for images within a group and dissimilar representations for images in different groups.
- After training the ResNet, they froze its weights. They appended a linear layer and fine-tuned it on the dataset’s labels.
Results: The authors compared their method to a self-supervised contrastive approach (SimCLR) and a weakly supervised contrastive approach (CMC). Their method achieved greater top-1 accuracy than ResNets trained via the SimCLR in all three tasks. For instance, it classified shoes with 84.6 percent top-1 accuracy compared to SimCLR’s 77.8 percent. It achieved greater top-1 accuracy than ResNets trained via CMC in two tasks. For example, it classified human scenes with 45.5 percent top-1 accuracy compared to CMC’s 34.1 percent.
Yes, but: The supervised contrastive learning method known as SupCon scored highest on all three tasks. For instance, SupCon classified shoes with 89 percent top-1 accuracy.
Why it matters: Self-supervised, contrastive approaches use augmentation to improve image classification. A weakly supervised approach that takes advantage of metadata builds on such methods to help them produce even better-informed representations.
We’re thinking: The authors refer to bird attributes like beak shape as metadata. Others might call them noisy or weak labels. Terminology aside, these results point to a promising approach to self-supervised learning.