
Dear friends,
Last week, I described trends that AI Fund, the venture studio I lead, has seen in building AI startups. I'd like to discuss another aspect of building companies that’s unique to AI businesses: the controversial topic of data moats.
A company has a data moat if its access to data makes it difficult for competitors to enter its business. Moat is a common business term used evoke the water-filled moats built around castles to make them easier to defend against attackers. For example, if a self-driving car company can acquire far more data than its competitors to train and test its system, and if this data makes a material difference in the system’s performance, then its business will be more defensible.
For a few years, some investors asked every AI startup’s founders about its data moat, as if they expected everyone to build one. But, like many things in AI, it depends. A data moat can provide protection, but its effectiveness varies depending on the specific circumstances of the business.
For instance, a data moat may not do much to protect an AI business if:
- System performance plateaus with more data. Say you're building a general-purpose speech recognizer, and human-level performance is 95 percent accurate. Collecting enough data to achieve 94 percent accuracy is hard, and getting incrementally more data will have diminishing returns. In fact, it’s much easier for a competitor to improve from 90 to 91 percent accuracy than for you to improve from 94 to 95 percent.
- Data doesn’t change over time. If the mapping from input x to output y remains the same (as in speech recognition, where the input spoken words “The Batch” will continue to map to their text equivalents for a long time), competitors will have time to accumulate data and catch up.
- The application can be built with a smaller dataset thanks to new data-centric AI development technologies, including the ability to generate synthetic data, and tools that systematically improve data quality.

In contrast, data can make an AI business more defensible if:
- Performance keeps improving materially within the range of dataset size that a company and its competitors can reasonably amass. For example, web searches form a very long tail of rare queries, which make up a large fraction of all searches. Thus, performance keeps improving for a long time as a search engine gets more clickstream data, and a dominant search engine can stay ahead of smaller outfits that try to bootstrap with little data. Generally, larger datasets tend to confer a longer-lasting benefit on applications where a large fraction of relevant data makes up a long tail of rare or hard-to-classify events.
- The data distribution varies significantly over time. In this case, access to an ongoing stream of fresh data is critical for keeping the machine learning model current, which in turn earns further access to the data stream. I believe this is one of the factors that makes social media companies especially defensible. The topics posted change regularly, and the ability to keep the system up-to-date helps increase its appeal relative to new competitors.
- The market has winner-take-all dynamics, and users have low switching costs. When a market supports only one leader, access to data that delivers even marginally better performance can be a major advantage. For instance, a ride-sharing company whose data pipeline enables passengers to reach rider destinations faster is likely to attract the most riders.
- Access to customer data significantly increases switching costs, reduces churn, or increases the ability to upsell. This is especially true if customers would have a hard time exporting or even making sense of their own data if they were to patronize a competitor.
Data strategy is important for AI companies, and thinking through how a system’s performance varies with the amount of data, the importance of fresh data, and other factors described above can help you decide how much having data adds to a business’ defensibility. Sometimes a data moat doesn't help at all. But in other cases, it's one pillar (hopefully among many) that makes it harder for competitors to catch up.
Keep learning!
Andrew
News
GPT-Free
Itching to get your hands on a fully trained large language model? The wait is over.
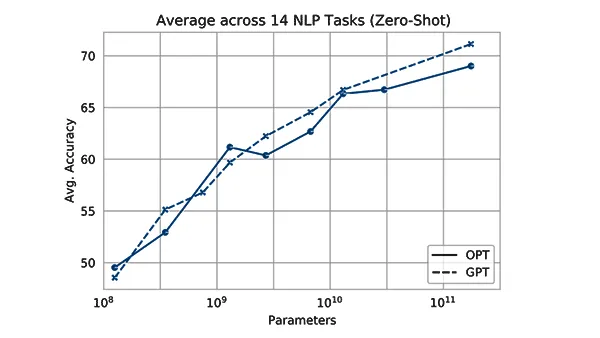
What’s new: Meta introduced the OPT family of transformer-based language models with nearly unfettered access to source code and trained weights. The family’s eight models range in size from 125 million to 175 billion parameters.
How it works: The OPT architecture is similar to that of OpenAI’s GPT-3. The models were trained on publicly available datasets that include novels, news articles, Reddit posts, and a subset of The Pile.
- The 175 billion parameter version, OPT-175B, is designed to approximate GPT-3. It has the same number of parameters, performs with comparable accuracy, and shows a similar propensity to generate worrisome output. It’s available for non-commercial use to researchers affiliated with organizations in academia, industry, government, and civil society but not to military researchers or those who work with biometric or surveillance data. You can request access here.
- The smaller versions — 125 million, 350 million, 1.3 billion, 2.7 billion, 6.7 billion, 13 billion, and 30 billion parameters — are freely available to anyone. Meta hopes this will encourage researchers to study the effects of varying scale.
- The release includes a log that documents successes, failures, bugs, and breakthroughs the team encountered while training OPT-175B over three months.
Behind the news: OPT-175B is the largest and most ambitious open-source language model to date, but it’s not the first.
- Last year, Google published the code library for the 1.6 trillion parameter Switch Transformer. It didn’t provide access to the trained weights.
- In February, the machine learning collective EleutherAI released its trained 20 billion-parameter GPT-NeoX. The group is also responsible for The Pile, an 812-gigabyte compilation of 22 text datasets.
- Hugging Face's BigScience project aims to release a trained 200 billion-parameter language model. So far, it has open-sourced the 11 billion parameter T0 series.
Yes, but: A parameter count of 175 billion parameters is mouthwatering, but it takes a lot of horsepower to drive a model that large. As Maarten Sap of the Allen Institute for Artificial Intelligence told IEEE Spectrum, “[I’d] love to use OPT-175B,” but “few research labs actually have the infrastructure to run this model.”
Why it matters: For researchers — well, for anyone interested in language modeling, really — the opportunity is obvious. OPT comes pretrained, ready to be used, fine-tuned, dissected, or adapted for any purposes the AI community dreams up. No more APIs! No more paywalls! It’s your party, so indulge yourself. For Meta, open-sourcing these models may have several benefits. Giving away OPT is a community-minded gesture at a time when the company has been under fire for proliferating hatred, misinformation, and disinformation on a grand scale. It’s a bid to attract talent that could help break in young engineers to the company’s coding practices. And it’s a shot at OpenAI, the former nonprofit, open-source shop, which was criticized for keeping GPT-3’s code under wraps.
We’re thinking: The OPT-175B training log offers a rare look at a large-scale machine learning project. While the mass media may imagine bespectacled programmers in airy, well-lit rooms debating the nature of intelligence, technology development is often messy as researchers struggle to visualize what an algorithm is doing or trace the source of a GPU crash. Worth a look!

Nurse’s Mechanical Helper
Hospitals are using robots to lighten the load on clinical staff.
What’s new: A number of U.S. hospitals are using Moxi, a robot from Diligent Robotics, to ferry supplies, lab specimens, soiled laundry, and other items, Wired reported.
How it works: Moxi is four feet tall with blinking L.E.D. eyes and an articulated arm tipped with a rubber grip. It navigates using a front-facing camera, rear-facing lidar, and auditory cues. A secure compartment that can be unlocked by a radio-frequency badge holds sensitive items such as lab samples. Fifteen Moxi robots are operating in U.S. hospitals, and another 60 are scheduled for deployment this year.
- The robot spends its first weeks in a new hospital learning to navigate the building’s layout, including elevators and room numbers. It uses object recognition to identify items and stores their location, color, shape, and other features. It uses this data to build a map of its surroundings.
- Faced with an unfamiliar task, it can request guidance. A human can teach Moxi by physically moving its arm to perform a desired action while giving voice commands that prompt the learning algorithm to note the motion. For instance, to teach it to pick up and move an object, the teacher might say “start here,” move the arm and say “go here,” and make the robot grasp the object and say “grab this.” The algorithm also notes the item’s weight, appearance, and sound it makes when handled.
- Given access to a periodic, anonymized health report that updates a patient’s condition, Moxi can deliver appropriate supplies and verify that a sign outside the room matches the patient’s current status.
- It connects to the cloud using wi-fi but uses LTE as a backup when a hospital’s network is inadequate, a common issue in the company’s experience.
- Clinical staff can assign chores at a kiosk or via text message.
Behind the news: In 2020, the American Nurses Association assessed Moxi’s performance in three Texas hospitals. The study found that the robots improved nurse productivity and reduced feelings of burnout. However, the robots struggled to navigate crowded hospital halls, and their inability to read expiration dates raised the worry that they might contribute to adverse consequences.
Why it matters: Robots may not have the best bedside manner (yet), but they can create much-needed breathing room for human caregivers. In a 2021 survey of U.S. nurses, 83 percent of respondents said their shifts were understaffed in a way that affected patients’ safety half of the time, and 68 percent had considered leaving the profession. Meanwhile, the U.S. is one of many countries with a rapidly growing population of elderly people, putting further strain on the healthcare system. These conditions create a clear opening for robots capable of performing many low-risk, repetitive chores.
We’re thinking: Come to think of it, Hippocrates’ dictum “first, do no harm” bears a striking similarity to Asimov’s First Law of Robotics, “a robot may not harm a human being.”
A MESSAGE FROM DEEPLEARNING.AI

What’s new about the revised Machine Learning Specialization that’s set to launch in June? It takes the core curriculum — vetted by millions of learners — and makes it more approachable by balancing intuition, code, and math for beginners. Pre-enroll now

Hit Picker
A neural network may help an online music service to spot songs with the potential to go big.
What’s new: Musiio uses AI to identify specific attributes and qualities in recorded music. Online audio distributor SoundCloud purchased the Singapore-based startup, which was valued at $10 million last year, for an undisclosed sum.
How it works: Musiio trained its model on a proprietary database of songs, each tagged with dozens of labels including genre, vocalist’s gender, instruments featured, and emotions expressed.
- Musiio’s technology drives a number of services including automated tagging of up to 1 million songs a day, audio search, a tool that combs a publisher’s catalog for weak material, and one that helps agents discover new talent.
- A demo released in 2019 enabled users to upload a song and generate labels for genre, key, tempo, energy level, and emotion. For instance, the demo might have labeled a song as instrumental, “moderate energy” with “small variance,” and a 72 percent probability of being “dark.”
Behind the news: A number of companies offer AI-powered tools designed to enable recording companies, artists, and fans to squeeze more value out of music.
- Fwaygo lets artists upload short video clips, which an algorithm will recommend based on a listener’s preferences. Fwaygo recently partnered with music distributor TuneCore, which supplies music to Amazon, iTunes, and Spotify.
- InGrooves, a music marketing firm owned by Universal, patented a system that generates social media posts that feature songs selected by an algorithm to appeal to a certain audience.
Why it matters: Millions of new songs are released every year. Amid the deluge, AI can help distributors recognize potential hits, recording companies identify talent, fans find music they like, and musicians create sounds that stand out. Of course, the makings of a hit include social dynamics among listeners — presumably that’s where acquirer SoundCloud comes in.
We’re thinking: According to models, this edition of The Batch has moderate energy with high variance and a 72 percent chance of being powerful.

Image Generation + Probabilities
If you want to both synthesize data and find the probability of any given example — say, generate images of manufacturing defects to train a defect detector and identify the highest-probability defects — you may use the architecture known as a normalizing flow. A new type of layer enables users to boost a normalizing flow’s performance by tuning it to their training data.
What’s new: Gianluigi Silvestri at OnePlanet Research Center and colleagues at Google Research and Radboud University introduced the embedded-model flow (EMF). This architecture uses a probabilistic program — a user-defined probability distribution — to influence the training of a normalizing flow.
Normalizing Flow basics: A normalizing flow (NF) is a generative architecture. Like a generative adversarial network (GAN), it learns to synthesize examples similar to its training data. Unlike a GAN, it also learns to calculate the likelihood of existing examples. During training, an NF transforms examples into noise. At inference, it runs in reverse to transform noise into synthetic examples. Thus it requires layers that can execute both forward and backward; that is, layers that are invertible as well as differentiable.
Key insight: Like a normalizing flow layer, the cumulative distribution function (CDF), which is a function of a probability distribution, can be both differentiable and invertible. (In cases where this is not true, it’s possible to approximate the CDF’s derivative or inverse.) The CDF of a probability distribution can be used to compute that distribution, so it can be used to create a probabilistic program. Such a program, being differentiable and invertible, can be used in an NF, where it can transform a random vector to follow a probability distribution and vice versa.
How it works: EMF is a normalizing flow composed of three normalizing flow layers and a user-defined probabilistic program layer. The authors used a dataset of handwritten digits to train the model to generate digits 0 through 9.
- The authors built a probabilistic program using a Gaussian hierarchical distribution, which models a user-defined number of populations (in this case, 10 digits).
- They modeled the distribution using the CDF and implemented the resulting function as a probabilistic program layer.
- The probabilistic program layer learned to transform the distribution’s 10 populations into random noise. This helped the normalizing flow layers learn to allocate various digits to different parts of the distribution.
- At inference, the authors reversed the network, putting the probabilistic program layer first. It transformed a random vector into the distribution of 10 populations, and the other layers produced a new image.
Results: The authors compared EMF with a baseline made up of a comparable number of normalizing flow layers. Generating examples in the test set, it achieved a negative log likelihood of 1260.8, while the baseline scored 1307.9 (lower is better). EMF outperformed similar baselines trained for other tasks. For instance, generating solutions to the differential equations for Brownian motion, it achieved a negative log likelihood of -26.4 compared to the baseline’s -26.1.
Yes, but: A baseline with an additional normalizing flow layer achieved a better negative log likelihood (1181.3) for generating test-set digits. The authors explain that EMF may have underperformed because it had fewer parameters, although they don’t quantify the difference.
Why it matters: Normalizing flows have their uses, but the requirement that its layers be invertible imposes severe limitations. By proposing a new layer type that improves their performance, this work makes them less forbidding and more useful. In fact, probabilistic programs aren’t difficult to make: They’re easy to diagram, and the authors offer an algorithm that turns such diagrams into normalizing flow layers.
We’re thinking: The authors achieved intriguing results with a small model (three layers, compared to other work and dataset (10,000 examples compared to, say, ImageNet’s 1.28 million). We look forward to learning what EMF-style models can accomplish with more and wider layers, and with larger datasets like ImageNet.