
Dear friends,
I’ve seen many new technologies go through a predictable process on their journey from idea to large scale adoption.
- First, a handful of experts apply their ideas intuitively. For example, 15 years ago, a handful of individuals were building neural networks from scratch in C++. The work was error-prone, and only a small number of people knew how to get such models to work.
- As the ideas become more widespread and publications describe widely applicable principles, more people can participate. In the example above, around five years later, a growing number of people were able to code up deep learning models in C++. It was still error-prone, but knowledge of how to do it became more widespread.
- Eventually, developer tools make it much easier for many people to take part. For instance, frameworks like TensorFlow and PyTorch made building neural networks simpler and more systematic, and implementations were much less likely to fail due to a stray C++ pointer.
The data-centric AI movement is going through such a process. Data-centric AI is the growing discipline of systematically engineering the data needed to build successful AI systems. This contrasts with the model-centric approach, which focuses on inventing and tuning machine learning model architectures while holding the data fixed.
Experienced machine learning practitioners have been engineering data by hand for decades. Many have made learning algorithms work by improving the data — but, even when I was doing it years ago, I didn’t have the language to explain why I did things in a certain way.
 |
Now more and more teams are articulating principles for engineering data. I’m seeing exciting processes for spotting data inconsistencies, accelerating human labeling, applying data augmentation, and crowdsourcing more responsibly. Finally, just as TensorFlow and PyTorch made building neural networks more systematic, new tools are starting to emerge. Landing AI (where I am CEO) is building a platform for computer vision applications, and I expect many more tools to be built by different companies for different applications. They will enable teams to take what once was an ad hoc set of ideas and apply the right process at the right time.
The tech community has gone through this process for code versioning (leading to tools like git) and transfer learning (where GPT-3, which was pre-trained on a massive amount of text, represents an early version of a tool). In less mature areas like reinforcement learning, I believe we’re still developing principles.
If you’re interested in learning more about the principles and tools of data-centric AI, we’re holding a workshop at NeurIPS on December 14, 2021. Dozens of great researchers will present poster sessions and lectures on cutting-edge topics in the field.
Keep learning!
Andrew
News
 |
Which Drug Helps Your Depression?
People seeking treatment for depression often experiment with different medications for months before finding one that works. Machine learning may remove some of the guesswork.
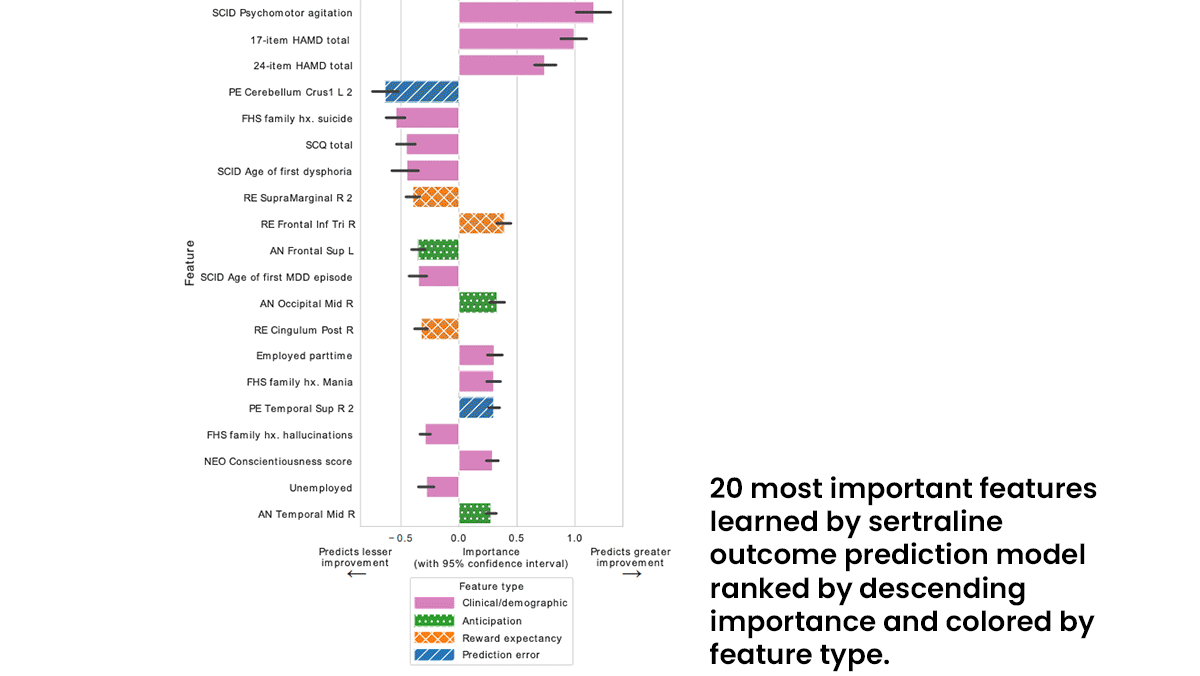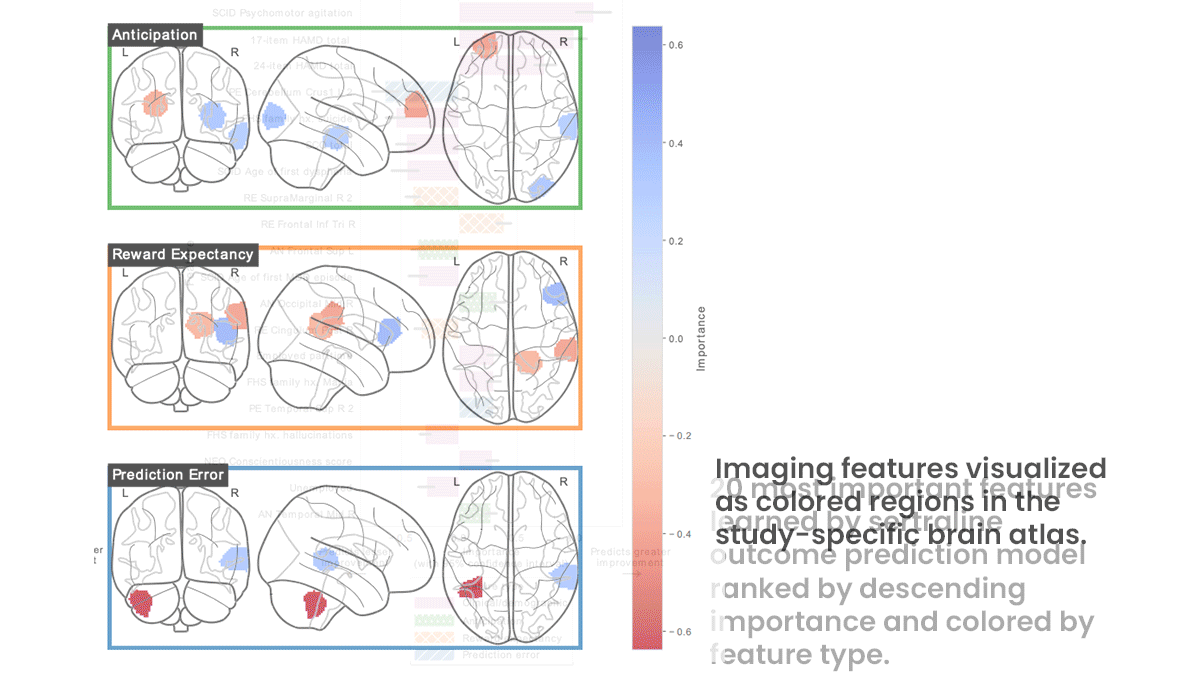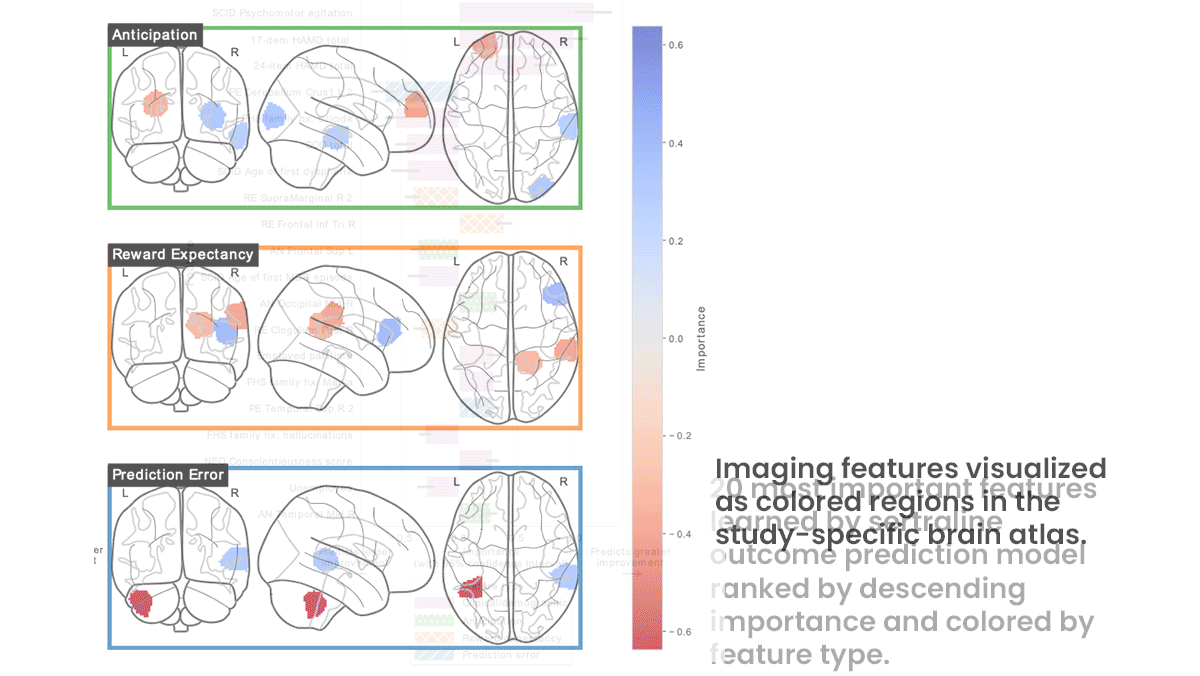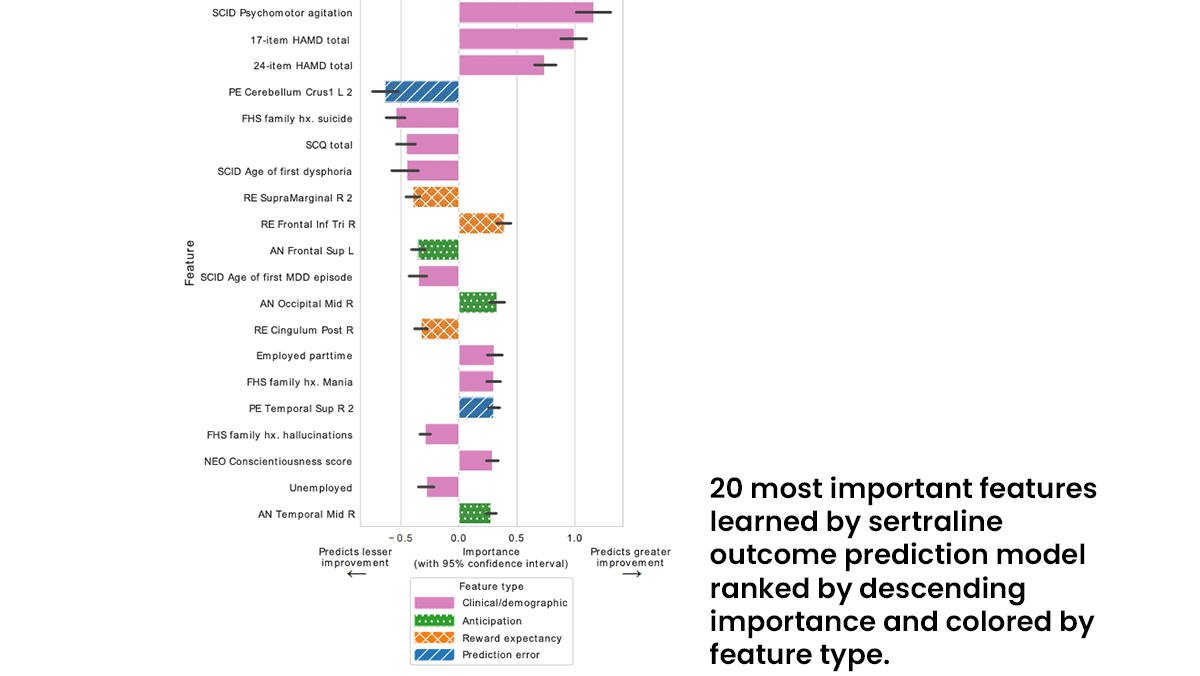
What’s new: Deep learning can predict how patients will respond to two antidepressant medicines, according to a study led by Albert Montillo and Madhukar Trivedi at University of Texas Southwestern Medical Center.
Key Insight: Patients with depression show various patterns of depressed brain activity in brain scans. At the same time, they vary in their reported responses to different drugs. Given brain scans of depressed people and their reports of effective treatment, a neural network can learn to match patients with medications likely to relieve their symptoms.
How it works: The authors trained separate vanilla neural networks to predict the change in patients’ depression levels after treatment with each of two drugs as well as placebo.
- The authors trained and tested their models on data from two clinical trials. The first included 222 patients who had been diagnosed with major depressive disorder. About half received sertraline (Zoloft), and the other half received a placebo. The second included 37 participants in the first trial who had not responded to sertraline. They received bupropion (Wellbutrin) instead.
- The dataset included 95 clinical and demographic features such as suicide risk, level of anxiety, race, and age.
- It also included each patient’s self-reported depression level at the beginning and end of an eight-week treatment period.
- Before undergoing treatment, the patients had received functional magnetic resonance imaging (fMRI) scans, which indicate neuronal activity, while playing a number-guessing game that triggers brain functions known to be altered by depression. The authors augmented the scans using a method that changes them in a realistic manner. They partitioned the real and synthetic scans into 200 regions and quantified brain activity using three metrics, yielding 600 features per scan.
Results: The authors evaluated their models on held-out data according to R2 value, a measure of performance in which 100 percent is perfect. The sertraline model achieved an R2 value of 48 percent. The bupropion model achieved 34 percent. Techniques that use brain scans to predict a patient’s response to drugs without deep learning have achieved R2 values around 15 percent, Montillo told The Batch.
Why it matters: Millions of adults suffer from major depression, and one-third of those try at least three drugs before settling on one. Moreover, many doctors are influenced by outcomes they observe in a handful of patients and aren’t able to systematically analyze data from a large cohort. Reliable predictions about which medicines are likely to work best — even if they’re far from perfectly accurate — could make a difference.
We’re thinking: Bringing this work into clinical practice would require training models to classify responses to many other antidepressants. The authors plan to apply their method to drugs beyond the two in this study, and we look forward to their progress.
 |
AI Goes Underground
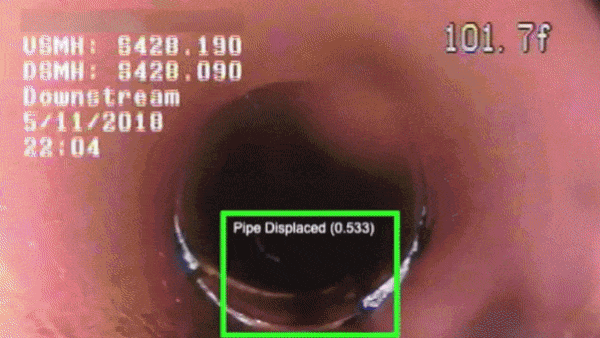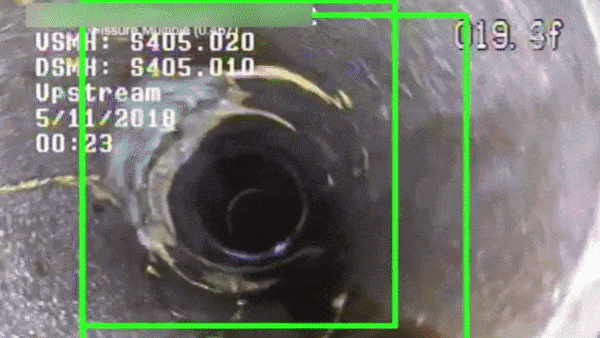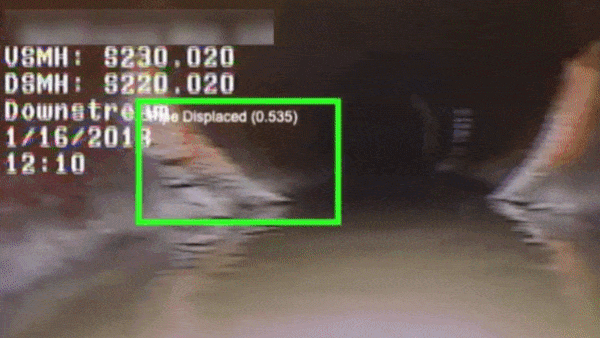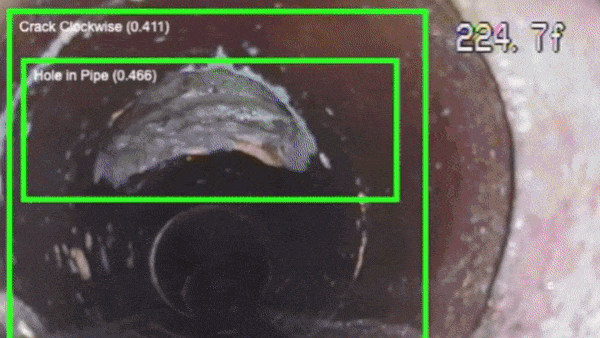
Computer vision systems are surveying sewers for signs of decay and degradation.
What’s new: A system from California startup SewerAI analyzes videos of underground pipes to prioritize those in need of repair.
How it works: SewerAI’s computer vision system classifies defects like cracks, holes, displacements, tree roots, and incursions in videos taken by sewer-crawling robots and human inspectors.
- The system was trained on 100,000 videos taken during sewer pipe inspections, amounting to about 3 million minutes of imagery, CEO Matthew Rosenthal told The Batch.
- The company serves dozens of clients, largely cities or their contractors, across the U.S. and parts of Canada. It enables HK Solutions Group to inspect 200,000 feet of pipe monthly and complete tasks in one day that formerly required weeks or months, an HK representative told The Wall Street Journal.
Behind the news: AI is doing the dirty work for a growing number of companies.
- DC Water, the water utility in the U.S. capital, collaborated with Intel and the information-technology company Wipro to develop a fully automated pipe inspector. Their Pipe Sleuth identifies defects in videos captured by autonomous crawlers made by Pennsylvania-based RedZone Robotics.
- IBAK, a German maker of pipe-inspection systems, is training a defect classifier on data supplied by users of its camera system.
Why it matters: Failed pipes can cause flooding, spread disease, and pollute water sources. In 2019, the American Society of Civil Engineers estimated the cost of shoring up the U.S. wastewater infrastructure at $129 billion — at least $81 billion more than lawmakers allocated in a recent law. By helping human inspectors prioritize repairs, computer vision could help stretch those dollars across more miles of pipe.
We’re thinking: Would we rather let a robot inspect sludge-filled pipes than do it ourselves? Sewer we would!
A MESSAGE FROM DEEPLEARNING.AI
 |
Start our Machine Learning Engineering for Production (MLOps) Specialization today! Learn how to design, build, and maintain integrated systems using well-established tools and methods. Enroll now
 |
Everyone Has a Voice
Google is improving speech recognition for people who have conditions that affect their ability to pronounce words.
What’s new: Project Relate is an Android app that offers a personalized speech recognition model for people whose speech is impaired or otherwise atypical. It’s designed to understand, transcribe, and synthesize speech for both person-to-person and person-to-machine interactions.
How it works: Researchers trained Relate using over a million speech samples collected from people with conditions including amyotrophic lateral sclerosis, cerebral palsy, Down syndrome, Parkinson’s disease, stroke, or traumatic brain injury. Users can fine-tune the system to their own voices by speaking 500 phrases.
- Relate transcribes speech to text in real time, restates what the user says in a synthesized voice, and translates the user’s voice commands for Google Assistant, such as dimming lights or playing music.
- It builds on previous Google projects. Parrotron is an LSTM-based sequence-to-sequence model that translates spoken words into synthesized speech. Another, unnamed project allowed researchers to develop fine-tuned speech recognition models using a speech-to-text network known as a recurrent neural network transducer.
- Google is recruiting English-speaking volunteers in Australia, Canada, New Zealand, and the U.S. to provide feedback to the beta-test version.
Behind the news: Recognizing the need to make their products more inclusive, tech companies have launched initiatives to make apps more accessible.
- Israeli startup Voiceitt developed a smartphone app that translates impaired speech into a synthesized voice for Amazon Alexa. Like Relate, it can be fine-tuned on a user’s voice.
- Apple is training Siri to recognize words spoken by people who stutter using audio clips of stuttered speech.
- AccessiBe has had mixed results with its accessibility tech, which uses object recognition to generate video captions and transcripts. The company recently was caught up in a lawsuit by disability advocates who said that its technology often mislabels images, making it harder for visually impaired people to navigate the web.
Why it matters: People whose speech is atypical can be excluded from social interactions, have trouble communicating when they need help, and experience difficulty using voice-activated devices. Technology that lets them be heard could make their lives richer, safer, and more engaging.
We’re thinking: Speech recognition is a convenience for most people, but for those with unusual speech patterns, it could be a lifeline.
 |
A Deeper Look at Graphs
Neural networks designed to process datasets in the form of a graph — a collection of nodes connected by edges — have delivered nearly state-of-the-art results with only a handful of layers. This capability raises the question: Do deeper graph neural networks have any advantage? New research shows that they do.
What’s new: Ravichandra Addanki and colleagues at DeepMind probed the impact of depth on the performance of graph neural networks.
GNN basics: A graph neural network (GNN) operates on graphs that link, for instance, customers to products they've purchased, papers to the other papers they cite, or pixels adjacent to one another in an image. A GNN typically represents nodes and edges as vectors and updates them iteratively based on the states of neighboring nodes and edges. Some GNNs represent an entire graph as a vector and update it according to the representations of nodes and edges.
Key insight: Previous work found that adding a few layers to a shallow GNN barely improved performance. That study used graphs that comprised hundreds of thousands of nodes and edges. Since then, graphs have emerged with hundreds of millions of nodes and edges. Deeper GNNs may achieve superior performance on these larger datasets.
How it works: The authors built GNNs up to more than 100 layers deep, including an encoder (a vanilla neural network), a graph network made up of message-passing blocks (each a trio of vanilla neural networks), and a decoder (another vanilla neural network). Among other experiments, they trained a GNN on 4 million graphs of molecules, in which nodes are atoms and edges are bonds between them, to estimate a particular key property called the HOMO-LUMO gap. (This property helps determine a molecule’s behavior in the presence of light, electricity, and other chemicals.)
- Given a graph, the encoder generated an initial representation of each edge, each node, and the entire graph.
- A series of message passing blocks updated the representations iteratively: (1) A three-layer vanilla neural network updated each edge representation based on the previous representation, the two nodes on either side, and the graph. (2) A three-layer vanilla neural network updated each node representation based on the previous representation, all connected edges, and the graph. (3) A three-layer vanilla neural network updated the graph representation based on the previous representation, all edges, and all nodes.
- Given the final representation of the graph, the decoder computed the HOMO-LUMO gap.
- To improve the representations, the authors used Noisy Nodes self-supervision, which perturbed the representations of nodes or edges and penalized the GNN depending on how well it reconstructed them.
Results: The authors tested GNNs with different numbers of message-passing blocks. Performance on the validation set improved progressively with more message-passing blocks up to 32 — 104 layers total — but showed no benefit beyond that depth. A version with 8 message-passing blocks achieved ~0.128 mean absolute error, one with 16 achieved ~0.124 mean absolute error, and one with 32 achieved ~0.121 mean absolute error.
Why it matters: Not all types of data can be represented easily as an image or text — consider a social network — but almost all can be represented as a graph. This suggests that deep GNNs could prove useful in solving a wide variety of problems.
We’re thinking: CNNs and RNNs have become more powerful with increasing depth. GNNs may have a lot of room to grow.