
Dear friends,
In earlier letters, I discussed some differences between developing traditional software and AI products, including the challenges of unclear technical feasibility, complex product specification, and need for data to start development. This time, let’s examine the further challenge of additional maintenance cost.
Some engineers think that when you deploy an AI system, you’re done. But when you first deploy, you may only be halfway to the goal. Substantial work lies ahead in monitoring and maintaining the system. Here are some reasons why:
- Data drift. The model was trained on a certain distribution of inputs, but this distribution changes over time. For example, a model may have learned to estimate demand for electricity from historical data, but climate change is causing unprecedented changes to weather, so the model’s accuracy degrades.
- Concept drift. The model was trained to learn an x->y mapping, but the statistical relationship between x and y changes, so the same input x now demands a different prediction y. For example, a model that predicts housing prices based on square footage will lose accuracy as inflation causes prices to rise.
- Changing requirements. The model was built to perform a particular task, but the product team decides to modify its capabilities. For instance, a model detects construction workers who wander into a dangerous area without a hard hat for more than 5 seconds. But safety requirements change, and now it must flag hatless workers who enter the area for more than 3 seconds. (This issue sometimes manifests as concept drift, but I put it in a different category because it’s often driven by changes in the product specification rather than changes in the world.)
Detecting concept and data drift is challenging, because AI systems have unclear boundary conditions. For traditional software, boundary conditions — the range of valid inputs — are usually easy to specify. But for AI software trained on a given data distribution, it’s challenging to recognize when the data distribution has changed sufficiently to compromise performance.

This problem is exacerbated when one AI system’s output is used as another AI’s input in what’s known as a data cascade. For example, one system may detect people and a second may determine whether each person detected is wearing a hard hat. If the first system changes — say, you upgrade to a better person detector — the second may experience data drift, causing the whole system to degrade.
Even if we detect these issues, our tools for fixing them are immature. Over the past few decades, software engineers have developed relatively sophisticated tools for versioning, maintaining, and collaborating on code. We have processes and tools that can help you fix a bug in code that a teammate wrote 2 years ago. But AI systems require both code and data. If you need to fix a few training examples that a teammate collected and labeled 2 years ago, will you be able to find the documentation and the exact version of the data? Can you verify that your changes are sound and retrain the model on the revised dataset? Tools for data management, unlike tools for code management, are still nascent.
Beyond data maintenance, we still have traditional software maintenance to deal with. For instance, many teams had to upgrade from TensorFlow 1 to TensorFlow 2.
These problems will recede as data-centric AI tools and methodologies evolve. But for now, being aware of them and planning projects around them can help you build better models and reduce costs.
Keep learning!
Andrew
News

Meet the New Smart-Cities Champ
Chinese researchers for the first time swept a competition to develop AI systems that monitor urban traffic.
What’s new: Chinese universities and companies won first and second place in all five categories of the 2021 AI City Challenge, beating hundreds of competitors from 38 nations. U.S. teams dominated the competition in its first three years, but Chinese contestants started overtaking them last year.
What happened: 305 teams entered at least one of the competition’s five tracks. All teams used the same training and testing data for each track. Here’s a summary of the challenges and winners:
- Counting the number of vehicles turning left, turning right, or going straight through an intersection. Winner: Baidu/Sun Yat-sen University.
- Tracking individual vehicles across multiple cameras. Winner: Alibaba.
- Tracking multiple vehicles across multiple cameras scattered around a city. Winner: Alibaba/University of China Academy of Sciences.
- Detecting car crashes, stalled vehicles, and other traffic anomalies. Winner: Baidu/Shenzhen Institute of Advanced Technology.
- Identifying vehicles using natural-language descriptions (a new challenge for this year’s contest). Winner: Alibaba/University of Technology Sydney/Zhejiang University.
Behind the news: Nvidia, QCraft, and several universities launched the AI City Challenge in 2017 to spur the development of smart city technology.
Why it matters: This competition is the latest example of China’s rising profile in AI. The Chinese government has funded hundreds of Smart City programs. In contrast, U.S. funding for urban AI initiatives has been limited to a few one-off grants or competitions.
We’re thinking: Smart-city technology could make urban living more pleasant and productive, yet it also carries a risk of invasive surveillance. We call on regulators and researchers who work on such projects worldwide to lead a global debate on appropriate standards of privacy and to design their systems that protect privacy from the ground up.

Fake Aim
Gamers looking to cheat in first-person shooters can’t miss with AI-assisted marksmanship.
What’s new: A video-game hack uses computer vision to blast virtual enemies at superhuman speed, Ars Technica reported. A system that implemented the technique was shut down last week.
How it works: Userviz worked with any shooter that runs on PC, PlayStation, or Xbox. It identified and fired on targets in under 10 milliseconds. (Professional gamers have reaction times between 100 and 250 milliseconds.) It worked like this:
- A video capture card streamed the game’s output to another computer that ran a YOLO object detector trained to recognize game avatars. A controller adapter translated YOLO’s output into in-game commands to snap the cursor onto a target and fire.
- The system could identify individual body parts, adjust for recoil, and automatically pull the trigger whenever an enemy entered the player’s crosshairs.
- The system’s vendor deleted access to and support for the system after it heard from Activision, publisher of the popular Call of Duty line of first-person shooters.
Behind the news: Cheat codes that enhance a player’s ability to aim and fire are common but frowned upon. Activision recently banned 60,000 players of Call of Duty: Warzone for using them. Typically, such cheats are add-ons to game software. Tools that use computer vision operate independently of the game and therefore are harder to detect. Userviz was one of several on the market, and some enterprising cheaters have coded their own.
Why it matters: Electronic gaming is a lucrative industry — and so is the market for products that make it easier to win. Unscrupulous players may have taken millions of dollars in competition money.
We’re thinking: Like fighting spam and fraud, thwarting aimbots is a game of cat and mouse. The next generation of such bots may behave more like humans — making an average player appear to be highly skilled — and thus be even harder to detect. Who’s up for a round of rock, paper, scissors?
A MESSAGE FROM DEEPLEARNING.AI

Moving projects from concept to production requires top-of-the-line skills. Learn to deploy data science and machine learning projects and to overcome challenges using Amazon SageMaker in our Practical Data Science Specialization.
Transformers: Smarter Than You Think
The transformer architecture has shown an uncanny ability to model not only language but also images and proteins. New research found that it can apply what it learns from the first domain to the others.
What’s new: Kevin Lu and colleagues at UC Berkeley, Facebook, and Google devised Frozen Pretrained Transformer (FPT). After pretraining a transformer network on language data, they showed that it could perform vision, mathematical, and logical tasks without fine-tuning its core layers.
Key insight: Transformers pick up on patterns in an input sequence, be it words in a novel, pixels in an image, or amino acids in a protein. If different types of data share similar patterns, a transformer trained on one type can operate on another.
How it works: The researchers started with a 36-layer GPT-2 pretrained on WebText (posts on the website Reddit). They froze its self-attention and feed-forward layers and, in separate copies, fine-tuned peripheral layers on each on a wide range of tasks: Bit memory (memorizing strings of bits), Bit XOR (performing logical operations on pairs of strings of bits), ListOps (parsing and performing mathematical operations), MNIST, CIFAR-10 (classification of images), CFAR-10 LRA (classification of flattened, greyscale images), and remote homology detection (predicting what kind of protein structure an amino acid is part of).
- The authors fine-tuned only an input layer, an output layer, layer norm parameters (which fix the mean and variance of a layer’s input), and positional embeddings (vectors that represent where items appear in an input sequence) — less than 0.1 percent of the model’s parameters.
- To evaluate the impact of the language pretraining, the authors also built models whose core layers didn’t benefit from that training. They randomly initialized a GPT-2, froze its self-attention and feed-forward parameters, and then fine-tuned it in the same way as the others.
Results: They compared GPT-2 models trained using their method to GPT-2s that had been fully fine-tuned for the same tasks. Their approach performed nearly as well, sometimes better. For instance, on CIFAR-10, their approach achieved 72.1 percent accuracy versus the fully fine-tuned model’s 70.3 percent. On remote homology detection, their approach achieved 12.7 percent versus 9 percent. Language pre-training contributed to the improvement: For instance, on CIFAR-10, their model achieved 68.2 percent versus the randomized model’s 61.7 percent.
Why it matters: It appears that similar information structures — in the authors’ term, grammars — pervade the world. Applying representations learned in one domain to another domain may conserve training time and lead to better multimodal models.
We’re thinking: It’s surprising that cross-modal pretraining works this well! Are there underlying statistics, common to many types of sequences, that we don’t yet appreciate?
U.S. Lax on Face Recognition
A U.S. government watchdog agency called for stronger face recognition protocols for federal agencies.
What’s new: An audit of federal agencies by the Government Accountability Office (GAO) found that, while many employ face recognition, they may not know where it came from, how it’s being used, or the hazards involved. The auditors recommended that agencies using commercial systems develop protocols for appropriate use.
What they found: Twenty agencies that employ law-enforcement officers reported using face recognition.
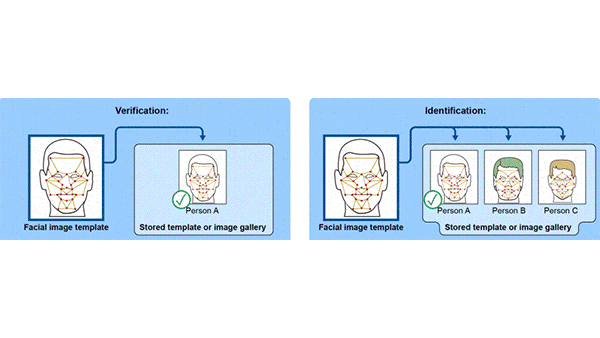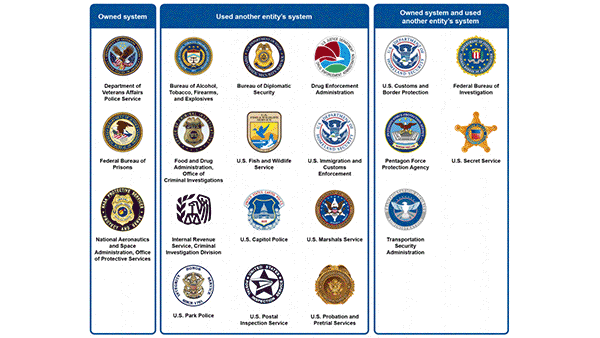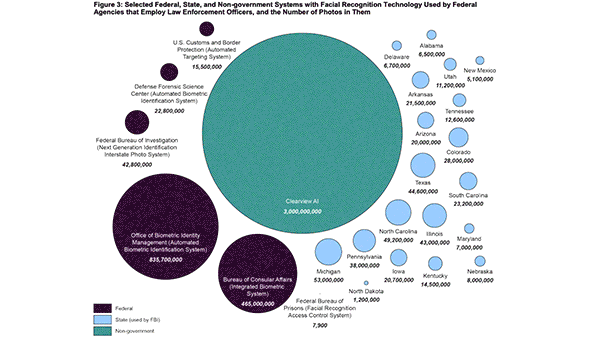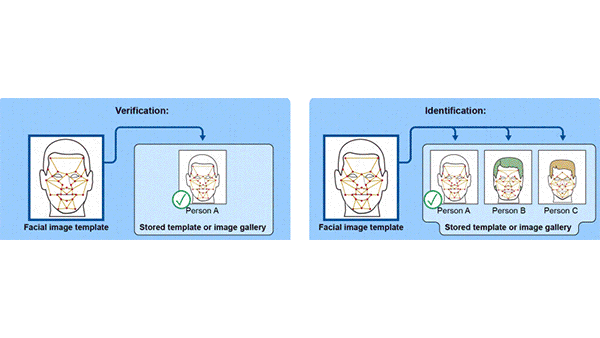
- Of these, 11 used systems developed by private companies including Clearview AI and Vigilant. The others either developed their own or used systems developed by another agency. One of the most popular is the Department of Homeland Security’s Automated Biometric Identification System, which contains data on 835 million individuals.
- Several agencies did not seem to know who built some of the systems they use.
- Six agencies used the technology to investigate people involved in protests against police brutality. Three used it to look into perpetrators of the January 6 attack on the U.S. Capitol.
- Only one agency that reported using a privately developed face recognition system — Immigrations and Customs Enforcement — had implemented oversight protocols such as requiring that employees report each use.
Behind the news: Face recognition is increasingly controversial in the U.S. Lawmakers recently introduced legislation that would freeze government use of the technology. At least 20 U.S. cities and several states have passed laws that restrict the technology.
Why it matters: Face recognition has clear potential to infringe on privacy. Moreover, it has a spotty record of identifying minorities, which has led to false arrests. The finding that many federal agencies are taking a cavalier approach raises troubling questions about privacy and fairness.
We’re thinking: The GAO audit of face recognition systems is a step forward. While regulators, ethicists, technologists, and businesses sort out appropriate standards, a moratorium on law enforcement use of face recognition would be sensible, so we can position the technology for socially beneficial uses while guarding against detrimental ones.