
Dear friends,
In a recent letter, I mentioned some challenges to building AI products. These problems are distinct from the issues that arise in building traditional software. They include unclear technical feasibility and complex product specification. A further challenge is the need for data to start development.
To develop a traditional software product, interviews with potential users might be sufficient to scope out a desirable product, after which you can jump into writing the code. But AI systems require both code and data. If you have an idea for, say, automating the processing of medical records or optimizing logistics networks, you need medical records data or logistics data to train a model. Where can you get it?
I see different answers for consumer-facing and business-facing AI products. For consumer-facing (B2C) products, it is generally easier to ask a small group of alpha testers to try out a product and provide data. This may be sufficient to bootstrap the development process. If the data you need is generic to many users — for example, photos on smartphones — it’s also more likely that a team will be able to find or acquire enough data to get started.

For business-facing (B2B) AI projects, it’s often difficult to get the data necessary to build a prototype because a lot of highly specialized data is locked up within the companies that produce it. I’ve seen a couple of general ways in which AI teams get around this problem.
- Some AI teams start by doing NRE (non-recurring engineering, or consulting) work, in which they build highly customized solutions for a handful of customers. This approach doesn’t scale, but you can use it to obtain enough data to learn the lessons or train the models needed to build a repeatable business. Given their need for data, AI startups seem to take this path more often than traditional software startups.
- Some AI entrepreneurs have worked with multiple companies in a vertical market. For example, someone who has worked for a large public cloud company may have exposure to data from multiple companies in a given industry and witnessed similar issues play out in multiple companies. I’ve also had friends in academia who consulted for multiple companies, which enabled them to recognize patterns and come up with general solutions. Experience like this puts entrepreneurs in a better position to build a nascent product that helps them approach companies that can provide data.
If you lack data to get started on an AI project, these tactics can help you get an initial dataset. Once you’ve built a product, it becomes easier to find customers, get access to even more data, and scale up from there.
Keep learning!
Andrew
News

Listening to the Brain
Neural networks translated a paralyzed man’s brainwaves into conversational phrases.
What’s new: Researchers at UC San Francisco and UC Berkeley trained a system to interpret electrical impulses from the brain of a man who had lost the ability to speak 15 years ago, and displayed them as words on a video screen.
How it works: The researchers implanted an array of 128 electrodes into the region of the brain responsible for movement of the mouth, lips, jaw, tongue, and larynx. They connected the implant to a computer. Then they asked the patient to try to speak 50 common words and 50 common phrases and recorded the resulting brain activity. They trained the system on 22 hours of these signals, team member Sean Metzger at UC San Francisco told The Batch.
- A stack of three LSTMs detected portions of brain activity related to speech.
- An ensemble of 10 convolutional gated recurrent unit models classified speech signals as one of the 50 words.
- An n-gram language model predicted the probability that a given word would come next.
- A custom Viterbi decoder, an algorithm often used in communications that are subject to transmission errors, determined the most likely of the 50 phrases based on the models’ output.
Results: During tests, the system decoded a median of 15.2 words per minute and translated sentences with a median error rate of 25.6 percent.
Behind the news: The system was built on more than a decade of research by lead author and neurosurgeon Edward F. Chang into links between neurological activity and the sounds of spoken language. A similar project called BrainGate translated brain signals associated with the act of handwriting into text.
Why it matters: Accidents, diseases, and other tragedies rob countless people of their ability to communicate. This technology opens a pathway for them to reconnect.
We’re thinking: It’s wonderful to see natural language models restoring the most natural form of language.

When Algorithms Manage Humans
Some delivery drivers fired by Amazon contend that the retailer’s automated management system played an unfair role in terminating their employment.
What’s new: Drivers in Amazon Flex, an Uber-like program that enables independent drivers to earn money delivering the company’s packages, said the program downgraded their performance unjustly and terminated them without warning, Bloomberg reported.
Flex or inflexible? Flex rates drivers automatically on how punctually they pick up and deliver packages and how closely they follow instructions like “place the package on my back porch.”
- Former drivers said the program didn’t account for unavoidable delays caused by obstacles like long lines at Amazon distribution centers, gated apartment complexes, or bad weather. A former Amazon manager told Bloomberg the company was aware that its system had flaws that could lead to bad publicity but decided that higher efficiency was worth that risk.
- Flex drivers have 10 days to appeal termination. However, drivers and anonymous sources told Bloomberg that email responses seemed to be automated and appeals rarely succeed. Drivers who lose an appeal can spend $200 to arbitrate the case.
- A company spokesperson told The Batch that human managers review Flex drivers flagged for poor performance, and that an algorithm does not make the final decision to terminate employment.
Behind the news: The U.S. Federal Trade Commission recently forced Amazon to pay Flex drivers $61.7 million in tips it had withheld. More broadly, Amazon’s penchant for using automated systems to manage personnel has been a steady source of controversy.
- In 2019, documents obtained by The Verge showed that the company used algorithms to track productivity in its warehouses and fired workers who did not meet performance benchmarks.
- In 2018, the company abandoned a hiring algorithm after an internal audit found that it was biased against women.
- The company requires its fleet drivers to consent to being monitored by AI-powered cameras that watch for signs of drowsiness or distraction. Some drivers have declined to work with the cameras, calling them an invasion of privacy.
Why it matters: Organizations increasingly rely on algorithms to help make decisions that impact peoples’ lives, including who gets a bank loan, a job, or jail time. Public backlash has led to proposals like the Algorithmic Accountability Act, which would require the U.S. government to develop rules that mitigate algorithmic bias and provide ways for citizens to appeal automated decisions.
We’re thinking: All algorithms are prone to some degree of error. At a company the size of Amazon, even a tiny error can have a large impact. Every effort should be made to audit such systems for fairness, make sure the tradeoffs between flexibility and efficiency are transparent, and treat individuals with compassion and respect.
A MESSAGE FROM DEEPLEARNING.AI

We’re proud to offer “Optimize ML Models and Deploy Human-in-the-Loop Pipelines,” Course 3 in our Practical Data Science Specialization. Harness human intelligence to tune accuracy, compare performance, and generate new training data. Enroll now
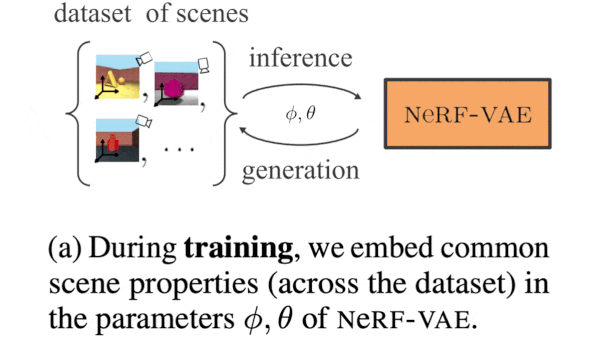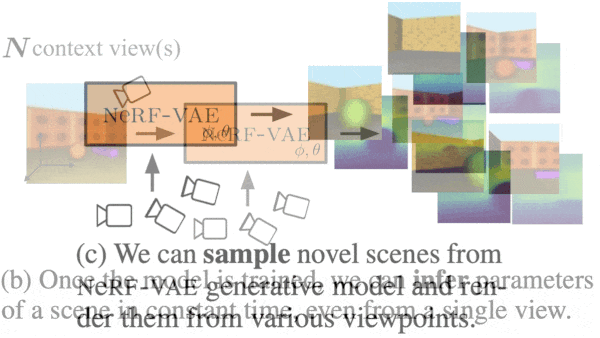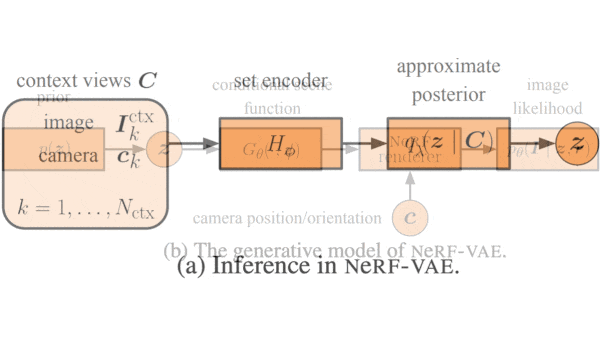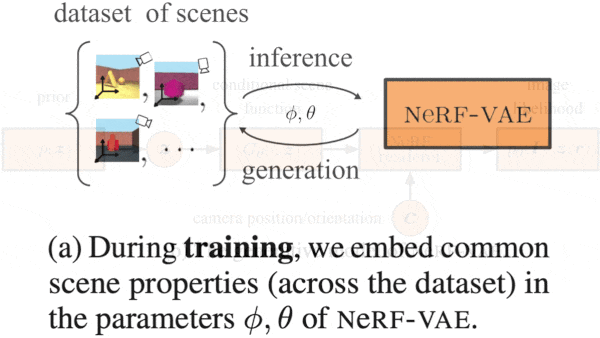
One Network, Many Scenes
To reconstruct the 3D world behind a set of 2D images, machine learning systems usually require a dedicated neural network for each scene. New research enables a single trained network to generate 3D reconstructions of multiple scenes.
What’s new: Adam Kosiorek and Heiko Strathmann led a team at DeepMind in developing NeRF-VAE. Given several 2D views of a 3D scene pictured in its training data, NeRF-VAE produces new views of the scene.
Key insight: The method known as Neural Radiance Fields (NeRF) produces new views of a scene based on existing views and the positions and orientations of the camera that produced them. NeRF-VAE takes the same input but adds representations of those views. This enables it to learn patterns within a scene. Those patterns help the network produce new views by enabling it to, say, infer the characteristics of common elements that were partly blocked from view in the training images.
How it works: NeRF-VAE is a modified variational autoencoder (VAE), where the encoder is a Nouveau ResNet and the decoder is basically NeRF with an additional input for a representation of the scene. The training set comprised four randomly generated views per scene of 200,000 synthetic 3D scenes composed of geometric shapes against plain backgrounds, as well as the associated camera positions and orientations. The authors trained the network to match predicted pixels with the pixels in the images.
- For each of the four views of a scene, the encoder predicts parameter values that correspond to the image’s data distribution. The system averages the parameters and uses the average distribution to generate a representation of the scene.
- The decoder samples points along rays that extends from the camera through each pixel in the views. It uses a vanilla neural network to compute the color and transparency of each point based on the point’s position and the ray’s direction as well as the scene representation.
- To determine the color of a given pixel, it combines the color and transparency of all sampled points along the associated ray. To generate a new view, it repeats this process for every pixel.
Results: The authors trained one NeRF-VAE on all scenes and a separate NeRF for each scene. Trained on four images per scene, NeRF-VAE achieved roughly 0.2 mean squared error, while NeRF achieved roughly 0.8 mean squared error. NeRF required training on 100 images of a scene to achieve a competitive degree of error.
Why it matters: NeRF falters when it attempts to visualize hidden regions in a scene. That’s partly because a NeRF model encodes information about only a single 3D structure. NeRF-VAE overcomes this weakness by learning about features that are common to a variety of 3D structures.
We’re thinking: By feeding a random vector directly to the decoder, the authors produced views of novel, generated scenes made up of elements in the training images. Could this approach extend deepfakery into the third dimension?

Bye Bye Bots
The independent research lab OpenAI wowed technology watchers in 2019 with a robotic hand that solved Rubik’s Cube. Now it has disbanded the team that built it.
What’s new: OpenAI cofounder Wojciech Zaremba revealed that OpenAI shuttered its robotics program last October.
Robo retrenchment: In a podcast produced by Weights & Biases, a maker of AI development tools, Zaremba said a lack of data was holding back OpenAI’s progress in robotics. The company’s broad goal is to develop artificial general intelligence, and it believes it can make more progress by focusing on approaches such as reinforcement learning with human feedback, a representative told VentureBeat.
Behind the news: OpenAI previously developed a robotics simulation environment, a reinforcement learning toolkit, and techniques for training robots.
Why it matters: The robotics industry has seen several high-profile players struggle with the high cost of research and development. In recent years, Honda shuttered its Asimo subsidiary, Rethink Robotics closed up shop, and Boston Robotics, famous for its acrobatic bipeds and resilient quadrupeds, repeatedly changed hands.
We’re thinking: When even a fleet of robots isn’t able to generate enough data, that’s a sign of how data-hungry our algorithms are. It’s also a reminder of how far the current state of the art is from human-level AI. After all, infants have only one body’s worth of data to learn from.