
Dear friends,
A few weeks ago, I wrote about my team at Landing AI’s work on visual prompting. With the speed of building machine learning applications through text prompting and visual prompting, I’m seeing a trend toward building and deploying models without using a test set. This is part of an important trend of speeding up getting models into production.
The test set has always been a sacred aspect of machine learning development. In academic machine learning work, test sets are the cornerstone of algorithm benchmarking and publishing scientific conclusions. Test sets are also used in commercial machine learning applications to measure and improve performance and to ensure accuracy before and after deployment.
But thanks to prompt-based development, in which you can build a model simply by providing a text prompt (such as “classify the following text as having either a positive or negative sentiment”) or a visual prompt (by labeling a handful of pixels to show the model what object you want to classify), it is possible to build a decent machine learning model with very few examples (few-shot learning) or no examples at all (zero-shot learning).
Previously, if we needed 10,000 labeled training examples, then the additional cost of collecting 1,000 test examples didn’t seem onerous. But the rise of zero-shot and few-shot learning — driven by prompt-based development — is making test set collection a bottleneck.
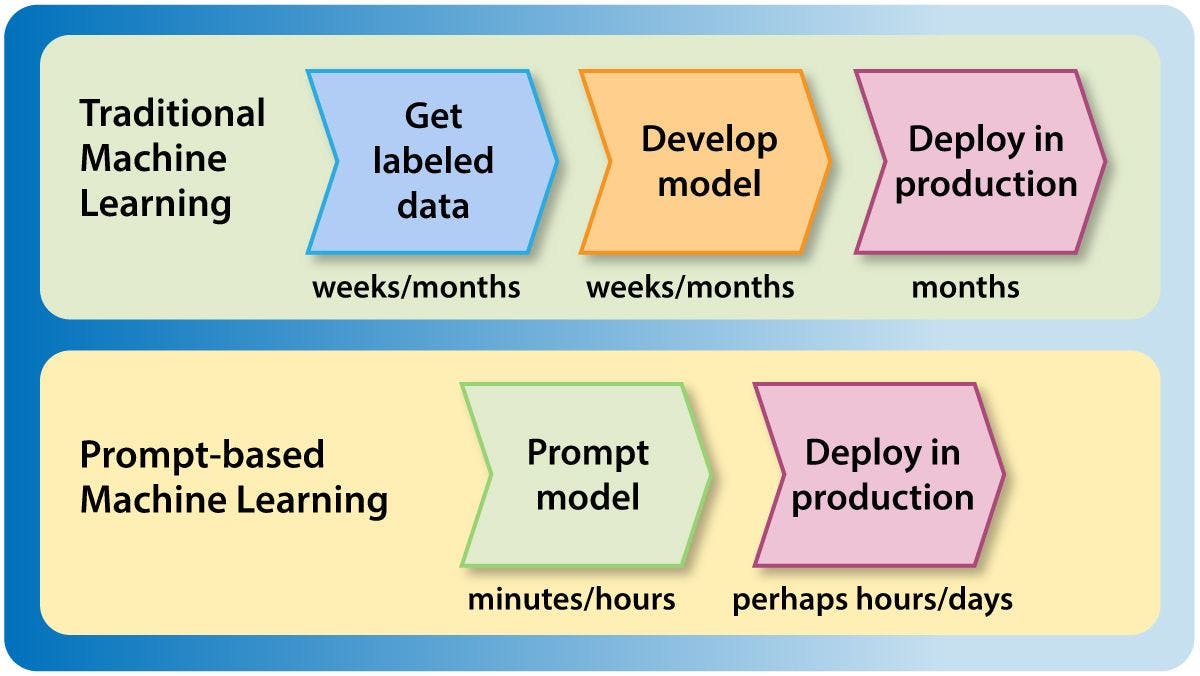
Thus I'm seeing more and more teams use a process for development and deployment that looks like this:
- Use prompting to develop a model. This can take minutes to hours.
- Deploy the model to production and run it on live data quickly but safely, perhaps by running in “shadow mode,” where the model’s inferences are stored and monitored but not yet used. (More on this below.)
- If the model’s performance is acceptable, let it start making real decisions.
- Only after the model is in production, and only if we need to benchmark more carefully (say, to eke out a few percentage points of performance improvement), collect test data to create a more careful benchmark for further experimentation and development. But if the system is doing well enough, don’t bother with this.
I’m excited by this process, which significantly shortens the time it takes to build and deploy machine learning models. However, there is one important caveat: In certain applications, a test set is important for managing risk of harm. Many deployments don’t pose a significant risk of harm; for example, a visual inspection system in a smartphone factory that initially shadows a human inspector and whose outputs aren’t used directly yet. But if we're developing a system that will be involved in decisions about healthcare, criminal justice, finance, insurance, and so on, where inaccurate outputs or bias could cause significant harm, then it remains important to collect a rigorous test set and deeply validate the model’s performance before allowing it to make consequential decisions.
The occurrence of concept drift and data drift can make the very notion of a “test set” problematic in practical applications, because the data saved for testing no longer matches the real distribution of input data. For this reason, the best test data is production data. For applications where it’s safe and reasonable to deploy without using a test set, I’m excited about how this can speed up development and deployment of machine learning applications.
Keep learning!
Andrew