

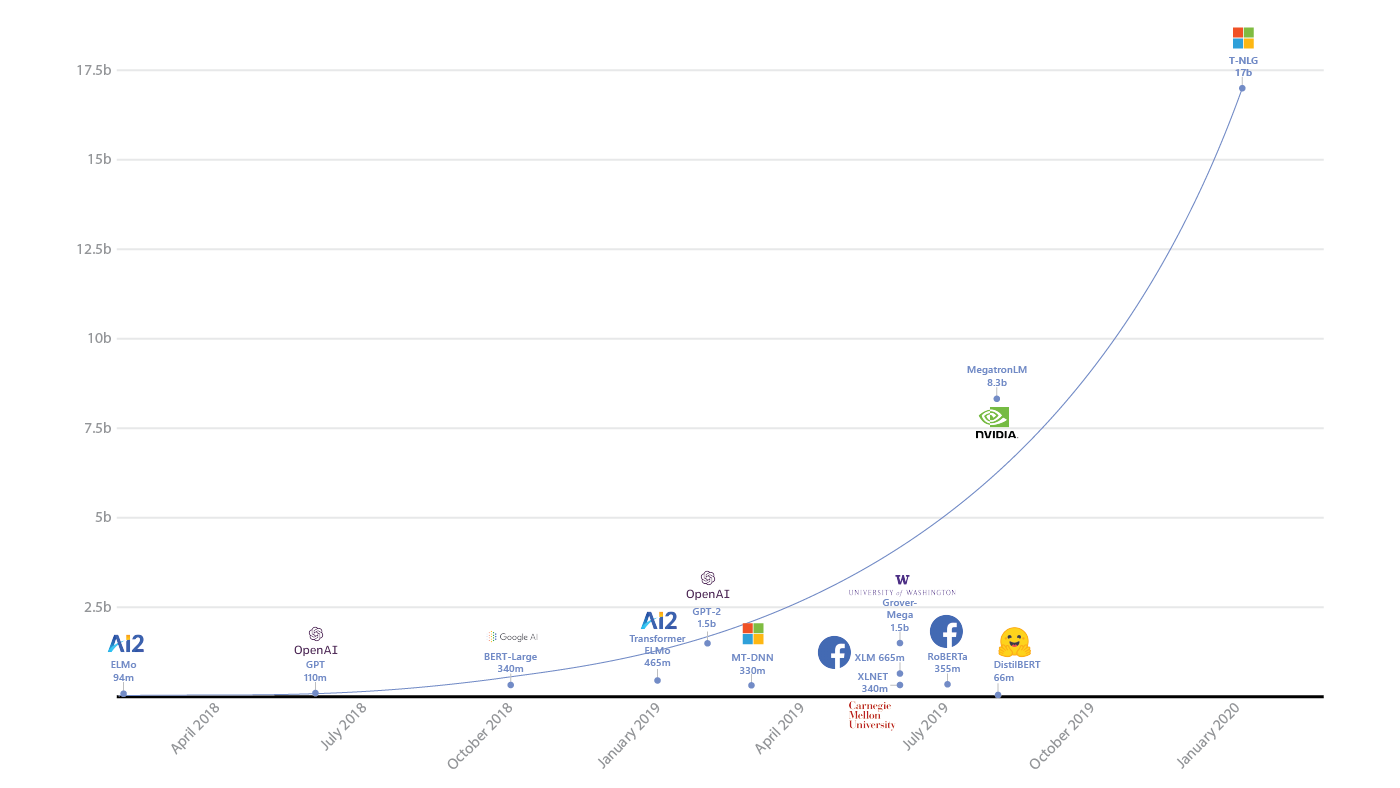
Natural language processing lately has come to resemble an arms race, as the big AI companies build models that encompass ever larger numbers of parameters. Microsoft recently held the record — but not for long.
What’s new: In February, Microsoft introduced Turing Natural Language Generation (Turing-NLG), a language model that comprises 17 billion parameters.
Key insight: More parameters is better. More training data is better. And more compute is better. For the time being, these factors determine the state of the art in language processing.
How it works: Like other recent large language models, Turing-NLG is based on the transformer architecture, which extracts features across long sequences of data without having to examine every element in between. Also like its immediate predecessors, it’s trained on unlabeled data via an unsupervised method, which enables it to absorb information from far more text than supervised models have available.
{kind=link}
- Turing-NLG draws on knowledge stored in its parameter values to answer questions such as: “How many people live in the U.S.?”. It generates responses one word at a time depending on context provided by the preceding words. For example, it would have to generate “There are 328.2 million” before deciding to generate “people.”
- The researchers fine-tuned the model on multiple text summarization datasets to generate abstractive summaries, or summaries that use novel words rather than phrases drawn from source texts. This enables it to answer questions by summarizing relevant portions of reference data.
- Like many deep learning models, Turing-NLG is far too big to train on a single GPU. Instead, such models are divided into pieces and distributed to many processors that run in parallel. That approach incurs a cost in processing efficiency, as each chip must move redundant data to and from memory, and for an architecture as big as Turing-NLG, that inefficiency can be crippling. To train their gargantuan model, the researchers used techniques developed by Nvidia for Megatron to distribute the model efficiently, and Microsoft’s own ZeRO to schedule memory resources dynamically.
Results: The researchers pitted Turing-NLG against Megatron. Turing-NLG improved state-of-the-art accuracy on the Lambada language understanding benchmark from 66.51 percent to 67.98 percent. It also improved perplexity (lower is better) on the WikiText of verified Wikipedia articles from 10.81 to 10.21.
Yes, but: The race to build bigger and better language models doesn’t leave any breathing room even for engineers at the biggest tech powerhouses. Less than four months after Microsoft announced Turing-NLG, OpenAI detailed GPT-3. At 175 billion parameters, it’s roughly 10 times bigger and achieved 76.2 percent accuracy on Lambada.
Why it matters: As language models balloon, so do scores on NLP benchmarks. Keep your seatbelts on: Microsoft says its approach to allocating hardware resources can scale past 1 trillion parameters.
We’re thinking: The recipe of adding parameters, data, and compute for better performance has a long history. That today’s language models ingest far more text than a human could read in a lifetime reveals both the power of brute-force training and the algorithms’ inefficiency at learning.