
Dear friends,
Voice-based AI that you can talk to is improving rapidly, yet most people still don’t appreciate how pervasive voice UIs (user interfaces) will become. Today, we use a keyboard and mouse to control most desktop and web applications. In the future, I hope we will be able additionally to talk to many of these applications to steer them. I’m particularly excited about the work of Vocal Bridge (an AI Fund portfolio company), where CEO Ashwyn Sharma is leading the way to provide developer tools that enable this.
Every significant UI change has spawned many new applications as well as allowed us to upgrade existing ones. The mouse made point-and-click possible. Touch and swipe gestures enabled new classes of mobile apps. Until recently, voice UIs suffered from high error rates and/or latency, but as they become more reliable, they will open up many new applications.
For instance, I had built a simple math-quiz application for my daughter. She has enjoyed using the keyboard to play this game (which shows a cute cat graphic on right answers because she loves cats! 🐱). Adding a voice UI, so it quizzes her verbally in a friendly way and she can respond verbally, removes friction and changes how the experience feels.
The vast majority of people find speaking and listening much easier than writing and reading. Because most developers are highly literate (and so are readers of The Batch), it’s easy to forget how hard many people find writing. Indeed, children who spend time with adults will automatically learn to speak and listen, but unless they are taught explicitly, they will not learn to read or write. Sci-fi movies from the past few decades, like Star Trek, frequently imagine people speaking with computers rather than typing at them. This is a vision of the future worth building toward!
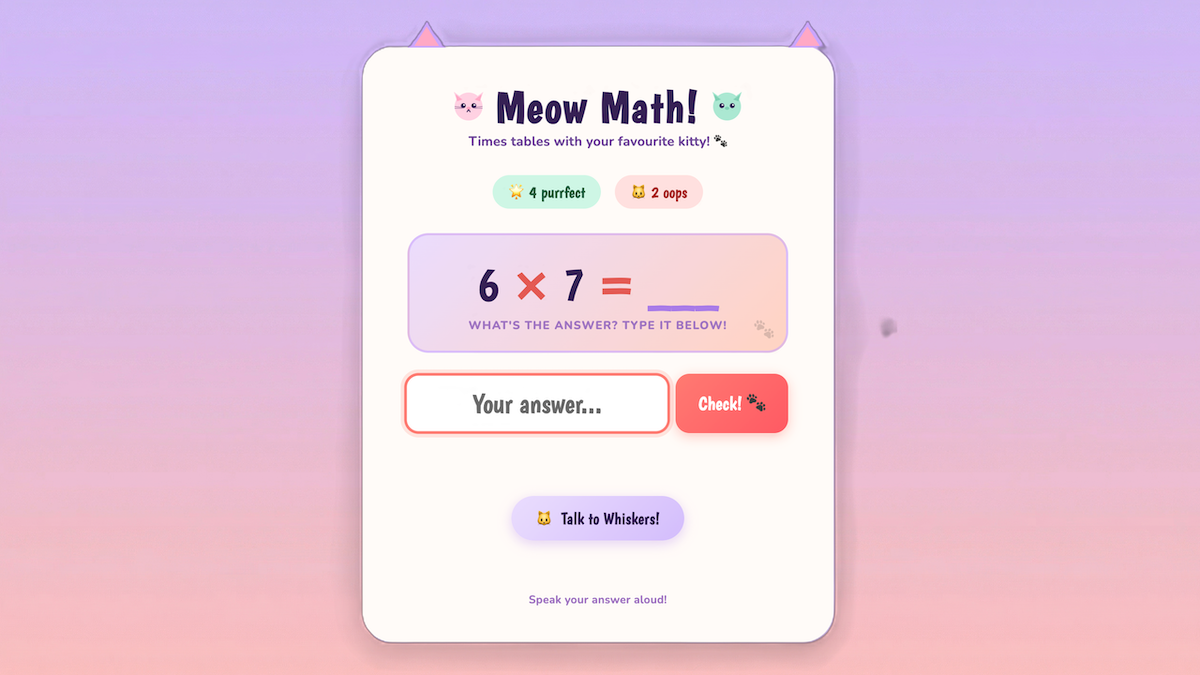
I’ve written about the tradeoff between latency and intelligence. The core problem is that while voice-in-voice-out models have low latency (which is important for verbal communications), they are hard to control and suffer from low reliability/intelligence. In comparison, a pipeline for Speech-to-text → LLM/Agentic AI → Text-to-speech gives high reliability but introduces excessive latency. Vocal Bridge implemented a custom architecture that uses a foreground agent to converse with the user in real time — thus ensuring low latency — and a background agent to manage a complex agentic workflow, reason, apply guardrails, call tools, and whatever else is needed to produce high-quality answers and actions — thus ensuring high intelligence.
I don't expect voice UIs to completely replace older interfaces. Instead, they will complement them, just as the mouse complements the keyboard. In some contexts, such as when working in close proximity to others, users will prefer to type rather than speak. But the potential for voice UIs goes well beyond the currently dominant use cases of automating call centers and providing an alternative to typing. In my math-quiz app, the application can speak and also update the questions and animations shown on the screen in response to spoken (or typed) inputs. This multimodal visual+voice interaction creates a much richer user experience than the voice-only interactions that many voice AI companies have focused on. One key to making it work is a background-agent loop that can bidirectionally receive input from the UI as well as call tools to update the UI.
Building voice UIs is probably easier than you think. Starting from an earlier, non-voice version of my math-quiz app, using Claude Code, it took me less than an hour to add voice capabilities. At a recent hackathon hosted by DeepLearning.AI and AI Fund, developers built voice-powered apps with Vocal Bridge including a clinical trial matcher for cancer patients, a conversational portfolio advisor, and interactive voice layers for existing text-based agents. I was delighted at the creativity that this new UI enables.
Voice UIs will be an important building block for AI applications. Only a minuscule fraction of the world's developers have ever created a voice app, so this is fertile ground for building. If you’d like to try adding voice to an application, try out Vocal Bridge for free here.
Keep building!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

We just released the AI Dev 26 agenda! Hear from teams at Google DeepMind, Oracle, AMD, and more across two days of talks, workshops, and demos—hosted by Andrew Ng. See what’s planned and start mapping your schedule
News

Inside Claude Code
The inner workings of the popular coding agent Claude Code are available for all to see.
What’s new: A recent version of Claude Code’s Node.js package accidentally included a key that revealed the code behind its command-line interface. Chaofan Shou, an intern at the blockchain startup Solayer Labs, unlocked the code and published it. Engineers rapidly deciphered its secrets.
What happened: Typically, when a software company publishes closed-source code, a bundler tool scrambles the source files. But when Anthropic published version 2.1.88 to Claude Code’s npm registry on March 30, it included a source map file that serves as a translation key to decode the files.
- Shou discovered the source map, decoded the files, and published them on the X social media network, exposing over 512,000 lines of code across 1,900 files.
- Anthropic promptly removed the package from the npm registry and GitHub. However, it had already been forked more than 40,000 times.
- An Anthropic spokesperson confirmed the leak, calling it “a release packaging issue caused by human error, not a security breach,” and stated that no user or customer data was exposed.
How Claude Code works: Engineers who studied the source code say Claude Code is built less like a chatbot wrapper and more like a small, dedicated operating system.
- Each of more than 40 different tools (that read files, execute bash commands, fetch information from the web, and the like) have their own modules and permission gates, separating them from both the language model and the user’s computer. Background processes manage memory, and the permission gates prevent the agent from running arbitrary code beyond defined resources.
- Claude Code spawns swarms of subagents that act as support agents with their own tool sets and resources. A controller agent delegates their permissions and subtasks. Each swarm team has a common memory to help coordinate its actions.
- Claude Code’s memory has three tiers. (i) A memory index called MEMORY.MD is always loaded but contains only pointers to (ii) Markdown memory files, which are called only when needed. In addition, (iii) JSON transcript files log file changes. These are not loaded into active context, but they can be searched for relevant lines of text. This three-tiered structure prevents memory bloat, keeps irrelevant or incomplete information out of the context window, and resolves all conflicts between the agent’s memory and the actual state of a file.
- Claude Code uses a three-stage strategy to compress memories and keep conversations within the context limit. (i) The first truncates cached tool outputs locally. (ii) The second generates a structured, 20,000-token summary of the most recent session when a conversation approaches the context limit. (iii) The third compresses the entire conversation, then adds recently accessed files (up to 5,000 tokens per file), active plans, and relevant skills.
Future capabilities?: The source map also reveals some of Anthropic’s possible plans for Claude. For instance, several undisclosed features sit behind flags that compile to “false” in the published build, a sign that they are currently in-progress and may be included in a future release.
- A subsystem called Kairos (Greek for timely) would run as an always-on background agent. Its logic system, called autoDream, merges duplicate memories, eliminates contradictions, resolves speculations, and otherwise prunes memory to make stored data more suitable for action.
- Other hidden features include a voice interface, a subagent called Ultraplan that sends resource-intensive tasks to the cloud, and a persona called Buddy comments on your work, presumably to boost engagement.
- Claude Code has a previously undisclosed “undercover mode” that allows the agent to commit files to public git repositories without leaving a signature or other sign that it has been active in a repository. This feature may enable Anthropic to test advanced models and work with partners that have not been announced publicly without inadvertently disclosing such activities.
- The files include references to a Claude 4.6 variant code named Capybara and an unreleased model called Numbat. Capybara version 8 makes false or exaggerated claims around 30 percent of the time, well above an earlier version’s 16.7 percent, suggesting the latest version of the model is tuned to jump to conclusions rather than show restraint.
Why it matters: The leak offers a peek under the hood of one of the most advanced and popular agentic systems available. We can see how Claude Code works and how it may work in the near future, revise our own systems to match, or differentiate our products by making different choices.
We’re thinking: The AI community is rightly concerned that software agents can inadvertently delete codebases or publish private files. Humans can, too!

OpenAI Exits Video Generation
OpenAI plans to shut down its video generator Sora in a sudden retreat from the video market.
What’s new: OpenAI will discontinue Sora, a high-profile follow-up to ChatGPT that the company had hoped would become another mass-market sensation, to reallocate resources to more profitable investments, The Wall Street Journal reported. Access to the model via web and app will end on April 26, and the API will close on September 24. The Sora team will be redirected to longer-term projects such as world models and robotics. In addition, OpenAI will consolidate its browser, the coding tool Codex, and the ChatGPT app into a single desktop application, The Wall Street Journal wrote in a separate report.
How it works: Sora produces high-definition videos of up to 25 seconds long that earned acclaim for their realism and visual quality. However, generating each clip takes minutes and requires a much larger amount of processing power than producing text or images. OpenAI previewed the model in February 2024. It updated the model and made it available via an iOS app in September 2025.
- The bulk of Sora’s revenue comes from subscribers to OpenAI’s paid plans. Sora is available in three tiers: Users of the app could generate about five free 10-second videos a day (by invitation only). ChatGPT Plus subscribers ($20 monthly) can use Sora 2 to generate a limited number of 15-second clips in 1280x720-pixel resolution. ChatGPT Pro subscribers ($200 monthly) can use the more-advanced Sora 2 Pro model to generate videos up to 25 seconds long in 1920x1080-pixel resolution.
- Sora has been losing roughly $1 million a day. Its number of daily active users peaked at around 1,000,000 shortly after the mobile app’s launch but soon fell to less than half that amount.
- Before announcing the shutdown on the X social network, OpenAI reportedly diverted Sora’s processing resources to running a new AI model, code named Spud, that powers various coding and enterprise products.
- The Sora team had proposed training a new model that would generate videos within ChatGPT, possibly as an alternative to the Sora app. Faced with the high cost of training another video model, the company chose to cancel video generation altogether.
- As of this writing, Sora 2 Pro places 19th on Artificial Analysis’ text-to-video leaderboard, well behind competing models by ByteDance, Kling, xAI, and Google.
Behind the news: In late 2025, OpenAI took advantage of Sora to form a high-profile partnership with Disney. OpenAI would license Disney characters and train its models on Disney footage, and Disney would invest up to $1 billion in OpenAI. Disney planned to show Sora videos on its streaming service Disney+ and use Sora to help create pre-production visualizations, marketing campaigns, and special effects. With Sora’s impending demise, the partnership is effectively over.
Why it matters: OpenAI has surrendered leadership in video generation, clearing the way for other companies — among several strong contenders — to vie for dominance. When it launched Sora two years ago, OpenAI envisioned another ChatGPT moment. It wanted its generated videos to thrill the mass market and achieve maximum cultural impact. But the arithmetic didn’t make sense. Video generation didn’t attract as many paid subscribers as applications for business and coding, and the costs of training and running video models proved too great to bear.
We’re thinking: The era in which an AI demo — however impressive — is sufficient to establish leadership may be drawing to a close. The field is maturing rapidly, and creating sustainable value is becoming a top priority.

Gemini’s Music Generator
Google added a music generator to Gemini and YouTube, putting a model that produces synthetic songs in front of hundreds of millions of users.
What’s new: Lyria 3 takes text descriptions or images and generates 30-second audio clips that can include instruments, singing voices, and song lyrics in several languages. Google took measures to ensure that the model’s output doesn’t violate copyrights: licensing its training data, filtering outputs for similarity to copyrighted works, and avoiding reproduction of an artist’s sonic likeness.
- Input/output: Text in, audio (30 seconds) and text (lyrics) out; the Gemini app accepts images and videos as input, converts them to text, and passes to Lyria 3
- Architecture: Latent diffusion model
- Features: Users can specify instrumentation, style, era, vocal style, tempo, and dynamics; song lyrics in eight languages (English, German, Spanish, French, Hindi, Japanese, Korean, and Portuguese); cover art produced by Nano Banana, Google's image generator; MP3 (audio) and MP4 (video with cover art) format; watermarked output
- Performance: In human and automated evaluations conducted by Google, Lyria 3 outperformed its predecessor, Lyria 2, with respect to audio quality and prompt adherence
- Availability: Free to users of Gemini app 18 years and older with higher usage limits for subscribers to Google AI Plus, Pro, and Ultra; free to users of YouTube Shorts via the video soundtrack generation tool Dream Track
- Undisclosed: Architecture, parameter count, training data and methods
How it works: Google disclosed only a high-level overview of Lyria 3’s architecture and training. Like latent diffusion image generators, which produce images by removing noise from embeddings of pure noise, Lyria 3 removes noise from representations of audio during a given slice of time. The Batch previously described an audio diffusion process developed by Stability.AI as well as Google’s earlier MusicLM music generation method.
- Lyria 3 was trained on audio annotated with text captions at varying levels of detail and filtered for quality, duplicates, and safety. Google licensed Lyria 3’s training data, a significant change after Lyria 2, which reportedly was trained on recordings under copyright without authorization.
- The model underwent three phases of training: pretraining, supervised fine-tuning, and reinforcement learning from human feedback.
- Lyria 3 marks its output with SynthID, a hidden watermark that identifies synthetic media. Users can upload audio files to the Gemini app to check whether they were generated by a Google model.
- If a prompt mentions a specific musician, the model will generate music in a similar style without replicating the artist’s voice or sound. Google said it compares outputs with existing music to avoid copyright violations, but acknowledged the approach is fallible and invites users to report outputs that may violate intellectual-property rights.
Behind the news: Lyria 3 arrives as the music industry is aggressively prosecuting developers of AI music generators for alleged copyright violations. The leading music generators, Suno and Udio, no longer generating music from scratch, leaving Google among a dwindling number of developers that do.
- In June 2024, Sony Music, Universal Music Group (UMG), and Warner Music, the world’s three largest music companies, sued Suno and Udio, which offer web-based music generators, for alleged copyright violations. In late 2025, the defendants settled with Universal Music Group and changed their services to emphasize altering existing, licensed recordings rather than generating new music. Sony’s lawsuit remains in progress.
- Google responded to music-industry pressure partly by exploring models geared for professional music production. In spring 2025, it introduced Music AI Sandbox, MusicFX DJ, and Lyria RealTime, which enable more fine-grained control over generated music. Days after launching Lyria 3, Google acquired another professional production tool, ProducerAI, formerly known as Riffusion.
Why it matters: Music generation is finding its place in an entertainment industry dominated by large, powerful incumbents. Lyria 3 puts it in front of more than 750 million Gemini users, dwarfing the current user bases of Suno (around two million paid subscribers) and Udio (around 3.3 million monthly users). It continues to produce original music — the direction that put Suno and Udio in the crosshairs of the world’s biggest recording companies — but adds safeguards, such as training on licensed music, to avoid aggravating copyright holders.
We’re thinking: Music generators produce impressive, versatile, surprisingly human-like output, yet we’re still waiting for generated music to have its ChatGPT moment. It may happen quietly as, say, producers of YouTube clips increasingly use Lyria 3 rather than pre-recorded sources.

Learning Long Context at Inference
Large language models typically become less accurate and slower when they process longer contexts, but researchers enabled an LLM to keep accuracy stable and inference time constant as its context grew.
What’s new: Arnuv Tandon, Karan Dalal, and colleagues at the nonprofit Astera Institute, Nvidia, Stanford, UC Berkeley, and UC San Diego introduced Test-Time Training, End-to-End (TTT-E2E), a method that compresses context into a transformer’s weights by training it during inference.
Key insight: LLMs built on the transformer architecture attend to the entire context (all tokens input and output so far) to generate the next output token. Thus, generating each new output token takes more processing than the last, potentially making inference expensive and slow. Instead of attending to the entire context, a transformer can restrict attention to a smaller window of fixed size — which keeps the time required to generate each output token constant — and learn from the context by updating its weights.
How it works: The authors built a 3 billion-parameter transformer that implemented sliding-window attention, which restricted attention to a fixed window of 8,000 tokens. They pretrained the model on sequences of 8,000 tokens — 164 billion tokens total — drawn from a filtered dataset of text scraped from the web. To enable it to track longer contexts, they fine-tuned it on sequences of up to 128,000 tokens drawn from the Books subset of The Pile. The authors used a form of meta-learning, or learning how to learn; in this case, the model learns how to learn from input provided at inference time.
- Training and fine-tuning took place in two loops, one (which we’ll call the inner loop) encompassed by the other (the outer loop). The inner loop simulated learning a chunk of context at inference, and the outer cycle evaluated how well the model would perform after that learning and adjusted the weights accordingly.
- The inner loop took a training sequence and split it into consecutive chunks of 1,000 tokens. For each chunk, the model used sliding-window attention to (i) predict each token in turn, (ii) compute a typical next-token prediction loss, and (iii) use the loss to compute how the weights should change in the fully connected layers of the last quarter of the network. The result was a sequence of weight updates, one for every 1,000 tokens.
- The outer loop used these weight updates to compute the average next-token prediction loss after the simulated weight updates. It backpropagated through the sequence of simulated weight updates and updated the entire model’s weights. (This process increased training time, because it required computing gradients of gradients.)
- During inference, the model followed the inner loop. It split the input context into chunks, calculated the next-token prediction loss on the chunks, and updated only the fully connected layers in the last quarter of the network. Then it generated new tokens. (Since inference used only the inner loop, it didn’t need the increased time required in the outer-loop training process, so processing time was constant regardless of the context length.)
Results: The authors compared TTT-E2E to a transformer with conventional attention as well as highly efficient architectures such as Mamba 2 (a recurrent neural network-style model) and Gated DeltaNet (which uses a custom form of linear attention). Its accuracy slightly exceeded that of the transformer over long contexts — except on Needle-in-a-Haystack, which involves recovering a short target string from a long context — and it generated output tokens as rapidly as the more-efficient architectures as context grew. Its exceptional inference speed came at the cost of slower and more complex training.
- TTT-E2E demonstrated very slightly higher performance than a vanilla transformer from short to long contexts, judging by next-token prediction loss. The vanilla transformer had an average loss of 0.015 higher across context lengths from 8,000 to 128,000 tokens. Mamba 2’s and Gated DeltaNet’s losses were still 0.03 higher. TTT-E2E matched those models on Needle-in-a-Haystack (NIAH) when processing shorter contexts, but its performance dropped dramatically after 8,000 tokens. For example, at 128,000 tokens, TTT-E2E (6 percent) fell below Mamba 2 (7 percent) and Gated DeltaNet (7 percent), and far below the vanilla transformer (99 percent).
- TTT-E2E processed long contexts faster than the vanilla transformer, roughly on par with Mamba 2 and Gated DeltaNet. Running on an H100 GPU, TTT-E2E’s time to generate its first token increased linearly by 25 milliseconds per 1,000 tokens as the context increased from 8,000 to 128,000 tokens. The vanilla transformer’s time to first token increased from 12 to 70 milliseconds per 1,000 tokens from 8,000 to 128,000 tokens.
- TTT-E2E’s training latency, or the time it took to process and execute model updates per 1,000 training tokens, exceeded that of Mamba 2 and Gated DeltaNet. TTT-E2E’s training latency rose from about 0.25 seconds given 8,000 training tokens to around 0.33 seconds given 128,000 training tokens. In contrast, Mamba 2 and Gated DeltaNet remained roughly constant at about 0.06 seconds. Given 8,000 training tokens, the vanilla transformer (0.08 seconds) trained four times faster. At 128,000 tokens that relationship flipped: vanilla transformer (0.39 seconds) trained about 1.2 times slower.
Why it matters: Learning at inference offers an approach to processing long contexts that’s simpler than designing custom attention mechanisms or recurrent architectures. This work reframes the problem as a trade-off between training and inference: Processing at inference is less expensive and more consistent per token, but training is slower.
We’re thinking: This model took it to heart when we said: Keep learning!