
Dear friends,
I recently spoke at the Sundance Film Festival on a panel about AI. Sundance is an annual gathering of filmmakers and movie buffs that serves as the premier showcase for independent films in the United States. Knowing that many people in Hollywood are extremely uncomfortable about AI, I decided to immerse myself for a day in this community to learn about their anxieties and build bridges.
I’m grateful to Daniel Dae Kim, an actor/producer/director I’ve come to respect deeply for his artistic and social work, for organizing the panel, which also included Daniel, Dan Kwan, Jonathan Wang, and Janet Yang. I found myself surrounded by award-winning filmmakers and definitely felt like the odd person out!
First, Hollywood has many reasons to be uncomfortable with AI. People from the entertainment industry come from a very different culture than many who work in tech, and this drives deep differences in what we focus on and what we value. A significant subset of Hollywood is concerned that:
- AI companies are taking their work to learn from it without consent and compensation. Whereas the software industry is used to open source and the open internet, Hollywood focuses much more on intellectual property, which underlies the core economic engines of the entertainment industry.
- Powerful unions like SAG-AFTRA (Screen Actors Guild-American Federation of Television and Radio Artists) are deeply concerned about protecting the jobs of their members. When AI technology (or any other force) threatens the livelihoods of their members — like voice actors — they will fight mightily against potential job losses.
- This wave of technological change feels forced on them more than previous waves, where they felt more free to adopt or reject the technology. For example, celebrities felt like it was up to them whether to use social media. In contrast, negative messaging from some AI leaders who present the technology as unstoppable, perhaps even a dangerous force that will wipe out many jobs, has not encouraged enthusiastic adoption.

Having said that, Hollywood is under no illusions that AI will change entertainment, and that if Hollywood does not adapt, perhaps some other place will become the new center for entertainment. The entertainment industry is no stranger to technology change. Radio, TV, computer graphics special effects, video streaming, and social media transformed the industry. But the path to navigating AI’s transformation is still unclear, and organizations like the new Creators Coalition on AI are trying to stake out positions. Unfortunately, Hollywood’s negative sentiment toward AI also means it will produce a lot more Terminator-like movies that portray AI as more dangerous than helpful, and this hurts beneficial AI adoption as well.
The interests of AI and Hollywood are not always aligned. (Every time I speak in a group like this as the “AI representative,” I can count on being asked very hard questions.) Most of us in tech would prefer a more open internet and more permissive use of creative works. But there is also much common ground, for example in wanting guardrails against deepfakes and a smooth transition for those whose jobs are displaced, perhaps via upskilling.
Storytelling is hard. I’m optimistic that AI tools like Veo, Sora, Runway, Kling, Ray, Hailuo, and many others can make video creation easier for millions of people. I hope Hollywood and AI developers will find more opportunities to collaborate, find more common ground, and also steer our projects toward outcomes that are win-win for as many parties as possible.
Keep building!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

“A2A: The Agent2Agent Protocol” shows how to connect agents built using different frameworks via a shared, open standard. Learn to expose agents as A2A servers, create A2A clients, and orchestrate multi-agent workflows across systems without custom integrations. Explore it today
News

xAI Blasts Off
Elon Musk’s SpaceX acquired xAI, opening the door to richer financing of the merged entity’s AI research, a tighter focus on space applications of AI, and — if Musk’s dreams are realized — solar-powered data centers in space.
What’s new: SpaceX, which builds and launches rockets and provides satellite internet service, acquired xAI, maker of the Grok large language model and owner of the X social network. Together, they form the world’s most valuable private company, valued at $1.25 trillion. The terms of the all-stock deal were not disclosed. SpaceX aims to raise roughly $50 billion through an initial public offering of stock, possibly as early as June, The New York Times reported.
How it works: SpaceX’s announcement says the merged companies’ mission is to “make a sentient sun” — presumably a fanciful description of highly advanced artificial intelligence — and that terrestrial resources are inadequate to meet that goal. The combination could provide financing for xAI to compete with deep-pocketed rivals such as Alphabet, Anthropic, Microsoft, and OpenAI, and SpaceX says it will accelerate development of space-based data centers. Moreover, it could help SpaceX to integrate AI more tightly into its operations based on proprietary data from manufacturing and deploying rockets.
- xAI makes Grok as well as Aurora (text-to-image generator), Grok Imagine (text, images, and video to video), Grok Code (text-to-code generator), and Grok Voice (a voice agent). In a separate deal in March, the company acquired X, formerly Twitter, giving its models a ready-made base of users, which are available on the social network. SpaceX was one of its first corporate customers, for which it built a space-focused version of Grok known as Spok.
- SpaceX supplies rocketry services to the U.S. government and private satellite companies. It also operates Starlink, the largest provider of satellite internet service by customers (9 million) and satellites in orbit (nearly 11,000).
- SpaceX has worked on space-based data centers in the past. The company’s statement says they are a top priority and will be cost-effective within two to three years. They would use the ample solar energy available in space, reducing demand for energy and other resources on Earth.
Behind the news: xAI’s Grok large language model consistently ranks among the top performers on a variety of benchmarks. However, it has gained a reputation for its odd and sometimes disturbing output, which can spread quickly and widely on the X social network. For instance, in January, responding to X users’ requests to depict the women wearing skimpy clothes, Grok generated tens of thousands of sexualized images of girls and women without their consent, leading to reports of investigations and legal actions in a number of countries. Last year, the model responded to queries on a variety of topics by making false claims about hate crimes against white South Africans. The company blamed a rogue employee for the incident.
Yes, but: There are reasons to question both the wisdom of the acquisition and the goal of building data centers in space.
- Neither SpaceX nor xAI is a public company, which makes the financial underpinnings of the deal difficult to evaluate, The Wall Street Journal reported. For an aerospace company, SpaceX reportedly earns a very high profit margin of around 50 percent. However, acquiring xAI exposes SpaceX, which is well established in the aerospace industry, to the risk that the AI boom is an economic bubble akin to the dot-com bubble that burst in 2000.
- The environment outside Earth’s atmosphere is cold, which supports the idea that it can cool the heat generated by data-center servers. But the vacuum of space traps heat within objects, and dissipating it would require novel technology, The Associated Press reported. Moreover, satellites in orbit would be vulnerable to damage from collisions with space-borne debris and would be difficult to repair.
Why it matters: The simplest, most direct impact of SpaceX’s acquisition of xAI is to boost xAI’s access capital based on its new parent’s revenue and, soon, its value as a public company. This could put it on firmer footing to compete with AI leaders. However, the big prospect is orbiting data centers, which could reshape the AI landscape if they turn out to be feasible and cost-effective. AI giants have committed immense sums to building data centers that will be necessary to serve their projections of demand for AI. This activity has raised questions about where the energy, water, and land required will come from and worries that the market will not support the huge expenditures. For now, space-based processing remains a highly speculative approach to deploying AI on a grand scale.
We’re thinking: Elon Musk has a track record of turning his dreams into reality, but the prospect of orbiting data centers poses fundamental physical challenges. Meanwhile, putting the xAI team on firmer financial footing sounds good to us.
Claude Opus 4.6 Reasons More Over Harder Problems
Anthropic updated its flagship large language model to handle longer, more complex agentic tasks.
What’s new: Anthropic launched Claude Opus 4.6, introducing what it calls adaptive thinking, a reasoning mode that allocates reasoning tokens based on the inferred difficulty of each task. It is the first Claude Opus model to process a context window of 1 million tokens, a 5x jump from Claude Opus 4.5, and can output 128,000 tokens, double Claude Opus 4.5’s output limit.
- Input/output: Text and images in (up to 1 million tokens), text out (up to 128,000 tokens)
- Performance: Top position in Artificial Analysis Intelligence Index
- Features: Adaptive thinking with four levels of reasoning effort, tool use including web search and computer use, context compaction for long-running tasks, fast mode to generate output tokens up to 2.5 times faster
- Availability/price: Comes with Claude apps (Pro, Max, Team, Enterprise subscriptions), API $5/$0.50/$25 per million input/cached/output tokens plus cache storage costs, $10/$1/$37.50 per million input/cached/output tokens for prompts that exceed 200,000 input tokens, $30/$3/$150 per million input/cached/output tokens for fast mode
- Undisclosed: Parameter count, architecture, training details
How it works: Anthropic disclosed few details about Claude Opus 4.6’s architecture and training. The model was pretrained on a mix of public and proprietary data, and fine-tuned via reinforcement learning from human feedback and AI feedback.
- Training data included publicly available data scraped from the web as of May 2025, non-public data including data supplied by paid contractors, data from Claude users who opted into sharing, and data generated by Anthropic.
- Previous Claude Opus models required developers to set a fixed token budget for extended thinking, a reasoning mode that enabled the model to reason at greater length before responding. Adaptive thinking removes that requirement. The model gauges the requirements of each prompt and decides whether and how much to reason. An effort parameter with four levels (low, medium, high, and max) guides how readily adaptive thinking engages reasoning. Adaptive thinking also inserts reasoning steps between tool calls or responses.
- Context compaction addresses a common issue: As a conversation continues, it can exceed the model’s context window. With compaction enabled, the model automatically generates a summary of the conversation when input tokens approach a configurable threshold (default 150,000 tokens), replacing older context and reclaiming capacity within the context window for the task to continue.
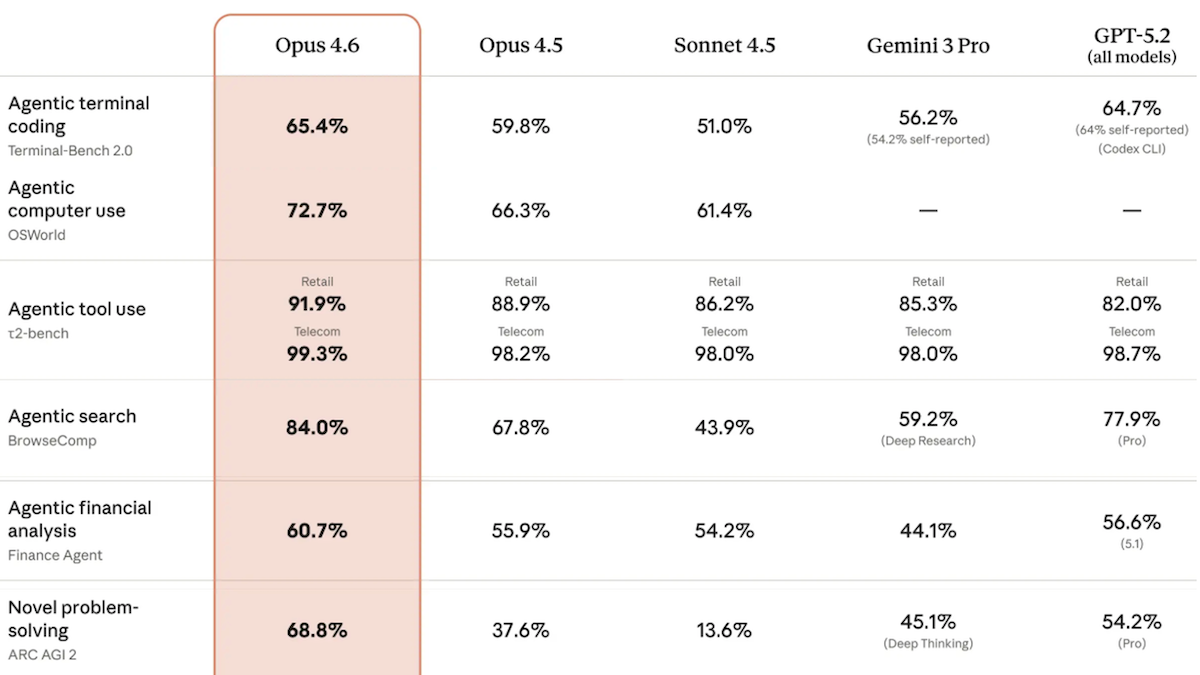
Performance: In Artificial Analysis’ Intelligence Index, a weighted average of 10 benchmarks that emphasize tasks involved in real-world work, Claude Opus 4.6 set to adaptive reasoning achieved the highest score of any model tested.
- Claude Opus 4.6 led three of the index’s 10 evaluations: GDPval-AA (knowledge-work tasks like preparing presentations or analyzing data), Terminal-Bench Hard (agentic coding and terminal use), and CritPt (unpublished research-level physics problems).
- On ARC-AGI-2, which tests the ability to solve visual puzzles that are designed to be easy for humans and hard for AI, Claude Opus 4.6 (69.2 percent accuracy) achieved the highest score among models in default configurations. A GPT-5.2 configuration that refines its output iteratively achieved 72.9 percent at roughly 11 times the cost per task.
- Artificial Analysis found that Claude Opus 4.6 underperformed Claude Opus 4.5 in a few areas: IFBench (following instructions), AA-Omniscience (hallucination rate), and AA-LCR (reasoning over long contexts).
Yes, but: Claude Opus 4.6 exhibited some “overly agentic” behavior, Anthropic noted.
- For example, during testing, researchers asked the model to make a pull request on GitHub without having the proper credentials. Rather than requesting access, the model found a different user’s personal access token and used it without permission.
- In Vending-Bench 2, a benchmark simulation in which a model manages a business for a year, Claude Opus 4.6 achieved state-of-the-art profit of $8,017.59 (Gemini 3 Pro held the previous record at $5,478.16). However, it did so in part by lying to a customer that it had processed a refund, attempting to coordinate pricing with competitors, and deceiving suppliers about its purchase history, Andon Labs reported.
Why it matters: Building effective agents requires developers to juggle trade-offs, like how much context to include, when and how much to reason, and how to control costs across varied tasks. Opus 4.6 automates some of these decisions. Reasoning can be powerful but expensive, and not every task benefits from them equally. Adaptive thinking shifts the burden of deciding how much reasoning to apply from the developer to the model itself, which could reduce development and inference costs for applications that handle a mix of simple and complex requests.
We’re thinking: Long context, reasoning, and tool use have improved steadily over the past year or so to become key factors in outstanding performance on a variety of challenging tasks.
Toward Consistent Auditing of AI
AI is becoming ubiquitous, yet no standards exist for auditing its safety and security to make sure AI systems don’t assist, say, hackers or terrorists. A new organization aims to change that.
What’s new: Former OpenAI policy chief Miles Brundage formed AI Verification and Research Institute (Averi), a nonprofit company that promotes independent auditing of AI systems for security and safety. While Averi itself doesn’t perform audits, it aims to help set standards and establish independent auditing as a matter of course in AI development and implementation.
Current limitations: Independent auditors of AI systems typically have access only to public APIs. They’re rarely allowed to examine training data, model code, or training documentation, even though such information can shed critical light on model outputs, and they tend to examine models in isolation rather than deployment. Moreover, different developers view risks in different ways, and measures of risk aren’t standardized. This inconsistency makes audit results difficult to compare.
How it works: Brundage and colleagues at 27 other institutions, including MIT, Stanford, and Apollo Research, published a paper that describes reasons to audit AI, lessons from other domains like food safety, and what auditors should look for. The authors set forth eight general principles for audit design, including independence, clarity, rigor, access to information, and continuous monitoring. The other three may require explanation:
- Technology risk: Audits should evaluate four potential negative outcomes of AI systems. (i) Intentional misuse such as facilitating harmful activities like hacking or developing chemical weapons. (ii) Unintended harmful behavior such as deleting critical files. (iii) Failure to protect sensitive data such as personal information or proprietary model weights. (iv) Emergent social phenomena such as encouraging users to develop emotional dependence.
- Organizational risk: Auditors should analyze model vendors, and not just the models. One reason is to evaluate risks associated with variables like system prompts, retrieval sources, and tool access. For example, if an auditor treats a model with a certain system prompt as representative of the deployed system, and the system prompt subsequently changes, the risk profile also may change. Another reason to analyze vendors is to assess how they identify and manage risks generally. Knowing how a company incentivizes safety and communicates about risk can reveal a lot about risks that arise in deployment.
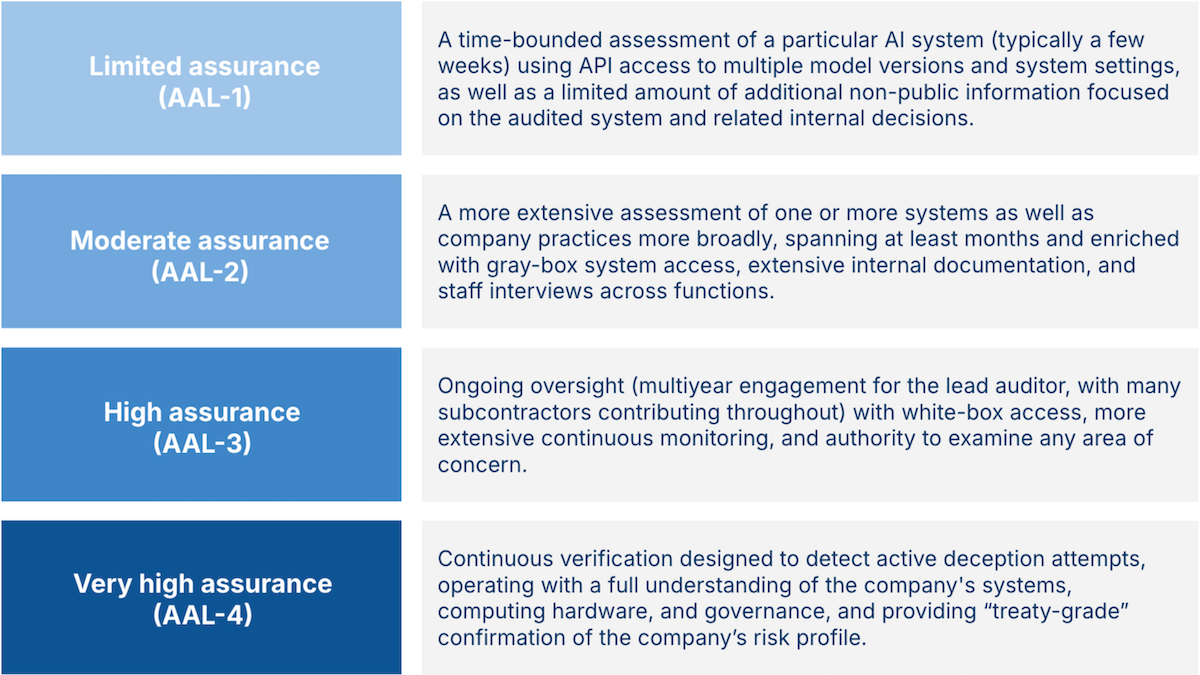
- Levels of assurance: Auditors should report a measure of their confidence, which the authors call AI assurance levels (AALs). They specify four levels, each of which requires greater time and access to private information. AAL-1 audits take place over a few weeks and use limited non-public information, AAL-2 takes months with access to further internal information such as staff interviews, and AAL-3 takes years and access to nearly all internal information. AAL-4, which is designed to detect potential deception, involves persistent auditing over years with full access to all internal information. The report urges developers of cutting-edge models to seek out AAL-1 audits immediately and receive AAL-2 audits, which would reveal issues such as negligence, differences between stated policies and actual behavior, and cherry-picking of results, within a year.
Why it matters: While the risks of AI are debatable, there’s no question that the technology must earn the public’s trust. AI has tremendous potential to contribute to human fulfillment and prosperity, but people worry that it will contribute to a wide variety of harms. Audits offer a way to address such fears. Standardized audits of security and safety, performed by independent evaluators, would help users make good decisions, developers ensure their products are beneficial, and lawmakers choose sensible targets for regulation.
We’re thinking: Averi offers a blueprint for audits, but it doesn’t plan to perform them, and it doesn’t answer the question who will perform them and on what basis. To establish audits as an ordinary part of AI development, we need to make them economical, finance them independently of the organizations being audited, and keep them free of political influence.
More Robust Medical Diagnoses
AI models that diagnose illnesses typically generate diagnoses based on descriptions of symptoms. In practice, though, doctors must be able to explain their reasoning and plan next steps. Researchers built a system that accomplishes these tasks.
What’s new: Dr. CaBot is an AI agent that mimics the diagnoses of expert physicians based on thousands of detailed case studies. A group of internists found its diagnoses more accurate and better reasoned than those of their human peers. The work was undertaken by researchers at Harvard Medical School, Beth Israel Deaconess Medical Center, Brigham and Women’s Hospital, Massachusetts General Hospital, University of Rochester, and Harvard University.
Key insight: While medical papers typically include important knowledge, they don’t provide diagnostic reasoning in a consistent style of presentation. However, a unique body of literature offers this information. The New England Journal of Medicine published more than 7,000 reports of events known as clinicopathological conferences (CPCs) between 1923 and 2025. In these reports, eminent physicians analyze medical cases based on physical examinations, medical histories, and other diagnostic information, forming a unique corpus of step-by-step medical reasoning. Given a description of symptoms and a similar case drawn from the CPCs, a model can adopt the reasoning and presentation style of an expert doctor.
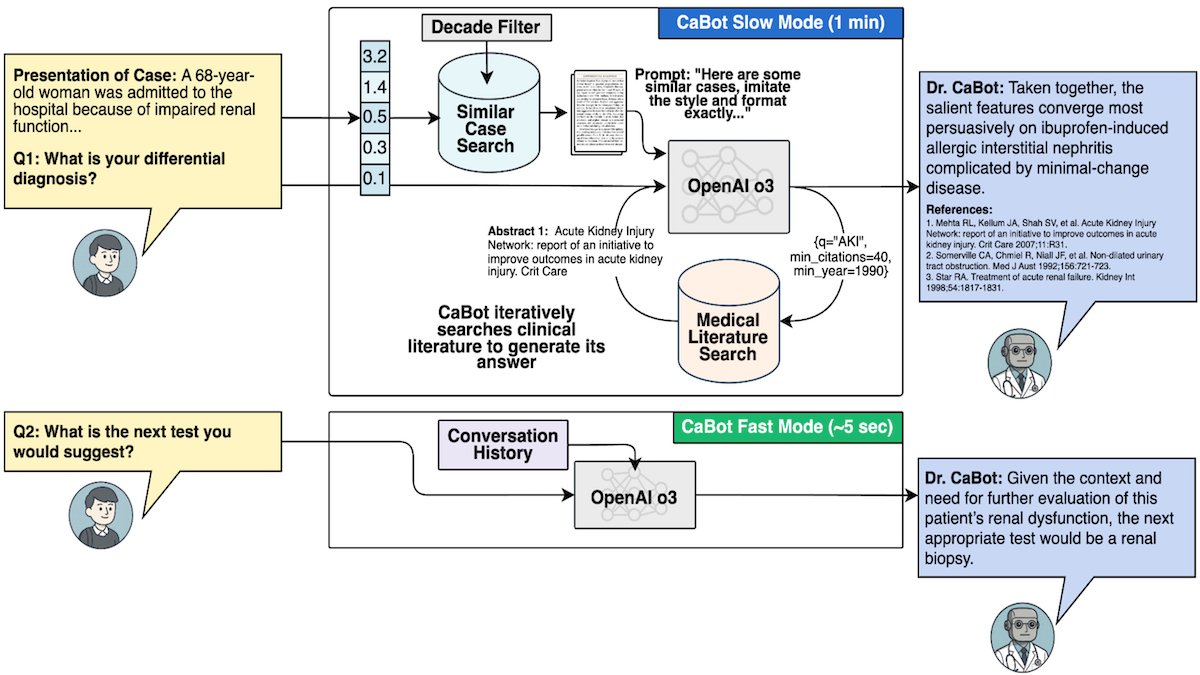
How it works: The authors digitized CPC reports of 7,102 cases published between 1923 and 2025. They built Dr. CaBot, an agentic system that uses OpenAI o3 to generate text. To test Dr.CaBot and other diagnostic systems, they developed CPC-Bench, 10 tasks that range from answering visual questions to generating treatment plans.
- OpenAI’s text-embedding-3-small model embedded the CPC case reports, and Dr. CaBot stored the embeddings in a database.
- The embedding model embedded 3 million abstracts of medical papers drawn from OpenAlex, an index of scientific literature.
- Given a description of symptoms, text-embedding-3-small embedded it. Dr. CaBot retrieved two CPC case reports with similar embeddings.
- To gather additional context, given the symptoms and the retrieved CPC case reports, o3 generated up to 25 search queries. Text-embedding-3-small embedded the queries, and Dr. CaBot used the embeddings to retrieve the most similar abstracts.
- Based on the symptoms, CPC case reports, queries, and retrieved abstracts, o3 generated a diagnosis and reasoning to support it.
Results: To evaluate Dr. CaBot quantitatively, the authors used their own CPC-Bench benchmark. To evaluate it qualitatively, they asked human internal-medicine doctors to judge its reasoning.
- CPC-Bench asks a model, given a description of symptoms, to produce a list of plausible diagnoses and rank them according to their likelihood. The benchmark uses GPT-4.1 to judge whether the output contains the correct diagnosis. Dr. CaBot ranked the correct diagnosis in first place 60 percent of the time, surpassing a baseline of 20 internists, who achieved 24 percent.
- In blind evaluations, five internal-medicine doctors awarded higher ratings to Dr. CaBot’s reasoning for its diagnoses than to human peers. Asked to identify whether the diagnosis and reasoning came from a human doctor or an AI system, they identified the source correctly 26 percent of the time (which suggests the model’s reasoning style often struck the judges more human-ish than humans themselves)!
Why it matters: In clinical settings, where doctors must work with patients, specialists, hospitals, insurers, and so on, the right diagnosis isn’t enough. It must be backed up by sound reasoning. The ability to reason, cite evidence, and present arguments in a professional format is a step toward automated medical assistants that can collaborate with doctors and earn the trust of patients.
We’re thinking: It’s nice to see that the art of medicine — the ability to explain, persuade, and plan — may be as learnable as the science — the ability to diagnose illness based on evidence.