
Dear friends,
If you have not yet built an agentic workflow, I encourage you to try doing so, using the simple recipe I’ll share here! With a few lines of code, you can now build a highly autonomous, moderately capable, and highly unreliable agent.
The ability of frontier LLMs to carry out multiple steps autonomously makes this possible. Specifically, you can give an LLM a tool such as disk access (or web search), instruct it via a prompt to perform a high-level task such as creating a game and saving it as an HTML file (or carrying out deep research on a topic), and let it loose and see what it does.
Important caveat: Hardly any of today’s many practical, commercially valuable agentic workflows were built using this simple approach. Today’s agents need much more scaffolding — that is, code that guides its step-by-step actions — rather than just letting an LLM have access to some tools and fully autonomously decide what to do. Building a reliable agent today requires much more scaffolding to guide it; but as LLMs become more capable, we will see successful agents built with less scaffolding.
If you want to build practical agents, our Agentic AI course is the best way to learn how. But you can still have fun playing with this simple but less practical recipe!
A quick way to implement this recipe is to use the open source aisuite package (pip install "aisuite[all]") that Rohit Prasad and I have been working on. This package makes it easy to switch LLM providers and also to get an LLM to use tools (function calls) without needing to write a massive amount of code.
Aisuite started as a weekend project when I was trying to solve my personal pain point of wanting an easy way to switch LLM providers. After building a workflow using a specific LLM, I often want to quickly try out alternatives to see if they perform better in accuracy, latency, or cost. Routing my LLM API calls through aisuite makes these swaps much easier. Many members of the open-source community have been contributing to this, and Rohit recently added MCP support, which makes it easy to build basic agentic workflows.
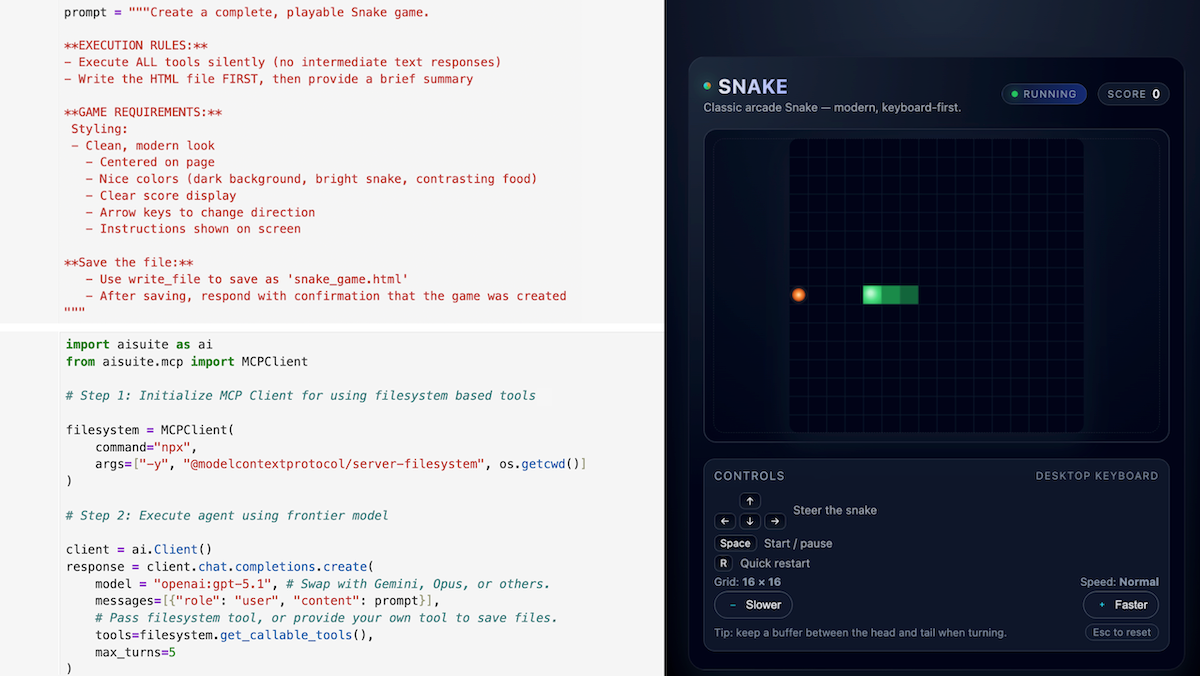
You can see the entirety of the code needed to generate a snake game in the image above, and access it in this Jupyter notebook. After writing a prompt instructing an LLM to create an HTML file with a snake game, the two steps are:
- Initialize the MCP-based file-system tool to let it write files.
- Let loose a frontier model (such as GPT-5.1, Claude Sonnet 4.5, or Gemini 3).
This (usually) results in the LLM creating a snake game and using the MCP server to save a file snake_game.html, which you can open in a web browser. (The parameter max_turns=5 means that it will alternate between calling the LLM and letting the LLM execute a tool up to 5 times before exiting.)
For another example, here’s a second notebook that demonstrates giving an LLM access to a web search tool and letting it autonomously decide when and how much to search the web to compile a report or HTML dashboard on the weather in multiple cities or some other topic of your choice.
If you have not yet built an agent, I hope this simple recipe lets you build your first one. Please run pip install "aisuite[all]" and have fun!
Keep building!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

Learn multi-vector image retrieval in our new short course with Qdrant. You’ll use ColBERT to see how multi-vector search works for text, ColPali to extract patch-level features from images, and MUVERA to compress those patches into a single vector for fast HNSW search, then combine everything into a multi-modal RAG pipeline. Enroll now
News
Claude Does More With Fewer Tokens
Claude Opus 4.5, the latest version of Anthropic’s flagship model, extends the earlier version’s strengths in coding, computer use, and agentic workflows while generating fewer tokens.
What’s new: Claude Opus 4.5 outperforms its immediate predecessor at one-third the price per token.
- Input/output: Text and images in (up to 200,000 tokens), text out (up to 64,000 tokens)
- Features: Adjustable effort (low, medium, high) that governs token generation across responses, tool calls, and reasoning; extended thinking that raises the budget for reasoning tokens; tool use including web search and computer use
- Availability/price: Comes with Claude apps (Pro, Max, Team, Enterprise subscriptions); API $5.00/$0.50/$25.00 per million input/cached/output tokens (plus cache storage costs) via Anthropic, Amazon Bedrock, Google Cloud Vertex AI, Microsoft Foundry
- Undisclosed: Parameter count, architecture, training details
How it works: Anthropic describes Claude Opus 4.5 as a hybrid reasoning model. Like Claude models since Claude Sonnet 3.7, it responds rapidly in its default mode or takes time to process reasoning tokens when extended thinking is enabled.
- Anthropic trained the model on public data scraped from the web and non-public data from third parties, paid contractors, Anthropic users who didn’t opt out, and Anthropic's internal operations. The team fine-tuned the model to be helpful using reinforcement learning from human and AI feedback.
- Claude’s consumer apps now automatically summarize earlier portions of conversations, enabling arbitrarily long interactions.
Performance: In independent tests performed by Artificial Analysis, Claude Opus 4.5 excelled at coding tasks and performed near the top in other areas. In Anthropic’s tests, it attained high performance while using tokens efficiently.
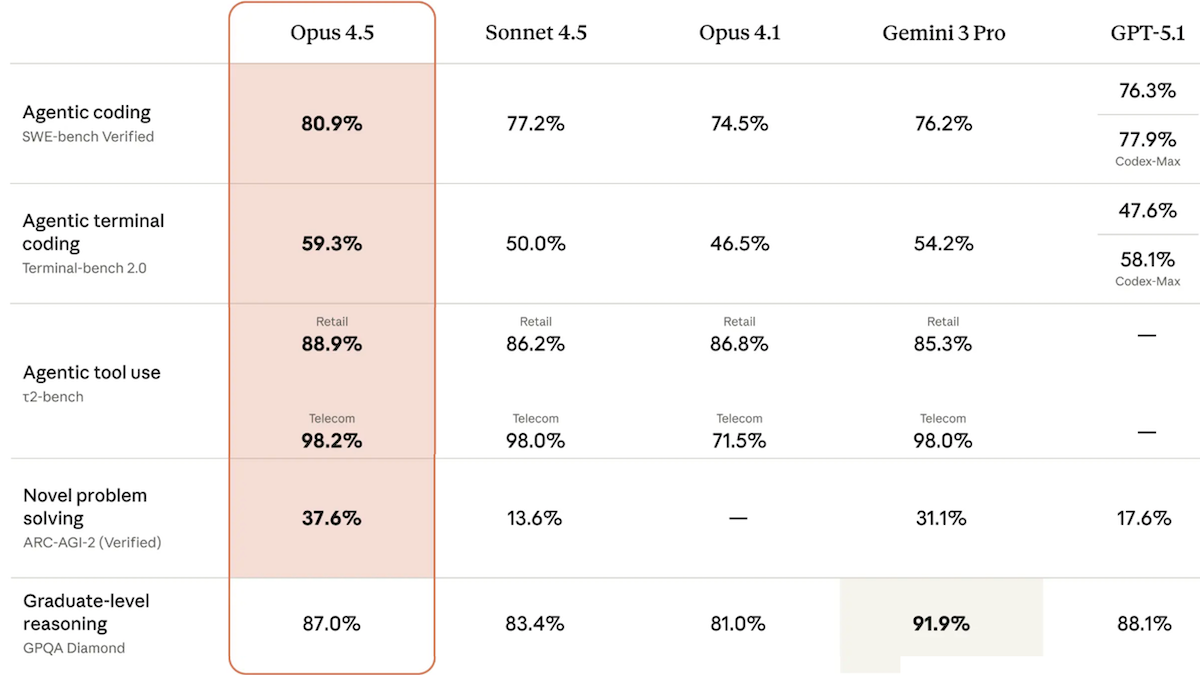
- On the Artificial Analysis Intelligence Index, a weighted average of 10 benchmarks, Claude Opus 4.5 (70) achieved a second-place score, matching OpenAI GPT-5.1 and trailing Google Gemini 3 Pro (73). In non-reasoning mode, it scored 60, highest among non-reasoning models tested. On the AA-Omniscience Index, which measures factual knowledge and tendency to fabricate information (higher is better), Claude Opus 4.5 (10) outperformed GPT-5.1 (2) but lagged behind Gemini 3 Pro Preview (13).
- On Terminal-Bench Hard (command-line tasks), Claude Opus 4.5 (44 percent) outperformed all other models tested by Artificial Analysis.
- According to Anthropic, set to medium effort, Claude Opus 4.5 matched Sonnet 4.5's SWE-bench Verified performance while using 76 percent fewer output tokens. At high effort, it exceeded Sonnet 4.5 by 4.3 percentage points while using 48 percent fewer tokens.
- Using “parallel test-time compute” that included a 64,000-token thinking budget and high effort, Claude Opus 4.5 outperformed all people who have taken a two-hour engineering exam that Anthropic uses to test candidates.
Behind the news: Generally, Claude Opus 4.5 generates fewer output tokens than competitors to achieve comparable results. To run the tests in the Artificial Analysis Intelligence Index, Claude Opus 4.5 (48 million tokens) used roughly half as many as Gemini 3 Pro set to high reasoning (92 million tokens) and GPT-5.1 set to high reasoning (81 million tokens). However, its higher per-token price amounts to higher overall costs than these competitors. Testing Claude Opus 4.5 cost $1,498, Gemini 3 Pro $1,201, and GPT-5.1 $859.
Why it matters: Claude Opus 4.5 arrives after a period in which Anthropic’s mid-tier Sonnet 4.5 often approached or outperformed the older, more expensive Opus 4.1 in many benchmarks. For instance, on the Artificial Analysis Intelligence Index, Claude Sonnet 4.5 (63) exceeded Claude Opus 4.1 (59). The disparity disincentivized users to pay premium rates for Opus for some time. But Claude Opus 4.5 restores a clear hierarchy within the Claude family, with the top-tier model now 7 points ahead of its mid-tier sibling.
We’re thinking: The difference in performance between various frontier models is shrinking. According to Stanford’s latest AI Index, the gap between top-ranked and 10th-ranked models on LM Arena, measured by Elo rating, fell from 11.9 percent to 5.4 percent between 2024 and 2025. The gap between the top two shrank to 0.7 percent. As this trend continues, leaderboard differences are coming to matter less for many applications.

White House Orders AI for Science
President Trump launched a United States effort to use AI to speed up scientific breakthroughs.
What’s new: The Genesis Mission, established by an executive order, directs the Department of Energy to integrate its 17 national labs and some of the country’s most powerful supercomputers to tackle research on areas that range from energy to medicine. Government researchers will work with private-sector partners, including Anthropic, Nvidia, and OpenAI, to train models on proprietary federal datasets and use AI to generate and run experiments.
How it works: The Energy Department will create an AI platform that provides access to government data and enables federal agencies, research labs, and companies to collaborate in building scientific foundation models and AI agents. It will also organize prize competitions, fellowships, partnerships, and funding opportunities that bring these communities together, coordinating diverse government, academic, and private resources that typically remain separate during peacetime. The project is the “largest marshaling of federal scientific resources since the Apollo program,” Michael Kratsios, head of the White House Office of Science and Technology Policy, told Bloomberg.
- Automation: The goal is to train AI models to conceive and conduct scientific research using robotic labs that allow for varying degrees of human involvement.
- Focus: The mission identifies six areas of research focus: biotechnology, manufacturing, materials, nuclear fission, quantum information science, and semiconductors.
- Goals: The project aims to (i) boost the pace of scientific discovery, (ii) protect national security, (iii) find paths to lower-cost energy, and (iv) increase the return on government investment for taxpayers.
- Funding: No new funding has been allocated so far, as is standard with U.S. executive orders. Agencies will start with existing resources, and Congress may approve additional spending.
- Nvidia will build 7 new supercomputers for the government labs, CEO Jensen Huang said, and AMD, Dell, and Nvidia have agreed to build new facilities within the government labs, The New York Times reported.
Behind the news: In scientific research, AI is evolving from a passive tool into an active collaborator that can manage the cycle of scientific discovery from hypothesis to results.
- Google’s AI co-scientist, a multi-agent system designed to generate in-depth research proposals, has demonstrated its capability to generate novel proposals for biomedical research. It identified drug candidates to repurpose for leukemia and liver fibrosis that were subsequently validated in labs.
- AI Scientist, an agentic workflow that directs large language models to generate ideas for AI research, produce code to test them, and document the enquiry, showcased the ability of LLMs to produce AI research papers by ideating, testing, and documenting experimental results.
- RoboChem, an integrated robotic lab developed by the University of Amsterdam, outperformed human chemists in optimizing chemical synthesis, boosting yield and throughput in experimental runs. In earlier work, researchers at the University of Liverpool trained a mobile robot arm to navigate a lab, operate equipment, handle samples, and obtain results far faster than a human scientist.
- AI-powered search engines like Consensus and Scite streamline the ability to find and summarize scientific literature by synthesizing vast amounts of peer-reviewed research.
Yes, but: The Genesis Mission depends on data, yet the federal government has systematically degraded its capacity to collect it. The White House has cut funding for weather data collection by the National Oceanic and Atmospheric Administration, suspended collection of health data by the Centers for Disease Control and Prevention, and shut down several facilities responsible for gathering and curating government data, Politico reported. Lack of large, current datasets could blunt both AI and humanity’s ability to understand the world.
Why it matters: The U.S. push to apply AI to scientific research and coordinate federal, academic, and private resources is a direct response to the investment and advances China has been making in AI, officials said. China is making strides in many areas of science and technology including quantum computing and battery technology, according to the Center for Strategic and International Studies, a nonpartisan think tank. For the AI industry, the Genesis Mission’s plan to launch competitions and other financial incentives to participate in new research efforts related to strategic goals and security is encouraging.
We’re thinking: Autonomous systems that produce, vet, and execute research ideas have shown intriguing progress. With adequate funding and access to data, a partnership between industry, academia, and the Department of Energy presents an exciting opportunity to accelerate it.
Amazon Steps Forward
Amazon raised the competitive profile of its foundation models and added services for custom model training and an agent platform for browser automation.
What’s new: The Nova 2 family of models covers multimodal reasoning, multimodal generation, and speech to speech. Early access to top-of-the-line Nova 2 Pro Preview (multimodal in, text out) and Nova 2 Omni Preview (multimodal in and out) are available via new Nova Forge ($100,000 annually), a new service that offers pre-trained, mid-trained, and post-trained Nova checkpoints, enabling customers to mix proprietary data with Amazon’s datasets. In addition, Amazon launched Nova Act, a service for building browser-automation agents that can navigate websites, fill out forms, extract data, and interact with the web via natural language or Python code. (Disclosure: Andrew Ng serves on Amazon’s board of directors.)
Nova 2 Pro Preview: The latest flagship Nova model, Nova 2 Pro Preview rivals models from Anthropic, Google, and OpenAI on selected benchmarks.
- Input/output: Text, images, video, speech in (up to 1 million tokens), text out.
- Features: Adjustable reasoning levels (low, medium, high), code interpreter via API that runs and evaluates Python code within the same workflow, web grounding via API that retrieves publicly available information with citations, offered as teacher for model distillation via Amazon Bedrock Model Distillation
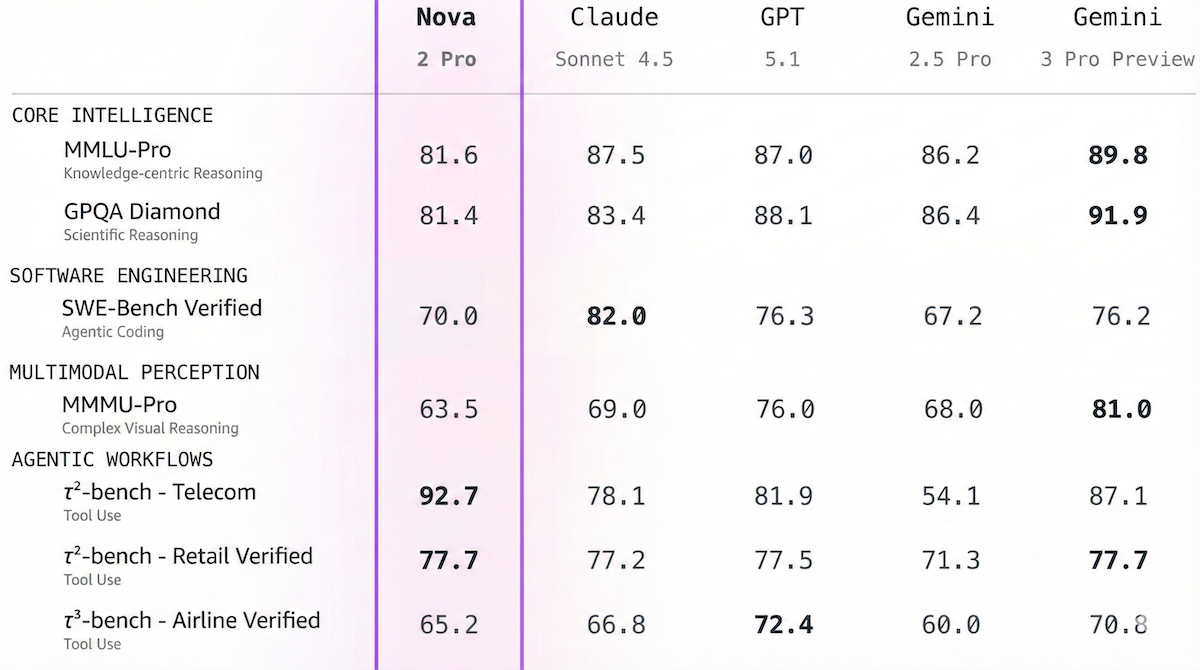
- Performance: In Amazon’s tests, Nova 2 Pro Preview performed equal to or better than Anthropic Claude Sonnet 4.5 on 10 of 16 benchmarks, equal to or better than Google Gemini 3 Pro Preview on 8 of 16 benchmarks, equal to or better than OpenAI GPT-5.1 on 8 of 18 benchmarks. On Artificial Analysis’ Intelligence Index, a weighted average of 10 benchmarks, Nova 2 Pro Preview set to medium reasoning (62) and without reasoning (42) outperformed the earlier Nova Premier (32) but fell short of current leader Gemini 3 Pro Preview (73). On the 𝜏²-Bench Telecom test of agentic behavior, Nova 2 Pro Preview (93 percent) tied for first place with with Grok 4.1 Fast and Kimi K2 Thinking. On the IFBench test of following instructions, Nova 2 Pro Preview (79 percent outperformed GPT 5.1 set to high reasoning (73 percent) and MiniMax-M2 (72 percent). Artificial Analysis has not yet tested Nova 2 Pro Preview on high reasoning.
- Price: $1.25/$0.31/$10 per million input/cached/output tokens via Amazon Nova Forge
Nova 2 Lite: The lightweight Nova 2 Lite is designed to be a fast, cost-effective reasoning model. Performance is equivalent to or better than that of Anthropic Claude Haiku 4.5, Google Gemini Flash 2.5, and OpenAI GPT-5 Mini on most benchmarks tested. $0.3/$0.03/$2.50 per million input/cached/output tokens via Amazon Bedrock.
Nova 2 Omni Preview: Nova 2 Omni Preview is the only widely available reasoning model that natively takes in text, images, video, and speech (up to 1 million tokens, text in over 200 languages, speech in 10 languages) and generates text and images. $0.30/$0.03 per million input/cached text, image, and video tokens; $1.00/$0.10 per million input/cached audio tokens; $2.50/$40 per million output text/image tokens via Amazon Nova Forge.
Nova 2 Sonic: The speech-to-speech model Nova 2 Sonic is multilingual in 7 languages and calls tools without interrupting conversation. In Amazon’s tests, users preferred Nova 2 Sonic to GPT Realtime and Gemini 2.5 Flash in most of its 7 languages. $3/$12 per million input/output speech tokens, $0.33/$2.75 per million input/output text tokens via Amazon Bedrock. The model integrates with Amazon Connect and third-party telephony providers including AudioCodes, Twilio, and Vonage.
Why it matters: The Nova 2 family fills a gap in Amazon’s model portfolio. Until now, the company lacked reasoning models with adjustable thinking levels that would compete with offerings from Anthropic, Google, and OpenAI. In addition, Nova Forge is exciting and significantly different from offerings by Amazon’s AI competitors, and browser automation via Nova Act is a powerful addition to Amazon Bedrock’s agentic capabilities.
We’re thinking: Amazon’s foundation models have lagged behind those of competitors. Nova 2’s higher performance relative to its predecessors suggests that Amazon is serious about closing the gap.
Small Models Solve Hard Puzzles
Large language models often fail at puzzles like Sudoku, for which a solution includes multiple elements and a single mistake invalidates all of them. Researchers showed that a tiny network, by repeatedly refining its solution, can solve this sort of puzzle well.
What’s new: Alexia Jolicoeur-Martineau at Samsung developed Tiny Recursive Model (TRM). This approach outperforms large, pretrained LLMs, including DeepSeek-R1 and Gemini 2.5 Pro, on visual puzzles that require filling in a grid by inferring an abstract rule based on limited information, specifically Sudoku, Maze, and current ARC-AGI benchmarks.
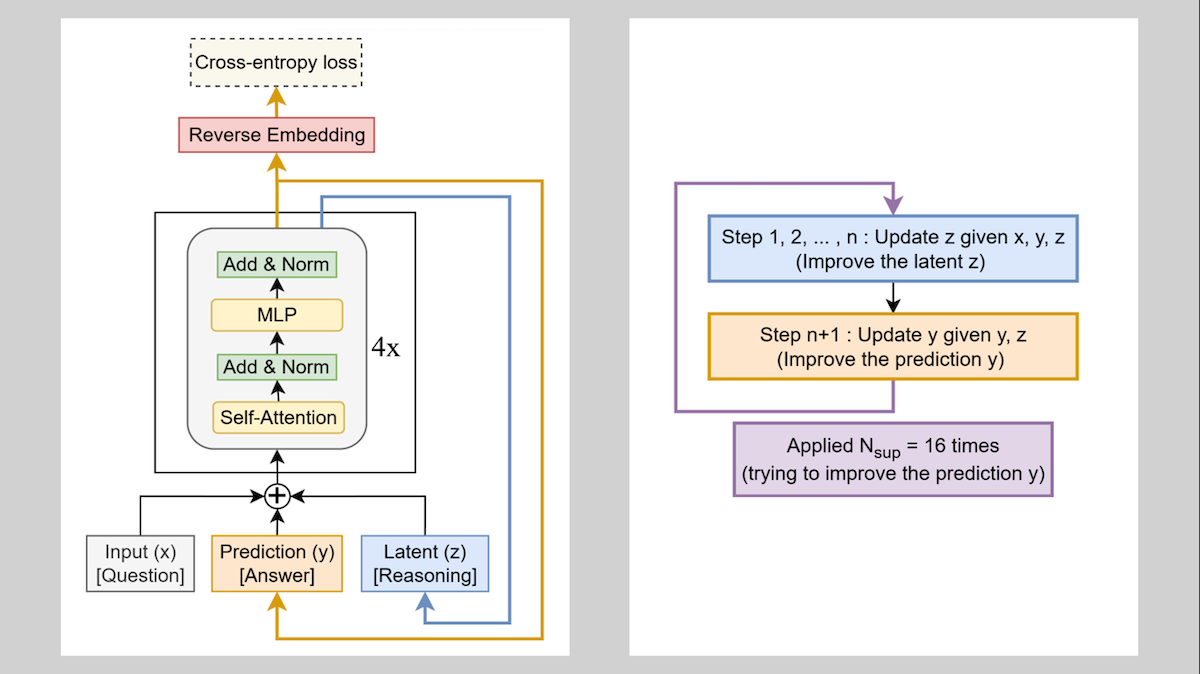
Key insight: Training a neural network to refine a solution iteratively can take place in 3 steps: (i) Give it a random solution and tell it to compute a solution, (ii) feed back the output, compute a new solution, and so on, and (iii) backpropagate through this recursive process so the network learns to produce a more accurate solution through iteration. However, this approach has a key flaw: The network doesn’t keep track of the changes it has made, so during inference, from iteration to iteration, it may undo changes that improved the solution. To counteract this problem, the network can produce a separate context embedding that also feeds back with each iteration. This tactic enables it to learn to store any information that helps to improve performance, such as changes it has made, without needing an explicit loss function that’s designed to accomplish this.
How it works: A TRM is a 2-layer network whose architecture depends on the type of puzzle to be solved. The authors used a 5 million-parameter vanilla neural network to learn Sudoku-Extreme, whose solutions are 9x9 matrices, and 7 million-parameter transformers to learn Maze-Hard, ARC-AGI-1 and ARC-AGI-2, which involve 30x30 matrices. Solving these puzzles requires logic, pathfinding, and visual reasoning at 2 levels of difficulty respectively.
- During training, given a puzzle (represented as tokens), solution tokens (random at first), and a context embedding (random at first), the network iterated for up to 16 cycles.
- Within each cycle, it recursively updated the context embedding 18 times. Each update consisted of a forward pass through the network.
- Each cycle included one more forward pass to produce an improved solution. The model learned to minimize the error between the improved solution and ground truth, and to classify correct solutions. If it recognized a correct solution, it stopped the process.
- During inference, given a puzzle, the network went through the same steps to produce a solution.
Results: TRM outperformed the earlier Hierarchical Reasoning Model (HRM) (27 million parameters) as well as pretrained LLMs.
- On Sudoku-Extreme and Maze-Hard, TRM (87.4 and 85.3 percent accuracy) exceeded HRM (55 and 74.5 percent accuracy). Anthropic Claude Sonnet 3.7, DeepSeek-R1, and OpenAI o3-mini set to high reasoning achieved 0 percent accuracy.
- On ARC-AGI-1, TRM (44.6 percent pass@2) came out behind xAI Grok 4 with thinking mode enabled (66.7 percent pass@2) but ahead of HRM (40.3 percent pass@2), Gemini 2.5 Pro (37 percent pass@2), and Claude Sonnet 3.7 with thinking mode enabled (28.6 percent pass@2).
- Similarly, on the more-challenging ARC-AGI-2 benchmark, TRM (7.8 percent pass@2) underperformed Grok 4 with thinking mode enabled (16.0 percent pass@2) but outperformed HRM (5.0 percent accuracy), Gemini 2.5 Pro (4.9 percent pass@2), and Claude Sonnet 3.7 with thinking mode enabled (0.7 percent pass@2).
Why it matters: A tiny model excels at solving puzzles that require multifaceted solutions to be perfectly correct. Training a simple — but specialized — architecture can be more effective and efficient than raw scale.
We’re thinking: LLMs reason by generating a chain of thought, one model execution at a time, before the final output. On the other hand, TRM reasons by recursively updating its context embedding, one model execution at a time, before the final output.