
Dear friends,
Separate reports by the publicity firm Edelman and Pew Research show that Americans, and more broadly large parts of Europe and the western world, do not trust AI and are not excited about it. Despite the AI community’s optimism about the tremendous benefits AI will bring, we should take this seriously and not dismiss it. The public’s concerns about AI can be a significant drag on progress, and we can do a lot to address them.
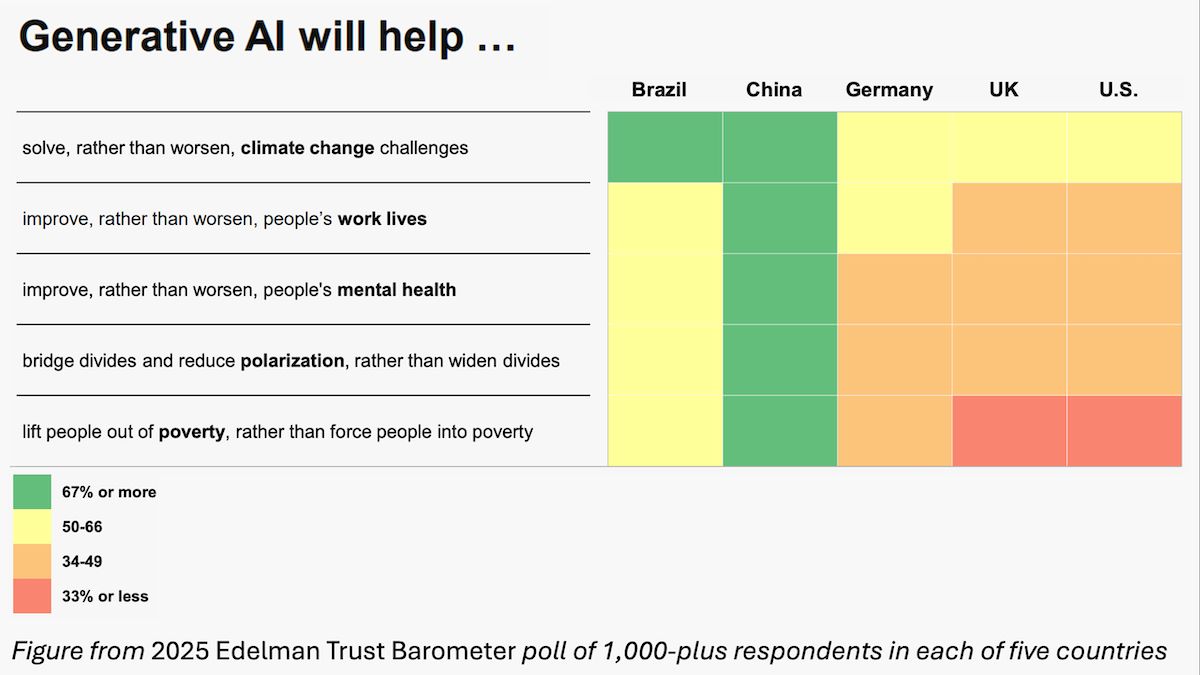
According to Edelman’s survey, in the U.S., 49% of people reject the growing use of AI, and 17% embrace it. In China, 10% reject it and 54% embrace it. Pew’s data also shows many other nations much more enthusiastic than the U.S. about AI adoption.
Positive sentiment toward AI is a huge national advantage. On the other hand, widespread distrust of AI means:
- Individuals will be slow to adopt it. For example, Edelman’s data shows that, in the U.S., those who rarely use AI cite Trust (70%) more than lack of Motivation and Access (55%) or Intimidation by the technology (12%) as an issue.
- Valuable projects that need societal support will be stymied. For example, local protests in Indiana brought down Google’s plan to build a data center there. Hampering construction of data centers will hurt AI’s growth. Communities do have concerns about data centers beyond the general dislike of AI; I will address this in a later letter.
- Populist anger against AI raises the risk that laws will be passed that hamper AI development.
To be clear, all of us working in AI should look carefully at both the benefits and harmful effects of AI (such as deepfakes polluting social media and biased or inaccurate AI outputs misleading users), speak truthfully about both benefits and harms, and work to ameliorate problems even as we work to grow the benefits. But hype about AI’s danger has done real damage to trust in our field. Much of this hype has come from leading AI companies that aim to make their technology seem extraordinarily powerful by, say, comparing it to nuclear weapons. Unfortunately, a significant fraction of the public has taken this seriously and thinks AI could bring about the end of the world. The AI community has to stop self-inflicting these wounds and work to win back society’s trust.
Where do we go from here?
First, to win people’s trust, we have a lot of work ahead to make sure AI broadly benefits everyone. “Higher productivity” is often viewed by general audiences as a codeword for “my boss will make more money,” or worse, layoffs. As amazing as ChatGPT is, we still have a lot of work to do to build applications that make an even bigger positive impact on people’s lives. I believe providing training to people will be a key piece of the puzzle. DeepLearning.AI will continue to lead the charge on AI training, but we will need more than this.
Second, we have to be genuinely worthy of trust. This means every one of us has to avoid hyping things up or fear mongering, despite the occasional temptation to do so for publicity or to lobby governments to pass laws that stymie competing products (such as open source).
I hope our community can also call out journalism that spreads hype. For example, Nirit Weiss-Blatt wrote a remarkable article about how 60 Minutes’ coverage of an Anthropic study in which Claude, threatened with being shut down, resorted to “blackmail,” was highly misleading. The study carried out a red-teaming exercise in which skilled researchers, after a lot of determined work, finally pushed an AI system into a corner so it demonstrated “blackmailing” behavior. Unfortunately, news reports distorted this and led many to think the “blackmail” behavior occurred naturally rather than only because skilled researchers engineered it to happen. The reports left many with a wildly exaggerated picture of how often AI actually “schemes.” Red-teaming exercises are important to test vulnerabilities of systems, but this particular piece of hype, which was widely circulated, will hurt AI for a long time.
Living in Silicon Valley, I realize I live in a bubble of AI enthusiasts, which is great for exchanging ideas and encouraging each other to build! At the same time, I recognize that AI does have problems, and the AI community needs to address them. I frequently speak with people from many different walks of life. I’ve spoken with artists concerned about AI devaluing their work, college seniors worried about the tough job market and whether AI is exacerbating their challenges, and parents worried about their kids being addicted to, and receiving harmful advice from, chatbots.
I don’t know how to solve all of these problems, but I will work hard to solve as many as I can. And I hope you will too. It will only be through all of us doing this that we can win back society’s trust.
Keep building!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

In “Building Coding Agents with Tool Execution,” you’ll learn how coding agents reason, execute code in isolated sandboxes, manage files, and handle feedback loops, then apply it to hands-on examples like a data-analysis agent and a sandboxed Next.js web app. Enroll today
News

Open 3D Generation Pipeline
Meta’s Segment Anything Model (SAM) image-segmentation model has evolved into an open-weights suite for generating 3D objects. SAM 3 segments images, SAM 3D turns the segments into 3D objects, and SAM 3D Body produces 3D objects of any people among the segments. You can experiment with all three.
SAM 3: SAM 3 now segments images and videos based on input text. It retains the ability to segment objects based on input geometry (bounding boxes or points that are labeled to include or exclude the objects at those locations), like the previous version.
- Input/output: Images, video, text, geometry in; segmented images or video out
- Performance: In Meta’s tests, SAM 3 outperformed almost all competitors on a variety of benchmarks that test image and video segmentation. For instance, on LVIS (segmenting objects from text), SAM 3 (48.5 percent average precision) outperformed DINO-X (38.5 percent average precision). It fell behind APE-D (53.0 percent average precision), which was trained on LVIS’ training set.
- Availability: Weights and fine-tuning code freely available for noncommercial and commercial uses in countries that don’t violate U.S., EU, UK, and UN trade restrictions under Meta license
SAM 3D: This model generates 3D objects from images based on segmentation masks. By individually predicting each object in an image, it can represent the entire scene. It can also take in point clouds to improve its output.
- Input/output: Image, mask, point cloud in; 3D object (mesh, Gaussian splat) out
- Performance: Judging both objects and scenes generated from photos, humans preferred SAM 3D’s outputs over those by other models. For instance, when generating objects from the LVIS dataset, people preferred SAM 3D nearly 80 percent of the time, Hunyuan3d 2.0 about 12 percent of the time, and other models 8 percent of the time.
- Availability: Weights and inference code freely available for noncommercial and commercial uses in countries that don’t violate U.S., EU, UK, and UN trade restrictions under Meta license
SAM 3D Body: Meta released an additional model that produces 3D human figures from images. Input bounding boxes or masks can also determine which figures to produce, and an optional transformer decoder can refine the positions and shapes of human hands.
- Input/output: Image, bounding boxes, masks in; 3D objects (mesh, Gaussian splat) out
- Performance: In Meta’s tests, SAM 3D Body achieved the best performance across a number of datasets compared to other models that take images or videos and generate 3D human figures. For example, on the EMDB dataset of people in the wild, SAM 3D Body achieved 62.9 Mean Per Joint Position Error (MPJPE, a measure of how different the predicted joint positions are from the ground truth, lower is better) compared to next best Neural Localizer Fields, which achieved 68.4 MPJPE. On Freihand (a test of hand correctness), SAM 3D Body achieved similar or slightly worse performance than models that specialize in estimating hand poses. (The authors claim the other models were trained on Freihand’s training set.)
- Availability: Weights, inference code, and training data freely available in countries that don’t violate U.S., EU, UK, and UN trade restrictions under Meta license
Why it matters: This SAM series offers a unified pipeline for making 3D models from images. Each model advances the state of the art, enabling more-accurate image segmentations from text, 3D objects that human judges preferred, and 3D human figures that also appealed to human judges. These models are already driving innovations in Meta’s user experience. For instance, SAM 3 and SAM 3D enable users of Facebook marketplace to see what furniture or other home decor looks like in a particular space.
We’re thinking: At the highest level, all three models learned from a similar data pipeline: Find examples the model currently performs poorly on, use humans to annotate them, and train on the annotations. According to Meta’s publications, this process greatly reduced the time and money required to annotate quality datasets.

Generated, Editable Virtual Spaces
Models that generate 3D spaces typically generate them as users move through them without generating a persistent world to be explored later. A new model produces 3D worlds that can be exported and modified.
What’s new: World Labs launched Marble, which generates persistent, editable, reusable 3D spaces from text, images, and other inputs. The company also debuted Chisel, an integrated editor that lets users modify Marble’s output via text prompts and craft spaces environments from scratch.
- Input/output: Text, images, panoramas, videos, 3D layouts of boxes and planes in; Gaussian splats, meshes, or videos out.
- Features: Expand spaces, combine spaces, alter visual style, edit spaces via text prompts or visual inputs, download generated spaces
- Availability: Subscription tiers include Free (4 outputs based on text, images, or panoramas), $20 per month (12 outputs based on multiple images, videos, or 3D layouts), $35 per month (25 outputs with expansion and commercial rights), and $95 per month (75 outputs, all features)
How it works: Marble accepts several media types and exports 3D spaces in a variety of formats.
- The model can generate a 3D space from a single text prompt or image. For more control, it accepts multiple images with text prompts (like front, back, left, or right) that specify which image should map to what areas. Users can also input short videos, 360-degree panoramas, or 3D models and connect outputs to build complex spaces.
- The Chisel editor can create and edit 3D spaces directly. Geometric shapes like planes or blocks can be used to build structural elements like walls or furniture and styled via text prompts or images.
- Generated spaces can be extended by clicking on an area to be extended or connected.
- Model outputs can be Gaussian splats (high-quality representations composed of semi-transparent particles that can be rendered in web browsers), collider meshes (simplified 3D geometries that define object boundaries for physics simulations), and high-quality meshes (detailed geometries suitable for editing). Video output can include controllable camera paths and effects like smoke or flowing water.
Performance: Early users report generating game-like environments and photorealistic recreations of real-world locations.
- Marble generates more complete 3D structures than depth maps or point clouds, which represent surfaces but not object geometries, World Labs said.
- Its mesh outputs integrate with tools commonly used in game development, visual effects, and 3D modeling.
Behind the news: Earlier generative models can produce 3D spaces on the fly, but typically such spaces can’t be saved or revisited interactively. Marble stands out by generating spaces that can be saved and edited. For instance, in October, World Labs introduced RTFM, which generates spaces in real time as users navigate through them. Competing startups like Decart and Odyssey are available as demos, and Google’s Genie 3 remains a research preview.
Why it matters: World Labs founder and Stanford professor Fei-Fei Li argues that spatial intelligence — understanding how physical objects occupy and move through space — is a key aspect of intelligence that language models can’t fully address. With Marble, World Labs aspires to catalyze development in spatial AI just as ChatGPT and subsequent large language models ignited progress in text processing.
We’re thinking: Virtual spaces produced by Marble are geometrically consistent, which may prove valuable in gaming, robotics, and virtual reality. However, the objects within them are static. Virtual worlds that include motion will bring AI even closer to understanding physics.
Baidu’s Multimodal Bids
Baidu debuted two models: a lightweight, open-weights, vision-language model and a giant, proprietary, multimodal model built to take on U.S. competitors.
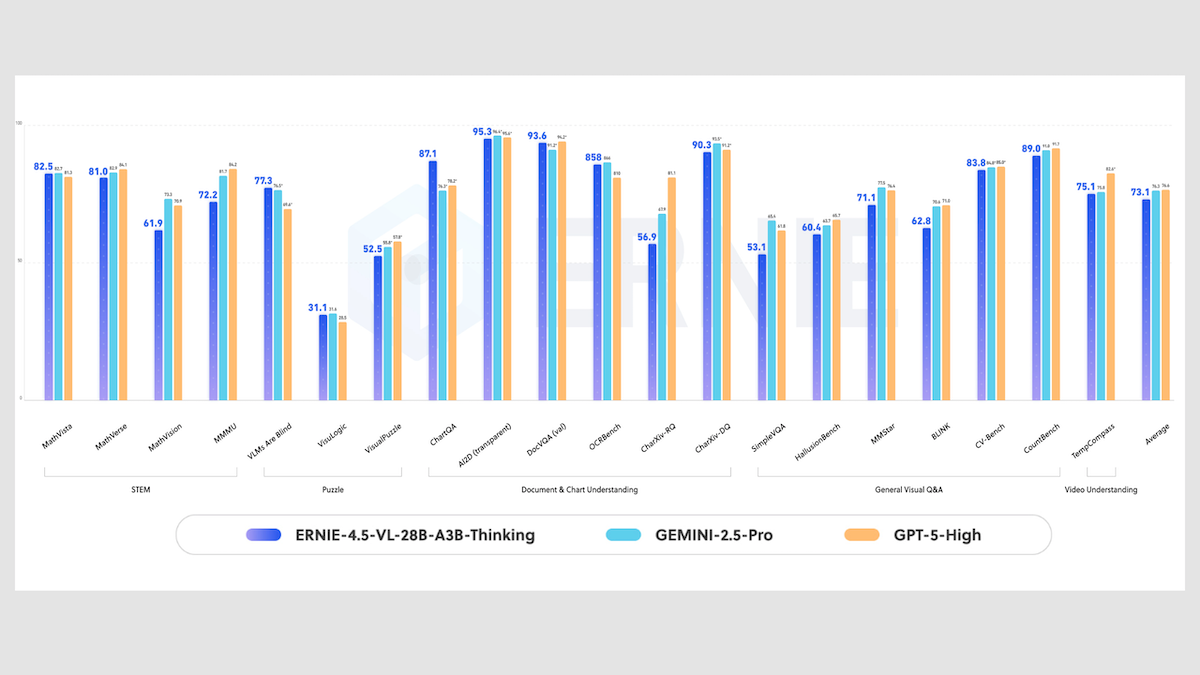
Ernie-4.5-VL-28B-A3B-Thinking: Baidu’s new open-weights model is based on the earlier Ernie-4.5-21B-A3B Thinking, a text-only MoE reasoning model, plus a 7 billion-parameter vision encoder to process images.It outperforms comparable and larger models on visual reasoning tasks. It can extract on-screen text and analyze videos across time, and it can call tools to zoom in on image details and search for related images.
- Input/output: Text, image, video in (up to 128,000 tokens); text out
- Architecture: Mixture-of-experts (MoE) transformer (28 billion parameters total, 3 billion active per token), 21 billion-parameter language decoder/encoder.
- Training: The authors used vision-language reasoning examples during mid-training, an emerging phase that typically uses mid-size datasets to sharpen distinct skills or impart specific domains prior to fine-tuning. In addition, they fine-tune via reinforcement learning (RL) with multimodal data. Because MoE architectures can become unstable during RL, the team used a combination of GSPO and IcePop to stabilize the fine-tuning.
- Features: Tool use, reasoning
- Performance: Ernie-4.5-VL-28B-A3B-Thinking competes with larger proprietary models on document understanding tasks despite activating only 3 billion parameters, Baidu said. For instance, on ChartQA (chart interpretation), Ernie-4.5-VL-28B-A3B-Thinking reached 87.1 percent accuracy, outperforming Gemini 2.5 Pro (76.3 percent) and GPT-5 set to high reasoning (78.2 percent). On OCRBench (text recognition in images), it achieved 858, ahead of GPT-5 set to high reasoning (810) but trailing Gemini 2.5 Pro (866).
- Availability: Weights free for noncommercial and commercial uses under Apache 2.0 license via HuggingFace. API $0.14/$0.56 per million input/output tokens via Baidu Qianfan.
- Undisclosed: Output size limit, training data, reward models
Ernie-5.0: Baidu describes Ernie-5.0’s approach as natively multimodal, meaning it was trained on text, images, audio, and video together rather than fusing different media encoders after training or routing inputs to specialized models. It performs comparably to the similarly multimodal Google Gemini 2.5 or OpenAI GPT-5, according to Baidu.
- Input/output: Text, image, audio, and video in (up to 128,000 tokens); text, image, audio, video out (up to 64,000 tokens)
- Architecture: Mixture-of-experts (MoE) transformer (2.4 trillion parameters total, less than 72 billion active per token)
- Features: Vision-language-audio understanding, reasoning, agentic planning, tool use
- Performance: In Baidu’s tests of multimodal reasoning, document understanding, and visual question-answering, the company reports that Ernie-5.0 matched or exceeded OpenAI GPT-5 set to high reasoning and Google Gemini 2.5 Pro. For instance, on OCRBench (document comprehension), DocVQA (document comprehension), and ChartQA (structured data reasoning), Baidu Ernie-5.0 achieved top scores. On MM-AU (multimodal audio understanding) and TUT2017 (acoustic scene classification), it demonstrated competitive performance, Baidu said without publishing specific metrics.
- Availability: Free web interface, API $0.85/$3.40 per million input/output tokens via Baidu Qianfan
- Undisclosed: Training data, training methods
Yes, but: Shortly after Ernie-5.0's launch, a developer reported that the model repeatedly called tools even after instruction not to. Baidu acknowledged the issue and said it was fixing it.
Why it matters: Ernie-4.5-VL-28B-A3B-Thinking offers top visual reasoning at the fraction of the cost of competing models, and more flexibility for fine-tuning and other commercial customizations. However, the long-awaited Ernie 5.0 appears to fall short of expectations. It matches top models on some visual tasks but stops short of the forefront (including Qwen3-Max and Kimi-K2-Thinking) on leaderboards like LM Arena. Pretraining on text, images, video, and audio together is a relatively fresh approach that could simplify current systems that piece together different encoders and decoders for different media types.
We’re thinking: Ernie-5.0 may outperform Gemini 2.5 and GPT-5, but Google and OpenAI have already moved on to Gemini 3 and GPT-5.1!

Coordinating Robot Teams
In factories, where teams of robotic arms work in tight spaces, their motions are programmed by hand to keep them from interfering with one another. Researchers automated this programming using graph neural networks trained via reinforcement learning.
What’s new: Matthew Lai, Keegan Go, and colleagues at Google DeepMind, University College London, and robotics software shop Intrinsic developed RoboBallet, a graph neural network that coordinates robotic arms.
Key insight: Coordinating several robot arms is computationally infeasible for traditional search-based planners that figure out how to reach a target by searching through possible joint movements while checking for collisions. Each additional robot or obstacle multiplies the number of possible configurations. A graph neural network can overcome this limitation by learning to produce synchronized, collision-free motions in large numbers of simulated setups with different robot placements, obstacles, and target positions.
How it works: RoboBallet is a graph neural network that takes as input positions and orientations of robots, obstacles, and targets and generates joint velocities for each arm from its current position to reach a target. The authors trained it entirely in simulation using the TD3 actor-critic algorithm, a reinforcement learning algorithm. They generated about 1 million simulated workspaces, each of which contained a team of 4 or 8 simulated 3-joint Franka Panda robotic arms attached to the sides of a table at random, 30 obstacle blocks placed at random, and 40 target positions/orientations per team. They rejected configurations that started in collision.
- Given a workspace, the authors represented robots, obstacles, and target positions as nodes in a graph. Edges connected each robot’s tip to its target position, each obstacle, and each other robot. The edge embeddings encoded how the robot’s tip related to an object’s or position’s centroid, size, and orientation.
- During training, every 100 milliseconds, the model selected joint velocities of all robots, effectively telling each arm how to move (the actor role in the actor-critic learning algorithm). In parallel, it evaluated how good each prediction was – that is, how much total reward the current action and all actions likely to follow would yield (the critic role).
- The authors rewarded the model for arms that touched the target positions and penalized collisions. Because the arms rarely touched the target positions, they used Hindsight Experience Replay, a method that turns failed attempts into useful examples by treating points that the arm reached accidentally as intended goals.
- The loss encouraged the actor to produce actions that the critic predicted would lead to higher long-term rewards. This helped the model learn to prefer actions that paid off over time rather than maximize immediate rewards.
Results: The authors tested the trained model in the real world. For real-world tests, the authors generated graphs from the known geometry of a physical workspace, using robot placements and 3D meshes of obstacles.
- Given new work spaces, the model generated collision-free trajectories for up to 8 Franka Panda robotic arms.
- RoboBallet effectively parallelized work. Average time to move robots to 20 target positions dropped from 7.5 seconds with 4 arms to 4.3 seconds with 8 arms.
- In a simplified benchmark with four robots and 20 target positions, RoboBallet produced trajectories as quickly as the best hand-optimized baselines, reaching all target poses in the same range of 8 to 11 seconds.
Why it matters: RoboBallet shows that a learning algorithm can coordinate many robots working together in real-world setups, and it can do so after training exclusively in a simulation. In addition, the model is more robust. When a robot fails, hard-coded routines can’t adapt. By contrast, the graph neural network continuously tracks how robots, tasks, and obstacles relate. If a robot fails, it can adapt on the fly and revise its plan.
We’re thinking: Representing the world as a graph enforces a built-in structure to the data, tracking relative positions and relationships between objects. Other data structures don’t inherently provide relationships between objects, so a network learning from them would have to learn those relationships as well. Using a graph makes it easier for a network to learn how to perform a task, since it doesn’t need to learn those relationships.