
Dear friends,
Readers responded with both surprise and agreement last week when I wrote that the single biggest predictor of how rapidly a team makes progress building an AI agent lay in their ability to drive a disciplined process for evals (measuring the system’s performance) and error analysis (identifying the causes of errors). It’s tempting to shortcut these processes and to quickly attempt fixes to mistakes rather than slowing down to identify the root causes. But evals and error analysis can lead to much faster progress. In this first of a two-part letter, I’ll share some best practices for finding and addressing issues in agentic systems.
Even though error analysis has long been an important part of building supervised learning systems, it is still underappreciated compared to, say, using the latest and buzziest tools. Identifying the root causes of particular kinds of errors might seem “boring,” but it pays off! If you are not yet persuaded that error analysis is important, permit me to point out:
- To master a composition on a musical instrument, you don’t only play the same piece from start to end. Instead, you identify where you’re stumbling and practice those parts more.
- To be healthy, you don’t just build your diet around the latest nutrition fads. You also ask your doctor about your bloodwork to see if anything is amiss. (I did this last month and am happy to report I’m in good health! 😃)
- To improve your sports team’s performance, you don’t just practice trick shots. Instead, you review game films to spot gaps and then address them.
To improve your agentic AI system, don’t just stack up the latest buzzy techniques that just went viral on social media (though I find it fun to experiment with buzzy AI techniques as much as the next person!). Instead, use error analysis to figure out where it’s falling short, and focus on that.
Before analyzing errors, we first have to decide what is an error. So the first step is to put in evals. I’ll focus on that for the remainder of this letter and discuss error analysis next week.

If you are using supervised learning to train a binary classifier, the number of ways the algorithm could make a mistake is limited. It could output 0 instead of 1, or vice versa. There are also a handful of standard metrics like accuracy, precision, recall, F1, ROC, etc. that apply to many problems. So as long as you know the test distribution, evals are relatively straightforward, and much of the work of error analysis lies in identifying what types of input an algorithm fails on, which also leads to data-centric AI techniques for acquiring more data to augment the algorithm in areas where it’s weak.
With generative AI, a lot of intuitions from evals and error analysis of supervised learning carry over — history doesn’t repeat itself, but it rhymes — and developers who are already familiar with machine learning and deep learning often adapt to generative AI faster than people who are starting from scratch. But one new challenge is that the space of outputs is much richer, so there are many more ways an algorithm’s output might be wrong.
Take the example of automated processing of financial invoices where we use an agentic workflow to populate a financial database with information from received invoices. Will the algorithm incorrectly extract the invoice due date? Or the final amount? Or mistake the payer address for the biller address? Or get the financial currency wrong? Or make the wrong API call so the verification process fails? Because the output space is much larger, the number of failure modes is also much larger.
Rather than defining an error metric ahead of time, it is therefore typically more effective to first quickly build a prototype, then manually examine a handful of agent outputs to see where it performs well and where it stumbles. This allows you to focus on building datasets and error metrics — sometimes objective metrics implemented in code, and sometimes subjective metrics using LLM-as-judge — to check the system’s performance in the dimensions you are most concerned about. In supervised learning, we sometimes tune the error metric to better reflect what humans care about. With agentic workflows, I find tuning evals to be even more iterative, with more frequent tweaks to the evals to capture the wider range of things that can go wrong.
I discuss this and other best practices in detail in Module 4 of the Agentic AI course we announced last week. After building evals, you now have a measurement of your system’s performance, which provides a foundation for trying different modifications to your agent, as you can now measure what makes a difference. The next step is then to perform error analysis to pinpoint what changes to focus your development efforts on. I’ll discuss this further next week.
Keep building!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

In this short course made in collaboration with Google, you’ll build real-time voice agents, from simple to multi-agent podcast systems, using Google’s Agent Development Kit. Enroll for free
News

OpenAI Strengthens Ties With AMD
OpenAI, strapped for processing power to drive a worldwide constellation of planned data centers, turned to Nvidia’s archrival AMD.
What’s new: In an unusual deal, OpenAI agreed to purchase what may amount to tens of billions of dollars of AMD Instinct GPUs and received the right to acquire a substantial portion of the chip designer’s shares, essentially for free, if certain conditions are met. The deal, which is to be completed in phases starting next year, covers enough GPUs to draw 6 gigawatts of power (roughly 6 times the city of San Francisco’s peak electricity demand) and up to 10 percent of AMD’s stock. It enables OpenAI to diversify and extend its supply of AI processors to build out a gargantuan size and number of data centers, while AMD secures a top-shelf customer and validates its products as competitors to GPU kingpin Nvidia’s — a huge boost to its credibility and sales in the AI market.
How it works: Completion of the financial deal is contingent on both companies reaching specific milestones that are largely undisclosed. OpenAI must hit deployment targets for AMD chips, and AMD’s stock price must hit certain levels.
- OpenAI plans to use AMD’s forthcoming Instinct MI450 data-center GPUs for inference. It will deploy the first batch (enough to consume 1 gigawatt) in a new facility, separate from data centers announced previously, starting next year. Completion of that purchase will unlock the first portion of AMD stock.
- AMD issued a warrant for OpenAI to buy up to 160 million AMD shares, worth more than $35 billion at the company’s current market capitalization, for $0.01 each. The warrant vests as the share price rises to specific levels on their way up to $600 per share, which is roughly three times the current price. If OpenAI acquires all the shares, it will own 10 percent of AMD, potentially enabling it to influence the company’s strategic direction.
Behind the news: OpenAI’s partnership with AMD is the latest in a series of financial commitments it has made to build data centers that may cost trillions of dollars in coming years. It’s also part of a broader move by big AI companies to secure processing power sufficient to fulfill their ambitions. Amazon, Google, Meta, Microsoft, and OpenAI have announced plans to spend more than $350 billion on data centers this year alone, requiring massive spending and tightening the supply of AI chips.
- Big AI’s plans threaten to outstrip the supply of Nvidia’s most capable GPUs. In a February post on the X social network, OpenAI CEO Sam Altman said OpenAI was “out of GPUs” and ready to acquire hundreds of thousands more. “It’s hard to overstate how difficult it’s become to get them,” he said.
- AMD holds a 5 percent share of the market for AI accelerators as of late last year, according to an estimate by the investment analyst Jefferies. It has been trying to crack Nvidia’s stranglehold on data-center GPUs since 2018, when it launched its Instinct line.
- OpenAI has been cultivating AMD as an alternative or complement to Nvidia for some time. It already uses AMD’s MI355X and MI300X GPUs on a limited basis and contributed to the design of the MI300x, according to Reuters.
- In addition, OpenAI announced a plan, starting in the second half of 2026, to deploy 10 gigawatts’ worth of custom chips designed by Broadcom. The plan follows an earlier $10 billion deal for Broadcom to supply custom chips for AI training that would augment, rather than replace, Nvidia GPUs.
- OpenAI’s data centers also need high-bandwidth memory chips. Earlier this month, it announced a deal with Samsung and SK Hynix, which will scale up their manufacturing capacities to serve Stargate, a data-center partnership between OpenAI, Oracle, and SoftBank.
Why it matters: AI leaders are racing for position in a market that could reach tens of trillions of dollars by some estimates. OpenAI is leading the charge to build data-center capacity. Its deal with AMD, which has been slowly but steadily encroaching on Nvidia’s dominance in GPUs, takes AMD along for what promises to be a wild ride. That said, it also further exposes both companies to financial risks that worry some observers. OpenAI has taken on substantial debt and its current commitments promise much more. As for AMD, it is giving away 10 percent of itself for the promise of future sales that Lisa Su said would amount to $100 billion considering both OpenAI and other customers it would inspire. The structure of the deal limits the risks and ensures that if the market stalls, both companies will suffer together.
We’re thinking: OpenAI’s plans to buy tens of billions of dollars worth of chips for inference supports the notion that demand for AI processing power is shifting from training to inference. Growing usage in general and the rise of agentic workflows in particular suggest that inference is poised for massive expansion, and AMD GPUs, which have relatively large memories, may provide an inference advantage over Nvidia chips in some settings. The more competitive the market for inference, the more likely that the price and speed of token generation will continue to fall — a tremendous boon to AI builders!
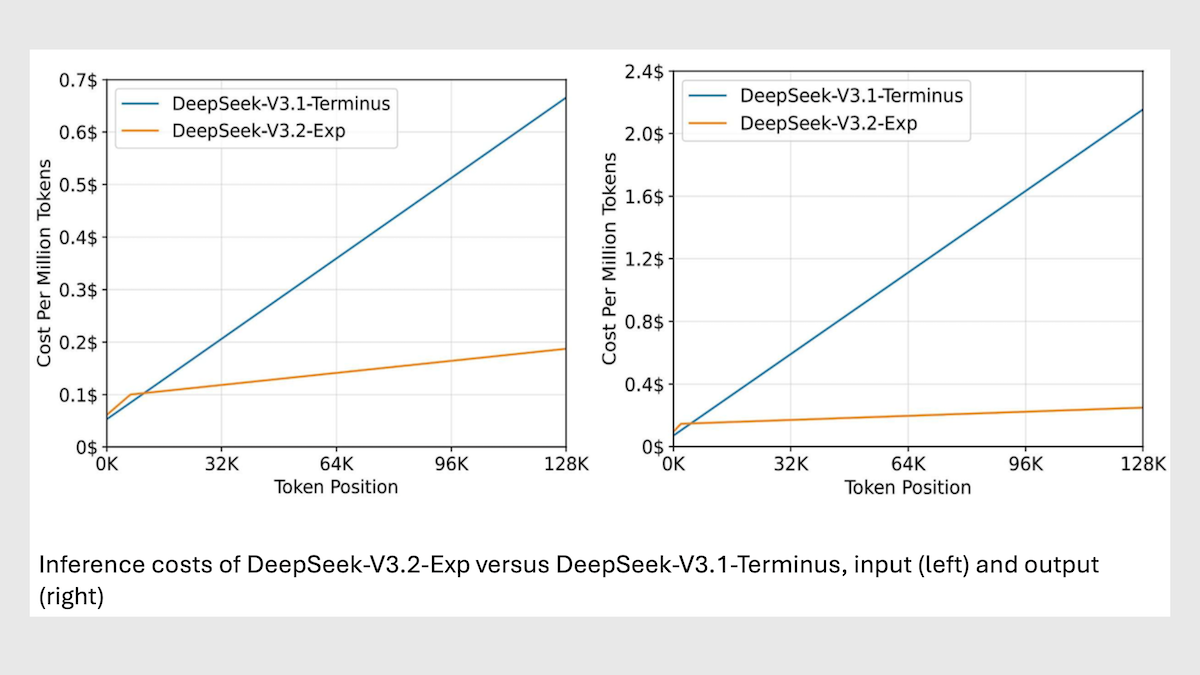
DeepSeek Cuts Inference Costs
DeepSeek’s latest large language model can cut inference costs by more than half and processes long contexts dramatically faster relative to its predecessor.
What’s new: DeepSeek released weights for DeepSeek-V3.2-Exp, a variation on DeepSeek-V3.1-Terminus, which was released in late September. It streamlines processing using a dynamic variation on sparse attention that enables inference speed to scale linearly with input length. The code supports AI chips designed by Huawei, and other Chinese chip designers have adapted it for their products, helping developers in China to use domestic alternatives to U.S.-designed Nvidia GPUs.
- Input/output: Text in (up to 128,000 tokens), text out (up to 8,000 tokens)
- Architecture: Mixture-of-experts transformer, 685 billion total parameters, approximately 37 billion active parameters per token
- Availability: Free via web interface or app, weights available for noncommercial and commercial uses under MIT license, $0.28/$0.028/$0.42 per million input/cached/output tokens via API
- Performance: Comparable to DeepSeek-V3.1-Terminus across many benchmarks, processing inputs over 7,000 tokens 2 to 3 times faster
How it works: The team modified DeepSeek-V3.1-Terminus with a sparse attention mechanism that, rather than attending to the entire input context, selectively processes only the most relevant tokens.
- During training, a “lightning indexer,” a weighted similarity function, learned from 2.1 billion tokens of text to predict which tokens DeepSeek-V3.1-Terminus’ dense attention mechanism would focus on. Then the team fine-tuned all parameters on around 100 billion tokens of text to work with the indexer’s sparse token selections.
- The team further fine-tuned the model by distilling five specialist models (versions of the pretrained DeepSeek-V3.2 base fine-tuned for reasoning, math, coding, agentic coding, and agentic search) into DeepSeek-V3.2-Exp.
- The team applied GRPO to merge reasoning, agentic, and alignment training into a single stage. This approach avoided the catastrophic forgetting problem, in which new learning displaces old, that typically bedevils multi-stage reinforcement learning.
- At inference, the indexer scores the relevance of each past token to the token being generated. It uses simple operations and FP8 precision (8-bit floating point numbers that are relatively imprecise but require less computation to process) to compute these scores quickly.
- Based on these scores, instead of computing attention across all tokens in the current input context, the model selects and computes attention across the top 2,048 highest-scoring tokens, dramatically reducing computational cost.
Results: In DeepSeek’s benchmark tests, DeepSeek-V3.2-Exp achieved substantial gains in efficiency with modest trade-offs in performance relative to its predecessor DeepSeek-V3.1-Terminus.
- DeepSeek-V3.2-Exp cut inference costs for long input contexts by 6 to 7 times compared to DeepSeek-V3.1 Terminus. Processing 32,000 tokens of context, DeepSeek-V3.2-Exp cost around $0.10 per 1 million tokens versus $0.60. Processing 128,000 tokens of context, it cost $0.30 per 1 million tokens compared to $2.30.
- DeepSeek-V3.2-Exp showed gains on tasks that involved coding and agentic behavior as well as some math problems. It surpassed DeepSeek-V3.1-Terminus on Codeforces coding challenges (2121 Elo versus 2046 Elo) and BrowseComp the browser-based agentic tasks (40.1 percent versus 38.5 percent). It also surpassed its predecessor on AIME 2025’s competition high-school math problems (89.3 percent versus 88.4 percent), which are more structured and have clearer solutions than those in HMMT (see below).
- However, its performance showed slight degradation relative to DeepSeek-V3.2-Terminus across several tasks. It trailed its predecessor on GPQA-Diamond’s graduate-level science questions (79.9 percent versus 80.7 percent), HLE’s abstract-thinking challenges (19.8 percent versus 21.7 percent), HMMT 2025’s competitive high-school math problems (83.6 percent versus 86.1 percent), and Aider-Polyglot’s coding tasks (74.5 percent versus 76.1 percent).
Behind the news: DeepSeek-V3.2-Exp is among the first large language models to launch with optimizations for domestic chips rather than adding these as an afterthought. The software has been adapted to run on chips by Huawei, Cambricon, and Hygon, following an order by China’s government to domestic AI companies not to use Nvidia chips. The government’s order followed reports that Chinese AI companies had struggled to use domestic chips rather than Nvidia chips, which are subject to U.S. export restrictions.
Why it matters: Even as prices have fallen, the cost of processing LLM output tokens can make it prohibitively expensive to perform long-context tasks like analyzing large collections of documents, conversing across long periods of time, and refactoring large code repositories. DeepSeek’s implementation of sparse attention goes some distance toward remedying the issue.
We’re thinking: DeepSeek-V3.2-Exp joins Qwen3-Next in experimenting with self-attention alternatives to improve the efficiency of large transformers. While Qwen3-Next combines Gated DeltaNet layers with gated attention layers, DeepSeek-V3.2-Exp uses dynamic sparse attention, suggesting that there’s still more efficiency to be gained by tweaking the transformer architecture.

Fine-Tuning Simplified
The first offering from Thinking Machines Lab, the startup founded by former OpenAI CTO Mira Murati, aims to simplify — and democratize — the process of fine-tuning AI models.
What’s new: Tinker is an API that streamlines working with multiple GPUs to fine-tune large language models. Users control their algorithms while code behind the scenes handles scheduling, resource allocation, and recovery in case a GPU crashes. You can join a waitlist for free access, but the company plans to start charging in coming weeks. Tinker currently offers a selection of pretrained Qwen3 and Llama 3 models with other open-weights options to come.
How it works: The API lets you work as though you were fine-tuning on a single device. You can select a model and write a fine-tuning script that loads your data and specifies a predefined loss function for supervised or reinforcement learning, or you can write your own. Tinker’s software determines, for instance, how to split the model and data among computing clusters.
During fine-tuning, the system builds and trains a LoRA adapter (two small matrices that modify a pretrained model’s weights at inference) for the task at hand.
- Using LoRA also enables the system to share a single pool of compute among multiple fine-tuning runs, which reduces costs.
- A Tinker Cookbook offers implementations of fine-tuning methods.
Behind the news: Several companies can fine-tune models on your data but don’t give you control over the training loop, similar to the way OpenAI fine-tunes its models on customer data. Libraries like DeepSpeed offer control over fine-tuning while simplifying parallelization across multi-GPU infrastructure, but they require you to manually request GPUs from cloud services (if you don’t have your own) and manage configuration files, which can be complicated.
Why it matters: Fine-tuning using multiple GPUs often requires dedicating time to figure out how to allocate resources, debug tricky APIs, and so on. Tinker saves that time, enabling model builders to spend it more productively. Academic researchers, startups, and mid-size companies that want to level up their investment in AI research and/or development are most likely to find it helpful.
We’re thinking: Tinker’s use of LoRA divides the cost of training base models among multiple fine-tuning runs, and potentially among users. This could enable users to experiment more within the a fixed budget.
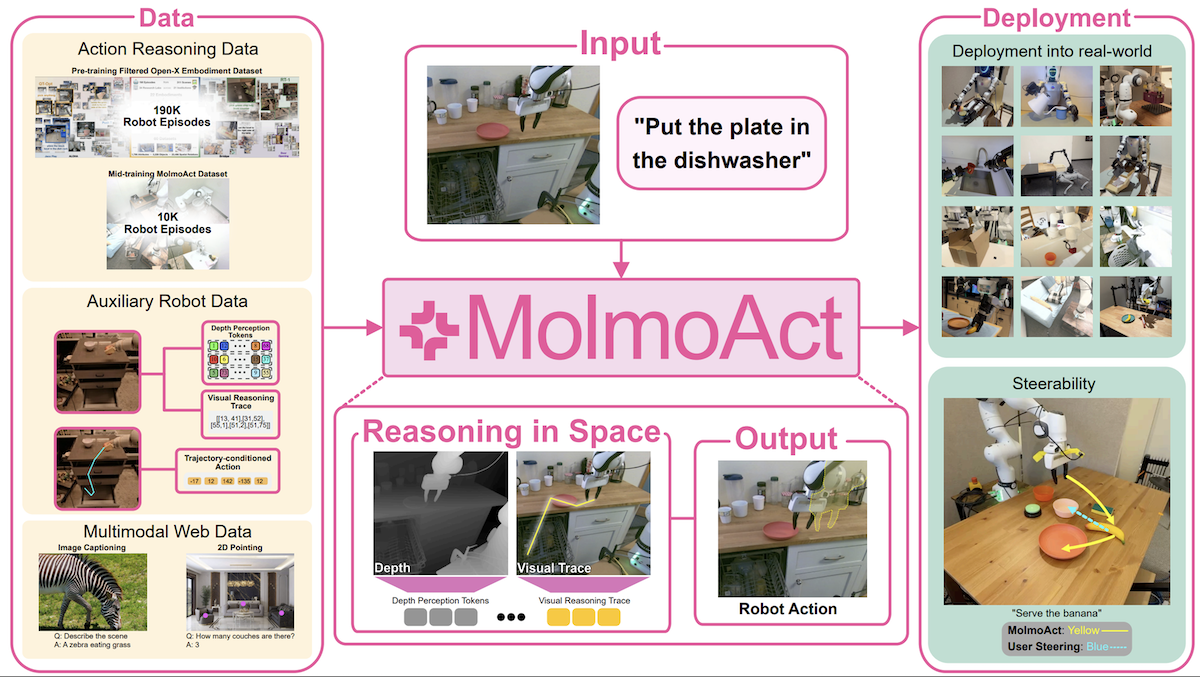
Better Spatial Perception for Robots
Robot control systems that accept only text input struggle to translate words into motions in space. Researchers developed a system that enables robots to plan spatial paths before they execute text instructions.
What’s new: Jason Lee and colleagues at Allen Institute for AI and University of Washington introduced MolmoAct, a robotics action system that improved a 3-jointed robot arm’s ability to manipulate objects and perform multi-step tasks by first estimating spatial depth and planning motion paths. The weights and code are available for noncommercial and commercial uses under the Apache 2 license, while the authors’ fine-tuning dataset is available under CC BY 4.0.
Key insight: Natural-language instructions don’t translate precisely into spatial directions. Just as humans can navigate more effectively with a map, robots perform more accurately given a sense of 3D space (a depth map) and the desired trajectory (a motion path drawn over a camera’s view). Along with a command like “take the cup off the table and put it in the trash,” the additional information enables a robot to avoid collisions with objects and move more precisely.
How it works: MolmoAct uses a SigLIP2 pretrained vision transformer to encode camera images into tokens. Given the image tokens and text instructions, a pretrained Qwen2.5-7B large language model learned to generate tokens that represented (i) a depth map, (ii) a motion path, and (ii) changes in joint positions.
- The authors started with 24.3 million robot demonstrations of tasks such as “pick up the water bottle from the drawer and put it on the desk.” Each example included a text instruction, camera views, and changes in joint positions. The authors augmented the examples with depth maps and motion paths.They generated the depth maps using a pretrained Depth Anything 2, and they produced visual paths by tracking the robot arm’s gripper in the camera images using Molmo, a pretrained vision-language model.
- They trained Qwen2.5-7B on the augmented dataset. Given a text instruction and camera image, the model learned to generate tokens that represented, in this order, (i) a depth map, (ii) a visual path, and (iii) changes in joint positions.
- To improve the system’s vision-language understanding, they further pretrained both models on 2 million examples of images and text scraped from the web.
- The authors fine-tuned the models to generate the next token in more than 2 million examples, which they collected themselves, of robots performing various tasks from start to finish. The examples included various combinations of text instructions, camera views, changes in joint positions, depth maps, and motion paths.
- At inference, users can see the next motion path before the robot moves and revise it by redrawing it via a tablet. This capability makes the robot’s actions interpretable and enables users to address potential errors before they happen.
Results: The authors tested MolmoAct’s performance using one or two Franka robotic arms in a simulation as well as 15 real-world tasks, including opening a container, putting trash in a bin, and folding a towel. On average, the system outperformed all other competitors.
- MolmoAct achieved 86.6 percent average success on diverse simulated challenges in LIBERO. The closest competitor, π0-FAST, achieved 85.5 percent average success.
- In real-world tasks, MolmoAct achieved 0.679 average task progress (a 0-to-1 score that represents how much of each task the robot completed, higher is better), while π0-FAST achieved 0.446 average task progress.
Why it matters: Earlier robotic control systems that use LLMs to interpret text instructions map visual input and text instructions directly to low-level actions without explicitly representing 3D space or visual motion paths. MolmoAct's approach makes such systems more precise, adaptable, and explainable.
We’re thinking: This robot system is definitely not lost in space!
A MESSAGE FROM DEEPLEARNING.AI

In Agentic AI, Andrew Ng teaches you to design multi-step, autonomous workflows in raw Python, covering four design patterns: reflection, tool use, planning, and multi-agent collaboration. Available exclusively at DeepLearning.AI. Enroll now!