
Dear friends,
AI’s ability to make tasks not just cheaper, but also faster, is underrated in its importance in creating business value.
For the task of writing code, AI is a game-changer. It takes so much less effort — and is so much cheaper — to write software with AI assistance than without. But beyond reducing the cost of writing software, AI is shortening the time from idea to working prototype, and the ability to test ideas faster is changing how teams explore and invent. When you can test 20 ideas per month, it dramatically changes what you can do compared to testing 1 idea per month. This is a benefit that comes from AI-enabled speed rather than AI-enabled cost reduction.
That AI-enabled automation can reduce costs is well understood. For example, providing automated customer service is cheaper than operating human-staffed call centers. Many businesses are more willing to invest in growth than just in cost savings; and, when a task becomes cheaper, some businesses will do a lot more of it, thus creating growth. But another recipe for growth is underrated: Making certain tasks much faster (whether or not they also become cheaper) can create significant new value.

I see this pattern across more and more businesses. Consider the following scenarios:
- If a lender can approve loans in minutes using AI, rather than days waiting for a human to review them, this creates more borrowing opportunities (and also lets the lender deploy its capital faster). Even if human-in-the-loop review is needed, using AI to get the most important information to the reviewer might speed things up. The ability to provide loans quickly opens up the market to new customers in need of rapid funds and helps customers who need a quick positive or negative decision to accept the loan or move on.
- If an academic institution gives homework feedback to students in minutes (via sophisticated autograding) rather than days (via human grading), not only is the automation cheaper, the rapid feedback facilitates better learning.
- If an online seller can approve purchases faster, this can lead to more sales. For example, many platforms that accept online ad purchases have an approval process that can take hours or days; if approvals can be done faster, they can earn revenue faster. Further, for customers buying ads, being able to post an ad in minutes lets them test ideas faster and also makes the ad product more valuable.
- If a company’s sales department can prioritize leads and respond to prospective customers in minutes or hours rather than days — closer to when the customers’ buying intent first led them to contact the company — sales representatives might close more deals. Likewise, a business that can respond more quickly to requests for proposals may win more deals.
I’ve written previously about looking at the tasks a company does to explore where AI can help. Many teams already do this with an eye toward making tasks cheaper, either to save costs or to do those tasks many more times. If you’re doing this exercise, consider also whether AI can significantly speed up certain tasks. One place to examine is the sequence of tasks on the path to earning revenue. If some of the steps can be sped up, perhaps this can help revenue growth.
Growth is more interesting to most businesses than cost savings, and if there are loops in your business that, when sped up, would drive growth, AI might be a tool to unlock this growth.
Keep building!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

In Course 4 of the Data Analytics Professional Certificate you’ll work with truly real-world data: messy, inconsistent, and often unstructured. You’ll extract data from websites, APIs, and databases, and clean it using Python and SQL. By the end, you’ll be able to make raw datasets analysis-ready, with speed and accuracy. Enroll today!
News
Reasoning Models With Recipes
Microsoft published its latest recipe for training reasoning models, substantially expanding what is still a fairly small base of public knowledge.
What’s new: Microsoft released Phi-4-reasoning, Phi-4-reasoning-plus, and Phi-4-mini-reasoning along with lessons learned in building the models.
- Input/output: text in (Phi-4-reasoning up to 32,000 tokens, Phi–4-reasoning-plus up to 32,000 tokens, Phi-4-mini-reasoning up to 128,000 tokens), text out
- Architecture: Transformer (Phi-4-reasoning 14 billion parameters, Phi-4-reasoning-plus 14 billion parameters, Phi-4-mini-reasoning: 3.8 billion parameters)
- Features: Reasoning
- Performance: Phi-4-reasoning-plus and Phi-4-mini-reasoning perform well on math problems
- Availability: Weights free to download for noncommercial and commercial uses under an MIT license
How it works: All three models are fine-tuned versions of pretrained models.
- Phi-4-reasoning: The authors fine-tuned Phi-4 to match curated outputs from OpenAI o3-mini on Q&A, math, science, and coding examples.
- Phi-4-reasoning-plus: They further fine-tuned Phi-4-reasoning via reinforcement learning to correctly answer math problems.
- Phi-4-mini-reasoning: They fine-tuned Phi-4-mini in stages to reason over math problems. Stages included (i) supervised fine-tuning to match correct output from DeepSeek-R1, (ii) direct preference optimization to train the model to prefer correct responses over incorrect ones from DeepSeek-R1, and (iii) reinforcement learning to further reward correct solutions to math problems.
Smaller model lessons learned: During reinforcement learning, Phi-4-mini-reasoning exhibited instability, such as output batches that varied greatly in length or received mostly negative rewards, apparently depending on the training data or output. The authors suspect that the model’s small size caused these issues. Among the lessons learned:
- Supervised fine-tuning on existing reasoning datasets like S1K can decrease performance. This phenomenon suggests a need either for larger, high-quality, supervised fine-tuning datasets or for fine-tuning via both supervised learning and reinforcement learning.
- To minimize discrepancies in output length, the authors tested multiple prompts and chose those that resulted in the most uniform output lengths.
- To address the output batches that received mostly negative rewards, they sampled lots of responses, retained those that received a positive reward, sampled an equal number of those that received a negative reward, and discarded the rest before adjusting the model’s weights.
Larger model lessons learned: Phi-4-reasoning and Phi-4-reasoning-plus didn’t present the same issues. However, the authors did make significant choices during reinforcement learning:
- The authors fine-tuned Phi-4-reasoning on both math and code data, but during reinforcement learning, they fine-tuned it only on math data to simplify the training process. The authors attribute the model’s relatively lackluster performance on code benchmarks to this choice.
- They crafted the reward function to give lower rewards for correct responses longer than 25,600 tokens than for shorter responses. This encouraged the model to finish thinking within the input length. Furthermore, the reward function gave a greater punishment for incorrect responses with fewer than 3,702 tokens compared to longer responses. This encouraged the model to produce more reasoning tokens when solving hard problems.
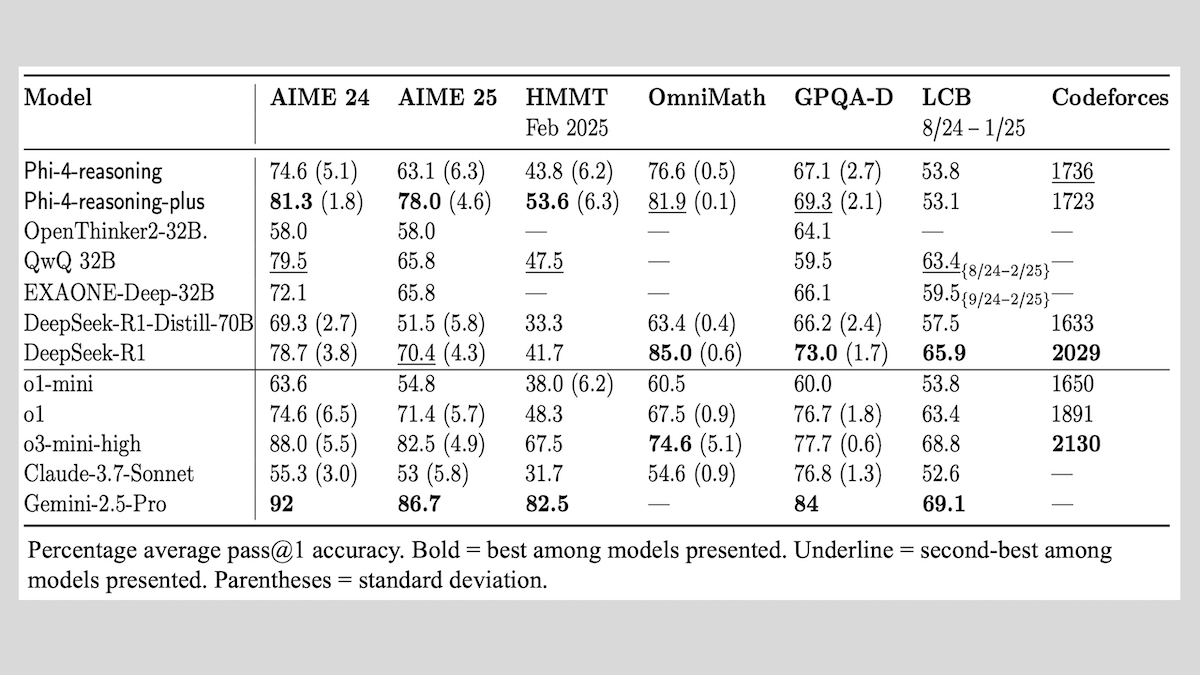
Results: Overall, Phi-4-reasoning-plus and Phi-4-mini-reasoning outperform similarly sized (and larger) open-weights models on math problems. Phi-4-reasoning generally outperformed DeepSeek-R1-Distilled-70B but underperformed Alibaba QwQ 32B. All three models deliver performance that falls in the middle among proprietary models and, in domains outside math, larger models with open weights.
- On math problems in AIME 2024, Phi-4-reasoning-plus (81.3 percent accuracy) outperformed the next-best open-weights model, QwQ 32B (79.5 percent accuracy). In comparison, Phi-4-reasoning (74.6 percent accuracy) underperformed the proprietary Gemini 2.5 Pro (92 percent accuracy).
- On AIME 2024, Phi-4-mini-reasoning (57.5 percent accuracy) outperformed the next-best open-weights model of similar size, DeepSeek-R1-Distill-Qwen-7B (53.3 percent accuracy). In comparison, o1-mini achieved 63.6 percent accuracy.
Why it matters: While reasoning models can outperform their non-reasoning counterparts, the best ways to train them aren’t widely known. Sharing recipes and lessons learned enables others to further iterate and improve the recipes, ultimately increasing model performance even more.
Open, Compact Code Generator
An open-source code generator performs comparably to the reasoning models DeepSeek-R1 and OpenAI o1 with a much smaller model.
What’s new: A team at the model platform Together.AI and Agentica, an open-source project devoted to reinforcement learning (RL), released DeepCoder-14B-Preview. The release includes weights, code, dataset, training logs, and data optimizations under an MIT license that allows noncommercial and commercial uses.
How it works: The team fine-tuned DeepSeek-R1-Distilled-Qwen-14B, which distills knowledge from DeepSeek-R1 (671 billion parameters) into Qwen-14B (14 billion parameters).
- The authors curated 24,000 coding problems from TACO Verified, SYNTHETIC-1, and LiveCodeBench). They removed duplicates, problems with less than five unit tests, problems whose solutions failed to pass all associated unit tests, and those that appeared in both test and training sets.
- They fine-tuned DeepSeek-R1-Distilled-Qwen-14B using a streamlined reinforcement learning approach that enhancedGroup Relative Policy Optimization (GPRO) with training optimizations from Decoupled Clip and Dynamic Sampling Policy Optimization (DAPO). Among other optimizations, they (i) removed the KL loss (typically used to keep the new model’s outputs from straying too far from the base model’s outputs), which eliminated the need to compute the base model’s output at each training step, and (ii) ignored the loss for outputs that exceeded the output size limit (16,000 tokens for the first training phase, 32,000 tokens for the second), which kept the model from being penalized for generating programs that didn’t work properly because they had been truncated.
- The authors updated the reinforcement learning library verl to improve the way the model parallelized sampling, computing the reward, and training. Instead of alternating between sampling new outputs, computing rewards, and training (as verl does), they sampled new outputs while training on the previous batch. (They computed the reward immediately after sampling a new output.) For coding problems, this cut total training time in half.
- To prevent the model from developing behaviors based on flaws in the reward model, the reward model dispensed rewards only when DeepCoder-14B-Preview’s output passed all 15 of a problem's most challenging unit tests (judged by input length) within 6 to 12 seconds. Otherwise, the model received no reward.
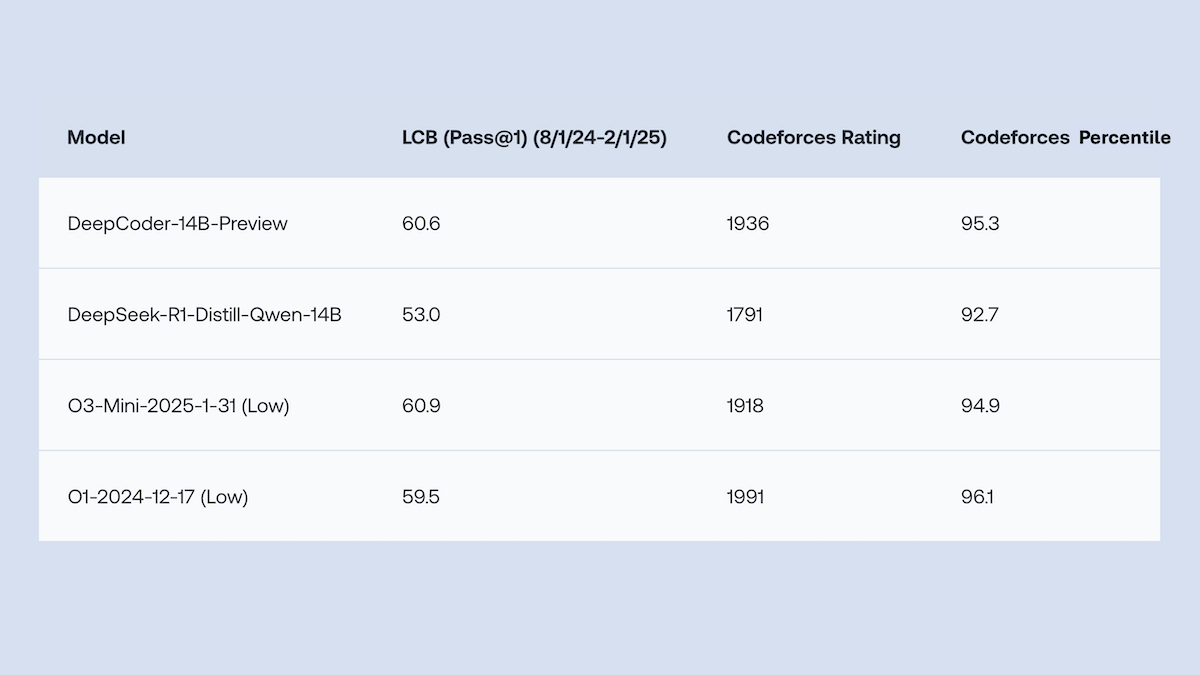
Results: DeepCoder-14B-Preview is competitive on several coding benchmarks with DeepSeek-R1 as well as proprietary models including OpenAI o3-mini and OpenAI o1, which is believed to be much larger.
- On LiveCodeBench (regularly updated coding problems), DeepCoder-14B-Preview (60.6 percent Pass@1 accuracy) was just shy of o3-mini-2025-1-31 set to low effort (60.9 percent) and slightly ahead of o1-2024-12-17 set to low effort (59.5 percent).
- On Codeforces (competitive coding problems), DeepCoder-14B-Preview (1936 CodeElo, higher is better) performed significantly better than DeepSeek-R1-Distill-Qwen-14B (1791 CodeElo). It performed comparably to o3-mini-2025-1-31 set to low effort (1918 CodeElo), o1-2024-12-17 set to low effort (1991 CodeElo), and Deepseek-R1 (1948 CodeElo).
Why it matters: Applying reinforcement learning to coding works, but it has two big issues: (i) Training examples of verifiable code are relatively scarce and (ii) computing reward signals for code is time-consuming, since it requires evaluating many test cases. DeepCoder-14B-Preview’s optimizations reduced this complexity, shrinking RL training from months to weeks. Those optimizations are built into Verl-pipeline, an open source RL library from Together.AI and Agentica, giving developers a powerful tool for model training.
We’re thinking: Kudos to the DeepCoder team for open sourcing their reasoning recipe! A handful of companies have developed the know-how to execute RL well, but many teams still have trouble implementing successfully. Open recipes for RL training methods and data curation techniques are important to move the field forward.
EU Loosens AI Regulations
The European Union made an abrupt U-turn away from its stringent AI regulations. Meta promptly adjusted to the loosening restrictions.
What’s new: Henna Virkkunen, the EU’s head of digital policy, said the organization would ease rules and requirements to support Europe’s competitiveness in AI.
How it works: Adopted last year, the EU’s AI Act provides a comprehensive framework for regulating AI that aims to reduce purported risks by banning certain applications, restricting others, and requiring extensive documentation of development efforts. The law is set to take effect in August, empowering various regulatory bodies to formulate detailed rules. However, in recent months, the EU has faced increasing pressure from the U.S. government and large AI companies to reduce the regulatory burden.
- Virkkunen announced the EU would withdraw a provision that allowed citizens to sue AI companies for damages caused by their systems and required extensive reporting and disclosure.
- She advocated adjusting the regulations to make the EU more competitive and independent. “When we want to boost investments in AI, we have to make sure that we have an environment that is faster and simpler than the European Union is right now,” he said.
- Critics accused regulators of defanging the AI Act to appease U.S. AI companies and the Trump administration, which has argued that the AI Act is an excessive barrier to innovation. Virkkunen denied bowing to U.S. pressure.
- Meta responded to the shifting regulatory environment by resuming training its models on European data. Last year, the company stopped releasing multimodal models in Europe after EU regulators warned that training models on data from European users of Facebook, Instagram, and other Meta properties potentially violated privacy laws.
Behind the news: In drafting the AI Act, the EU aspired to a comprehensive, specific set of regulations. However, not all European lawmakers agreed that rules were needed. Virkkunen’s supporters noted that existing laws already allowed consumers to file claims against AI companies. Meanwhile, some policymakers have become less worried about AI than they were during the early drafting of the AI Act.
Why it matters: It’s unlikely that all nations – or even states within nations – will ever agree fully on rules and regulations that govern AI companies that do business within their borders, or protections from flaws such as model bias. But AI companies including Meta, OpenAI, and others argue that a more uniform regulatory environment will make it easier to serve users worldwide.
We’re thinking: The EU overreached with the AI Act. Fortunately, the legislation provides enough flexibility to pull back. Clearer rules will help European teams innovate and European and international companies better serve EU citizens.
Memory Layers for More-Factual Output
Improving a large language model’s factual accuracy typically requires making it bigger, which in turn, involves more computation. Researchers devised an architecture that enables models to recall relevant details without significantly increasing the amount of computation required.
What’s new: Vincent-Pierre Berges, Barlas Oğuz, and colleagues at Meta augmented transformers with trainable memory layers that efficiently store and retrieve information related to a prompt. The training code is available under a CC BY-NC license, which permits noncommercial uses.
Memory layer basics: Memory layers were introduced in 2015 and were applied to transformers a few years later. They compute vectors, which may capture details like names or dates that were learned through training, and retrieve them according to a given input. Computing the output of a memory layer is similar to computing that of a self-attention layer. Both describe vectors that represent queries, keys, and values, and both compute the similarity between queries and keys and then weight the values by that similarity. However, while a self-attention layer computes queries, keys, and values from linear transformations of the input, a memory layer (which computes queries the same way) learns keys and a corresponding value for each key through training.
Key insight: Memory layers can be scaled to millions of keys, but computing the similarity between a query and so many keys is computationally expensive. One solution is to represent each key as a combination of two half-keys drawn from two much smaller sets. For example, two sets of 1,000 half-keys each can represent 1 million possible keys. Comparing a query to these smaller sets is much more efficient, making it practical to scale up memory layers dramatically.
How it works: The authors pretrained Llama-style models of several sizes (from 134 million to 8 billion parameters) on data similar to Llama 2’s and Llama 3’s pretraining datasets. They replaced the fully connected layers with memory layers in three transformer blocks. These layers shared parameters and held up to 16 million values (an extra 64 billion parameters total). The memory layers performed these steps:
- Given a query (a prompt that has been embedded by preceding transformer layers), split it into two vectors half the size.
- Compute similarity scores between each half-query to and each half-key drawn from two sets of half keys. Identify the k highest-scoring half-keys.
- Concatenate the highest-scoring half keys to produce k2 full keys.
- Sum the similarity scores of the two half keys that make up each full key. Choose the k highest-scoring full keys.
- Compute the index of each full key based on the indices of the corresponding half-keys.
- Retrieve the values that correspond to the full keys.
- Output the summed values weighted by the similarity scores.
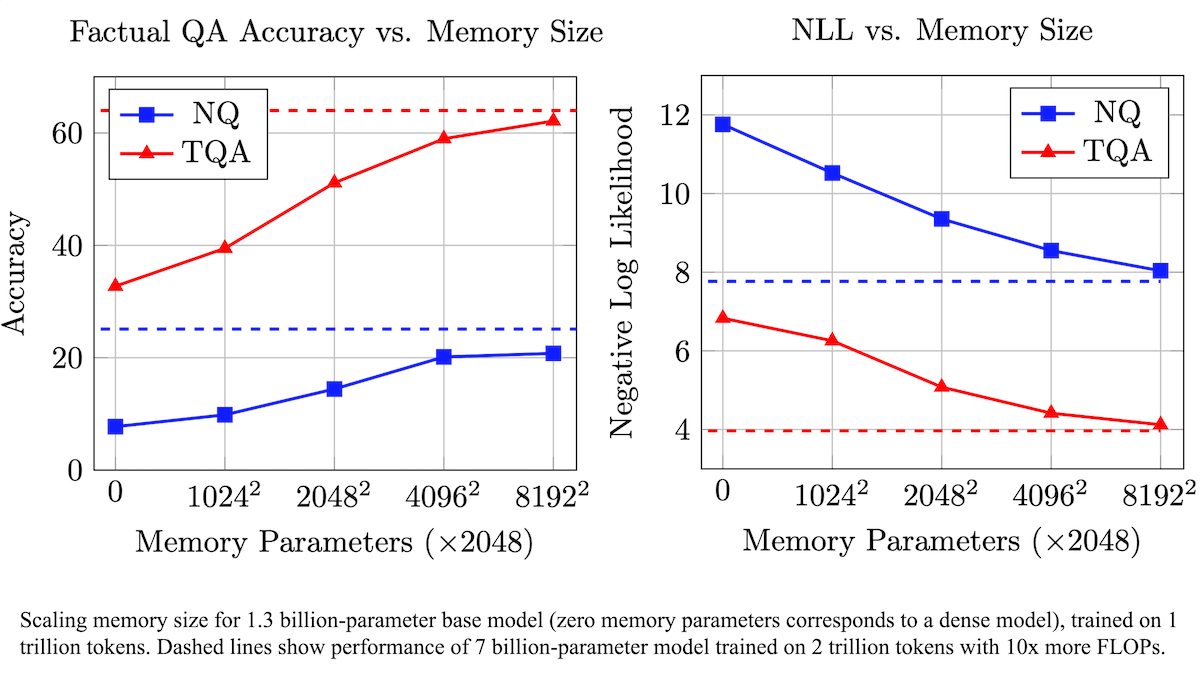
Results: The authors compared a model (8 billion parameters) with memory layers to a similar model without memory layers, both trained on 1 trillion tokens.
- They used nine question-answering datasets for evaluation. The model with memory layers achieved higher performance on seven of them. For example, on MMLU, the memory model achieved 63.04 percent accuracy, while the unmodified transformer achieved 59.68 percent accuracy.
- In general, the memory model performed worse than Llama 3.1 8B trained on 15 trillion tokens. For example, Llama 3.1 8B achieved 66 percent accuracy on MMLU.
Why it matters: Memory layers didn’t catch on in the early days of large language models (LLMs), but they can improve the output of today’s much bigger models. LLMs outfitted with memory layers require less data and computation for pretraining than conventional models to achieve the same result, at least with respect to answering factual questions.
We’re thinking: While retrieval-augmented generation can help LLMs deliver more-factual output by retrieving facts from a database, the authors add trainable parameters for this purpose.
A MESSAGE FROM DEEPLEARNING.AI

Build AI applications that access tools, data, and prompt templates using Model Context Protocol (MCP), an open standard developed by Anthropic. In “MCP: Build Rich-Context AI Apps with Anthropic,” you’ll build and deploy an MCP server, make an MCP-compatible chatbot, and connect applications to multiple third-party servers. Sign up now