
Dear friends,
When I wrote recently about how to build a career in AI, several readers wrote to ask specifically about AI product management: the art and science of designing compelling AI products. I’ll share lessons I’ve learned about this here and in future letters.
A key concept in building AI products is iteration. As I’ve explained in past letters, developing a machine learning system is a highly iterative process. First you build something, then run experiments to see how it performs, then analyze the results, which enables you to build a better version based on what you’ve learned. You may go through this loop several times in various phases of development — collecting data, training a model, deploying the system — before you have a finished product.
Why is development of machine learning systems so iterative? Because (i) when starting on a project, you almost never know what strange and wonderful things you’ll find in the data, and discoveries along the way will help you to make better decisions on how to improve the model; and (ii) it’s relatively quick and inexpensive to try out different models.
Not all projects are iterative. For example, if you’re preparing a medical drug for approval by the U.S. government — an expensive process that can cost tens of millions of dollars and take years — you’d usually want to get the drug formulation and experimental design right the first time, since repeating the process to correct a mistake would be costly in time and money. Or if you’re building a space telescope (such as the wonderful Webb Space Telescope) that’s intended to operate far from Earth with little hope of repair if something goes wrong, you’d think through every detail carefully before you hit the launch button on your rocket.
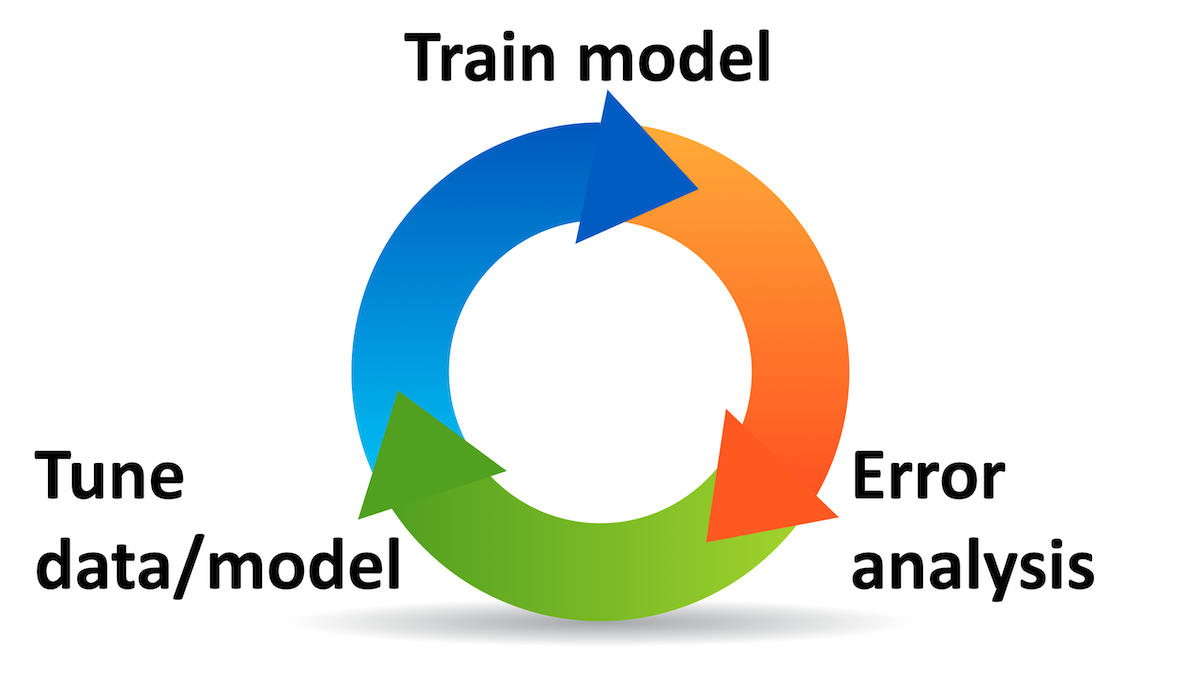
Iterating on projects tends to be beneficial when (i) you face uncertainty or risk, and building or launching something can provide valuable feedback that helps you reduce the uncertainty or risk, and (ii) the cost of each attempt is modest.
This is why The Lean Startup, a book that has significantly influenced my thinking, advocates building a minimum viable product (MVP) and launching it quickly. Developing software products often involves uncertainty about how users will react, which creates risk for the success of the product. Making a quick-and-dirty, low-cost implementation helps you to get valuable user feedback before you’ve invested too much in building features that users don’t want. An MVP lets you resolve questions about what users want quickly and inexpensively, so you can make decisions and investments with greater confidence.
When building AI products, I often see two major sources of uncertainty, which in turn creates risk:
- Users. The considerations here are similar to those that apply to building software products. Will they like it? Are the features you’re prioritizing the ones they’ll find most valuable? Is the user interface confusing?
- Data. Does your dataset have enough examples of each class? Which classes are hardest to detect? What is human-level performance on the task, and what level of AI performance is reasonable to expect?
A quick MVP or proof of concept, built at low cost, helps to reduce uncertainty about users and/or data. This enables you to uncover and address hidden issues that may hinder your success.
Many product managers are used to thinking through user uncertainty and using iteration to manage risk in that dimension. AI product managers should also consider the data uncertainty and decide on the appropriate pace and nature of iteration to enable the development team to learn the needed lessons about the data and, given the data, what level of AI functionality and performance is possible.
Keep learning!
Andrew
News

Text to Video Without Text-Video Data
Text-to-image generators like DALL·E 2, Midjourney, and Stable Diffusion are winning art contests and worrying artists. A new approach brings the magic of text-to-image generation to video.
What's new: Make-A-Video, a system built by Uriel Singer and colleagues at Meta, turns text prompts into high-resolution videos without training on text-video pairs. You can see its output here.
Key insight: While billions of text-image pairs are available to train a text-to-image generator, text-video pairs are too scarce to train a video equivalent. A model can learn relationships between words and pictures via pretraining on text-image pairs. Then it can be adapted for video by adding further layers that process image patches across frames and — while keeping the pretrained layers fixed — fine-tuning the new layers on videos, which are plentiful. In this way, a system can generate videos using knowledge it learned from text-image pairs.
How it works: The authors pretrained a series of models (one transformer and four U-Net diffusion models) to generate images from text, generate in-between video frames, and boost image resolution. To pretrain the text-to-image models, they used 2.3 billion text-image pairs. After pretraining, they modified some of the models to process sequences of video frames: On top of each pretrained convolutional layer, the authors stacked a 1D convolutional layer that processed a grid of pixels in each frame; and on top of each pretrained attention layer, they stacked a 1D attention layer that, likewise, processed a grid of pixels in each frame. To fine-tune or train the modified models on video, they used 20 million internet videos.
- Given a piece of text, the pretrained transformer converted it into an embedding.
- The authors pretrained a diffusion model to take the embeddings and generate a 64x64 image. Then they modified the model as described above and fine-tuned it to generate sequences of 16 frames of 64x64 resolution.
- They added a second diffusion model. Given a 76-frame video made up of 16 frames, each followed by four masked (blacked-out) frames, it learned to regenerate the masked frames.
- They added a third diffusion model and pretrained it, given a 64x64 image, to increase the image’s resolution to 256x256. After modifying the model, they fine-tuned it to increase the resolution 76 successive frames to 256x256.
- Given a 256x256 image, a fourth diffusion model learned to increase its resolution to 768x768. Due to memory restrictions, this model was not modified for video or further trained on videos. At inference, given the 76-frame video, it increased the resolution of each frame without reference to other frames.
Results: The authors compared their system’s output to that of the previous state of the art, CogVideo, which takes a similar approach but requires training on text-video pairs. Crowdworkers supplied 300 prompts and judged the output of the author’s system to be of higher quality 77.15 percent of the time and to better fit the text 71.19 percent of the time.
Why it matters: Text-to-image generators already transform text into high-quality images, so there’s no need to train a video generator to do the same thing. The authors’ approach enabled their system to learn about things in the world from text-image pairs, and then to learn how those things move from unlabeled videos.
We're thinking: The Ng family’s penchant for drawing pandas is about to undergo another revolution!
Tough Economy Hits AI Startups
Venture investors are tapping the brakes on AI amid rising economic uncertainty.
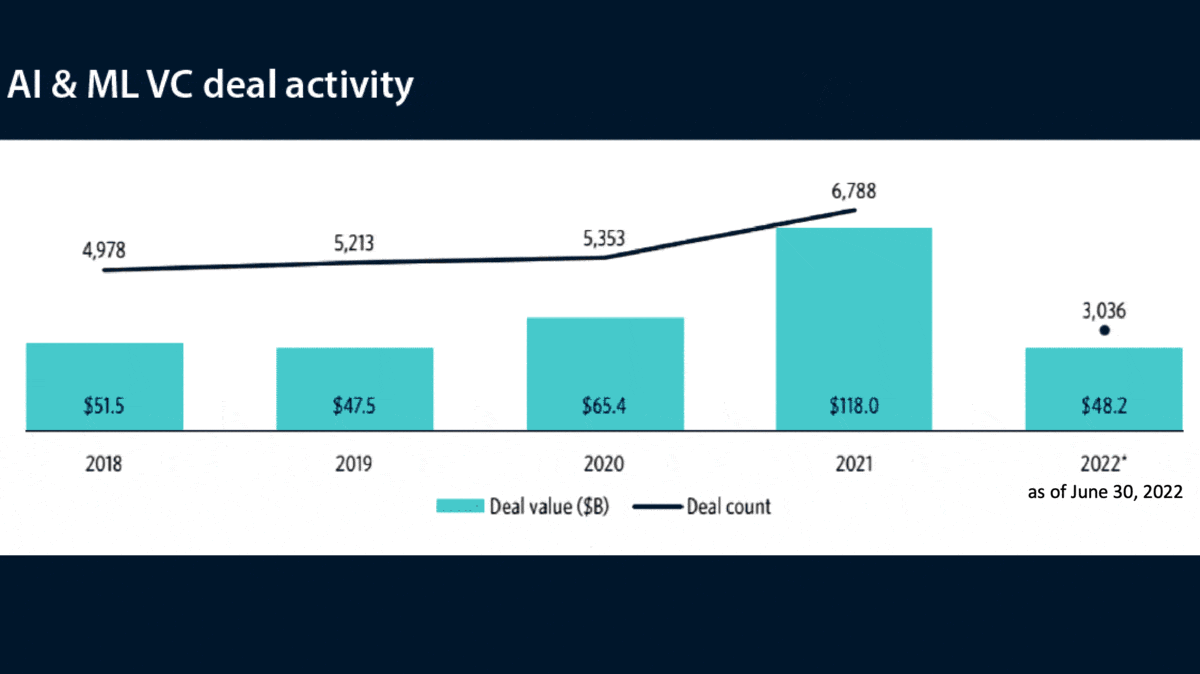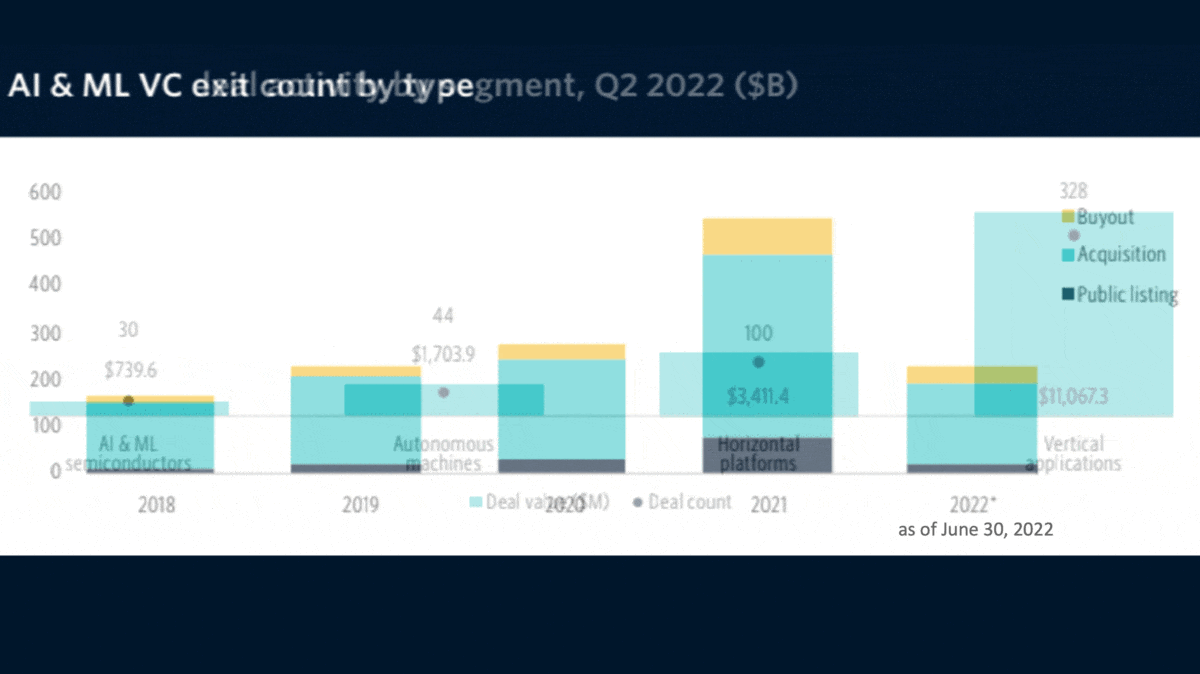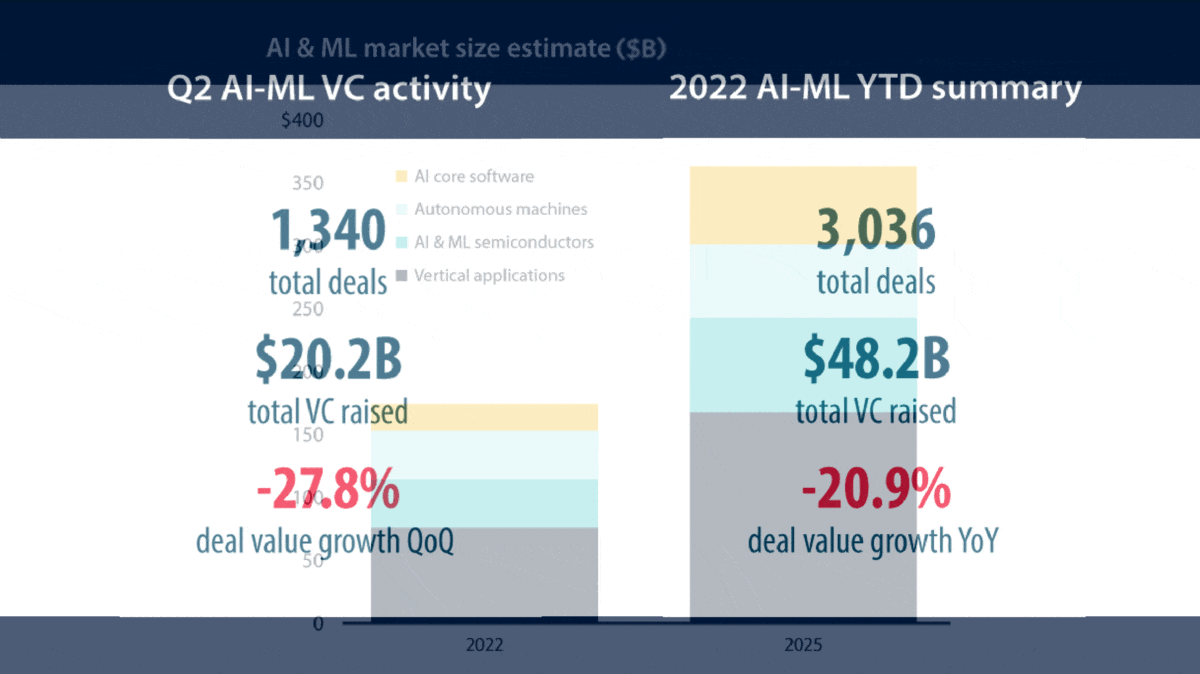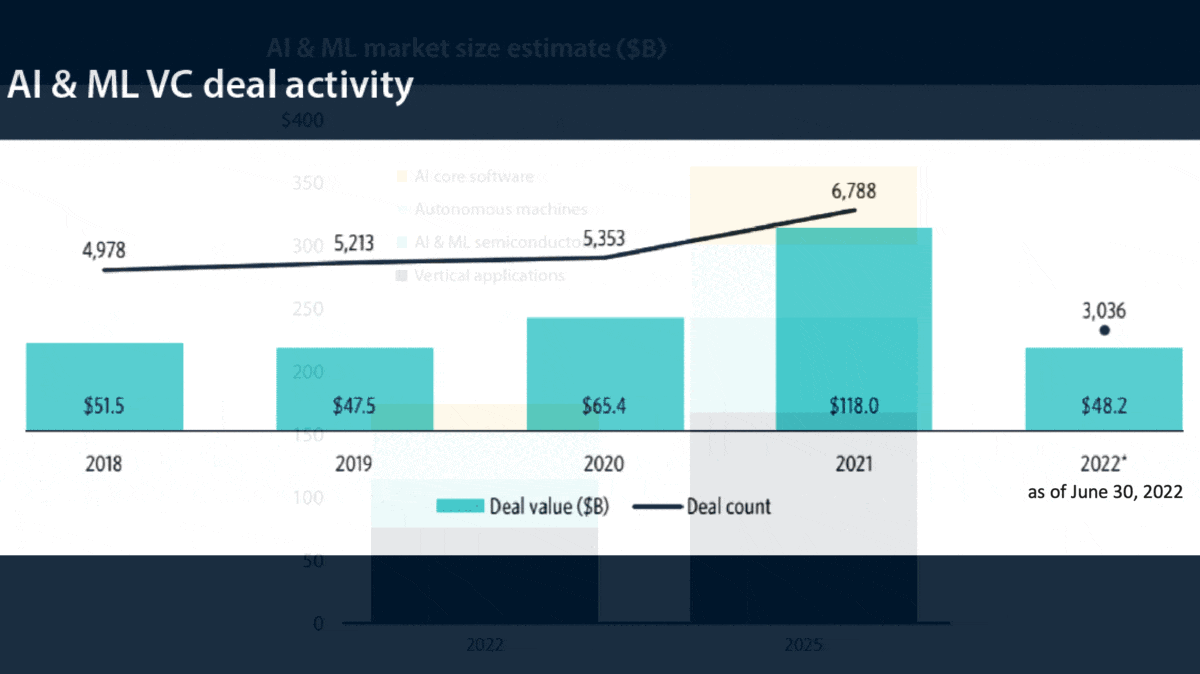
What’s new: In their latest Artificial Intelligence & Machine Learning Report, market research firm PitchBook documents a sharp reduction in investment in AI startups in the first half of 2022, a time of rising inflation and interest rates.
What it says: The report delivers bad news and highlights categories that have continued to hold venture investors’ interest — and those that haven’t.
- Funding for AI startups during the first two quarters of 2022 dropped 20.9 percent from the same period last year. It fell 27.8 percent from the first quarter — faster than information technology as a whole, which fell 21.6 percent. On the bright side, funding for the year ($48.2 billion in the first half) is on pace to beat the total for 2020 ($65.3 billion).
- Exits in the first half of the year totaled $27 billion. 2021 saw $144.2 billion in the same period and $200 billion for the full year.
- Over half of venture investment in AI in the second quarter — $11 billion out of the $20.2 billion total — went to applications such as drug discovery, security, and sales and marketing.
- Startups that specialize in cloud-based AI were hit hardest. That category’s funding is on pace to tumble 87.7 percent in 2022 relative to 2021.
Future forecasts: Despite the grim numbers, the authors reject characterizing the current period as an AI winter. They expect investments to rebound from around $175 billion in 2022 to over $350 billion in 2025, driven primarily by advances in multimodal AI, general-purpose models, and synthetic data.
Behind the news: In a separate analysis, CB Insights determined that AI funding would fall by 21 percent each quarter in 2022. Similarly, it found that the losses were not uniform: AI startups in healthcare, financial technology, and retail — areas that have a solid track record — have maintained their funding levels better than other, more speculative fields.
Why it matters: When credit is harder to obtain, investors tend to back away from riskier investments. Given rising interest rates, inflation, and the threat of recession, that explains the falloff in funding for startups without proven market value. Companies that focus on proven applications and markets should continue to prosper, although competition is bound to stiffen as vendors are pressed to demonstrate that their offering is superior.
We’re thinking: As we noted in previous issues of The Batch, rising interest rates and falling stock indices signal that AI developers should be ready for increased pressure to develop projects that demonstrate near-term, tangible value. We continue to believe this is a good time to invest in long-term bets on AI, as the real interest rate (adjusted for inflation) remains very low and the transformative value of AI is more financially powerful than interest rates.
A MESSAGE FROM OUR PARTNER

Join FourthBrain’s Machine Learning Engineer program for access to live, instructor-led classes and dedicated career services. Our graduates have seen an average salary increase of $27,000! Applications are due by October 10, 2022. The next cohort starts on October 18. Learn more

The Dark Side of the Moon — Lit Up!
Neural networks are making it possible to view parts of the Moon that are perpetually shrouded by darkness.
What’s new: Valentin Bickel at ETH Zürich and colleagues devised a method called Hyper-effective Noise Removal U-net Software (HORUS) to remove noise from images of the Moon’s south pole, where direct sunlight never falls. The National Aeronautics and Space Administration (NASA) is using the denoised images to plan lunar missions that will put humans on the Moon for the first time in decades.
The challenge: The only light that strikes the lunar south pole’s craters, boulders, mounds, and crevasses comes from scant photons that reflect off Earth or nearby lunar landforms or arrive from faraway stars. An imaging system aboard NASA’s Lunar Reconnaissance Orbiter can capture features that are lit this way, but it has a tendency to detect photons where none exist. Transmitting and processing the images introduces more noise, further blurring details in the already-dim images. Removing noise optimizes the available light, making it possible to see the landscape.
How it works: The authors trained two neural networks to remove the noise from lunar images.
- Using 70,000 calibration images collected during the Lunar Reconnaissance Orbiter’s mission, a convolutional neural network (CNN) called DeStripeNet learned to generate an array of pixels that simulates camera-produced noise for a given image when fed metadata associated with that image, such as the temperature of the camera and various other pieces of hardware. Then it removed this noise by overlaying the generated pixels on the original image and subtracting their values.
- A U-Net CNN called PhotonNet was trained on modified image pairs of sunlit lunar regions. The images were artificially darkened, and one in each pair was further modified by adding noise generated by a mathematical model. This noise represented errors arising from sources such as data compression applied when transmitting images to Earth. PhotonNet learned to simulate these errors and subtracted them from the output of DeStripeNet, producing a cleaner image.
Results: HORUS removed noise from 200,000 images of the lunar surface. The authors identified possible landing sites, hazards to avoid, and evidence that some areas may contain water ice beneath the surface.
Behind the news: The Moon’s south pole is the target for NASA’s upcoming Artemis program. Artemis 1, scheduled to launch in late September, will be fully automated. Artemis 2, scheduled for 2024, aims to land humans on the Moon for the first time since NASA’s final Apollo mission in 1972.
Why it matters: NASA chose the Moon’s south pole as the target for future missions because water may be frozen at the bottoms of craters there. Water on the Moon could provide clues about the heavenly body’s origin as well as hydration, radiation shielding, and propellant for missions further out in the solar system.
We’re thinking: This AI project is out of this world!

The Sound of Conversation
In spoken conversation, people naturally take turns amid interjections, overlaps, and other patterns that aren’t strictly verbal. A new approach generated natural-sounding — though not necessarily semantically coherent — audio dialogs without training on text transcriptions that mark when one party should stop speaking and the other should chime in.
What's new: Tu Anh Nguyen and colleagues at Meta, France’s National Institute for Research in Digital Science and Technology, and École des Hautes Études en Sciences Sociales introduced Dialogue Transformer Language Model (DLM), a system that learned to incorporate the interruptions, pauses, and inflections of conversational speech into audio dialogues. You can listen to examples here.
Key insight: Prior efforts to model dialogue were based on text, but text datasets omit information that’s unique to spoken interactions. Training directly on recordings of spoken dialogue can enable models to learn this additional mode of expression so they can mimic face-to-face conversation more naturally.
How it works: The system encoded two audio signals — two sides of a spoken conversation — into tokens. It processed each token stream through a separate transformer and decoded the tokens back to audio signals. The transformers were trained on Fisher English Training Speech, a dataset that comprises over 10,000 telephone conversations, an average of 10 minutes long, recorded using a separate audio channel for each participant.
- HuBERT, a self-supervised system that produces speech representations, tokenized the audio signals using a convolutional neural network (CNN) and transformer, which reduced 16,000 samples per second to 50. To adapt it to the Fisher dataset, the authors trained it to generate masked tokens.
- Given tokens from HuBERT, HiFi-GAN, a generative adversarial network with CNN architecture, learned to generate the audio waveform of one speaker.
- Given the token streams, two transformers with shared weights learned to predict new tokens. The authors modified the transformers by adding, between the usual self-attention and fully connected layers, a cross-attention layer that attended to tokens from both signals. Estimating each token’s duration meant the authors could remove repetitions of the same token from the training data to avoid generating overly elongated sounds (such as a “hmm” that never ends).
- At inference, the transformers repeatedly added the next predicted tokens to two sequences, each of which started with a preset starting token. HiFi-GAN converted the sequence into audio.
Results: Crowdsourced evaluators compared DLM to a similar approach that used a single transformer to process both channels of conversation. They rated naturalness of turn-taking and meaningfulness on a 1 to 5 scale. (Ground-truth dialogs scored around 4.25 for both criteria.) DLM performed relatively well in turn-taking though poorly in meaningful output. For turn-taking, DLM achieved 3.86 while the single transformer achieved 3.46. For meaningfulness, DLM achieved 2.71, while the single transformer achieved 2.46.
Why it matters: Two transformers can model a pair of participants in conversation (or other interaction) more effectively than one. Connecting them via cross attention layers enables them to be aware of one another’s activity without needing to predict it. This simplifies the task of modeling their interactions while avoiding potentially confounding variables such as who said what.
We're thinking: The system’s ability to mimic the ebb and flow of conversation is impressive, but its verbal output is largely gibberish. To be fair, training on only 1,700 hours of audio conversation may not be expected to impart much about semantics. We look forward to an update that produces more cogent spoken conversation.